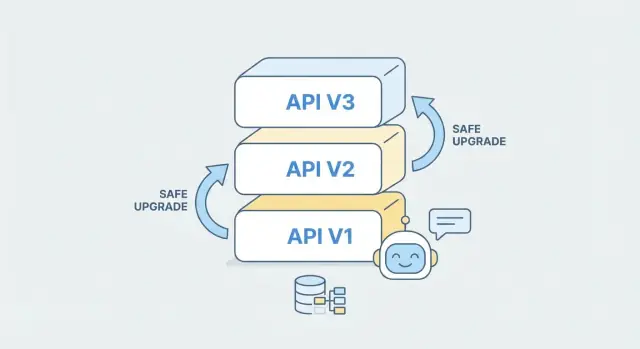
Wat API-evolutie betekent voor door AI gegenereerde backends
API-evolutie is het voortdurende proces van het wijzigen van een API nadat er al echte clients gebruik van maken. Dat kan het toevoegen van velden, aanpassen van validatieregels, verbeteren van performance of het introduceren van nieuwe endpoints betekenen. Het wordt pas echt belangrijk zodra clients in productie draaien, omdat zelfs een "kleine" wijziging een mobiele app-release, een integratiescript of een partnerworkflow kan breken.
Achterwaartse compatibiliteit, eenvoudig uitgelegd
Een wijziging is achterwaarts compatibel als bestaande clients blijven werken zonder updates.
Bijvoorbeeld, stel dat je API dit retourneert:
{ "id": "123", "status": "processing" }
Het toevoegen van een nieuw optioneel veld is typisch achterwaarts compatibel:
{ "id": "123", "status": "processing", "estimatedSeconds": 12 }
Oudere clients die onbekende velden negeren blijven werken. Daarentegen zijn het hernoemen van status naar state, het veranderen van een type (string → number) of het verplicht maken van een eerder optioneel veld veelvoorkomende breaking changes.
Wat “door AI gegenereerde backend” hier betekent
Een door AI gegenereerde backend is niet alleen een codefragment. In de praktijk omvat het:
- Gegeneerde API-code (handlers, controllers, serializers)
- Configuratie (routing, auth-regels, rate limits)
- Infrastructuur-koppelingen (migraties, deployment-templates, omgevingsinstellingen)
Omdat AI delen van het systeem snel kan regenereren, kan de API "driften" tenzij je wijzigingen actief beheert.
Dit geldt vooral wanneer je hele apps genereert vanuit een chatgestuurde workflow. Bijvoorbeeld, Koder.ai (een vibe-coding platform) kan web-, server- en mobiele applicaties maken vanuit een simpele chat—vaak met React voor web, Go + PostgreSQL op de backend en Flutter voor mobiel. Die snelheid is fantastisch, maar het maakt contractdiscipline (en geautomatiseerde diff/tests) nog belangrijker zodat een geregenereerde release niet per ongeluk verandert waar clients op vertrouwen.
Wat geautomatiseerd kan worden vs. wat menselijke review nodig heeft
AI kan veel automatiseren: OpenAPI-specs produceren, boilerplate code bijwerken, veilige defaults voorstellen en zelfs migratiestappen opstellen. Maar menselijke review blijft essentieel voor beslissingen die contracten met clients raken—welke wijzigingen zijn toegestaan, welke velden zijn stabiel en hoe om te gaan met randgevallen en bedrijfsregels. Het doel is snelheid met voorspelbaar gedrag, niet snelheid ten koste van verrassingen.
Waarom achterwaartse compatibiliteit topprioriteit is
API's hebben zelden één enkele "client." Zelfs een klein product kan meerdere afnemers hebben die van dezelfde endpoints afhankelijk zijn:
- Een webapp die continu wordt geleverd
- Een mobiele app die via app stores langzamer bijwerkt
- Partnerintegraties (vaak in bezit van andere teams of bedrijven)
- Interne services en automatiseringen (billing, analytics, supporttools)
Wanneer een API breekt, is de kost niet alleen ontwikkeltijd. Mobiele gebruikers kunnen weken op oudere appversies blijven, dus een breaking change kan uitlopen tot een lange staart van fouten en supporttickets. Partners kunnen downtime ervaren, data missen of kritieke workflows stoppen—vaak met contractuele of reputatieschade tot gevolg. Interne services kunnen stilletjes falen en rommelige backlogs veroorzaken (bijv. missende events of onvolledige records).
