Van prototype naar SaaS: waar de verwarring begint
Een prototype bewijst een idee. Een SaaS moet echt gebruik doorstaan: piekverkeer, rommelige data, retries en klanten die elke hapering opmerken. Daar wordt het verwarrend, omdat de vraag verandert van “werkt het?” naar “blijft het werken?”.
Met echte gebruikers faalt “het werkte gisteren” om alledaagse redenen. Een background job draait later dan normaal. Eén klant uploadt een bestand dat tien keer groter is dan je testdata. Een payment provider hangt 30 seconden. Niets exotisch, maar de gevolgen worden luid zodra onderdelen van je systeem van elkaar afhankelijk zijn.
De meeste complexiteit verschijnt op vier plekken: data (dezelfde feitelijkheid bestaat op meerdere plekken en verschuift), latency (50 ms-aanroepen duren soms 5 seconden), fouten (timeouts, gedeeltelijke updates, retries) en teams (verschillende mensen shippen verschillende services op verschillende schema’s).
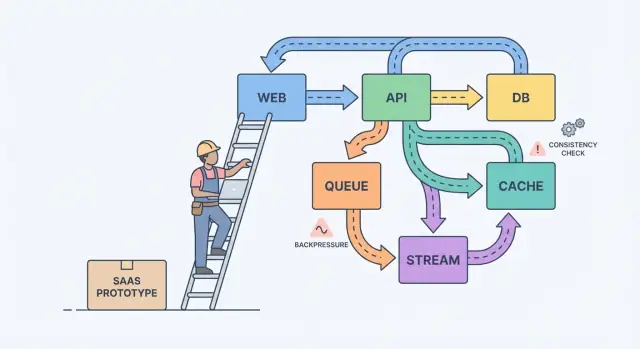
Een simpel mentaal model helpt: componenten, berichten en state.
Componenten doen werk (webapp, API, worker, database). Berichten verplaatsen werk tussen componenten (requests, events, jobs). State is wat je onthoudt (bestellingen, gebruikersinstellingen, billing-status). Schaalpijn ontstaat meestal door een mismatch: je stuurt berichten sneller dan een component kan verwerken, of je werkt state bij op twee plekken zonder een duidelijke bron van waarheid.
Een klassiek voorbeeld is billing. Een prototype maakt misschien in één request een factuur, verstuurt een e-mail en zet het plan van een gebruiker omhoog. Onder load vertraagt e-mail, loopt het request vast, retryt de client en heb je nu twee facturen en één planwijziging. Betrouwbaarheidswerk gaat vooral over voorkomen dat die alledaagse fouten klantzichtbare bugs worden.
Maak concepten tot geschreven beslissingen
Systemen worden meestal complexer omdat ze groeien zonder overeenstemming over wat correct moet zijn, wat alleen snel hoeft te zijn en wat moet gebeuren bij fouten.
Begin met het tekenen van een grens rond wat je gebruikers belooft. Benoem binnen die grens de acties die elke keer correct moeten zijn (geld bewegen, toegangscontrole, account-eigendom). Benoem daarna de gebieden waar “eventueel correct” prima is (analytics, zoek-indexen, aanbevelingen). Deze ene scheiding verandert vage theorie in prioriteiten.
Schrijf vervolgens je source of truth op. Dat is waar feiten één keer duurzaam worden vastgelegd, met duidelijke regels. Alles anders is afgeleide data voor snelheid of gemak. Als een afgeleid beeld corrupt raakt, moet je het kunnen herbouwen vanuit de source of truth.
Wanneer teams vastlopen, brengen deze vragen meestal naar boven wat belangrijk is:
- Welke data mag nooit verloren gaan, zelfs als het vertraagt?
- Wat kan worden gereconstrueerd uit andere data, zelfs als het uren duurt?
- Wat mag verouderd zijn, en hoe lang, vanuit het perspectief van een gebruiker?
- Welke fout is erger voor jullie: duplicaten, missende events of vertragingen?
Als een gebruiker hun billingplan bijwerkt, kan een dashboard achterlopen. Maar je kunt geen mismatch tolereren tussen betaalstatus en daadwerkelijke toegang.
Streams, queues en logs: kies de juiste vorm van werk
Als een gebruiker op een knop klikt en meteen het resultaat moet zien (profiel opslaan, dashboard laden, permissies checken), is een normaal request-response API meestal genoeg. Houd het direct.
