29 dec 2025·8 min
Beheertools die gegevensverlies voorkomen: veiligere bulkacties
Admin-tools die gegevensverlies voorkomen gebruiken veiliger bulkacties, duidelijke bevestigingen, soft deletes, auditlogs en rolbeperkingen zodat operators kostbare fouten vermijden.
Waar gegevensverlies gebeurt in admin-tools
Interne admin-tools voelen veiliger omdat “alleen personeel” ze gebruikt. Die vertrouwelijkheid is precies waarom ze risicovol zijn. De mensen die ermee werken hebben macht, handelen snel en voeren vaak dezelfde handeling meerdere keren per dag uit. Eén foutje kan duizenden records raken.
De meeste ongelukken zijn niet kwaadwillig. Ze komen door van die “oeps”-momenten: een filter dat te ruim is, een zoekterm die meer matcht dan verwacht, of een dropdown die op de verkeerde tenant bleef staan. Een klassieker is ook de verkeerde omgeving: iemand denkt in staging te zitten, maar kijkt naar productie omdat de UI bijna hetzelfde oogt.
Snelheid en herhaling verergeren dit. Als een tool is gemaakt om snel te werken, leren gebruikers spiergeheugen: klik, bevestig, volgende. Als het scherm traag is, klikt men twee keer. Als een bulkactie tijd kost, opent men een tweede tab. Die gewoonten zijn normaal, maar creëren de voorwaarden voor fouten.
“Gegevens vernietigen” is niet alleen op een delete-knop drukken. In praktijk kan het betekenen:
- Records verwijderen (inclusief cascade deletes)
- Velden overschrijven (bijvoorbeeld status op “closed” zetten voor de verkeerde groep)
- Relaties loskoppelen (een gebruiker van een account ontkoppelen, permissies verwijderen)
- Geschiedenis wissen (logs leegmaken, berichten wissen, tabellen truncaten)
- Irreversibele exports of syncs (verkeerde data naar een ander systeem pushen)
Voor teams die admin-tools bouwen om gegevensverlies te voorkomen, moet “veilig genoeg” een duidelijke afspraak zijn, geen vaag gevoel. Een simpele definitie: een gehaaste operator moet zich kunnen herstellen van een veelvoorkomende fout zonder engineeringhulp, en een zeldzame onomkeerbare actie moet extra wrijving, duidelijke intentie en een auditbaar log vereisen.
Zelfs als je apps snel bouwt met een platform zoals Koder.ai, blijven deze risico's bestaan. Het verschil is of je vanaf dag één vangrails ontwerpt of wacht tot het eerste incident het onderwijs geeft.
Begin met een eenvoudige risicokaart
Voordat je een UI verandert, wees duidelijk over wat er eigenlijk mis kan gaan. Een risicokaart is een korte lijst van handelingen die echt schade kunnen veroorzaken, plus de regels die erbij horen. Deze stap is wat admin-tools die gegevensverlies voorkomen scheidt van tools die alleen maar voorzichtig lijken.
Schrijf eerst je gevaarlijkste acties op. Dat zijn meestal niet de dagelijkse aanpassingen. Het zijn operaties die veel records snel veranderen of gevoelige data aanraken.
Een nuttige eerste inventarisatie is:
- Accounts verwijderen, samenvoegen, sluiten of hard-disable
- Eigendom herverdelen (klanten, facturen, tickets, leads)
- Imports en bulkupdates (CSV, API-jobs, migraties)
- Billing-acties (refunds, credits, annuleringen)
- Permissiewijzigingen (rollen, toegang tot PII)
Markeer elke actie vervolgens als omkeerbaar of onomkeerbaar. Wees streng. Als je hem alleen kunt terugzetten via backup-restore, behandel hem als onomkeerbaar voor de operator die het werk uitvoert.
Bepaal daarna wat door beleid beschermd moet worden, niet alleen door design. Juridische en privacyregels gelden vaak voor PII (namen, e-mails, adressen), facturatiegegevens en auditlogs. Ook al kan een tool technisch iets verwijderen, het beleid kan retentie of een twee-persoons-review vereisen.
Scheid routinematig werk van uitzonderlijke handelingen. Routinematig werk moet snel en veilig zijn (kleine wijzigingen, duidelijke undo). Uitzonderlijke werkzaamheden mogen langzaam zijn met opzet (extra checks, goedkeuringen, strakkere limieten).
