Wat breekt er eerst als de database onder druk staat
Als je database overbelast raakt, zien gebruikers zelden een nette "down"-melding. Ze ervaren time-outs, pagina's die half laden, knoppen die eeuwig draaien en acties die soms werken en soms falen. Een opslaan kan één keer slagen en de volgende keer een fout geven met "Er is iets misgegaan." Die onzekerheid maakt incidenten chaotisch.
Meestal breken eerst de schrijf-zware paden: records bewerken, checkout flows, formulierinzendingen, achtergrondupdates en alles wat een transactie en locks nodig heeft. Onder stress worden schrijfbewerkingen trager, blokkeren ze elkaar en kunnen ze ook reads vertragen door locks vast te houden en extra werk af te dwingen.
Willekeurige fouten voelen erger dan een gecontroleerde beperking omdat gebruikers niet weten wat ze daarna moeten doen. Ze proberen opnieuw, verversen, klikken nog eens en creëren zo nog meer load. Supporttickets schieten omhoog omdat het systeem er "een beetje werkt", maar niemand het vertrouwen heeft.
Het doel van alleen-lezen modus tijdens incidenten is geen perfectie. Het is om de belangrijkste onderdelen bruikbaar te houden: belangrijke records bekijken, zoeken, status checken en downloaden wat mensen nodig hebben om door te werken. Je stopt of vertraagt opzettelijk de risicovolle acties (schrijfbewerkingen) zodat de database kan herstellen en de overgebleven reads responsief blijven.
Stel verwachtingen duidelijk. Dit is een tijdelijke beperking en het betekent niet dat data wordt verwijderd. In de meeste gevallen staan de bestaande gegevens van de gebruiker nog steeds veilig - het systeem pauzeert gewoon wijzigingen tot de database weer gezond is.
Wat alleen-lezen modus daadwerkelijk betekent
Alleen-lezen modus tijdens incidenten is een tijdelijke staat waarin je product bruikbaar blijft voor bekijken, maar alles weigert dat data zou wijzigen. Het doel is simpel: de service nuttig houden terwijl je de database beschermt tegen extra werk.
In gewone taal: mensen kunnen nog steeds dingen opzoeken, maar ze kunnen geen wijzigingen doorvoeren die schrijfbewerkingen triggeren. Dat betekent meestal dat bladeren, zoeken, filteren en records openen nog werken. Formulieren opslaan, instellingen aanpassen, reacties plaatsen, bestanden uploaden of nieuwe accounts aanmaken worden geblokkeerd.
Een praktische vuistregel: als een actie een rij bijwerkt, een rij aanmaakt, een rij verwijdert of naar een queue schrijft, is het niet toegestaan. Veel teams blokkeren ook "verborgen schrijfbewerkingen" zoals analytics-events die in de primaire database worden opgeslagen, synchronously geschreven auditlogs en "last seen"-timestamps.
Alleen-lezen modus is de juiste keuze wanneer reads nog grotendeels werken, maar write-latency stijgt, lock-contentie groeit of een achterstand van schrijfintensief werk alles vertraagt.
Ga volledig offline wanneer zelfs basis-reads time-outs geven, je cache de essentials niet kan leveren, of het systeem gebruikers niet betrouwbaar kan vertellen wat veilig is om te doen.
Waarom dit helpt: schrijven kost vaak veel meer dan een simpele read. Een write kan indexes, constraints, locks en vervolgqueries triggeren. Schrijfbewerkingen blokkeren voorkomt ook retry-stormen, waarbij clients mislukte saves blijven herhalen en de schade vermenigvuldigen.
Voorbeeld: tijdens een CRM-incident kunnen gebruikers nog zoeken in accounts, contactgegevens openen en recente deals bekijken, maar de acties Bewerken, Aanmaken en Importeren zijn uitgeschakeld en elk save-verzoek wordt onmiddellijk afgewezen met een duidelijke melding.
