31 dec 2025·7 min
Correlatie-id's end-to-end: traceer een gebruikersactie in logs
Correlation IDs end-to-end laat zien hoe je één ID in de frontend maakt, via API's doorgeeft en in logs opneemt zodat support problemen snel kan traceren.
Correlation IDs end-to-end laat zien hoe je één ID in de frontend maakt, via API's doorgeeft en in logs opneemt zodat support problemen snel kan traceren.
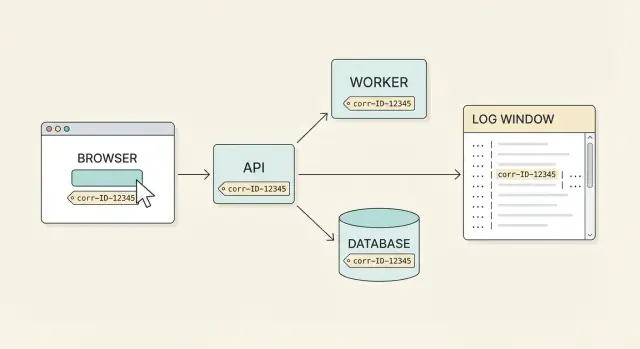
Support krijgt zelden een nette foutmelding. Een gebruiker zegt: "Ik klikte op Betalen en het mislukte", maar die enkele klik kan de browser, een API-gateway, een betalingsservice, een database en een background job raken. Elk onderdeel logt zijn eigen stukje van het verhaal op verschillende momenten, op verschillende machines. Zonder één gedeeld label blijf je raden welke logregels bij elkaar horen.
Een correlatie-id is dat gedeelde label. Het is één ID gekoppeld aan één gebruikersactie (of één logische workflow) en die wordt meegedragen door elk request, elke retry en elke service-hop. Met echte end-to-end dekking kun je bij een gebruikersmelding beginnen en de volledige tijdlijn over systemen heen ophalen.
Mensen verwarren vaak een paar vergelijkbare ID's. Dit is de duidelijke scheiding:
Wat goed eruitziet is eenvoudig: een gebruiker meldt een probleem, je vraagt om de correlatie-id die in de UI staat (of die in een supportscherm gevonden wordt), en iemand in het team kan het volledige verhaal binnen enkele minuten vinden. Je ziet het frontend-request, de API-response, de backend-stappen en het database-resultaat — allemaal verbonden.
Voordat je iets genereert, spreek een paar regels af. Als elk team een andere headernaam of logveld kiest, blijft support gokken.
Begin met één canonieke naam en gebruik die overal. Een veelgebruikte keuze is een HTTP-header zoals X-Correlation-Id, plus een gestructureerd logveld zoals correlation_id. Kies één spelling en één case, documenteer het en zorg dat je reverse proxy of gateway de header niet hernoemt of verwijdert.
Kies een formaat dat makkelijk te maken is en veilig om te delen in tickets en chats. UUID's werken goed omdat ze uniek en saai zijn. Houd de ID kort genoeg om te kopiëren, maar niet zo kort dat je botsingen riskeert. Consistentie is belangrijker dan slimheid.
Bepaal ook waar de ID moet verschijnen zodat mensen er daadwerkelijk iets aan hebben. In de praktijk betekent dat: aanwezig in requests, logs en foutuitvoer, en doorzoekbaar in de tool die jullie gebruiken.
Definieer hoe lang een ID moet leven. Een goede default is één gebruikersactie, zoals "op Betalen geklikt" of "profiel opgeslagen". Voor langere workflows die over services en queues hops gaan, behoud je dezelfde ID totdat de workflow eindigt, en begin je daarna een nieuwe voor de volgende actie. Vermijd "één ID voor de hele sessie" omdat zoekresultaten dan snel rumoerig worden.
Een harde regel: stop nooit persoonlijke gegevens in de ID. Geen e-mails, telefoonnummers, gebruikers-ID's of ordernummers. Als je die context nodig hebt, log het in aparte velden met de juiste privacycontrols.