Tot slot: spreek eenvoudige termen voor “blast radius” af zodat iedereen dezelfde taal gebruikt: één record, veel records, alle records. Bijvoorbeeld: “herassign dit ene klantaccount” verschilt van “herassign alle klanten van deze sales rep.” Dat label stuurt later je defaults, bevestigingen en rol-limieten.
Voorbeeld: in een vibe-coding project op Koder.ai tag je misschien “bulk import users” als many-records, alleen omkeerbaar als je elke gemaakte ID logt, en policy-protected omdat het PII raakt.
Patronen voor veiligere bulkacties
Bulkacties zijn waar goede admin-tools risicovol worden. Als je admin-tools bouwt die gegevensverlies voorkomen, behandel elke “apply to many”-knop als een krachtig gereedschap: nuttig, maar ontworpen om uitglijders te vermijden.
Een sterk uitgangspunt is eerst een preview, daarna uitvoeren. Voer niet direct uit; toon wat er zou veranderen en laat de operator pas bevestigen nadat ze de scope zien.
Maak de scope expliciet en moeilijk misbaar. Accepteer niet “alles” als vaag begrip. Forceer de operator filters te definiëren zoals tenant, status en datumbereik, en toon vervolgens het exacte aantal records dat matcht. Een kleine samplelijst (al 10 items) helpt mensen fouten te zien zoals “verkeerde regio” of “gearchiveerde items meegeteld.”
Een praktisch patroon dat goed werkt:
- Begin met een dry run-scherm dat aantal, filters en een korte sample van getroffen records toont
- Vereis een expliciete scope-keuze (bijvoorbeeld: “Alleen Active customers in Tenant A, created before 2024-01-01”)
- Limiteer elke run (bijvoorbeeld 1.000 records) en vraag om opnieuw te starten voor het volgende batch
- Demp wijzigingen zodat één foutklik de database of downstream systemen niet overspoelt
- Laat het als een queued job draaien met voortgang, logs en een duidelijke annuleer-optie
Queued jobs verslaan “vuur-en-vergeet” omdat ze een papierpad creëren en de operator de kans geven te stoppen als er iets mis lijkt bij 5% voltooiing.
Voorbeeld: een operator wil in bulk accounts disablen na een fraudespike. De preview toont 842 accounts, maar de sample bevat VIP-klanten. Dat kleine signaal voorkomt vaak de echte fout: een filter miste “fraud_flag = true.”
Als je snel een interne console in elkaar zet (zelfs met een build-by-chat platform zoals Koder.ai), veranker deze patronen vroeg. Ze besparen meer tijd dan ze kosten.
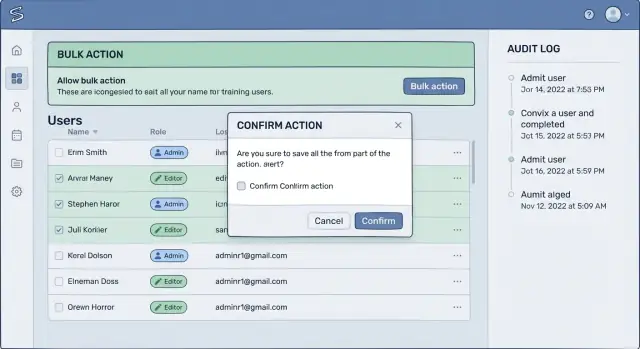
Bevestigingsflows die mensen echt lezen
De meeste bevestigingen falen omdat ze te generiek zijn. Als het scherm “Weet je het zeker?” zegt, klikken mensen automatisch door. Een bevestiging die werkt gebruikt dezelfde woorden die je gebruiker zou gebruiken om de uitkomst aan een collega uit te leggen.
Vervang vage labels zoals “Delete” of “Apply” door de werkelijke impact: “Deactivate 38 accounts”, “Remove access for this tenant” of “Void 12 invoices”. Dit is een van de eenvoudigste verbeteringen om gegevensverlies te voorkomen, omdat het een reflex-klik verandert in een moment van herkenning.
Laat de gebruiker de scope bevestigen
Een goede flow dwingt een korte mentale check af: “Is dit het juiste, op de juiste set records?” Zet de scope in de bevestiging, niet alleen op de pagina erachter. Neem de tenant- of workspace-naam op, het recordaantal en eventuele filters zoals datumbereik of status.