Kies welke reads je moet behouden en welke schrijfbewerkingen je stopt
Als je overschakelt naar alleen-lezen modus tijdens incidenten is het doel niet "alles moet werken." Het doel is dat de belangrijkste schermen nog laden, terwijl alles wat extra database-druk veroorzaakt snel en veilig stopt.
Begin met het benoemen van de paar gebruikersacties die zelfs op een slechte dag moeten blijven werken. Dit zijn meestal kleine reads die beslissingen mogelijk maken: het nieuwste record bekijken, een status checken, zoeken in een korte lijst of een rapport downloaden dat al in cache staat.
Bepaal vervolgens wat je kunt pauzeren zonder grote schade. De meeste schrijf-paden vallen tijdens een incident in "fijn om te hebben": bewerkingen, bulk-updates, imports, reacties, bijlagen, analytics-events en alles dat extra queries triggert.
Een eenvoudige manier om de keuze te maken is acties in drie bakken te sorteren:
- Must keep: kleine, snelle reads die gebruikers nu uit de brand helpen
- Can pause: schrijfbewerkingen en zware reads die load toevoegen of rijen blokkeren
- Can degrade: functies die gecachte data of een gedeeltelijke weergave kunnen tonen
Stel ook een tijdshorizon in. Als je minuten verwacht, kun je streng zijn en bijna alle schrijfbewerkingen blokkeren. Verwacht je uren, overweeg dan een zeer beperkte set veilige schrijfbewerkingen toe te staan (zoals wachtwoordresets of kritieke statusupdates) en queue alles anders.
Kom vroeg overeen: veiligheid boven volledigheid. Het is beter een duidelijke "wijzigingen zijn gepauzeerd"-melding te tonen dan een write toe te staan die half slaagt en data inconsistent achterlaat.
Hoe beslis je wanneer je het inschakelt
Overschakelen naar alleen-lezen is een afweging: minder features nu, maar een bruikbaar product en een gezondere database. Het doel is handelen voordat gebruikers een spiraal van retries, time-outs en vastzittende verbindingen veroorzaken.
Let op een klein aantal signalen die je in één zin kunt uitleggen. Als er twee of meer tegelijk optreden, zie het als een vroege waarschuwing:
- Verzoeken die time-outs krijgen of een duidelijke latency-drempel overschrijden (bijv. p95 van 300 ms naar 3 s)
- Database-CPU die voor meerdere minuten vastzit, niet alleen een korte spike
- Uitputting van de connection pool (verzoeken in de wachtrij omdat geen verbindingen beschikbaar zijn)
- Slow query-log die plotseling volloopt met dezelfde paar queries
- Foutenpercentage dat stijgt door lock-waits, deadlocks of mislukte transacties
Metrics alleen mogen niet de enige trigger zijn. Voeg een menselijke beslissing toe: de on-call verklaart een incidentstatus en schakelt de alleen-lezen modus in. Dat stopt discussies onder druk en maakt de actie auditeerbaar.
Maak drempels makkelijk te onthouden en te communiceren. "Writes zijn gepauzeerd omdat de database overbelast is" is duidelijker dan "we hebben saturatie bereikt." Definieer ook wie de schakel om kan zetten en waar dat geregeld wordt.
Vermijd flappen tussen modi. Voeg simpele hysterese toe: blijf minstens een minimale periode in alleen-lezen (bijv. 10–15 minuten) en schakel pas terug nadat de belangrijkste signalen langere tijd normaal zijn. Dit voorkomt dat gebruikers formulieren zien die de ene minuut werken en de volgende niet.
Stapsgewijs: alleen-lezen veilig inschakelen
Behandel alleen-lezen modus tijdens incidenten als een gecontroleerde wijziging, niet als paniekwerk. Het doel is de database te beschermen door schrijfbewerkingen te stoppen, terwijl je de meest waardevolle reads beschikbaar houdt.
Een veilige rollout-volgorde
Als het kan, deploy de codepad voordat je de schakel omzet. Zo is het inschakelen van alleen-lezen gewoon een toggle, geen live wijziging.