Zodra werk later mag plaatsvinden, verplaats het naar async. Denk aan e-mails sturen, kaarten afschrijven, rapporten genereren, uploads herschalen of data synchroniseren naar search. De gebruiker hoeft hier niet op te wachten en je API moet niet geblokkeerd zijn terwijl dit draait.
Een queue is een takenlijst: elke taak moet één keer door één worker worden afgehandeld. Een stream (of log) is een record: events blijven op volgorde zodat meerdere lezers kunnen replayen, bijpraten of later nieuwe features bouwen zonder de producer te moeten aanpassen.
Een praktische keuzehulp:
- Gebruik request-response wanneer de gebruiker een direct antwoord nodig heeft en het werk klein is.
- Gebruik een queue voor achtergrondwerk met retries waarbij slechts één worker elke taak mag doen.
- Gebruik een stream/log wanneer je replay, een audit-trail of meerdere consumenten nodig hebt die niet gekoppeld moeten zijn aan één service.
Voorbeeld: jouw SaaS heeft een “Create invoice”-knop. De API valideert input en slaat de factuur op in Postgres. Daarna handelt een queue “send invoice email” en “charge card” af. Als je later analytics, notificaties en fraud-checks toevoegt, laat een stream van InvoiceCreated-events elk feature subscriben zonder je core-service in een doolhof te veranderen.
Event-design: wat je publiceert en wat je bewaart
Naarmate een product groeit, worden events meer dan “nice to have”: ze vormen een vangnet. Goed event-design draait om twee vragen: welke feiten leg je vast en hoe kunnen andere onderdelen van het product reageren zonder te moeten raden?
Begin met een kleine set business-events. Kies momenten die ertoe doen voor gebruikers en geld: UserSignedUp, EmailVerified, SubscriptionStarted, PaymentSucceeded, PasswordResetRequested.
Namen overleven code. Gebruik verleden tijd voor voltooide feiten, wees specifiek en vermijd UI-terminologie. PaymentSucceeded blijft betekenisvol zelfs als je later coupons, retries of meerdere payment providers toevoegt.
Behandel events als contracten. Vermijd een alles-in-één event zoals “UserUpdated” met een grote verzameling velden die elke sprint veranderen. Geef de voorkeur aan het kleinste feit waar je jarenlang achter kunt staan.
Om veilig te evolueren, geef de voorkeur aan additive changes (nieuwe optionele velden). Heb je een breaking change nodig, publiceer dan een nieuwe event-naam (of expliciete versie) en draai beide totdat oude consumers weg zijn.
Wat bewaar je? Als je alleen de laatste rijen in een database bewaart, verlies je het verhaal hoe je daar gekomen bent.
Raw events zijn uitstekend voor audit, replay en debugging. Snapshots zijn handig voor snelle reads en snelle herstelprocedures. Veel SaaS-producten gebruiken beide: bewaar raw events voor sleutelworkflows (billing, permissies) en onderhoud snapshots voor user-facing schermen.
Consistentieafwegingen die gebruikers echt merken
Consistentie verschijnt in momenten als: “Ik veranderde mijn plan, waarom staat het nog op Free?” of “Ik stuurde een invite, waarom kan mijn collega nog niet inloggen?”
Sterke consistentie betekent dat zodra je een succesvolle melding krijgt, elk scherm de nieuwe toestand meteen zou moeten tonen. Eventual consistency betekent dat de verandering zich in de tijd verspreidt en dat verschillende delen van de app voor een korte periode kunnen verschillen. Geen van beide is per definitie ‘beter’. Je kiest op basis van de schade die een mismatch kan veroorzaken.
Sterke consistentie past meestal bij geld, toegang en veiligheid: een kaart afschrijven, een wachtwoord wijzigen, API-sleutels intrekken, seat-limieten afdwingen. Eventual consistency past vaak bij activity feeds, zoekresultaten, analytics dashboards, “laatst gezien” en notificaties.
Als je staleness accepteert, ontwerp er dan voor in plaats van het te verbergen. Houd de UI eerlijk: toon een “Bezig met bijwerken…”-status na een write totdat bevestiging binnenkomt, bied een handmatige verversoptie voor lijsten en gebruik optimistic UI alleen wanneer je gemakkelijk kunt terugdraaien.
Retries zijn waar consistentie slinks wordt. Netwerken vallen uit, clients dubbeltikken en workers herstarten. Voor belangrijke operaties maak requests idempotent zodat het herhalen van dezelfde actie niet twee facturen, twee invites of twee refunds creëert. Een veelgebruikte aanpak is een idempotency key per actie plus een serverregel om het oorspronkelijke resultaat bij herhalen terug te geven.
