2025년 12월 31일·5분
상관관계 ID 엔드투엔드: 로그에서 사용자 동작을 추적하는 방법
프런트엔드에서 하나의 ID를 생성해 API를 통해 전달하고 로그에 포함시켜 지원팀이 문제를 빠르게 추적할 수 있도록 하는 방법을 설명합니다.
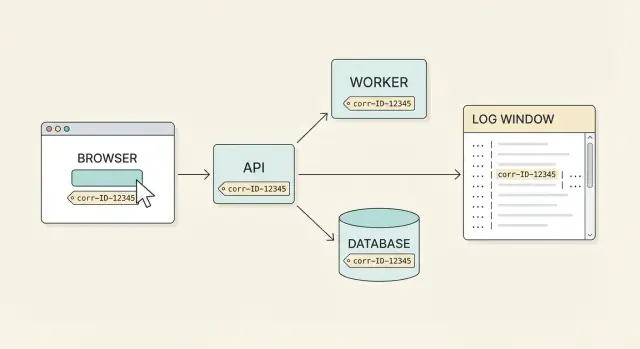
프런트엔드에서 하나의 ID를 생성해 API를 통해 전달하고 로그에 포함시켜 지원팀이 문제를 빠르게 추적할 수 있도록 하는 방법을 설명합니다.
지원팀에 접수되는 버그 리포트는 거의 깔끔하지 않습니다. 사용자가 "결제 버튼을 눌렀는데 실패했다"고 말하면 그 한 번의 클릭이 브라우저, API 게이트웨이, 결제 서비스, 데이터베이스, 백그라운드 잡까지 건드릴 수 있습니다. 각 구성요소는 서로 다른 시간과 머신에서 자체 로그를 남기고, 공통 표식이 없으면 어떤 로그 라인들이 함께 속하는지 추측해야 합니다.
상관관계 ID는 그 공통 표식입니다. 하나의 사용자 동작(또는 하나의 논리적 워크플로)에 붙는 하나의 ID로, 모든 요청과 재시도, 서비스 홉을 통해 전달됩니다. 진정한 엔드투엔드 적용이 되어 있다면 사용자의 불만에서 시작해 시스템 전반의 전체 타임라인을 바로 끌어올 수 있습니다.
사람들은 비슷한 여러 ID를 혼동하곤 합니다. 명확한 구분은 다음과 같습니다:
잘 작동하는 모습은 단순합니다. 사용자가 문제를 보고하면 UI(또는 지원 화면)에 표시된 상관관계 ID를 물어보고, 팀의 누구나 그 ID로 몇 분 안에 전체 이야기를 찾을 수 있습니다. 프런트엔드 요청, API 응답, 백엔드 단계, 데이터베이스 결과가 모두 하나로 연결됩니다.
무언가를 생성하기 전에 몇 가지 규칙에 합의하세요. 팀마다 서로 다른 헤더 이름이나 로그 필드를 쓰면 지원팀은 여전히 추측해야 합니다.
하나의 표준 이름을 정해 어디서나 사용하세요. 일반적인 선택은 X-Correlation-Id 같은 HTTP 헤더와 correlation_id 같은 구조화된 로그 필드입니다. 하나의 철자와 케이스를 정하고 문서화하며, 리버스 프록시나 게이트웨이가 헤더 이름을 바꾸거나 제거하지 않는지 확인하세요.
티켓이나 채팅에 안전하게 붙여넣을 수 있는 형식을 선택하세요. UUID는 고유하고 단순해 잘 쓰입니다. 복사하기 쉬울 정도로 충분히 짧게 유지하되 충돌 위험이 생길 만큼 짧지는 않게 하세요. 일관성이 기발함보다 중요합니다.
또한 사람이 실제로 사용할 수 있도록 ID가 어디에 노출되어야 하는지도 결정하세요. 실제로는 요청, 로그, 오류 출력에 있어야 하고 팀이 쓰는 도구에서 검색 가능해야 합니다.