Door AI gegenereerde backends voegen een twist toe: code kan snel en frequent veranderen, soms met grote diffs, omdat generatie is geoptimaliseerd om werkende code te produceren—niet per se om gedrag over tijd te behouden. Die snelheid is waardevol, maar verhoogt ook het risico op onbedoelde breaking changes (hernoemde velden, andere defaults, strengere validatie, nieuwe auth-vereisten).
Daarom moet achterwaartse compatibiliteit een weloverwogen productbeslissing zijn, geen goodwill-activiteit. De praktische aanpak is een voorspelbaar wijzigingsproces definiëren waarbij de API als productinterface wordt behandeld: je mag mogelijkheden toevoegen, maar je verrast bestaande clients niet.
Een nuttig mentaal model is het API-contract (bijv. een OpenAPI-spec) als de "source of truth" te beschouwen voor wat clients kunnen verwachten. Generatie wordt dan een implementatiedetail: je kunt de backend regenereren, maar het contract—en de beloften die het doet—blijft stabiel tenzij je doelbewust versoepelt en communiceert.
Het API-contract als de source of truth
Als een AI-systeem backendcode snel kan genereren of aanpassen, is het enige betrouwbare anker het API-contract: de geschreven beschrijving van welke calls clients kunnen doen, wat ze moeten sturen en wat ze terug kunnen verwachten.
Wat “contract” in de praktijk betekent
Een contract is een machine-leesbare specificatie zoals:
- OpenAPI voor REST-endpoints (paths, parameters, auth, response-structuren)
- JSON Schema voor het valideren van request/response payloads (vaak ingebed in OpenAPI)
- GraphQL schema voor types, queries, mutaties en deprecations
Dit contract is wat je belooft aan externe consumenten—ook als de implementatie erachter verandert.
Contract-first vs. code-first (en waar generators passen)
In een contract-first workflow ontwerp of update je eerst de OpenAPI/GraphQL-schema, en genereer je dan serverstubs en vul je de logica in. Dit is doorgaans veiliger voor compatibiliteit omdat wijzigingen intentioneel en reviewbaar zijn.
In een code-first workflow wordt het contract geproduceerd uit code-annotaties of runtime-introspectie. Door AI gegenereerde backends neigen vaak van nature naar code-first, wat prima is—zolang de gegenereerde contracten als een artefact worden gereviewd, niet als bijzaak.
Een praktisch hybride: laat de AI codewijzigingen voorstellen, maar vereis dat het ook de contracten bijwerkt (of regenereert), en behandel contractdiffs als het belangrijkste wijzigingssignaal.
Leg het contract onder versiebeheer
Sla je API-specs op in dezelfde repo als de backend en review ze in pull requests. Een simpele regel: geen merge tenzij de contractwijziging begrepen en goedgekeurd is. Zo worden achterwaarts-incompatibele edits vroeg zichtbaar, voordat ze productie bereiken.
Genereer zowel server als clients vanuit één bron
Om drift te verminderen: genereer serverstubs en client-SDKs vanuit hetzelfde contract. Wanneer het contract wordt geüpdatet, updaten beide zijden samen—waardoor het veel lastiger wordt voor een door AI gegenereerde implementatie om gedrag te "uitvinden" waar clients niet op gebouwd zijn.
Versioneringsstrategieën die in de praktijk werken
API-versionering gaat niet om het voorspellen van elke toekomstige wijziging—het gaat om clients een duidelijke, stabiele manier geven om te blijven werken terwijl je de backend verbetert. In de praktijk is de "beste" strategie degene die je consumenten direct begrijpen en je team consequent kan toepassen.
