18 aug 2025·8 min
Chris Lattner’s LLVM: de stille motor achter moderne toolchains
Ontdek hoe Chris Lattner’s LLVM uitgroeide tot het modulaire compilerplatform achter talen en tools—dat optimalisaties, betere diagnostiek en snelle builds mogelijk maakt.
Wat LLVM is, in eenvoudige bewoordingen
LLVM kun je het beste zien als de “machineruimte” die veel compilers en ontwikkeltools delen.
Als je code schrijft in een taal zoals C, Swift of Rust, moet iets die code vertalen naar instructies die je CPU kan uitvoeren. Een traditionele compiler bouwde vaak elk deel van die keten zelf. LLVM kiest een andere aanpak: het levert een hoogwaardige, herbruikbare kern die de moeilijke, dure onderdelen afhandelt—optimalisatie, analyse en het genereren van machinecode voor veel soorten processors.
Een gedeelde basis voor veel talen
LLVM is meestal geen enkele compiler die je direct gebruikt. Het is compilerinfrastructuur: bouwstenen die taakteams kunnen samenvoegen tot een toolchain. Het ene team kan zich richten op syntax, semantiek en ontwikkelaarsgerichte features, en de zware taken aan LLVM overdragen.
Die gedeelde basis is een belangrijke reden waarom moderne talen snel, veilige toolchains kunnen leveren zonder decennia aan compilerwerk telkens opnieuw uit te vinden.
Waarom het belangrijk is, ook als je geen compilerpersoon bent
LLVM verschijnt in de dagelijkse ontwikkelaarservaring:
- Snelheid: het kan hoog-niveau code efficiënt vertalen naar machinecode op meerdere platforms.
- Betere foutmeldingen en debugging: het ecosysteem rond LLVM maakt rijkere diagnostiek en betere tooling mogelijk.
- Meer dan “alleen compilatie”: statische analyse, sanitizers, code coverage en andere ontwikkelaarshulpmiddelen bouwen vaak op dezelfde onderliggende representatie en bibliotheken.
Wat dit artikel wél en niet is
Dit is een rondleiding langs de ideeën die Chris Lattner in gang zette: hoe LLVM is opgebouwd, waarom die middenlaag ertoe doet, en hoe het optimalisaties en multi-platform ondersteuning mogelijk maakt. Het is geen leerboek—we richten ons op intuïtie en reële impact in plaats van formele theorie.
Chris Lattner’s oorspronkelijke visie
Chris Lattner is een computerwetenschapper en engineer die, als promovendi begin jaren 2000, LLVM begon vanuit een praktische frustratie: compilers waren krachtig, maar moeilijk herbruikbaar. Als je een nieuwe programmeertaal wilde, betere optimalisaties of ondersteuning voor een nieuwe CPU, moest je vaak prutsen aan een strak gekoppelde “alles-in-één” compiler waar elke wijziging bijeffecten had.
Het probleem dat hij wilde oplossen
Destijds waren veel compilers gebouwd als één grote machine: het deel dat de taal begreep, het deel dat optimaliseerde en het deel dat machinecode genereert waren sterk verweven. Dat maakte ze effectief voor hun oorspronkelijke doel, maar duur om aan te passen.
Lattner wilde niet “een compiler voor één taal”. Hij wilde een gedeelde basis die veel talen en tools kon aandrijven—zonder dat iedereen steeds dezelfde complexe onderdelen opnieuw hoeft te schrijven. De gok was: als je het midden van de pijplijn kunt standaardiseren, kun je sneller innoveren aan de randen.
Waarom “modulaire infrastructuur” nieuw was
De sleutelverschuiving was compilatie zien als een set scheidbare bouwblokken met heldere grenzen. In een modulaire wereld:
- kan een taakteams zich richten op parsing en ontwikkelaarsfeatures,
- kan een optimalisatieteam prestaties één keer verbeteren en die verbetering breed delen,
- kan hardware-ondersteuning worden toegevoegd zonder alles stroomopwaarts opnieuw te ontwerpen.
Deze scheiding klinkt nu vanzelfsprekend, maar ging tegen de manier in waarop veel productcompilers waren gegroeid.