ID의 수명을 정의하세요. 기본은 "한 번의 사용자 동작"(예: "결제 클릭" 또는 "프로필 저장")입니다. 서비스와 큐를 건너가는 긴 워크플로의 경우 해당 워크플로가 끝날 때까지 같은 ID를 유지하고 다음 동작에는 새 ID를 사용하세요. "세션 전체에 하나의 ID"는 검색 결과가 금세 시끄러워지므로 피하세요.
한 가지 엄격한 규칙: ID에 개인 정보를 절대 넣지 마세요. 이메일, 전화번호, 사용자 ID, 주문번호 등은 넣지 마세요. 필요하면 적절한 개인정보 보호 통제가 적용된 별도 필드에 로그하세요.
상관관계 ID를 시작하기 가장 쉬운 곳은 사용자가 관심 있는 동작을 시작하는 순간입니다: "저장" 클릭, 폼 제출, 여러 요청을 촉발하는 플로우 등. 백엔드에서 생성되기를 기다리면 UI 오류, 재시도, 취소된 요청 같은 초기 부분을 놓치기 쉽습니다.
무작위이면서 고유한 형식을 사용하세요. UUID v4는 생성이 쉽고 충돌 가능성이 낮아 흔히 쓰입니다. ID는 불투명하게 유지해 헤더나 로그로 개인 정보가 유출되지 않도록 하세요.
"워크플로"는 검증, 업로드, 레코드 생성, 목록 새로고침처럼 여러 요청을 촉발할 수 있는 하나의 사용자 동작으로 간주하세요. 워크플로가 시작되면 하나의 ID를 생성하고, 워크플로가 완료(성공, 실패, 사용자가 취소)될 때까지 유지하세요. 간단한 패턴은 컴포넌트 상태나 가벼운 요청 컨텍스트 객체에 저장하는 것입니다.
사용자가 같은 동작을 두 번 시작하면 두 번째 시도에 대해 새 상관관계 ID를 생성하세요. 이렇게 하면 "같은 클릭이 재시도된 경우"와 "서로 다른 두 번의 제출"을 구분할 수 있습니다.
해당 워크플로에서 발생하는 모든 API 호출에 ID를 추가하세요. 보통 X-Correlation-ID 같은 헤더를 사용합니다. 공통 API 클라이언트(fetch 래퍼, Axios 인스턴스 등)를 사용한다면 한 번만 전달해 클라이언트가 모든 호출에 주입하게 하세요.
// 1) when the user action starts
const correlationId = crypto.randomUUID(); // UUID v4 in modern browsers
// 2) pass it to every request in this workflow
await api.post('/orders', payload, {
headers: { 'X-Correlation-ID': correlationId }
});
await api.get('/orders/summary', {
headers: { 'X-Correlation-ID': correlationId }
});
UI가 폴링, 애널리틱스, 자동 새로고침처럼 동작과 무관한 백그라운드 요청을 한다면 그 워크플로 ID를 재사용하지 마세요. 상관관계 ID는 하나의 이야기를 말하도록 집중시켜야 합니다.
브라우저에서 상관관계 ID를 생성했다면 해야 할 일은 단순합니다: 모든 요청에서 프런트엔드를 떠나고 모든 API 경계에서 변경되지 않고 도착해야 합니다. 팀이 새 엔드포인트나 새 클라이언트, 새 미들웨어를 추가할 때 여기서 가장 자주 깨집니다.
가장 안전한 기본은 모든 호출에 HTTP 헤더(예: X-Correlation-Id)를 사용하는 것입니다. 헤더는 한 곳에서 추가하기 쉽고(fetch 래퍼, Axios 인터셉터, 모바일 네트워킹 레이어 등) 페이로드를 변경할 필요가 없습니다.
교차 출처 요청(CORS)이 있다면 API가 해당 헤더를 허용하는지 확인하세요. 그렇지 않으면 브라우저가 조용히 차단해 전송된 줄 알지만 실제로는 전송되지 않을 수 있습니다.