Veelvoorkomende strategieën (en hoe ze voelen voor clients)
URL-versionering plaatst de versie in het pad, zoals /v1/orders en /v2/orders. Het is zichtbaar in elk verzoek, makkelijk te debuggen en werkt goed met caching en routing.
Header-versionering houdt URL's schoon en zet de versie in een header (bijv. Accept: application/vnd.myapi.v2+json). Dat kan elegant zijn, maar is minder duidelijk tijdens troubleshooting en kan gemist worden in gekopieerde voorbeelden.
Query-parameter versionering gebruikt iets als /orders?version=2. Het is rechttoe rechtaan, maar kan rommelig worden als clients of proxies querystrings verwijderen/wijzigen, en het is makkelijker voor mensen om per ongeluk versies te mixen.
Een standaardaanbeveling
Voor de meeste teams—vooral als je wilt dat clients het makkelijk begrijpen—standaardiseer op URL-versionering. Het is de minst verrassende aanpak, makkelijk te documenteren en maakt duidelijk welke versie een SDK, mobiele app of partner-integratie aanroept.
Hoe door AI gegenereerde backends kunnen helpen
Wanneer je AI gebruikt om een backend te genereren of uit te breiden, behandel elke versie als een aparte "contract + implementatie"-eenheid. Je kunt een nieuwe /v2 scaffolden vanaf een bijgewerkte OpenAPI-spec terwijl je /v1 intact houdt, en waar mogelijk businesslogica delen. Dit vermindert risico: bestaande clients blijven werken, terwijl nieuwe clients v2 doelbewust adopteren.
Documentatie en wijzigingscommunicatie
Versionering werkt alleen als je docs bijblijven. Houd versioned API docs bij, zorg dat voorbeelden per versie consistent zijn en publiceer een changelog die duidelijk zegt wat er is veranderd, wat is gedepreceerd en migratienotities bevat (bij voorkeur met zij-aan-zij request/response voorbeelden).
Compatibele vs. breaking wijzigingen: een praktische checklist
Wanneer een door AI gegenereerde backend update, is de veiligste manier om over compatibiliteit te denken: "Blijft een bestaande client werken zonder wijzigingen?" Gebruik de checklist hieronder om wijzigingen te classificeren voordat je ze uitrolt.
Meestal compatibele (additieve) wijzigingen
Deze wijzigingen breken doorgaans geen bestaande clients omdat ze niet ongeldig maken wat clients al sturen of verwachten:
- Nieuwe optionele response-velden (bijv.
middleName of metadata). Oudere clients blijven werken zolang ze onbekende velden negeren.
- Nieuwe endpoints (of nieuwe methods op een ander pad). Niets verandert voor het bestaande.
- Nieuwe optionele request-velden die de server kan negeren of behandelen met defaults.
- Uitgebreide enums in responses (clients moeten onbekende waarden defensief afhandelen).
Meestal breaking (risicovolle) wijzigingen
Behandel deze als breaking tenzij je sterk bewijs hebt dat het veilig is:
- Velden of endpoints verwijderen, of stoppen met support voor een requestveld dat clients nu sturen.
- Velden hernoemen (zelfs met dezelfde betekenis). Veel clients mappen op naam.
- Typewijzigingen (string → number, object → array,
nullable → non-nullable).
- Gedragswijzigingen: andere defaults, sortering, paginatiesemantiek, gewijzigde validatieregels.
- Aanscherpen van constraints: optioneel → verplicht, maximale lengte verkleinen, geaccepteerde formaten wijzigen.
“Tolerant readers” als je compatibiliteitsbasis
Moedig clients aan om tolerante lezers te zijn: negeer onbekende velden en handel onverwachte enumwaarden netjes af. Dit maakt het mogelijk dat de backend evolueert door velden toe te voegen zonder dat clients moeten updaten.
Hoe AI-generators de regels moeten afdwingen
Een generator kan onbedoelde breaking changes voorkomen via beleid:
- Blokkeer merges als OpenAPI-diffs veldverwijdering, hernoemingen of typewijzigingen bevatten zonder versiebump.