Open source, gemaakt om door anderen gebruikt te worden
LLVM werd vroeg als open source vrijgegeven, wat belangrijk was omdat gedeelde infrastructuur alleen werkt als meerdere groepen het kunnen vertrouwen, inspecteren en uitbreiden. In de loop van de tijd hebben universiteiten, bedrijven en onafhankelijke bijdragers het project gevormd door targets toe te voegen, randgevallen te repareren, de prestaties te verbeteren en nieuwe tools eromheen te bouwen.
Dat gemeenschapsaspect was niet alleen goedheid—het hoorde bij het ontwerp: maak de kern breed bruikbaar, en het wordt de moeite waard om samen te onderhouden.
Het grote idee: frontends, een gedeelde kern en backends
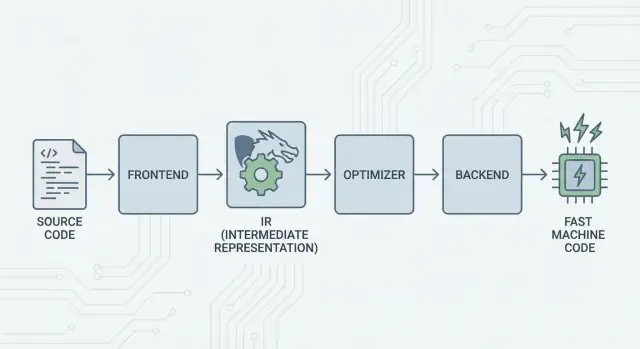
Het kernidee van LLVM is eenvoudig: splits een compiler in drie hoofdonderdelen zodat veel talen het moeilijkste werk kunnen delen.
1) Frontends: “Wat bedoelde de programmeur?”
Een frontend begrijpt een specifieke programmeertaal. Het leest je broncode, controleert de regels (syntax en types) en zet het om in een gestructureerde representatie.
Het belangrijkste punt: frontends hoeven niet alle CPU-details te kennen. Hun taak is taalconcepten—functies, lussen, variabelen—om te zetten in iets universeels.
2) De gedeelde middenlaag: één gemeenschappelijke kern in plaats van N×M werk
Traditioneel betekende het bouwen van een compiler vaak dat je hetzelfde werk steeds opnieuw deed:
- Met N talen en M chiptargets krijg je N×M combinaties om te ondersteunen.
LLVM reduceert dat tot:
- N frontends die vertalen naar een gedeelde vorm
- M backends die van die gedeelde vorm naar machinecode vertalen
Die “gedeelde vorm” is het hart van LLVM: een gemeenschappelijke pijplijn waar optimalisaties en analyses leven. Dit vereenvoudigt enorm. Verbeteringen in het midden (zoals betere optimalisaties of betere debug-informatie) kunnen veel talen tegelijk ten goede komen, in plaats van in elke compiler opnieuw te worden geïmplementeerd.
3) Backends: “Hoe laten we dit snel draaien op die CPU?”
Een backend neemt de gedeelde representatie en produceert machine-specifieke output: instructies voor x86, ARM, enzovoort. Hier tellen details zoals registers, calling conventions en instructieselectie.
Een intuïtief beeld van de pijplijn
Zie compilatie als een reisroute:
- Broncode begint in een taalspecifiek land (frontend).
- Het passeert een grens naar een gedeelde, gestandaardiseerde “middentaal” (LLVM’s kernrepresentatie en passes).
- Daarna neemt het een lokaal treinsysteem naar een specifieke eindbestemming (backend voor je target-machine).
Het resultaat is een modulaire toolchain: talen kunnen zich focussen op duidelijkheid van expressie, terwijl LLVM’s gedeelde kern zich richt op efficiënt draaien op veel platforms.
LLVM IR: de middenlaag die hergebruik mogelijk maakt
LLVM IR (Intermediate Representation) is de “gemeenschappelijke taal” tussen een programmeertaal en de machinecode die je CPU uitvoert.
Een compilerfrontend (zoals Clang voor C/C++) vertaalt je broncode naar deze gedeelde vorm. Daarna werken LLVM’s optimalisatoren en codegenerators op de IR, niet op de oorspronkelijke taal. Ten slotte zet een backend de IR om in instructies voor een specifiek target (x86, ARM, enz.).