불가피하게 쿼리 스트링이나 요청 본문에 ID를 넣어야 하는 경우(일부 서드파티 도구나 파일 업로드 상황) 일관되게 문서화하고 하나의 필드 이름을 사용하세요. 엔드포인트마다 correlationId, requestId, cid를 섞어 쓰지 마세요.
재시도도 흔한 함정입니다. 재시도는 여전히 같은 사용자 동작이라면 같은 상관관계 ID를 유지해야 합니다. 예: 사용자가 "저장"을 클릭했는데 네트워크가 끊겨 클라이언트가 POST를 재시도하면 지원팀은 하나의 연결된 흔적을 보아야 합니다. 새 사용자 클릭(또는 새 백그라운드 잡)은 새 ID를 받아야 합니다.
WebSocket의 경우 초기 핸드셰이크에만 ID를 포함하지 말고 메시지 엔벨로프에도 ID를 넣으세요. 하나의 연결이 여러 사용자 동작을 운반할 수 있습니다.
간단한 신뢰성 체크로는 다음과 같은 규칙을 유지하세요:
correlationId 필드를 포함합니다.API 엣지(게이트웨이, 로드 밸런서, 또는 트래픽을 처음 받는 첫 웹 서비스)는 상관관계 ID가 신뢰할 수 있게 되거나 추측거리가 되는 지점입니다. 이 진입점을 신뢰의 원천으로 취급하세요.
클라이언트가 전송한 경우 수락하되 항상 존재한다고 가정하지 마세요. 누락되면 즉시 새 ID를 생성해 요청의 나머지 처리에 사용하세요. 이렇게 하면 구형 클라이언트나 잘못 구성된 클라이언트가 있어도 작동합니다.
값이 로그를 오염시키지 않도록 가벼운 검증을 하세요. 관대하게: 길이와 허용 문자만 검사하고 실 트래픽을 거부하는 엄격한 포맷은 피하세요. 예를 들어 16~64자와 영문자, 숫자, 대시, 밑줄을 허용하세요. 값이 검증을 통과하지 못하면 새 ID로 교체하고 계속 진행합니다.
호출자에게 ID를 보이게 하세요. 항상 응답 헤더에 포함하고 오류 본문에도 기재하세요. 이렇게 하면 사용자가 UI에서 복사하거나 지원 담당자가 요청해 정확한 로그 흔적을 찾을 수 있습니다.
실용적인 엣지 정책 예시는 다음과 같습니다:
X-Correlation-ID(또는 선택한 헤더)를 읽습니다.X-Correlation-ID를 추가합니다.예시 오류 페이로드(지원 티켓과 스크린샷에 표시될 내용):
{
"error": {
"code": "PAYMENT_FAILED",
"message": "We could not confirm the payment.",
"correlation_id": "c3a8f2d1-9b24-4c61-8c4a-2a7c1b9c2f61"
}
}
요청이 백엔드에 도달하면 상관관계 ID를 전역 변수에 숨겨두지 말고 요청 컨텍스트의 일부로 취급하세요. 전역 변수는 동시에 두 요청을 처리할 때 또는 응답 후 비동기 작업이 계속될 때 즉시 문제를 일으킵니다.
규모에 맞는 규칙: 로그를 남기거나 다른 서비스를 호출할 수 있는 모든 함수는 ID를 포함한 컨텍스트를 인자로 받아야 합니다. Go 서비스에서는 보통 context.Context를 핸들러, 비즈니스 로직, 클라이언트 코드에 내려보내는 방식입니다.
서비스 A가 서비스 B를 호출할 때는 동일한 ID를 그대로 아웃고잉 요청에 복사해 넣으세요. 중간에 새 ID를 생성하면 안 됩니다. 꼭 새 ID가 필요하면 원래 것을 parent_correlation_id 같은 별도 필드로 보존하세요. ID를 바꾸면 지원팀은 하나로 연결된 실타래를 잃게 됩니다.