De makkelijkste plek om een correlatie-id te starten is op het moment dat de gebruiker een actie begint die je belangrijk vindt: op "Opslaan" klikken, een formulier verzenden, of een flow starten die meerdere requests triggert. Als je wacht tot de backend hem maakt, mis je vaak het eerste deel van het verhaal (UI-fouten, retries, geannuleerde requests).
Gebruik een willekeurig, uniek formaat. UUID v4 is een veelvoorkeur omdat het eenvoudig te genereren is en weinig kans op botsingen heeft. Houd het ondoorzichtig (geen gebruikersnamen, e-mails of tijdstempels) zodat je geen persoonlijke gegevens in headers en logs lekt.
Beschouw een "workflow" als één gebruikersactie die meerdere requests kan triggeren: valideren, uploaden, record aanmaken en daarna lijsten vernieuwen. Maak één ID zodra de workflow start en behoud die totdat de workflow eindigt (succes, fout of gebruiker annuleert). Een simpel patroon is om het in component-state of een lichtgewicht request-contextobject op te slaan.
Als de gebruiker dezelfde actie twee keer start, genereer dan een nieuwe correlatie-id voor de tweede poging. Dat helpt support om "zelfde klik opnieuw geprobeerd" te onderscheiden van "twee afzonderlijke inzendingen."
Voeg de ID toe aan elke API-aanroep die door de workflow wordt getriggerd, meestal via een header zoals X-Correlation-ID. Als je een gedeelde API-client gebruikt (fetch-wrapper, Axios-instance, etc.), geef de ID één keer door en laat de client hem in alle calls injecteren.
// 1) when the user action starts
const correlationId = crypto.randomUUID(); // UUID v4 in modern browsers
// 2) pass it to every request in this workflow
await api.post('/orders', payload, {
headers: { 'X-Correlation-ID': correlationId }
});
await api.get('/orders/summary', {
headers: { 'X-Correlation-ID': correlationId }
});
Als je UI achtergrondrequests maakt die niet bij de actie horen (polling, analytics, auto-refresh), hergebruik de workflow-id dan niet voor die calls. Houd correlatie-id's gefocust zodat één ID één verhaal vertelt.
Zodra je een correlatie-id in de browser genereert, is de taak simpel: hij moet met elk request de frontend verlaten en onveranderd bij elke API-grens aankomen. Dit is waar het meestal misgaat wanneer teams nieuwe endpoints, nieuwe clients of nieuwe middleware toevoegen.
De veiligste default is een HTTP-header op elke call (bijvoorbeeld X-Correlation-Id). Headers zijn makkelijk op één plek toe te voegen (een fetch-wrapper, een Axios-interceptor, een mobile networking layer) en vereisen geen aanpassing van payloads.
Als je cross-origin requests hebt, zorg dat je API die header toestaat. Anders kan de browser hem stilletjes blokkeren en denk je dat je hem verzendt terwijl dat niet zo is.
Als je de ID in de querystring of requestbody moet plaatsen (sommige third-party tools of file uploads dwingen dit af), houd het consistent en noteer het. Kies één veldnaam en gebruik die overal. Mix geen correlationId, requestId en cid afhankelijk van het endpoint.
Retries zijn een andere veelvoorkomende val. Een retry moet dezelfde correlatie-id behouden als het nog steeds dezelfde gebruikersactie betreft. Voorbeeld: een gebruiker klikt op "Opslaan", het netwerk valt weg, je client probeert de POST opnieuw. Support moet één verbonden spoor zien, niet drie losstaande. Een nieuwe gebruikersklik (of een nieuwe background job) krijgt een nieuwe ID.
Voor WebSockets: zet de ID in de message-envelop, niet alleen in de initiële handshake. Eén verbinding kan veel gebruikersacties vervoeren.
Als je een snelle betrouwbaarheidstest wilt:
correlationId-veld.Je API-edge (gateway, load balancer of de eerste webservice die verkeer ontvangt) is waar correlatie-id's betrouwbaar worden of in chaos veranderen. Behandel dit entrypoint als de bron van waarheid.
Accepteer een binnenkomende ID als de client er een stuurt, maar ga er niet van uit dat die er altijd is. Als hij ontbreekt, genereer er dan meteen een nieuwe en gebruik die voor de rest van het request. Zo blijft alles werken, zelfs wanneer sommige clients ouder of verkeerd geconfigureerd zijn.