- Maak één incident-toggle (feature flag of config-instelling) die het hele systeem leest. Houd het globaal en saai:
READ_ONLY=true. Vermijd meerdere flags die uit sync kunnen raken.
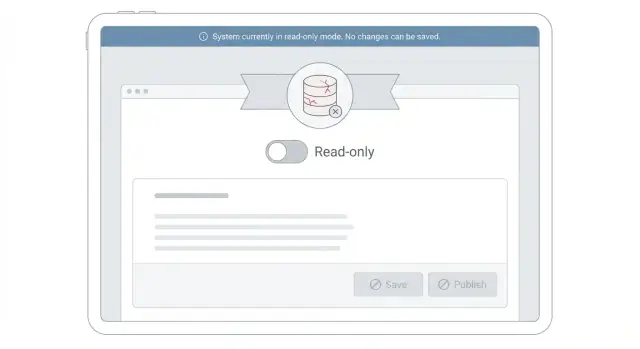
- Werk de UI bij om schrijfpogingen te voorkomen. Schakel Opslaan-knoppen uit, verberg bewerkformulieren en zet invoervelden om naar platte tekst. Blijf data tonen zodat mensen verder kunnen werken (bekijken, zoeken, exporteren).
- Handhaaf het op de server, niet alleen in de UI. Blockeer schrijfbewerkingen op één plek (middleware, controller guard of servicelaag) zodat elke client gedekt is, inclusief mobiele apps, API-gebruikers en automatisering.
- Retourneer een duidelijke, consistente fout voor geblokkeerde schrijfbewerkingen. Gebruik een dedicated statuscode en bericht zoals: "Bewerken is tijdelijk uitgeschakeld terwijl we het systeem stabiliseren. Je data is veilig. Probeer het later opnieuw." Geef geen generieke 500 terug die op dataverlies lijkt.
- Log elke geblokkeerde schrijfpoging. Leg gebruiker, endpoint en type actie vast. Houd de payload minimaal om gevoelige data niet in logs te zetten. Deze logs helpen UX-gaten te dichten en kritieke acties later te kunnen replayen.
Een klein detail dat herhaalde incidenten voorkomt
Als alleen-lezen actief is: faal snel voordat je de database raakt. Voer geen validatie-queries uit en blokkeer daarna pas de write. Het snelst geblokkeerde verzoek is het verzoek dat je nooit naar je overbelaste database stuurt.
UI-berichten die verwarring en supporttickets verminderen
Verdien terwijl je bouwt
Verdien credits door te delen wat je hebt geleerd bij het bouwen van incidentfeatures met Koder.ai.
Als je de alleen-lezen modus inschakelt, wordt de UI onderdeel van de oplossing. Als mensen blijven klikken op Opslaan en vage fouten krijgen, blijven ze opnieuw proberen, verversen en tickets aanmaken. Duidelijke berichtgeving vermindert load en frustratie.
Een goed patroon is een zichtbare, persistente banner bovenaan de app. Houd het kort en feitelijk: wat er gebeurt, wat gebruikers mogen verwachten en wat ze nu kunnen doen. Verberg het niet in een toast die verdwijnt.
Zeg wat werkt, wat gepauzeerd is en wat er volgt
Gebruikers willen vooral weten of ze kunnen blijven werken. Schrijf het in duidelijke taal. Voor de meeste producten betekent dat:
- Werkt nog: records bekijken, zoeken, downloaden, dashboards lezen
- Gepauzeerd: aanmaken, bewerken, verwijderen, uploads, betalingen, berichten versturen
- Doe in plaats daarvan: belangrijke info kopiëren, een view exporteren, later opnieuw proberen
- Updates: "We plaatsen hier een update over 15 minuten."
Een eenvoudige statuslabel helpt mensen voortgang te begrijpen zonder te gokken. "Investigating" betekent dat je de oorzaak zoekt. "Stabilizing" betekent dat je load verlaagt en data beschermt. "Recovering" betekent dat schrijfbewerkingen snel terugkomen, maar mogelijk langzaam zijn.