Bijvoorbeeld: “Close accounts for Tenant: Acme Retail. Count: 38. Filter: last login before 2024-01-01.” Als één van die waarden vreemd lijkt, ziet de gebruiker het vóórdat er schade ontstaat.
Als de actie echt destructief is, vereist het een kleine, doelbewuste handeling. Getypte bevestigingen werken goed als de kost van een fout hoog is.
- Vraag om een korte frase zoals TYP VERWIJDER 38 ACCOUNTS
- Of vraag precies de tenantnaam te typen
- Of laat ze het op het scherm getoonde aantal opnieuw invoeren
Gebruik twee stappen alleen bij hoge impact
Twee-stappen-bevestigingen moeten zeldzaam zijn, anders negeren gebruikers ze. Bewaar ze voor acties die moeilijk te herstellen zijn, tenant-overstijgend, of geld raken. Stap één bevestigt intentie en scope. Stap twee bevestigt timing, zoals “Run now” vs “Schedule”, of vereist een hogere permissie of goedkeuring.
Vermijd tenslotte “OK/Cancel”. Knoppen moeten zeggen wat er gebeurt: “Deactivate accounts” en “Go back”. Dat vermindert verkeerde klikken en maakt de beslissing concreet.
Soft deletes, restores en retentieregels
Oefen met rollback
Test destructieve flows met snapshots zodat je na een “oeps” run kunt herstellen.
Soft delete is voor de meeste user-facing records de veiligste default: accounts, bestellingen, tickets, berichten en zelfs uitbetalingen. In plaats van de rij te verwijderen, markeer je hem als verwijderd en verberg je hem in normale weergaven. Dit is één van de eenvoudigste patronen achter admin-tools die gegevensverlies voorkomen, omdat fouten omkeerbaar worden.
Een soft delete-beleid heeft een duidelijke retentietijd en duidelijk eigenaarschap nodig. Bepaal hoe lang verwijderde items herstelbaar blijven (bijvoorbeeld 30 of 90 dagen), en wie ze mag terugzetten. Koppel restore-rechten aan rollen, niet aan individuele personen, en behandel restores als productie-wijzigingen.
Maak herstellen duidelijk (en gelogd)
Herstel moet makkelijk te vinden zijn wanneer iemand naar een verwijderd record kijkt, niet weggestopt in een apart scherm. Voeg een zichtbare status toe zoals “Deleted”, toon wanneer het gebeurde en wie het deed. Log een restore als een eigen event, niet als een edit op de originele delete.
Een snelle manier om je retentieregels te definiëren is deze vragen te beantwoorden:
- Wat is de standaard retentieperiode per objecttype?
- Welke rol kan herstellen, en moeten ze een reden opgeven?
- Wat gebeurt er na het verstrijken van de retentieperiode?
- Wie kan retentie verlengen voor juridische of billingzaken?
- Hoe handel je “verwijder mijn gegevens”-verzoeken af?
Randgevallen die herstel breken
Soft delete klinkt simpel totdat je terugzet in een wereld die intussen verder is gegaan. Unieke constraints kunnen botsen (een gebruikersnaam is hergebruikt), referenties kunnen ontbreken (een parent record is verwijderd), en facturatiegeschiedenis moet consistent blijven ook als de gebruiker “weg” is. Een praktische aanpak is immutable ledgers (facturen, betaalgebeurtenissen) gescheiden te houden van profieldata, en relaties voorzichtig te herstellen met duidelijke waarschuwingen als volledig herstel niet mogelijk is.
Hard delete moet zeldzaam en expliciet zijn. Als je het toestaat, laat het voelen als uitzondering, met een korte goedkeuringsroute:
- Vereis een hogere rol dan soft delete
- Vraag om een getypte bevestiging en een reden
- Zet de delete in de queue met vertraging (bijvoorbeeld 24 uur)
- Waarschuw een eigenaar of on-call kanaal
- Bewaar een laatste auditrecord zelfs na verwijdering
Als je je admin bouwt op een platform zoals Koder.ai, definieer soft delete, restore en retentie vroeg als first-class acties zodat ze consistent zijn over elk gegenereerd scherm en workflow.
Auditability: maak acties later verklaarbaar
Ongelukken gebeuren in adminpanelen, maar de echte schade komt vaak later: niemand kan beantwoorden wat er veranderde, wie het deed en waarom. Als je admin-tools wilt die gegevensverlies voorkomen, behandel auditlogs als onderdeel van het product, niet als een debug-na-dacht.