Doe lichte validatie zodat slechte waarden je logs niet vervuilen. Houd het permissief: controleer lengte en toegestane tekens, maar vermijd strikte formats die echt verkeer zouden weigeren. Sta bijvoorbeeld 16–64 tekens toe en letters, cijfers, streepje en underscore. Als de waarde niet door de validatie komt, vervang hem door een verse ID en ga door.
Maak de ID zichtbaar voor de caller. Geef hem altijd terug in response-headers en neem hem op in foutresponses. Zo kan een gebruiker hem uit de UI kopiëren of een supportagent erom vragen en precies het logspoor vinden.
Een praktisch edge-beleid ziet er zo uit:
X-Correlation-ID (of jouw gekozen header) uit het request.X-Correlation-ID toe aan elke response, inclusief fouten.Voorbeeld van een foutpayload (wat support in tickets en screenshots moet zien):
{
"error": {
"code": "PAYMENT_FAILED",
"message": "We could not confirm the payment.",
"correlation_id": "c3a8f2d1-9b24-4c61-8c4a-2a7c1b9c2f61"
}
}
Zodra een request je backend raakt, behandel de correlatie-id als onderdeel van de requestcontext, niet als iets dat je in een globale variabele stopt. Globals breken op het moment dat je twee requests tegelijk verwerkt, of wanneer asynchroon werk doorgaat nadat de response is verstuurd.
Een schaalbare regel: elke functie die kan loggen of een andere service kan aanroepen, ontvangt de context die de ID bevat. In Go-services betekent dat doorgaans het doorgeven van context.Context door handlers, businesslogica en clientcode.
Als Service A Service B aanroept, kopieer dan dezelfde ID in het uitgaande request. Maak geen nieuwe aan tijdens het transport tenzij je de originele ook bewaart als een apart veld (bijvoorbeeld parent_correlation_id). Als je ID's verandert, verliest support de draad die het verhaal verbindt.
Propagatie wordt vaak gemist op een paar voorspelbare plekken: background jobs die tijdens het request starten, retries binnen clientlibraries, webhooks die later worden getriggerd en fan-out calls. Elk async-bericht (queue/job) moet de ID dragen, en elke retry-logica moet hem behouden.
Logs moeten gestructureerd zijn met een stabiele veldnaam zoals correlation_id. Kies één spelling en houd die overal aan. Vermijd het mixen van requestId, req_id en traceId tenzij je ook een duidelijke mapping definieert.
Als het kan, neem de ID ook op in database-visibility. Een praktische aanpak is om hem toe te voegen aan query-comments of session-metadata zodat langzame querylogs hem kunnen tonen. Wanneer iemand meldt dat de "Opslaan-knop 10 seconden hapte", kan support zoeken op correlation_id=abc123 en de API-log, de downstream-servicecall en de ene langzame SQL-statement zien die de vertraging veroorzaakte.
Een correlatie-id helpt alleen als mensen hem kunnen vinden en volgen. Maak er een eersteklas logveld van (niet begraven in de message-string) en houd de rest van de logentry consistent over services heen.
Koppel de correlatie-id aan een klein setje velden die antwoorden op: wanneer, waar, wat en wie (op een gebruikersveilige manier). Voor de meeste teams betekent dat:
timestamp (met timezone)service en env (api, worker, prod, staging)route (of operation name) en methodstatus en duration_msaccount_id of een gehashte user-id, geen e-mail)Hiermee kan support op ID zoeken, bevestigen dat ze bij de juiste request zitten en zien welke service het afhandelde.
Streef naar een paar sterke broodkruimels per request, niet naar een transcript.
rows=12).Om lawaaiige logs te vermijden, houd debug-level details standaard uit en promoot alleen events die iemand helpen beantwoorden: "Waar is het mislukt?" Als een regel niet helpt het probleem te lokaliseren of de impact te meten, hoort het waarschijnlijk niet in info-level logs.
Redactie (redaction) is net zo belangrijk als structuur. Plaats nooit PII in de correlatie-id of logs: geen e-mails, namen, telefoonnummers, volledige adressen of raw tokens. Als je een gebruiker moet identificeren, log dan een intern ID of een eenrichtingshash.