- Vereis dat elke breaking wijziging eerst als nieuwe velden/endpoints wordt geïntroduceerd, met deprecatie-notices op oude.
- Geef waarschuwingen bij het toevoegen van response-enums of wijzigen van defaults, en vraag een compatibiliteitsreview.
Database- en schemamigraties zonder clients te breken
Veiliger schema-wijzigingen
Prototypeer migraties met expand-migrate-contract stappen en houd oudere clients werkend tijdens rollouts.
API-wijzigingen zijn wat clients zien: request/response-vormen, veldnamen, validatieregels en foutgedrag. Database-wijzigingen zijn wat je backend opslaat: tabellen, kolommen, indexen, constraints en dataformaten. Ze zijn verwant, maar niet identiek.
Een veelgemaakte fout is een DB-migratie als "interne wijziging" behandelen. In door AI gegenereerde backends wordt de API-laag vaak gegenereerd van het schema (of is er een sterke koppeling), dus een schemawijziging kan stilletjes een API-wijziging worden. Zo breken oudere clients, ook als je de API niet bewust wilde aanpassen.
Een veilig migratiepatroon (expand → migrate → contract)
Gebruik een multi-step aanpak die zowel oude als nieuwe codepaden laat werken tijdens rolling upgrades:
- Add: introduceer nieuwe kolommen/tabellen zonder bestaande te verwijderen of hernoemen.
- Backfill: vul nieuwe velden voor bestaande rijen (in batches indien nodig).
- Dual-write: laat de backend naar oude en nieuwe locaties schrijven.
- Switch reads: begin te lezen vanaf de nieuwe bron terwijl je nog steeds dual-write doet.
- Clean up: verwijder legacy-velden pas nadat alle clients zijn geüpdatet en oude code weg is.
Dit patroon voorkomt "big bang" releases en geeft rollback-opties.
Defaults, nulls en "ontbrekende" velden
Oudere clients gaan er vaak van uit dat een veld optioneel is of een stabiele betekenis heeft. Bij het toevoegen van een nieuwe non-null kolom kies je tussen:
- een server-side default die gedrag behoudt, of
- tijdelijk NULL toestaan en het expliciet in de API-laag afhandelen.
Wees voorzichtig: een DB-default helpt niet altijd als je API-serializer nog steeds null uitzendt of validatieregels verandert.
Door AI gegenereerde migraties: behulpzaam, niet automatisch
AI-tools kunnen migratiescripts opstellen en backfills voorstellen, maar menselijke validatie blijft nodig: bevestig constraints, controleer performance (locks, index builds) en voer migraties uit tegen staging-data om zeker te zijn dat oudere clients blijven werken.
Feature flags en geleidelijke uitrol voor veiliger updates
Feature flags laten je gedrag veranderen zonder de endpoint-vorm te veranderen. Dat is vooral nuttig in door AI gegenereerde backends, waar interne logica vaak regenereren of optimaliseren, maar clients nog steeds van consistente requests en responses afhankelijk zijn.
In plaats van een grote release, ship je het nieuwe codepad uitgeschakeld, en schakel je het geleidelijk in. Als er iets misgaat, zet je het uit—zonder een nood-deploy.
Hoe geleidelijke uitrol werkt
Een praktisch rollout-plan combineert meestal drie technieken:
- Canary release: zet het nieuwe gedrag eerst voor een kleine slice van het verkeer (of één tenant) aan.
- Percentage-based rollout: verhoog exposure van 1% → 10% → 50% → 100%, en houd error rates en clientimpact in de gaten.
- Fast rollback plan: definieer van tevoren welke metrics rollback triggeren (bijv. 5xx-rate, validatiefouten, supporttickets) en maak de flag binnen enkele minuten omkeerbaar.