Houd de toon rustig en specifiek
Vermijd beschuldigende of vage teksten zoals "Er is iets misgegaan" of "Je had geen toestemming." Als een knop uitgeschakeld is, label het: "Bewerken is tijdelijk gepauzeerd terwijl we het systeem stabiliseren."
Een klein voorbeeld: in een CRM blijven contact- en dealpagina's leesbaar, maar disable je Bewerken, Notitie toevoegen en Nieuwe deal. Als iemand toch een schrijfactie triggert, toon een korte dialoog: "Wijzigingen zijn nu gepauzeerd. Je kunt dit record kopiëren of de lijst exporteren en later opnieuw proberen."
Behoud belangrijke reads zonder de load te verergeren
Het doel is niet "alles zichtbaar houden." Het is "de paar pagina's behouden waarop mensen vertrouwen," zonder extra druk op de database te zetten.
Begin met het trimmen van de zwaarste schermen. Lange tabellen met veel filters, full-text zoekacties over meerdere velden en complexe sorteringen veroorzaken vaak trage queries. Maak die schermen in alleen-lezen eenvoudiger: minder filteropties, een veilige standaard-sorteervolgorde en een beperkte datumbereik.
Geef de voorkeur aan gecachte of voorgecomputeerde views voor de belangrijkste pagina's. Een simpele "account overview" die uit een cache of samenvattende tabel leest is meestal veiliger dan raw event logs of veel joins.
Praktische manieren om reads leefbaar te houden zonder extra load:
- Gebruik kleinere paginagroottes en verwijder "alles tonen"
- Vervang complexe sorteringen door een standaardvolgorde (bijv. "meest recent eerst")
- Stel niet-essentiële reads zoals analytics, aanbevelingen en activiteitsgrafieken uit
- Geef de voorkeur aan gecachte samenvattingen boven ruwe histories
- Sta licht verouderde data toe als dat core-pagina's responsief houdt
Een concreet voorbeeld: tijdens een CRM-incident houd je View contact, View deal status en View laatste notitie werkend. Verberg tijdelijk Geavanceerd zoeken, Omzetgrafiek en Volledige e-mailtijdlijn, en toon een notitie dat data enkele minuten oud kan zijn.
Wat te doen met jobs, webhooks en integraties
Map reads versus writes
Plan must-keep reads en stop-doing writes voordat je de schermen en API's genereert.
Het grootste verrassingsmoment is vaak niet de UI, maar de onzichtbare schrijvers: achtergrondjobs, geplande syncs, admin bulk-acties en derden die de database blijven belasten.
Stop achtergrondwerk dat records aanmaakt of bijwerkt. Veelvoorkomende boosdoeners zijn imports, nachtelijke syncs, e-mailverzending die deliverylogs schrijft, analytics-rollups en retry-lussen die dezelfde mislukte update blijven proberen. Pauzeren hiervan vermindert snel de druk en voorkomt een tweede golf van load.
Een veilige standaard: pauzeer of throttle schrijf-intensieve jobs en queue-consumers die resultaten persistenteren, schakel admin-bulk-acties uit (massale updates, bulk deletes, grote re-indexes) en faal snel op write-endpoints met een duidelijke tijdelijke respons in plaats van een time-out.
Voor webhooks en integraties is duidelijkheid beter dan optimisme. Als je een webhook accepteert maar niet kunt verwerken, creëer je mismatches en supportwerk. Als schrijfbewerkingen gepauzeerd zijn, geef een tijdelijke fout terug zodat de afzender later opnieuw probeert en zorg dat je UI-berichtgeving overeenkomt met wat er achter de schermen gebeurt.
Wees voorzichtig met "queue it for later"-buffering. Het klinkt vriendelijk, maar kan een achterstand creëren die het systeem overspoelt zodra je schrijven weer inschakelt. Buffer alleen gebruikerwrites als je idempotentie kunt garanderen, de wachtrijgrootte kunt begrenzen en de gebruiker de echte status toont (in afwachting vs opgeslagen).