Backpressure: voorkom dat het systeem smelt
Backpressure heb je nodig wanneer requests of events sneller binnenkomen dan je systeem kan verwerken. Zonder backpressure hoopt werk zich op in geheugen, queues groeien en de traagste afhankelijkheid (vaak de database) bepaalt wanneer alles faalt.
In gewone taal: je producer blijft praten terwijl je consumer verdrinkt. Als je blijft accepteren, word je niet alleen trager. Je veroorzaakt een kettingreactie van timeouts en retries die de load vermenigvuldigt.
Waarschuwingssignalen verschijnen meestal voordat een outage: backlog groeit continu, latency stijgt na pieken of deploys, retries nemen toe door timeouts, niet-gerelateerde endpoints falen wanneer één afhankelijkheid traag is, en databaseconnecties zitten op de limiet.
Als je dat punt bereikt, kies dan een duidelijke regel voor wat er gebeurt als je vol bent. Het doel is niet alles tegen elke prijs te verwerken. Het doel is blijven functioneren en snel herstellen. Teams starten meestal met één of twee controls: rate limits (per gebruiker of API-key), begrensde queues met een gedefinieerd drop/delay-beleid, circuit breakers voor falende afhankelijkheden en prioriteiten zodat interactieve verzoeken voorrang hebben op achtergrondtaken.
Bescherm de database eerst. Houd connection pools klein en voorspelbaar, stel query timeouts in en zet harde limieten op dure endpoints zoals ad-hoc rapporten.
Een stapsgewijze route naar betrouwbaarheid (zonder alles te herschrijven)
Betrouwbaarheid vereist zelden een grote rewrite. Het komt meestal door een paar beslissingen die fouten zichtbaar, begrensd en herstelbaar maken.
Begin met de flows die vertrouwen winnen of verliezen en zet daarna veiligheidsrails voordat je features toevoegt:
-
Map critical paths. Schrijf de exacte stappen op voor signup, login, password reset en elke payment flow. Noem voor elke stap de afhankelijkheden (database, email provider, background worker). Dit dwingt duidelijkheid af over wat direct moet en wat “eventueel” kan worden opgelost.
-
Voeg observability-basis toe. Geef elk request een ID dat in logs verschijnt. Volg een kleine set metrics die bij gebruikerspijn passen: error rate, latency, queue-diepte en trage queries. Voeg tracing alleen toe waar requests services kruisen.
-
Isoleer traag of flaky werk. Alles wat met een externe service praat of regelmatig langer dan een seconde duurt, moet naar jobs en workers.
-
Ontwerp voor retries en gedeeltelijke fouten. Ga uit van timeouts. Maak operaties idempotent, gebruik backoff, zet tijdslimieten en houd user-facing acties kort.
-
Oefen herstel. Backups zijn alleen belangrijk als je ze kunt terugzetten. Gebruik kleine releases en houd een snelle rollback-route.
Als je tooling snapshots en rollback ondersteunt (Koder.ai doet dat), bouw dat dan in in normale deployment-habits in plaats van het als noodgreep te behandelen.
Voorbeeld: van een kleine SaaS naar iets betrouwbaars
Stel je een kleine SaaS voor die teams helpt nieuwe klanten onboarden. De flow is simpel: een gebruiker meldt zich aan, kiest een plan, betaalt en ontvangt een welkomstmail plus een paar "getting started"-stappen.
In het prototype gebeurt alles in één request: account aanmaken, kaart afschrijven, ‘paid’ op de gebruiker zetten, e-mail versturen. Het werkt totdat het verkeer groeit, retries plaatsvinden en externe services vertraagd raken.
Om het betrouwbaar te maken, zet het team sleutelacties om in events en houdt een append-only geschiedenis bij. Ze introduceren een paar events: UserSignedUp, PaymentSucceeded, EntitlementGranted, WelcomeEmailRequested. Dat geeft hen een audit-trail, maakt analytics makkelijker en laat traag werk op de achtergrond gebeuren zonder signup te blokkeren.
Een paar keuzes doen het meeste werk:
- Behandel payments als source of truth voor toegang, niet één enkele ‘paid’-vlag.
- Ken entitlements toe vanaf
PaymentSucceeded met een duidelijke idempotency key zodat retries geen dubbele toekenningen doen.
- Verstuur e-mails vanuit een queue/worker, niet vanuit het checkout-request.