Voor API's is het belangrijk om responses stabiel te houden terwijl je intern experimenteert. Je kunt implementaties verwisselen (nieuw model, nieuwe routinglogica, nieuwe DB-queryplan) terwijl je dezelfde statuscodes, veldnamen en errorformaten teruggeeft die het contract belooft. Als je nieuwe data moet toevoegen, geef dan de voorkeur aan additieve velden die clients kunnen negeren.
Simpel voorbeeld: geleidelijke uitrol van strengere validatie
Stel POST /orders accepteert momenteel phone in veel formaten. Je wilt E.164 afdwingen, maar aanscherpen kan bestaande clients breken.
Een veiligere aanpak:
- Ship de strengere validator achter een flag (bijv.
strict_phone_validation).
- Begin in "report-only" mode: accepteer het verzoek, maar log wat zou hebben gefaald. Responses blijven ongewijzigd.
- Canary enable enforcement voor interne gebruikers of 1% van het verkeer.
- Ramp up percentages terwijl je monitort: validatiefoutspieken, client retries en afnames.
- Rollback direct als failures boven drempels komen.
Dit patroon laat je naar betere datakwaliteit bewegen zonder een achterwaarts compatibele API per ongeluk te breken.
Deprecation en sunsetting: hoe oude versies af te voeren
Krijg snel een v1 draaiend
Bouw vandaag een kleine v1 API en oefen compatibiliteitsregels voordat je met partners integreert.
Deprecation is het "beleefde vertrek" voor oud API-gedrag: je moedigt het niet meer aan, waarschuwt clients vroeg en geeft ze een voorspelbare route vooruit. Sunsetting is de laatste stap: een oude versie wordt op een gepubliceerde datum uitgezet. Voor door AI gegenereerde backends—waar endpoints en schema's snel kunnen evolueren—houdt een strikt retirement-proces updates veilig en behoudt vertrouwen.
Definieer wat “major” betekent (Semantic Versioning)
Gebruik semver op het niveau van het API-contract, niet alleen in je repo.
- MAJOR: elke breaking change (velden/endpoints verwijderen, betekenis van een veld veranderen, validatie aanscherpen, auth-vereisten veranderen, default-gedrag wijzigen waarop clients vertrouwen).
- MINOR: achterwaarts-compatibele toevoegingen (nieuwe optionele velden, nieuwe endpoints, additieve enumwaarden als clients onbekenden kunnen negeren, nieuwe filterparams).
- PATCH: bugfixes en niet-functionele verbeteringen (performance, interne refactors) die het contract of observeerbaar gedrag niet veranderen.
Leg deze definitie eenmaal vast in je docs en pas hem consequent toe. Zo voorkom je "stille majors" waarbij een AI-ondersteunde wijziging klein lijkt maar een echte client breekt.
Een praktisch deprecation-tijdschema
Kies een standaardbeleid en houd je eraan zodat gebruikers kunnen plannen. Een veelgebruikte aanpak:
- Announce deprecation: meteen wanneer je de nieuwe versie releaset.
- Deprecation window: houd de oude versie werkend voor 90–180 dagen (langer voor enterpriseklanten).
- Sunset date: publiceer op dag één een vaste cutoff-datum.
Als je twijfelt, kies een iets langere window; de kost van het kort tijdelijk live houden van een versie is meestal lager dan de kosten van noodmigraties voor clients.
Deprecation-signalen (maak het moeilijk om te missen)
Gebruik meerdere kanalen, want niet iedereen leest release notes.
- Response headers: bijv.
Deprecation: true en Sunset: Wed, 31 Jul 2026 00:00:00 GMT, plus Link: /docs/api/v2/migration.
- Docs-notities: een duidelijke banner in de oude versie docs met de sunset-datum en een migratie-checklist (tekstuele verwijzing naar /docs/api/v2/migration).
- SDK-waarschuwingen: waarschuwingen in officiële SDKs (runtime logs + compile-time deprecation-annotaties waar mogelijk).
Neem deprecatie-notices ook op in changelogs en statusupdates zodat procurement en ops teams ze zien.