Begin met het loggen van acties op een manier die een mens kan lezen. “User 183 updated record 992” is niet genoeg wanneer een klant boos is en de on-call persoon het snel wil oplossen. Goede logs leggen identiteit, timing, scope en intent vast, plus voldoende detail om terug te draaien of de impact te begrijpen.
Wat je moet registreren (zodat het later nuttig is)
Een praktisch minimum is:
- Wie het deed (gebruiker, rol en impersonatie-info als gebruikt)
- Wat en waar (actienaam, tenant/account en getroffen objecttypes)
- Wanneer en van waar (timestamp, timezone, IP of device/session ID)
- Wat er veranderde (voor/na voor sleutelvelden, of een diff voor grotere objecten)
- Waarom het gebeurde (vrije-tekst reden en optionele ticket-/referentie-ID)
Bulkacties verdienen speciale behandeling. Log ze als één “job” met een duidelijke samenvatting (hoeveel geselecteerd, hoeveel gelukt, hoeveel gefaald), en bewaar ook per-item resultaten. Zo kun je makkelijk antwoorden op “Hebben we 200 orders terugbetaald of slechts 173?” zonder door een muur van regels te moeten graven.
Maak logs makkelijk doorzoekbaar: op admin-gebruiker, tenant, actietype en tijdsbereik. Voeg filters toe voor “bulk jobs only” en “high-risk actions” zodat reviewers patronen zien.
Maak van logs geen bureaucratie. Een korte “reden”-veld dat templates ondersteunt (“Klant gevraagd sluiting”, “Fraudeonderzoek”) wordt vaker ingevuld dan een lang formulier. Als er een supportticket is, laat mensen het ID plakken.
Plan tenslotte leesrechten. Veel interne gebruikers moeten logs kunnen bekijken, maar slechts een kleine groep mag gevoelige velden zien (zoals volledige voor/na-waarden). Scheid “kan audit-samenvattingen bekijken” van “kan details bekijken” om blootstelling te beperken.
Rolgebaseerde limieten en guardrails
De meeste ongelukken gebeuren omdat permissies te ruim zijn. Als iedereen effectief admin is, kan een vermoeide operator met één klik permanente schade aanrichten. Het doel is simpel: maak het veilige pad de default en laat risicovolle acties extra intentie vereisen.
Ontwerp rollen rondom echte taken, niet titels. Een supportagent die tickets beantwoordt heeft niet dezelfde toegang nodig als iemand die billingregels beheert.
Bouw rollen rond taken
Begin met het scheiden van wat mensen kunnen zien van wat ze kunnen veranderen. Een praktisch set interne rollen kan eruitzien als:
- Read-only: bekijk gebruikers, orders en logs
- Operator: pas profielen aan en reset wachtwoorden
- Billing operator: geef refunds binnen een limiet uit
- Data steward: merge records en voer bulkfixes uit
- Security admin: disable accounts en beheer rollen
Dit houdt “delete” uit het dagelijkse werk en verkleint de blast radius wanneer iemand een fout maakt.
Voor de gevaarlijkste acties, voeg een elevated mode toe. Zie het als een tijdgebonden sleutel. Om elevated mode in te gaan, vereis je een sterkere stap (re-auth, manager approval of een tweede persoon) en laat je het automatisch terugvallen na 10 tot 30 minuten.
Omgevings-guardrails helpen ook. De UI moet het moeilijk maken staging met productie te verwarren. Gebruik luide visuele cues, toon de omgevingsnaam in elke header en schakel destructieve acties in niet-productie uit tenzij je ze expliciet inschakelt.
Bescherm tenants ook van elkaar. In multi-tenant systemen moeten cross-tenant wijzigingen standaard geblokkeerd zijn en alleen mogelijk voor specifieke rollen met een expliciete tenant-switch en duidelijke on-screen bevestiging.
Als je bouwt op een platform zoals Koder.ai, behandel deze guardrails als productfeatures, geen bijzaak. Admin-tools die gegevensverlies voorkomen zijn vaak gewoon goede permissieontwerpen plus een paar goed geplaatste drempels.
Een realistisch scenario: bulk refunds en accountsluitingen
Maak verwijderen omkeerbaar
Implementeer soft deletes en restores met duidelijke retentieverblijven voor veiligere operaties.