Een gebruiker stuurt support: "Checkout mislukte toen ik op Betalen klikte." De beste vervolgvraag is simpel: "Kun je de correlatie-id plakken die op het foutscherm staat?" Ze antwoorden met cid=9f3c2b1f6a7a4c2f.
Support heeft nu één handvat dat de UI, API en database-werkzaamheden verbindt. Het doel is dat elke logregel voor die actie dezelfde ID draagt.
Support zoekt in de logs naar 9f3c2b1f6a7a4c2f en ziet de flow:
frontend INFO cid=9f3c2b1f6a7a4c2f event="checkout_submit" cart=3 items
api INFO cid=9f3c2b1f6a7a4c2f method=POST path=/api/checkout user=1842
api ERROR cid=9f3c2b1f6a7a4c2f msg="payment failed" provider=stripe status=502
Daarna volgt een engineer dezelfde ID naar de volgende hop. Het belangrijkste is dat backend-servicecalls (en queue-jobs) de ID ook doorsturen.
payments INFO cid=9f3c2b1f6a7a4c2f action="charge" amount=49.00 currency=USD
payments ERROR cid=9f3c2b1f6a7a4c2f err="timeout" upstream=stripe timeout_ms=3000
db INFO cid=9f3c2b1f6a7a4c2f query="insert into failed_payments" rows=1
Nu is het probleem concreet: de payments-service timed out na 3 seconden en er is een failure-record geschreven. De engineer kan recente deploys checken, bevestigen of timeout-instellingen veranderden en zien of er retries plaatsvinden.
Om de lus te sluiten, doe vier checks:
De snelste manier om correlatie-id's waardeloos te maken is de keten te verbreken. De meeste fouten ontstaan door kleine beslissingen die onschuldig lijken tijdens het bouwen, maar lastig worden wanneer support antwoorden nodig heeft.
Een klassieker is het genereren van een verse ID bij elke hop. Als de browser een ID meestuurt, moet je API-gateway die behouden, niet vervangen. Als je echt een interne ID nodig hebt (voor een queue-bericht of background job), bewaar dan de originele als parent-veld zodat het verhaal verbonden blijft.
Een andere veelvoorkomende gap is gedeeltelijke logging. Teams voegen de ID toe aan de eerste API, maar vergeten hem in worker-processen, scheduled jobs of de database-accesslaag. Het resultaat is een doodlopend spoor: je ziet het request het systeem binnenkomen, maar niet waar het daarna naartoe ging.
Zelfs wanneer de ID overal bestaat, kan het moeilijk doorzoeken zijn als elke service een andere veldnaam of format gebruikt. Kies één naam en houd je eraan op frontend, API's en in logs (bijv. correlation_id). Kies ook één formaat (vaak een UUID), en behandel het als case-sensitive zodat copy-paste werkt.
Verlies de ID niet wanneer er iets misgaat. Als een API 500 teruggeeft of een validatiefout, includeer dan de correlatie-id in de foutresponse (en idealiter ook in een response-header). Zo kan een gebruiker hem in een supportchat plakken en kan je team direct het volledige pad traceren.
Een snelle test: kan een supportmedewerker met één ID beginnen en die door elke logregel volgen, inclusief fouten?
Gebruik dit als sanity check voordat je support vertelt "zoek het maar even in de logs". Dit werkt alleen wanneer elke hop dezelfde regels volgt.
correlation_id in request-gerelateerde logs als een gestructureerd veld.Kies de kleinste wijziging die de keten ononderbroken maakt.
correlation_id en voeg een aparte span_id toe als je meer detail nodig hebt.Een snelle test die gaten opvangt: open devtools, trigger één actie, kopieer de correlatie-id uit het eerste request, en bevestig dat je dezelfde waarde ziet in elk gerelateerd API-request en in elke corresponderende logregel.
Correlatie-id's helpen alleen wanneer iedereen ze op dezelfde manier gebruikt, altijd. Behandel het gedrag rondom correlatie-id's als een verplicht onderdeel van uitrollen, niet als een aardigheidje voor logging.