Verwijderen: sunset met een vaste datum (en veilige eindtoestand)
Houd oude versies draaiende tot de sunset-datum, en schakel ze dan bewust uit—niet geleidelijk via onbedoeld breken.
Bij sunset:
- Geef een duidelijke fout voor de gepensioneerde versie (bijv.
410 Gone) met een boodschap die naar de nieuwste versie en de migratiepagina verwijst.
- Houd tijdelijk een stabiele, menselijk leesbare uitlegpagina beschikbaar (bijv. /docs/deprecations/v1).
Belangrijker nog: behandel sunsetting als een geplande wijziging met eigenaren, monitoring en een rollback-plan. Die discipline maakt frequente evolutie mogelijk zonder clients te verrassen.
Testen dat per ongeluk breaking changes voorkomt
Door AI gegenereerde code kan snel veranderen—en soms op verrassende plekken. De veiligste manier om clients werkend te houden is het contract te testen (wat je extern beloofd), niet alleen de implementatie.
Contracttests: spec-naar-spec vergelijkingen
Een praktisch uitgangspunt is een contracttest die de vorige OpenAPI-spec vergelijkt met de nieuw gegenereerde. Behandel het als een "voor vs na" controle:
- Detecteer verwijderde endpoints, hernoemde velden, aangescherpte validatieregels of gewijzigde auth-vereisten
- Flag response-code wijzigingen (bijv. 200 → 204, of ander 404-gedrag)
- Vang subtiele verschuivingen zoals een optioneel veld dat ineens verplicht wordt
Veel teams automatiseren een OpenAPI-diff in CI zodat geen gegenereerde wijziging gedeployed kan worden zonder review. Dit is vooral nuttig wanneer prompts, templates of modelversies veranderen.
Consumer-driven contract testing (in eenvoudige bewoordingen)
Consumer-driven contract testing keert het perspectief om: in plaats van dat het backend-team raadt hoe clients de API gebruiken, deelt elke client een kleine set verwachtingen (de requests die het stuurt en de responses waarop het vertrouwt). De backend moet bewijzen dat het deze verwachtingen nog voldoet vóór release.
Dit werkt goed wanneer je meerdere consumenten hebt (webapp, mobile app, partners) en je updates wilt doorvoeren zonder elke deployment te coördineren.
Regresietests voor response-vormen en fouten
Voeg regresietests toe die vastleggen:
- Response JSON-structuur (veldnamen, types, nesting)
- Defaults en nullable-gedrag (ontbrekend vs null)
- Paginatie- en sorteersemantiek
- Errorformaten: stabiele errorcodes, berichtstructuur en validatie-errorvelden
Als je een error-schema publiceert, test het expliciet—clients parsen fouten vaak meer dan je zou willen.
CI-gates vóór uitrol
Combineer OpenAPI-diff checks, consumer contracts en shape/error regresietests in een CI-gate. Als een gegenereerde wijziging faalt, is de oplossing meestal het prompt aanpassen, generatie-regels bijstellen of een compatibiliteitslaag toevoegen—voordat gebruikers iets merken.
Error handling en gedragsstabiliteit over versies heen
Wanneer clients integreren met je API, lezen ze meestal geen foutmeldingen—ze reageren op fout vormen en codes. Een typefout in een mensvriendelijk bericht is vervelend maar vaak te overleven; een gewijzigde statuscode, ontbrekend veld of hernoemde foutidentifier kan een herstelbare situatie veranderen in een gebroken checkout, een mislukte sync of een oneindige retry-lus.
Stabiele errors: prioriteer machine-leesbaarheid
Streef naar een consistent error-envelope (de JSON-structuur) en een stabiele set identifiers waarop clients kunnen vertrouwen. Bijvoorbeeld: als je { code, message, details, request_id } retourneert, verwijder of hernoem die velden niet in een nieuwe versie. Je kunt de tekst in message verbeteren, maar hou code-semantiek stabiel en gedocumenteerd.