- Leg events vast, ook als een handler faalt, zodat je kunt replayen en herstellen.
- Voeg timeouts en een circuit breaker toe rond externe providers.
Als betaling succesvol is maar toegang nog niet is toegekend, voelen gebruikers zich opgelicht. De oplossing is niet “perfecte consistentie overal.” Het is beslissen wat nu consistent moet zijn en die beslissing in de UI tonen met een status als “Je plan wordt geactiveerd” totdat EntitlementGranted binnenkomt.
Op een slechte dag maakt backpressure het verschil. Als de e-mail-API vastloopt tijdens een marketingcampagne, time-out de oude opzet checkouts en retryen gebruikers, wat dubbele afschrijvingen en dubbele e-mails creëert. In het betere ontwerp slaagt de checkout, worden e-mailverzoeken in een queue gezet en zorgt een replay-job dat de backlog wordt weggedraaid zodra de provider herstelt.
Veelvoorkomende valkuilen bij opschalen
De meeste outages worden niet veroorzaakt door één heldhaftige bug. Ze ontstaan door kleine beslissingen die logisch leken in een prototype en daarna gewoon werden.
Een veelvoorkomende valkuil is te vroeg splitsen in microservices. Je krijgt services die vooral elkaar aanroepen, onduidelijke ownership en veranderingen die vijf deploys vereisen in plaats van één.
Een andere valkuil is eventual consistency gebruiken als vrijbrief. Gebruikers geven niets om de term; ze willen dat wanneer ze op Opslaan klikken de pagina later geen oude data toont of een factuurstatus heen en weer flipt. Accepteer je vertragingen, zorg dan voor gebruikersfeedback, timeouts en een definitie van “goed genoeg” per scherm.
Andere veelvoorkomende fouten: events publiceren zonder reprocessing-plan, onbeperkte retries die de load tijdens incidenten vermenigvuldigen en elk service direct laten praten met hetzelfde databaseschema zodat één wijziging veel teams breekt.
Snelle checks voordat je het “production ready” noemt
“Production ready” is een set beslissingen waar je om 02:00 naar kunt wijzen. Duidelijkheid verslaat cleverness.
Begin met het benoemen van je sources of truth. Voor elk sleuteldata-type (customers, subscriptions, invoices, permissions) beslis waar het definitieve record leeft. Als je app “waarheid” uit twee plaatsen leest, ga je vroeg of laat verschillende antwoorden aan verschillende gebruikers tonen.
Kijk daarna naar retries. Ga ervan uit dat elke belangrijke actie ooit twee keer zal lopen. Als hetzelfde verzoek twee keer binnenkomt, kun je dan dubbele betalingen, dubbele verzendingen of dubbele creaties vermijden?
Een kleine checklist die de meeste pijnlijke fouten opvangt:
- Per data-type kun je een source of truth aanwijzen en benoemen wat afgeleid is.
- Elke belangrijke write is veilig te herhalen (idempotency key of unieke constraint).
- Je async werk kan niet onbeperkt groeien (je meet lag/oude bericht-leeftijd en waarschuwt voordat gebruikers het merken).
- Je hebt een plan voor verandering (omkeerbare migraties, event-versioning).
- Je kunt rollbacks en restores met vertrouwen uitvoeren omdat je het geoefend hebt.
Volgende stappen: neem één beslissing tegelijk
Schaalbaarheid wordt makkelijker als je systeemontwerp behandelt als een korte lijst keuzes, niet als een stapel theorie.
Schrijf 3 tot 5 beslissingen op die je de komende maand verwacht te maken, in gewone taal: “Verplaatsen we e-mailverzending naar een background job?” “Accepteren we licht verouderde analytics?” “Welke acties moeten onmiddellijk consistent zijn?” Gebruik die lijst om product en engineering op één lijn te krijgen.
Kies daarna één workflow die momenteel synchroon is en zet alleen die om naar async. Bonussen zijn: receipts, notificaties, rapporten en bestandsverwerking. Meet twee dingen voor en na: gebruikerszichtbare latency (voelde de pagina sneller?) en foutgedrag (maakten retries duplicaten of verwarring?).
Als je snel wilt prototypen, kan Koder.ai (koder.ai) nuttig zijn om te itereren op een React + Go + PostgreSQL SaaS terwijl je snapshots en rollback binnen handbereik houdt. De maatstaf blijft simpel: ship één verbetering, leer van echt verkeer en beslis de volgende.