Tot slot: audit verborgen bulk-writers in je eigen product. Als een automatisering duizenden rijen kan updaten, moet die uitgeschakeld worden in alleen-lezen modus, zelfs als de rest van de app nog laadt.
Veelgemaakte fouten die incidenten erger maken
De snelste manier om een incident te verergeren is alleen-lezen modus als cosmetische wijziging behandelen. Als je alleen knoppen in de UI uitschakelt, zullen mensen nog steeds via APIs, oude tabs, mobiele apps en achtergrondjobs schrijven. De database blijft onder druk en je verliest vertrouwen omdat gebruikers op één plek "opgeslagen" zien en elders wijzigingen ontbreken.
Een echte alleen-lezen modus tijdens incidenten vereist één duidelijke regel: de server weigert schrijfbewerkingen, elke keer, voor elke client.
Fouten om op te letten
Deze patronen komen vaak voor tijdens database-overbelasting:
- Alleen edits in de UI blokkeren terwijl de backend nog POST, PUT, PATCH en DELETE accepteert
- Verborgen paden vergeten: adminpanelen, interne tools, import-endpoints en publieke APIs die door integraties worden gebruikt
- Het systeem elke minuut laten flappen tussen normaal en alleen-lezen
- Vage meldingen tonen zoals "Er is iets misgegaan"
- Toestaan van partiële writes die inconsistente data achterlaten
Hoe ze te vermijden
Laat het systeem voorspelbaar gedrag vertonen. Handhaaf één server-side switch die writes afwijst met een duidelijke respons. Voeg een cooldown toe zodat je minimaal in alleen-lezen blijft voor een ingestelde tijd (bijv. 10–15 minuten) tenzij een operator anders beslist.
Wees streng op dataintegriteit. Als een write niet volledig kan worden voltooid, faal de hele operatie en vertel de gebruiker wat te doen. Een simpel bericht als "Alleen-lezen modus: bekijken werkt, wijzigingen zijn gepauzeerd. Probeer het later opnieuw." vermindert herhaalde retries.
Snelle checks voor en tijdens een incident
Alleen-lezen modus helpt alleen als het makkelijk is in te schakelen en overal hetzelfde gedrag geeft. Zorg vooraf dat er één toggle is (feature flag, config, admin switch) die on-call binnen seconden kan inschakelen, zonder deploy.
Als je database-vermoedens hebt, doe snel een controle:
- Zet de toggle in een veilige omgeving om en bevestig dat het onmiddellijk werkt
- Test een paar write-acties (opslaan, verwijderen, import) en controleer dat elk write-endpoint dezelfde geblokkeerde respons en statuscode teruggeeft
- Controleer dat de bannertekst klaar, kort en zichtbaar is op de meest gebruikte schermen
- Laad je top 3 pagina's (bijv. login, dashboard, record-view) en bevestig dat ze onder stress nog renderen
- Zorg dat support één alinea heeft die uitlegt wat werkt, wat gepauzeerd is en waar updates te volgen zijn
Tijdens het incident houd je één persoon gefocust op de gebruikerservaring, niet alleen dashboards. Een korte controle in een incognito-venster vangt problemen als verborgen banners, kapotte formulieren of eindeloze spinners die extra refresh-traffic veroorzaken.
Plan de exit voordat je inschakelt. Bepaal wat "gezond" betekent (latency, error rate, replicatie-achterstand) en voer een korte verificatie uit nadat je weer schrijft: maak een testrecord, bewerk het en controleer tellingen en recente activiteit.
Voorbeeldincident: houd een CRM bruikbaar terwijl edits geblokkeerd zijn
Oefen de switch in staging
Zet je incident-playbook om in een werkende app-flow die je altijd kunt testen.