Een gemeenschappelijke taal tussen tools en CPU's
Zie LLVM IR als een zorgvuldig ontworpen brug:
- Boven: veel bron-talen kunnen aansluiten (C, C++, Rust, Swift, Julia, enz.).
- Onder: veel CPU's kunnen worden aangesproken.
- In het midden: dezelfde analyse- en optimalisatietools kunnen hergebruikt worden.
Daarom noemen mensen LLVM vaak “compilerinfrastructuur” in plaats van “een compiler”. De IR is het gedeelde contract dat die infrastructuur herbruikbaar maakt.
Waarom IR hergebruik mogelijk maakt (en iedereen werk bespaart)
Zodra code in LLVM IR staat, hoeven de meeste optimalisatiepasses niet te weten of het origineel C++-templates, Rust-iterators of Swift-generics waren. Ze kijken vooral naar universele ideeën zoals:
- “Deze waarde is constant.”
- “Deze berekening wordt herhaald; kunnen we het resultaat hergebruiken?”
- “Deze geheugenlaadactie kan veilig worden verplaatst of verwijderd.”
Taakteams hoeven dus niet hun eigen volledige optimizer-stack te bouwen en onderhouden. Ze kunnen zich richten op de frontend—parsing, typechecking, taalregels—en daarna het zware werk aan LLVM overdragen.
Hoe het conceptueel “uitziet”
LLVM IR is laag genoeg om netjes naar machinecode te mapppen, maar nog steeds gestructureerd genoeg voor analyse. Conceptueel is het opgebouwd uit eenvoudige instructies (add, compare, load/store), expliciete controleflow (branches) en sterk getypte waarden—meer een nette assembly-taal voor compilers dan iets dat mensen doorgaans schrijven.
Hoe optimalisaties werken (zonder de wiskunde)
Als mensen “compileroptimalisaties” horen, denken ze vaak aan mysterieuze trucs. In LLVM zijn de meeste optimalisaties beter te begrijpen als veilige, mechanische herschrijvingen van het programma—transformaties die behouden wat de code doet, maar proberen het sneller (of kleiner) te maken.
Zie het als redigeren, niet uitvinden
LLVM neemt je code (in LLVM IR) en past herhaaldelijk kleine verbeteringen toe, vergelijkbaar met het polijsten van een concept:
- Dupliceer werk verwijderen: Als een waarde twee keer wordt berekend en er verandert niets ertussen, kan LLVM het één keer berekenen en het resultaat hergebruiken.
- Eenvoudige logica vereenvoudigen: Constante expressies kunnen vroeg worden gevouwen (bijv.
3 * 4naar12), zodat de CPU minder werk op runtime heeft. - Lussen stroomlijnen: Luspassen kunnen herhaalde controles verminderen, invarianten uit de lus verplaatsen of patronen herkennen die efficiënter uitgevoerd kunnen worden.
Deze veranderingen zijn bewust conservatief. Een pass voert alleen een herschrijving uit als ze kan bewijzen dat het de betekenis van het programma niet verandert.
Begrijpelijke voorbeelden
Als je programma conceptueel dit doet:
- Een configuratiewaarde elke iteratie van een lus lezen
- Dezelfde berekening op dezelfde inputs op meerdere plaatsen uitvoeren
- Een conditie controleren die in de context altijd waar of onwaar is
…dan probeert LLVM dat om te zetten in “zet de setup één keer”, “hergebruik resultaten” en “verwijder dode takken”. Het is minder magie en meer opruimen.
De echte afweging: compilatietijd versus runtime
Optimalisatie kost iets: meer analyse en meer passes betekent meestal langere compilatietijd, ook al draait het eindprogramma sneller. Daarom bieden toolchains niveaus zoals “beetje optimaliseren” versus “agressief optimaliseren”.
Profielen helpen hierbij. Met profile-guided optimization (PGO) draai je het programma, verzamel je gebruiksdata en compileer je opnieuw zodat LLVM zijn inspanning richt op de paden die echt belangrijk zijn—waardoor de afweging voorspelbaarder wordt.