Een supportagent moet een betalingsstoring afhandelen. Het plan is simpel: terugbetalen van getroffen orders en daarna sluiten van accounts die annuleerden. Dit is precies waar admin-tools die gegevensverlies voorkomen zich bewijzen, want de agent staat op het punt twee high-impact bulkacties achter elkaar te draaien.
Het risico zit in één klein detail: het filter. De agent selecteert “Orders created last 24 hours” in plaats van “Orders paid during outage window.” Op een drukke dag kan dat duizenden normale klanten meenemen en ongevraagde refunds triggeren. Als de volgende stap is “Close accounts for refunded orders”, verspreidt de schade zich snel.
Voordat de tool iets uitvoert, moet de UI een pauze forceren met een duidelijke preview die toont hoe mensen denken, niet hoe de database denkt. Bijvoorbeeld het moet tonen:
- Totaal accounts die gesloten worden (en hoeveel al gesloten zijn)
- Totaal terugbetaald bedrag, plus min/max refundgroottes
- Een kleine, scrollbare sample van getroffen klanten (namen, e-mails, order-ID's)
- Uitzonderingen en overslagen (mislukte betalingen, al terugbetaald, betwiste orders)
- De exacte filter-samenvatting in platte taal, met een duidelijke “Edit filter”-knop
Voeg dan een tweede, aparte bevestiging toe voor accountsluiting, omdat dat een andere soort schade is. Een goed patroon is het vereisen van het typen van een korte frase zoals “CLOSE 127 ACCOUNTS” zodat de agent merkt als het getal vreemd is.
Als “close account” een soft delete is, is herstel realistisch. Je kunt accounts terugzetten, logins geblokkeerd houden en een retentieregel instellen (bijv. auto-purge na 30 dagen) zodat het niet permanent rommel wordt.
Auditlogs maken cleanup en onderzoek later mogelijk. De manager moet kunnen zien wie het draaide, het exacte filter, de preview-totals die destijds getoond werden en de lijst van getroffen records. Rolverdelingen zijn ook belangrijk: agents kunnen refunds doen tot een daglimiet, maar alleen een manager kan accounts sluiten of sluitingen boven een drempel goedkeuren.
Als je dit soort console in Koder.ai bouwt, zijn features zoals snapshots en rollback nuttige extra vangrails, maar de eerste verdedigingslinie blijft preview, bevestigingen en rollen.
Stapsgewijs: retrofit veiligheid in een bestaande admin
Retrofitting werkt het beste wanneer je je admin als een product behandelt, niet als een stapel interne pagina's. Kies eerst één high-risk workflow (zoals bulk user disables) en ga dan stap voor stap te werk.
Een praktisch retrofitplan
Begin met het opsommen van schermen en endpoints die kunnen verwijderen, overschrijven of geldbewegingen triggeren. Neem “verborgen” risico's op zoals CSV-imports, bulk edits en scripts die operators vanuit de UI draaien.
Maak bulkacties daarna veiliger door scope en preview te forceren. Toon precies welke records de filters matchen, hoeveel er wijzigen en een kleine sample van IDs vóór de actie draait.
Vervang vervolgens waar mogelijk hard deletes door soft delete. Sla een deleted-flag op, wie het deed en wanneer. Voeg een restore-pad toe dat net zo makkelijk is als delete, plus duidelijke retentieregels (bijv. “restorebaar voor 30 dagen”).
Daarna voeg je een auditlog toe en ga je met operators zitten om echte entries te reviewen. Als een logregel niet kan beantwoorden “wat veranderde, van wat naar wat, en waarom”, helpt het niet bij incidenten.
Tenslotte verscherp je rollen en voeg je goedkeuringen toe voor high-impact acties. Laat support refunds doen tot een klein limiet, maar eis een tweede persoon voor grote bedragen of accountsluitingen. Zo blijven admin-tools die gegevensverlies voorkomen bruikbaar zonder eng te zijn.
Kort voorbeeld
Een operator moet 200 inactieve accounts sluiten. Vóór de wijziging klikken ze op “Delete” en vertrouwen dat filters kloppen. Na retrofit moeten ze het exacte query bevestigen (“status=inactive, last_login>365d”), het aantal en een samplelijst bekijken, kiezen voor “Close (restorable)” in plaats van delete en een reden invoeren.
Een goed “done”-standaard is:
- Je kunt het getroffen set previewen en exporteren vóór uitvoering.
- Je kunt undo-en (restore of rollback) binnen een bepaalde termijn.