Als je al meerdere formaten in het wild hebt, weersta de verleiding het "in-place" op te ruimen. Voeg in plaats daarvan een nieuw formaat toe achter een versiegrens of een negotiatiemechanisme (bijv. Accept header), terwijl je het oude blijft ondersteunen.
Nieuwe errorcodes toevoegen zonder oude clients te breken
Nieuwe errorcodes zijn soms nodig (nieuwe validatieregels, nieuwe autorisatiechecks), maar je moet ze zo introduceren dat bestaande integraties niet verrast worden.
Een veilige aanpak:
- Houd oude codes geldig: als clients al
VALIDATION_ERROR afhandelen, vervang dat niet abrupt door INVALID_FIELD.
- Introduceer nieuwe codes als meer specifieke varianten: geef de nieuwe
code, maar voeg ook backward-compatible hints toe in details (of map naar de oudere gegeneraliseerde code voor oudere versies).
- Documenteer een fallback-regel: laat clients weten onbekende codes te behandelen als een generieke klasse op basis van HTTP-status (400/401/403/404/409/429/500) en nog steeds
message tonen.
Belangrijk: verander nooit de betekenis van een bestaande code. Als NOT_FOUND eerder "resource bestaat niet" betekende, gebruik het dan niet plotseling voor "toegang geweigerd" (dat is een 403).
Gedragsstabiliteit: defaults mogen niet stilletjes verschuiven
Achterwaartse compatibiliteit betekent ook "zelfde request, zelfde resultaat." Kennelijk kleine default-wijzigingen kunnen clients breken die parameters nooit expliciet instellen.
Paginatie: verander niet de default limit, page_size of cursor-gedrag zonder versionering. Overschakelen van page-based naar cursor-based paginatie is een breaking change tenzij je beide paden behoudt.
Sortering: de standaard sorteervolgorde moet stabiel zijn. Wisselen van created_at desc naar relevance desc kan lijsten herschikken en UI-veronderstellingen of incrementele sync breken.
Filtering: vermijd het wijzigen van impliciete filters (bijv. plotseling standaard "inactive" items uitsluiten). Als je nieuw gedrag wilt, voeg een expliciete vlag toe zoals include_inactive=true of status=all.
Sommige compatibiliteitsproblemen gaan niet over endpoints maar over interpretatie.
- Tijdzones: specificeer altijd of timestamps UTC zijn, include offsets en houd het consistent. Een verschuiving van lokale tijd naar UTC zonder waarschuwing kan duplicate of missende events veroorzaken.
- Numberformaten: JSON-nummers zijn eenduidig, maar strings die op nummers lijken (valuta, decimalen) kunnen variëren. Verander
"9.99" niet zomaar in 9.99 (of omgekeerd) in-place.
- Boolean defaults: defaults zoals
include_deleted=false of send_email=true mogen niet zomaar flippen. Als je een default moet veranderen, laat de client opt-in via een nieuw parameter.
Voor door AI gegenereerde backends vooral: leg deze gedragingen vast in expliciete contracten en tests; het model kan anders "verbeteren" tenzij je stabiliteit afdwingt als een eerste prioriteit.
Observeerbaarheid: compatibiliteit monitoren in de praktijk
Houd errors consistent
Stel stabiele error-shapes en statuscodes in en regenereer zonder integraties te verrassen.
Achterwaartse compatibiliteit verifieer je niet één keer en vergeet je. Met door AI gegenereerde backends kan gedrag sneller veranderen dan bij handgebouwde systemen, dus je hebt feedbackloops nodig die laten zien wie wat gebruikt en of een update clients schaadt.
Meet metrics per API-versie (en per endpoint)
Tag elk verzoek met een expliciete API-versie (pad zoals /v1/..., header zoals X-Api-Version of de onderhandelde schema-versie). Verzamel dan metrics gesegmenteerd op die versie:
- Gebruik: requests per minuut per versie en route
- Latency: p50/p95 per versie (een compatibele wijziging kan nog steeds te traag zijn)
- Error rates: 4xx vs 5xx per versie (pieken onthullen vaak verborgen breakages)
Zo zie je bijvoorbeeld dat /v1/orders 5% van het verkeer is maar 70% van de errors na een rollout.