Backends: veel CPU's bereiken zonder alles opnieuw te schrijven
Go Cross Platform
Maak naast je web- en serverdelen ook een Flutter mobiele app.
Een compiler heeft twee heel verschillende taken. Ten eerste moet hij je broncode begrijpen. Ten tweede moet hij machinecode produceren die een specifieke CPU kan uitvoeren. LLVM-backends richten zich op die tweede taak.
Wat een backend daadwerkelijk doet
Zie LLVM IR als een “universeel recept” voor wat het programma moet doen. Een backend zet dat recept om in de exacte instructies voor een processorfamilie—x86-64 voor de meeste desktops en servers, ARM64 voor veel telefoons en nieuwere laptops, of gespecialiseerde targets zoals WebAssembly.
Concreet is een backend verantwoordelijk voor:
- Instructieselectie: IR-operaties naar echte CPU-instructies mappen
- Registerallocatie: kiezen welke waarden in snelle CPU-registers leven versus in geheugen
- Scheduling: instructies ordenen zodat de CPU ze efficiënt kan uitvoeren
- Assembly/object-output: code uitstoten die de linker en het OS begrijpen
Waarom gedeelde infrastructuur nieuwe hardwareondersteuning makkelijker maakt
Zonder gedeelde kern zou elke taal al dit werk voor elke CPU die ze wil ondersteunen opnieuw moeten implementeren—een enorme hoeveelheid werk en een constante onderhoudslast.
LLVM keert dat om: frontends (zoals Clang) produceren één keer LLVM IR, en backends handelen de “last mile” per target af. Ondersteuning voor een nieuwe CPU betekent meestal het schrijven van één backend (of een bestaande uitbreiden), niet het herschrijven van elke compiler die bestaat.
Portabiliteit voor teams die op meerdere platforms leveren
Voor projecten die moeten draaien op Windows/macOS/Linux, op x86 en ARM, of zelfs in de browser, is het backend-model van LLVM een praktisch voordeel. Je kunt één codebasis en grotendeels één buildpipeline behouden en dan retargeten door een andere backend te kiezen (of cross-compilatie toe te passen).
Die portabiliteit is waarom LLVM overal opduikt: het gaat niet alleen om snelheid—het gaat er ook om te voorkomen dat teams telkens platform-specifiek compilerwerk moeten doen dat alles vertraagt.
Clang: waar veel ontwikkelaars LLVM voor het eerst ervaren
Clang is de C, C++ en Objective-C frontend die op LLVM aansluit. Als LLVM de gedeelde motor is die kan optimaliseren en machinecode genereren, leest Clang je bronbestanden, begrijpt het de taalregels en zet het om in een vorm waar LLVM mee kan werken.
Waarom Clang opviel
Veel ontwikkelaars ontdekten LLVM niet via compilerpapers—ze merkten het de eerste keer dat ze van compiler wisselden en de feedback plotseling verbeterde.
Clang’s diagnostiek staat bekend om betere leesbaarheid en precisie. In plaats van vage fouten wijst het vaak op exact het token dat het probleem veroorzaakte, toont de relevante regel en legt uit wat het verwachtte. Dat scheelt in het dagelijkse werk, omdat de “compileer, fix, repeat”-lus minder frustrerend wordt.
Clang biedt ook schone, goed gedocumenteerde interfaces (onder andere via libclang en het bredere Clang-tooling-ecosysteem). Dat maakte het gemakkelijker voor editors, IDE's en andere ontwikkeltools om diepe taalbegrip te integreren zonder een C/C++-parser opnieuw te schrijven.
Hoe het in dagelijkse workflows verschijnt
Zodra een tool je code betrouwbaar kan parsen en analyseren, krijg je features die minder voelen als tekstbewerking en meer als werken met een gestructureerd programma:
- Nauwkeurige code-navigatie (“ga naar definitie”, “vind referenties”) zelfs in grote, macro-rijke C++ projecten
- Refactoring-ondersteuning die symbolen en scopes begrijpt, niet alleen zoek-en-vervang
- Inline hints en snelle fixes aangedreven door echte syntax- en type-informatie
Daarom is Clang vaak het eerste “aanraakpunt” voor LLVM: het is waar praktische verbeteringen in ontwikkelaarservaring vandaan komen. Zelfs als je nooit nadenkt over LLVM IR of backends, profiteer je nog steeds wanneer de autocomplete slimmer is, statische controles preciezer en build-fouten makkelijker te verhelpen.