- Elke actie is toerekenbaar aan een persoon en een reden.
- High-impact acties worden gelimiteerd op rol of vereisen goedkeuring.
Als je interne tools bouwt in een chat-gedreven platform zoals Koder.ai, maak deze guardrails als herbruikbare componenten zodat nieuwe admin-pagina's veiliger starten.
Veelgemaakte fouten die nog steeds tot ongelukken leiden
Preview voordat je runt
Voeg een dry-run stap toe die filters, recordaantallen en een sample toont vóór uitvoering.
Veel teams bouwen admin-tools die in theorie gegevensverlies voorkomen, maar verliezen toch data in praktijk omdat veiligheidsfuncties makkelijk te negeren of lastig te gebruiken zijn.
De meest voorkomende val is een one-size-fits-all bevestiging. Als elke actie dezelfde “Weet je het zeker?”-tekst toont, stoppen mensen met lezen. Nog erger: teams voegen meer bevestigingen toe om fouten te “fixen”, wat trainers gebruikers aanzet sneller te klikken.
Een ander probleem is ontbrekende context op het moment dat het ertoe doet. Een destructieve actie moet duidelijk tonen in welke tenant of workspace je zit, of dit productie is of een testomgeving, en hoeveel records geraakt worden. Als die informatie ergens anders verborgen zit, vraagt de tool stilletjes om een slechte dag.
Bulkacties zijn ook gevaarlijk als ze onmiddellijk draaien zonder tracking. Operators hebben een duidelijke job-record nodig: wat draaide, op welk filter, wie startte het en wat deed het systeem bij errors. Zonder dat kun je niet pauzeren, undo-en of zelfs verklaren wat er gebeurde.
Hier zijn terugkerende fouten:
- Dezelfde bevestigingstekst gebruiken voor deletes, refunds en permissiewijzigingen
- Zoveel bevestigingen toevoegen dat mensen er doorheen klikken
- Geen recordaantal, tenant en omgeving tonen op het bevestigingsscherm
- Bulkacties meteen laten lopen zonder preview, jobpagina of stopoptie
- Auditlogs bewaren, maar ze niet doorzoekbaar maken op gebruiker, record of tijd
Een snel voorbeeld: een operator wil 12 accounts deactiveren in een sandbox-tenant, maar de tool onthoudt de laatst gebruikte tenant en verbergt die in de header. Ze draaien een bulkactie die meteen uitvoert en het enige “log”-item is vaag als “bulk update completed.” Tegen de tijd dat iemand het opmerkt, kun je niet makkelijk terugzien wat er veranderde of herstellen.
Goede veiligheid is niet meer popups. Het is duidelijke context, betekenisvolle bevestigingen en acties die je kunt volgen en terugdraaien.
Korte checklist en vervolgstappen
Voordat je een destructieve actie uitrolt, doe een laatste check met frisse blik. De meeste admin-incidenten gebeuren wanneer een tool iemand iets laat doen op de verkeerde scope, de echte impact verbergt of geen duidelijke weg terug biedt.
Hier is een pre-flight checklist voor admin-tools die gegevensverlies voorkomen:
- Scope + preview: toon exact wat verandert (wie, wat, waar). Voeg een leesbare preview en een sample van records toe.
- Aantallen + limieten: toon het totaal aantal items en leg redelijke caps en rate limits op zodat één klik niet “alles” raakt.
- Contextchecks: laat de operator tenant/account, omgeving (prod vs test) bevestigen en voeg een korte reden toe die in de logs verschijnt.
- Herstelpaden: geef waar mogelijk de voorkeur aan soft delete, controleer dat de restore-flow werkt en definieer retentie.
- Verantwoordelijkheid: log wie wat deed, wanneer, van waar en met welke filters. Maak logs doorzoekbaar en zorg dat rollen overeenkomen met verantwoordelijkheden.
Als operator: pauzeer tien seconden en lees het gereedschap terug: “Ik voer actie uit op tenant X, verander N records, in productie, om reden Y.” Als iets onduidelijk voelt, stop en vraag om een veiligere UI voordat je de actie draait.
Vervolgstappen: prototypeer veilige flows snel in Koder.ai met Planning Mode om eerst de schermen en guardrails te schetsen. Gebruik tijdens testen snapshots en rollback zodat je echte randgevallen kunt proberen zonder angst. Zodra de flow solide voelt, exporteer de broncode en deploy wanneer je klaar bent.