전파는 다음과 같은 장소에서 자주 누락됩니다: 요청 중에 시작된 백그라운드 잡, 클라이언트 라이브러리 내부의 재시도, 나중에 트리거되는 웹훅, 팬아웃 호출 등. 비동기 메시지(큐/잡)에는 항상 ID를 담아야 하며 재시도 로직도 이를 보존해야 합니다.
로그는 correlation_id 같은 안정적인 필드 이름으로 구조화하세요. 프런트엔드, API, 워커 등에서 requestId, req_id, traceId를 섞어 쓰지 마세요(혹은 명확한 매핑을 정의하세요).
가능하면 데이터베이스 가시성에도 ID를 포함하세요. 실용적인 방식은 쿼리 코멘트나 세션 메타데이터에 넣어 느린 쿼리 로그에 보이게 하는 것입니다. 사용자가 "저장 버튼이 10초 동안 멈췄다"고 보고하면 지원팀이 correlation_id=abc123로 검색해 API 로그, 다운스트림 호출, 지연을 유발한 SQL을 한 번에 볼 수 있어야 합니다.
상관관계 ID는 사람들이 찾고 따라갈 수 있어야만 도움이 됩니다. 로그 메시지 문자열 안에 묻히지 않게 최상위 필드로 만들고 서비스 전반에 걸쳐 로그 항목의 형식을 일관되게 유지하세요.
상관관계 ID와 함께 언제, 어디서, 무엇이, 누구(개인 정보 보호 준수 하에)를 답할 수 있는 소수 필드를 쌍으로 기록하세요. 대부분 팀은 다음을 포함합니다:
timestamp(타임존 포함)service와 env(api, worker, prod, staging)route(또는 작업 이름)와 methodstatus와 duration_msaccount_id나 해시된 사용자 ID 같은 안전한 식별자이렇게 하면 지원팀은 ID로 검색해 올바른 요청을 확인하고 어떤 서비스가 처리했는지 알 수 있습니다.
요청마다 전체 대본을 기록할 필요는 없습니다. 대신 문제 위치 파악에 도움이 되는 강한 브레드크럼을 몇 개 남기세요.
rows=12).노이즈가 많은 로그를 피하려면 디버그 수준의 상세는 기본에서 끄고, 문제 위치를 찾는 데 도움이 되는 이벤트만 인포 레벨로 올리세요. 한 줄이 문제 위치를 찾거나 영향도를 측정하는 데 도움이 되지 않는다면 인포 레벨에 있을 필요가 없습니다.
마스킹(레드액션)은 구조만큼 중요합니다. 로그나 ID에 PII를 절대 넣지 마세요: 이메일, 이름, 전화번호, 전체 주소, 원시 토큰 등은 금지입니다. 사용자를 식별해야 한다면 내부 ID나 일방향 해시를 사용하세요.
사용자가 지원에 메시지 보냅니다: "결제 시 결제 실패가 떴어요." 가장 좋은 후속 질문은 간단합니다: "오류 화면에 표시된 상관관계 ID를 붙여넣어 주시겠어요?" 사용자가 cid=9f3c2b1f6a7a4c2f를 답합니다.
지원팀은 이제 UI, API, DB 작업을 연결하는 하나의 핸들을 가집니다. 목표는 해당 동작의 모든 로그 라인에 같은 ID가 붙어 있는 것입니다.
지원팀이 9f3c2b1f6a7a4c2f로 로그를 검색하면 흐름을 볼 수 있습니다:
frontend INFO cid=9f3c2b1f6a7a4c2f event="checkout_submit" cart=3 items
api INFO cid=9f3c2b1f6a7a4c2f method=POST path=/api/checkout user=1842
api ERROR cid=9f3c2b1f6a7a4c2f msg="payment failed" provider=stripe status=502
엔지니어는 같은 ID로 다음 홉을 따라갑니다. 핵심은 백엔드 서비스 호출(및 큐 잡)도 ID를 전달하는 것입니다.
payments INFO cid=9f3c2b1f6a7a4c2f action="charge" amount=49.00 currency=USD
payments ERROR cid=9f3c2b1f6a7a4c2f err="timeout" upstream=stripe timeout_ms=3000
db INFO cid=9f3c2b1f6a7a4c2f query="insert into failed_payments" rows=1
이제 문제는 구체적입니다: 결제 서비스가 3초 후 타임아웃이 발생했고 실패 레코드가 기록되었습니다. 엔지니어는 최근 배포를 확인하고 타임아웃 설정이 변경되었는지, 재시도가 발생하는지 등을 점검할 수 있습니다.