Waarom veel moderne talen op LLVM bouwen
LLVM trekt taakteams aan om een eenvoudige reden: het laat hen focussen op de taal in plaats van jaren te besteden aan het opnieuw uitvinden van een volledige optimaliserende compiler.
Snellere time-to-market
Een nieuwe taal bouwen omvat al parsing, typechecking, diagnostics, pakketbeheer, documentatie en community-ondersteuning. Als je daarnaast een productieklare optimizer, codegenerator en platformondersteuning helemaal zelf moet maken, vertraagt dat vaak de release—soms met jaren.
LLVM levert een kant-en-klare compilatiekern: registerallocatie, instructieselectie, volwassen optimalisatiepasses en targets voor gangbare CPU's. Teams kunnen een frontend koppelen die hun taal naar LLVM IR verlaagt en vervolgens vertrouwen op de bestaande pijplijn om native code te produceren voor macOS, Linux en Windows.
Hoge prestaties (zonder heldendaden)
LLVM’s optimizer en backends zijn het resultaat van langjarige engineering en constante test in de praktijk. Dat vertaalt zich in sterke basisprestaties voor talen die het adopteren—vaak goed genoeg in het begin en met ruimte om te verbeteren naarmate LLVM zelf verbetert.
Dat is een reden waarom enkele bekende talen omheen zijn gebouwd:
- Swift gebruikt LLVM om geoptimaliseerde native binaries te genereren op Apple-platforms.
- Rust vertrouwt op LLVM voor codegeneratie en veel architectuurtargets.
- Julia gebruikt LLVM om snelle numerieke code mogelijk te maken, inclusief runtime-compilatie voor gespecialiseerde workloads.
Niet elke taal heeft LLVM nodig
Kiezen voor LLVM is een afweging, geen verplichting. Sommige talen geven prioriteit aan zeer kleine binaries, extreem snelle compilatie of strikte controle over de volledige toolchain. Anderen hebben al gevestigde compilers (zoals GCC-gebaseerde ecosystemen) of verkiezen simpelere backends.
LLVM is populair omdat het een sterk default is—niet omdat het de enige geldige weg is.
JIT en runtime-compilatie: snelle feedbackloops
Ship a Full Stack App
Genereer een React-frontend met een Go- en PostgreSQL-backend in één workflow.
“Just-in-time” (JIT) compilatie kun je het makkelijkst zien als compileren terwijl je runt. In plaats van alle code vooraf te vertalen naar een finale executable, wacht een JIT-engine tot een stuk code nodig is en compileert dat deel on-the-fly—vaak gebruikmakend van echte runtime-informatie (zoals exacte types en datamaten) om betere keuzes te maken.
Waarom JIT snel kan aanvoelen
Omdat je niet alles up-front hoeft te compileren, kunnen JIT-systemen snelle feedback leveren voor interactieve workflows. Je schrijft of genereert een stuk code, voert het meteen uit en het systeem compileert alleen wat nu nodig is. Als die code vaak draait, kan de JIT het gecompileerde resultaat cachen of “hete” secties agressiever hercompileren.
Waar runtime-compilatie in de praktijk helpt
JIT blinkt uit bij dynamische of interactieve workloads:
- REPLs en notebooks: snippets direct evalueren en toch native-snelheid krijgen voor zware lussen.
- Plugins en extensies: applicaties kunnen gebruikerscode laden en compileren voor de host-CPU.
- Dynamische workloads: wanneer inputs sterk variëren, kan runtime-profiling bepalen welke paden optimalisatie verdienen.
- Wetenschappelijk rekenen: gegenereerde kernels (voor specifieke matrixgroottes, modelvormen of hardwarefeatures) kunnen on-demand worden gecompileerd.