Voeg een kleine traceerbaarheid-check toe aan je definition of done voor elk nieuw endpoint of UI-actie. Beschrijf hoe de ID wordt aangemaakt (of hergebruikt), waar hij tijdens de flow leeft, welke header hem draagt en wat elke service doet als de header ontbreekt.
Een lichte checklist volstaat meestal:
correlation_id) over apps en services heen.Support heeft ook een simpel script nodig zodat debuggen snel en herhaalbaar is. Bepaal waar de ID voor gebruikers zichtbaar is (bijv. een "Kopieer debug-ID" knop in foutdialogs) en schrijf op wat support moet vragen en waar te zoeken.
Voordat je erop vertrouwt in productie, doorloop een staged flow die echt gebruik nabootst: klik op een knop, trigger een validatiefout en voltooi vervolgens de actie. Bevestig dat je dezelfde ID kunt volgen van browser-request, via API-logs, in achtergrondworkers en tot en met database-call-logs als je die opneemt.
Als je apps bouwt op Koder.ai, helpt het om je correlatie-id-header en loggingconventies in Planning Mode op te nemen zodat gegenereerde React-frontends en Go-services standaard consistent beginnen.
A correlation ID is één gedeelde identificatie die alles tagt wat bij één gebruikersactie of workflow hoort — in de browser, API's, services en workers. Het stelt support in staat om vanaf één ID de volledige tijdlijn op te halen in plaats van te gissen welke logregels bij elkaar horen.
Gebruik een correlatie-id wanneer je één incident snel end-to-end wilt debuggen, zoals “ik klikte op Betalen en het mislukte”. Een sessie-id is te breed omdat die veel acties omvat, en een request-id is te nauw omdat die slechts één HTTP-request identificeert en bij retries verandert.
De beste default is het aanmaken bij het begin van de gebruikersactie in de frontend — zodra de workflow start (formulierverzending, knopklik, multi-step flow). Zo behoud je het vroegste deel van het verhaal, inclusief UI-fouten, retries en geannuleerde requests.
Gebruik een UUID-achtige, ondoorzichtige waarde die makkelijk te kopiëren is en veilig om te delen in supporttickets. Codeer geen persoonlijke gegevens, gebruikersnamen, e-mails, ordernummers of tijdstempels in de ID; die context bewaar je in aparte logvelden met de juiste privacycontroles.
Standaardiseer op één headernaam en gebruik die overal, bijvoorbeeld X-Correlation-ID, en log het onder een consistent gestructureerd veld zoals correlation_id. Consistentie is belangrijker dan de exacte naam, omdat support één voorspelbare waarde nodig heeft om op te zoeken.
Houd dezelfde correlatie-id aan bij retries zolang het dezelfde gebruikersactie is, zodat logregels verbonden blijven. Genereer alleen een nieuwe correlatie-id wanneer de gebruiker een nieuwe poging start als een aparte actie (bijvoorbeeld later opnieuw op de knop klikken).
Je API-entrypoint moet een binnenkomende ID accepteren als die aanwezig is, en een nieuwe aanmaken wanneer deze ontbreekt of duidelijk ongeldig is. Echo de ID ook terug in responses (inclusief fouten) zodat gebruikers en support deze uit de UI kunnen kopiëren.
Neem de correlatie-id op in je requestcontext en kopieer die naar elk downstream-verzoek, inclusief interne HTTP/gRPC-aanroepen en berichten in queues. Vermijd het aanmaken van een nieuwe correlatie-id tijdens de vlucht; als je extra granulariteit nodig hebt, voeg dan een apart intern kenmerk toe zonder de originele keten te verbreken.
Log het als een eersteklas gestructureerd veld, niet begraven in een tekstregel, zodat het zoekbaar en filterbaar is. Koppel het aan enkele praktische velden zoals servicenaam, route, status, duur en een gebruikersveilige identifier, en zorg dat fouten het ook loggen zodat het spoor niet stopt op het belangrijkste moment.
Een snelle test: trigger één actie, kopieer de correlatie-id uit het eerste request of foutscherm, en controleer dat die exact hetzelfde waarde heeft in elke gerelateerde request-header en in elke service-logregel die de workflow verwerkt. Als de ID verdwijnt in workers, retries of foutresponses, dan is dat de eerste gap om te repareren.