루프를 닫으려면 네 가지를 확인하세요:
상관관계 ID를 쓸모없게 만드는 가장 빠른 방법은 체인을 끊는 것입니다. 대부분의 실패는 개발 중에는 무해해 보이던 작은 결정들에서 시작해 지원이 답을 찾을 때 문제가 됩니다.
클래식한 실수는 매 홉마다 새 ID를 생성하는 것입니다. 브라우저가 ID를 보냈다면 API 게이트웨이는 그것을 유지해야지 교체하면 안 됩니다. 내부적으로 별도 ID가 정말로 필요하다면(큐 메시지나 백그라운드 잡을 위해) 원래 ID를 부모 필드로 보존하세요.
또 다른 흔한 공백은 부분적인 로깅입니다. 팀이 첫 API에만 ID를 추가하고 워커 프로세스, 예약 잡, 데이터베이스 접근 레이어에는 잊어버리면 요청이 시스템에 들어오는 것은 보이나 그 다음으로 어디로 갔는지 알 수 없는 교착 상태가 됩니다.
ID가 모든 곳에 존재해도 각 서비스가 다른 필드 이름이나 형식을 쓰면 검색이 어려워집니다. 프런트엔드, API, 로그 전반에 하나의 이름(예: correlation_id)을 선택하고 고수하세요. 또한 하나의 형식(보통 UUID)을 선택하고 대소문자 구분을 유지해 복사/붙여넣기가 정확히 동작하도록 하세요.
문제가 발생했을 때 ID를 잃어버리지 마세요. API가 500이나 검증 오류를 반환할 때 상관관계 ID를 오류 응답(가능하면 응답 헤더에도) 포함시키면 사용자가 지원 채팅에 붙여넣어 팀이 즉시 전체 경로를 추적할 수 있습니다.
간단한 테스트: 지원 담당자가 하나의 ID로 시작해 관련된 모든 로그 라인을 따라갈 수 있는가?
지원팀에게 "그냥 로그 검색하세요"라고 말하기 전에 이 체크리스트를 사용해 기본적인 점검을 하세요. 이 방식은 모든 홉이 같은 규칙을 따르면 작동합니다.
correlation_id를 구조화된 필드로 포함한다.체인을 끊지 않게 만드는 최소한의 변경을 선택하세요.
correlation_id를 유지하세요. 더 자세한 정보가 필요하면 별도 span_id를 추가하세요.빠른 테스트: 개발자 도구를 열고 한 동작을 트리거한 다음 첫 요청에서 상관관계 ID를 복사해 관련된 모든 API 요청과 관련 로그 라인에서 같은 값을 확인하세요.
상관관계 ID는 모든 사람이 매번 같은 방식으로 사용해야만 도움이 됩니다. 상관관계 ID 동작을 선택 사항이 아닌 배포 필수 항목으로 취급하세요.
새 엔드포인트나 UI 동작을 배포할 때 작은 추적 가능성 단계를 정의의 완료 조건(Definition of Done)에 추가하세요. ID가 어떻게 생성(또는 재사용)되는지, 워크플로 동안 어디에 저장되는지, 어떤 헤더가 이를 전달하는지, 헤더가 없을 때 각 서비스가 무엇을 하는지 포함하세요.
가벼운 체크리스트면 충분합니다:
correlation_id)을 유지한다.지원팀도 디버깅이 빠르고 반복 가능하도록 간단한 스크립트를 필요로 합니다. 사용자가 어디에서 ID를 얻을 수 있는지(예: 오류 대화상자의 "디버그 ID 복사" 버튼) 결정하고, 지원팀이 무엇을 요청해야 하고 어디서 검색해야 하는지 문서화하세요.