Het is 10:20. Je CRM is traag en de database-CPU is vastgelopen. Supporttickets komen binnen: gebruikers kunnen geen wijzigingen opslaan in contacten en deals. Het team moet echter nog steeds telefoonnummers opzoeken, deal-stadia zien en de laatste notities lezen voor gesprekken.
Je kiest een eenvoudige regel: bevries alles dat schrijft, behoud de meest waardevolle reads. Praktisch betekent dit dat contactzoeken, contactdetails en het deal-pipeline-overzicht beschikbaar blijven. Contacten bewerken, nieuwe deals aanmaken, notities toevoegen en bulk-imports worden geblokkeerd.
In de UI is de verandering duidelijk en rustig. Op bewerkschermen is de Opslaan-knop uitgeschakeld en het formulier blijft zichtbaar zodat mensen kunnen kopiëren wat ze hebben ingetikt. Een banner bovenaan zegt: "Read-only modus is aan wegens hoge load. Bekijken is beschikbaar. Wijzigingen zijn gepauzeerd. Probeer het later opnieuw." Als een gebruiker toch een schrijfactie triggert (bijv. via een API-call), retourneer dan een duidelijk bericht en voorkom automatische retries die de database bestoken.
Operationeel: houd de flow kort en herhaalbaar. Schakel alleen-lezen in en verifieer dat alle write-endpoints het respecteren. Pauzeer achtergrondjobs die schrijven (syncs, imports, e-maillogging, analytics backfills). Throttle of pauzeer webhooks en integraties die updates aanmaken. Monitor database-load, foutpercentages en trage queries. Plaats een statusupdate met wat is beïnvloed (edits) en wat nog werkt (zoeken en bekijken).
Herstel is niet alleen de schakel terugzetten. Schakel schrijfbewerkingen geleidelijk weer in, controleer foutlogs op mislukte saves en let op een write-storm van gebufferde jobs. Communiceer daarna duidelijk: "Read-only modus is uit. Opslaan is hersteld. Als je probeerde op te slaan tussen 10:20 en 10:55, controleer je laatste wijzigingen opnieuw."
Volgende stappen: maak alleen-lezen modus onderdeel van je playbook
Alleen-lezen modus werkt het beste als het saai en herhaalbaar is. Het doel is een kort script volgen met duidelijke eigenaren en checks.
Bouw een klein, bruikbaar playbook
Houd het op één pagina. Neem je triggers op (de paar signalen die overschakelen rechtvaardigen), de exacte schakel die je omzet en hoe je bevestigt dat writes geblokkeerd zijn, een korte lijst met key reads die moeten werken, duidelijke rollen (wie schakelt, wie kijkt naar metrics, wie handelt support af) en exit-criteria (wat moet waar zijn voordat je writes weer inschakelt en hoe je backlogs drained).
Bereid UI-tekst voor voordat je het nodig hebt
Schrijf en keur de teksten nu goed zodat je tijdens een outage niet over wording hoeft te discussiëren. Een eenvoudige set dekt de meeste gevallen:
- Banner: "We zijn in alleen-lezen modus terwijl we performance herstellen. Je kunt data bekijken, maar wijzigingen zijn tijdelijk uitgeschakeld."
- Bij geblokkeerde acties: "Opslaan is nu gepauzeerd. Je wijzigingen zijn niet toegepast. Probeer het over een paar minuten opnieuw."
- Statusdetail: "Laatst bijgewerkt om HH:MM. Volgende update over 10 minuten."
Oefen de switch in staging en tijd het. Zorg dat support en on-call de toggle snel kunnen vinden en dat logs geblokkeerde schrijfbewerkingen duidelijk tonen. Evalueer na elk incident welke reads echt cruciaal waren, wat nice-to-have was en wat per ongeluk load creëerde, en werk de checklist bij.
Als je producten bouwt op Koder.ai (koder.ai), kan het nuttig zijn om alleen-lezen als een first-class toggle in je gegenereerde app te behandelen zodat UI en server-side write-guards consistent blijven als je ze het meest nodig hebt.