LLVM’s rol (zonder de hype)
LLVM maakt niet elk programma automatisch sneller en het is op zichzelf geen complete JIT. Wat het biedt is een toolkit: een goed gedefinieerde IR, een groot aantal optimalisatiepasses en codegeneratie voor veel CPU's. Projecten kunnen JIT-engines bovenop deze bouwstenen bouwen en de juiste afweging kiezen tussen opstarttijd, piekprestaties en complexiteit.
Prestaties, voorspelbaarheid en reële afwegingen
LLVM-gebaseerde toolchains kunnen extreem snelle code produceren—maar “snel” is geen enkele, stabiele eigenschap. Het hangt af van de exacte compiler-versie, het target-CPU, optimalisatie-instellingen en zelfs wat je de compiler laat veronderstellen over het programma.
Waarom “dezelfde bron, verschillende resultaten” voorkomt
Twee compilers kunnen dezelfde broncode lezen en toch merkbaar verschillende machinecode genereren. Dat komt deels doordat elke compiler zijn eigen set optimalisatiepasses, heuristieken en standaardinstellingen heeft. Zelfs binnen LLVM kunnen Clang 15 en Clang 18 verschillende inline-beslissingen nemen, andere lussen vectoriseren of instructies anders schedulen.
Het kan ook veroorzaakt worden door undefined behavior en unspecified behavior in de taal. Als je programma per ongeluk vertrouwt op iets wat de standaard niet garandeert (zoals signed overflow in C), kunnen verschillende compilers—of verschillende flags—resulteren in optimalisaties die de uitkomst veranderen.
Determinisme, debug-builds en release-builds
Mensen verwachten vaak dat compilatie deterministisch is: dezelfde inputs, dezelfde outputs. In de praktijk kom je dichtbij, maar niet altijd identieke binaries over omgevingen heen. Build-paden, timestamps, link-order, profile-gegevens en LTO-keuzes kunnen het eindresultaat beïnvloeden.
Het belangrijkere, praktische onderscheid is debug vs. release. Debug-builds schakelen doorgaans veel optimalisaties uit om stap-voor-stap debuggen en leesbare stacktraces te behouden. Release-builds zetten agressieve transformaties aan die code kunnen herordenen, functies inline kunnen zetten en variabelen kunnen verwijderen—goed voor prestaties, maar soms lastiger om te debuggen.
Praktisch advies: meet, gok niet
Behandel prestaties als een meetprobleem:
- Benchmark op representatieve hardware en met realistische datasets.
- Warm caches op en draai meerdere iteraties.
- Vergelijk builds met expliciete flags (bijv.
-O2vs-O3, LTO aan/uit, of een target selecteren met-march).
Kleine flag-wijzigingen kunnen prestaties in beide richtingen verschuiven. De veiligste werkwijze is: formuleer een hypothese, meet het en houd benchmarks dicht bij wat je gebruikers echt draaien.
Tooling buiten compilatie: analyse, debugging en veiligheid
Go from Build to Live
Breng een gehoste versie live zonder handmatig build-stappen aan elkaar te lijmen.
LLVM wordt vaak beschreven als een compilertoolkit, maar veel ontwikkelaars ervaren de impact via tools die rond compilatie zitten: analyzers, debuggers en veiligheidschecks die je tijdens builds en tests kunt inschakelen.
Analyse en instrumentatie als “add-ons”
Omdat LLVM een heldere intermediate representation (IR) en een pass-pijplijn exposeert, is het logisch om extra stappen te bouwen die code inspecteren of herschrijven voor een ander doel dan snelheid. Een pass kan tellers voor profilering invoegen, verdachte geheugenoperaties markeren of coverage-gegevens verzamelen.
Het kernpunt is dat deze features kunnen worden geïntegreerd zonder dat elk taaktteam dezelfde infrastructuur opnieuw moet bouwen.
Sanitizers: bugs dicht bij de bron vangen
Clang en LLVM populariseerden een familie van runtime-“sanitizers” die programma's instrumenteren om veelvoorkomende bugklassen tijdens testing te detecteren—denk aan out-of-bounds memory access, use-after-free, data races en patronen van undefined behavior. Het zijn geen magische schilden en ze maken programma's meestal trager, dus ze worden vooral in CI en pre-release tests gebruikt. Maar wanneer ze afgaan, wijzen ze vaak naar een precieze bronlocatie met een leesbare uitleg, precies wat teams nodig hebben bij het opsporen van intermitterende crashes.