운영에서 신뢰하기 전에 실제 사용과 유사한 스테이지 환경에서 흐름을 실행하세요: 버튼을 클릭하고 검증 오류를 발생시킨 뒤 동작을 완료하세요. 브라우저 요청에서 시작해 API 로그, 백그라운드 워커, 데이터베이스 호출 로그까지 같은 ID로 따라갈 수 있는지 확인하세요.
Koder.ai로 앱을 구축하는 경우 Planning Mode에 상관관계 ID 헤더와 로깅 규약을 적어두면 생성된 React 프런트엔드와 Go 서비스가 기본적으로 일관되게 시작하는 데 도움이 됩니다.
상관관계 ID는 브라우저, API, 서비스, 워커 등 한 사용자 동작이나 워크플로와 관련된 모든 항목에 태그를 붙이는 공통 식별자입니다. 지원팀은 하나의 ID로 전체 타임라인을 조회해 어떤 로그 라인이 함께 속하는지 추측할 필요 없이 문제를 빠르게 파악할 수 있습니다.
한 건의 사고를 엔드투엔드로 빠르게 디버그하려면 상관관계 ID를 사용하세요. 세션 ID는 여러 동작을 포함해 너무 광범위하고, 요청 ID는 HTTP 요청 하나에만 해당해 재시도 시 변경되므로 범위가 좁습니다.
기본적으로 프런트엔드에서 사용자 동작이 시작될 때 생성하는 것이 가장 좋습니다(폼 제출, 버튼 클릭, 다단계 플로우 시작 등). 이렇게 하면 UI 오류, 재시도, 취소된 요청 등 초기 이야기를 보존할 수 있습니다.
UUID 형태의 불투명한 값이 적절합니다. 복사하기 쉬우며 지원 티켓에 안전하게 붙여넣을 수 있도록 개인 정보(이메일, 사용자명, 주문번호, 타임스탬프 등)를 포함하지 마세요.
하나의 표준 헤더 이름을 정해 모두에서 사용하세요. 예를 들어 X-Correlation-ID를 헤더로, 로그에는 correlation_id 같은 구조화된 필드로 기록하는 식입니다. 중요한 건 정확한 이름보다 일관성입니다.
같은 사용자 동작에 대한 재시도라면 동일한 상관관계 ID를 재사용하세요. 사용자가 나중에 다시 시도해 새로 시작한 동작이면 새로운 상관관계 ID를 생성해야 합니다.
API 진입점은 들어오는 헤더를 수락하고, 누락되거나 명백히 잘못된 값이면 새 ID를 생성해야 합니다. 또한 응답 헤더와 오류 응답에 ID를 에코해 사용자가 UI에서 복사할 수 있게 하세요.
요청 컨텍스트에 ID를 넣어 하위 호출로 전달하세요. 내부 HTTP/gRPC 호출이나 큐에 넣는 작업에도 동일한 ID를 복사해 전달하고, 중간에서 새로 생성하지 마세요. 더 세부적인 식별자가 필요하면 원래 ID를 유지하면서 별도의 내부 식별자(span_id 등)를 추가하세요.
상관관계 ID를 구조화된 최상위 로그 필드로 기록하세요(메시지 문자열 안에 묻히지 않게). 서비스 이름, 라우트, 상태, 지연 시간, 사용자 안전 식별자 같은 필드를 함께 기록하면 검색과 분석이 쉬워집니다. 실패 시에도 반드시 기록돼야 합니다.
간단한 테스트: 하나의 동작을 트리거하고 첫 요청이나 오류 화면에서 상관관계 ID를 복사한 뒤, 동일한 값이 관련 요청 헤더와 워크플로를 처리한 모든 서비스 로그 라인에 나타나는지 확인하세요. 워커, 재시도, 오류 응답에서 ID가 사라지면 그 부분부터 수정하세요.