Detecteer clients die nog oude velden of endpoints gebruiken
Instrumenteer je API-gateway of applicatie om te loggen wat clients daadwerkelijk sturen en welke routes ze aanroepen:
- Requests naar deprecated endpoints (bijv.
/v1/legacy-search)
- Payloads met deprecated velden
- Requests zonder nieuw optionele velden die sommige gegenereerde code misschien veronderstelt
Als je SDKs beheert, voeg een lichte clientidentifier + SDK-versie header toe om verouderde integraties te vinden.
Gebruik logs en tracing om de wijziging te pinpointen
Wanneer errors stijgen, wil je snel antwoord op: "Welke deployment veranderde gedrag?" Correleer pieken met:
- release-identifiers (commit hash/build id)
- gestructureerde logs met versie, route en validatiefouten
- distributed traces die laten zien waar latency of exceptions begonnen (gateway → handler → DB)
Rollback passend bij gegenereerde deployments
Houd rollbacks eenvoudig: zorg dat je altijd het vorige gegenereerde artefact (container/image) kunt redeployen en verkeer terug kunt flippen via je router. Vermijd rollbacks die dataverdwijningen vereisen; als schema-wijzigingen betrokken zijn, geef de voorkeur aan additieve DB-migraties zodat oudere versies blijven werken terwijl je de API-laag terugdraait.
Als je platform environment snapshots en snelle rollback ondersteunt, gebruik die. Bijvoorbeeld, Koder.ai bevat snapshots en rollback als onderdeel van de workflow, wat goed samenwerkt met “expand → migrate → contract” database-wijzigingen en geleidelijke API-rollouts.
Een herhaalbare workflow voor het evolueren van door AI gegenereerde API's
Door AI gegenereerde backends kunnen snel veranderen—nieuwe endpoints verschijnen, modellen verschuiven en validaties verscherpen. De veiligste manier om clients stabiel te houden is API-wijzigingen te behandelen als een kleine, herhaalbare releasecyclus in plaats van "eenmalige edits."
De workflow (voorstel → sunset)
- Propose the change
Schrijf op waarom, het bedoelde gedrag en de exacte impact op het contract (velden, types, required/optional, errorcodes).
- Classify it
Markeer als compatible (veilig) of breaking (vereist clientwijzigingen). Als je het niet zeker weet, ga uit van breaking en ontwerp een compatibiliteitspad.
- Design the compatibility plan
Bepaal hoe je oude clients ondersteunt: aliassen, dual-write/dual-read, defaultwaarden, tolerant parsen of een nieuwe versie.
- Implement behind a guardrail
Voeg de wijziging toe met feature flags of configuratie zodat je het geleidelijk kunt uitrollen en snel kunt terugdraaien.
- Test the contract
Draai geautomatiseerde contractchecks (bijv. OpenAPI-diff regels) plus golden “known client” request/response-tests om gedragsdrift te vangen.
- Release with documentation
Elke release moet bevatten: bijgewerkte referentiedocs in /docs, een korte migratienoot indien relevant en een changelog die vermeldt wat er veranderde en of het compatibel is.
- Deprecate and remove on a schedule
Kondig deprecations met data aan, voeg response headers/warnings toe, meet resterend gebruik en verwijder na het sunset-venster.
Mini-voorbeeld: een veld hernoemen zonder clients te breken
Als je last_name naar family_name wilt hernoemen:
- Request handling: accepteer beide velden; als beide aanwezig zijn, geef prioriteit aan
family_name.
- Response handling: retourneer beide tijdens een overgangsperiode (of retourneer
family_name en houd last_name als aliasveld).
- Storage: map beide naar dezelfde interne kolom.
- Docs + changelog: documenteer de nieuwe naam, markeer
last_name als deprecated en zet een verwijderdatum.
Als je product plan-gebaseerde support of langdurige versie-ondersteuning biedt, vermeld dat duidelijk op /pricing.