Betere diagnostiek = snellere onboarding
Kwaliteit van tooling gaat ook over communicatie. Duidelijke waarschuwingen, bruikbare foutmeldingen en consistente debug-info verminderen de “mystery factor” voor nieuwkomers. Als de toolchain uitlegt wat er gebeurde en hoe het op te lossen, besteden ontwikkelaars minder tijd aan het onthouden van compilereigenaardigheden en meer tijd aan het leren van de codebase.
LLVM garandeert op zichzelf geen perfecte diagnostiek of veiligheid, maar het biedt een gemeenschappelijke basis die het praktisch maakt om deze ontwikkelaarsgerichte tools te bouwen, onderhouden en delen over veel projecten.
Wanneer je LLVM zou gebruiken (en wanneer niet)
LLVM is het beste te zien als een “bouw-je-eigen-compiler-en-toolkit”. Die flexibiliteit is precies waarom het zoveel moderne toolchains aandrijft—maar ook waarom het niet altijd de juiste keuze is.
Wanneer LLVM uitstekend past
LLVM blinkt uit wanneer je serieuze compiler-engineering wilt hergebruiken in plaats van het opnieuw uit te vinden.
Als je een nieuwe programmeertaal bouwt, kan LLVM je een bewezen optimalisatiepijplijn, volwassen codegeneratie voor veel CPU's en een route naar goede debug-ondersteuning bieden.
Als je cross-platform applicaties uitbrengt, vermindert LLVM’s backend-ecosysteem het werk om verschillende architecturen te targeten. Je kunt je richten op je taal of productlogica in plaats van aparte codegeneratoren te schrijven.
Als je doel ontwikkelaarstooling is—linters, statische analyse, code-navigatie, refactoring—is LLVM (en het bredere ecosysteem eromheen) een sterke basis omdat de compiler al de code-structuur en types “begrijpt”.
Wanneer het overkill kan zijn
LLVM kan te zwaar zijn als je aan kleine embedded systemen werkt waar buildgrootte, geheugen en compilatietijd streng beperkt zijn.
Het kan ook slecht passen bij zeer gespecialiseerde pipelines waar je geen algemene optimalisaties wilt, of waar je “taal” meer op een vaste DSL lijkt met een rechtstreekse direct-naar-machine-code mapping.
Een eenvoudige checklist
Stel jezelf deze drie vragen:
- Moeten we meerdere platforms/CPU's targeten nu of binnenkort?
- Profiteren we van bestaande optimalisaties en debug-info, in plaats van alles zelf te bouwen?
- Willen we een ecosysteem (tooling, integraties, werving) boven een minimale custom compiler?
Als je op de meeste vragen “ja” hebt geantwoord, is LLVM meestal een praktische gok. Als je vooral de kleinste, simpelste compiler wilt die één specifiek probleem oplost, kan een lichtere aanpak winnen.
Een praktisch noot voor productteams: LLVM’s voordelen zonder compilerexperts te worden
De meeste teams willen LLVM niet als een project adopteren. Ze willen resultaten: cross-platform builds, snelle binaries, goede diagnostiek en betrouwbare tooling.
Dat is één reden waarom platforms zoals Koder.ai in dit verband interessant zijn. Als je workflow steeds meer gestuurd wordt door hogere-level automatisering (planning, scaffolding genereren, itereren in een korte cyclus), profiteer je nog steeds indirect van LLVM via de onderliggende toolchains—of je nu een React-webapp bouwt, een Go-backend met PostgreSQL, of een Flutter mobiele client. Koder.ai’s chat-gedreven “vibe-coding” richt zich op sneller product opleveren, terwijl moderne compilerinfrastructuur (LLVM/Clang en aanverwanten, waar van toepassing) op de achtergrond het onaantrekkelijke werk van optimalisatie, diagnostiek en draagkracht afhandelt.