2025년 8월 27일·6분
백그라운드 작업을 위한 Go 워커 풀: 재시도, 취소, 종료
Go 워커 풀은 작은 팀이 무거운 인프라를 도입하기 전에 재시도, 취소, 안전한 종료를 간단한 패턴으로 처리해 백그라운드 작업을 안정적으로 운영하게 해줍니다.
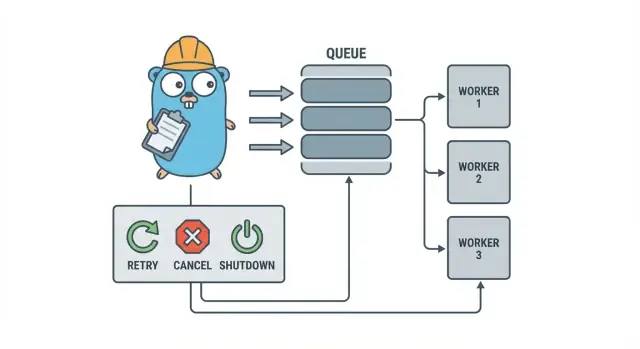
백그라운드 작업이 빠르게 복잡해지는 이유
작은 Go 서비스에서 백그라운드 작업은 보통 단순한 목표로 시작합니다. HTTP 응답을 빠르게 반환하고 느린 작업은 나중에 처리하는 것입니다. 이메일 발송, 이미지 리사이징, 다른 API와의 동기화, 검색 인덱스 재구성, 야간 리포트 생성 등이 여기에 해당합니다.
문제는 이 작업들이 실제 프로덕션 작업이지만 요청 처리에서 자연스럽게 얻는 안전장치가 없다는 점입니다. HTTP 핸들러에서 킥오프한 고루틴은 괜찮아 보이지만 배포 중에 작업이 중단되거나, 상류 API가 느려지거나, 동일한 요청이 재시도되어 작업이 두 번 트리거되는 상황이 발생합니다.
초기 문제 지점은 예측 가능합니다:
- 작업 정체: 하나의 호출이 멈추면 워커들이 진전하지 못합니다.
- 중복 작업: HTTP 레이어의 재시도가 동일한 작업을 다시 실행합니다.
- 종료 계획 부재: 프로세스가 종료되어 작업이 손실되거나 중간 상태로 남습니다.
- 무음 실패: 오류가 한 번만(혹은 전혀) 기록되어 사라집니다.
- 재시도 폭주: 실패한 작업이 즉시 재시도되어 의존성에 과부하를 줍니다.
이럴 때 간단하고 명시적인 패턴인 Go 워커 풀이 도움이 됩니다. 동시성 수준을 선택 가능하게 하고(N 워커), “나중에 처리”를 명확한 작업 타입으로 바꾸며, 재시도와 타임아웃, 취소를 한 곳에서 다루게 해 줍니다.
예시: SaaS 앱에서 송장을 발송해야 한다고 합시다. 대량 임포트 후 500개의 동시 발송을 원치 않고, 요청이 재시도되어 같은 송장을 다시 보내는 것도 원하지 않습니다. 워커 풀은 처리량을 제한하고 “송장 #123 보내기”를 추적 가능한 단위로 취급할 수 있게 합니다.
워커 풀은 내구성 있는 프로세스 간 보장을 필요로 할 때 적절한 도구가 아닙니다. 작업이 크래시를 견뎌야 하거나 예약되어야 하거나 여러 서비스에서 처리되어야 한다면 실제 큐와 작업 상태의 영속 저장이 필요합니다.
평이한 언어로 설명한 워커 풀 모델
Go 워커 풀은 의도적으로 단순합니다: 작업을 큐에 넣고 고정된 수의 워커가 그것을 가져가 실행하며 전체 시스템이 깔끔하게 멈출 수 있게 합니다.
기본 용어들:
- 작업(Job): 한 단위의 작업, 예: “이 이미지를 리사이즈하라” 또는 “이 송장 이메일을 보내라”.
- 큐: 작업이 대기하는 장소.
- 워커: 반복해서 작업을 가져와 실행하는 고루틴.
- 디스패처: 작업을 받아 큐에 넣는 부분.
많은 인프로세스 설계에서 Go 채널이 큐 역할을 합니다. 버퍼드 채널은 생산자가 블록되기 전에 제한된 수의 작업을 보관할 수 있습니다. 그 블로킹이 곧 백프레셔이며, 트래픽 급증 시 서비스가 무제한 작업을 받아 메모리를 모두 소진하는 것을 막아줍니다.
버퍼 크기는 시스템의 느낌을 바꿉니다. 작은 버퍼는 압력이 빨리 가시화되어 호출자가 더 빨리 기다리게 합니다. 큰 버퍼는 짧은 급증을 완화하지만 과부하를 숨길 수 있습니다. 완벽한 수치는 없고, 당신이 감내할 수 있는 기다림의 수준에 맞는 수치만 있습니다.
풀 크기를 고정할지 동적으로 변경할지도 결정해야 합니다. 고정 풀은 이해하기 쉽고 자원 사용을 예측 가능하게 합니다. 자동 확장 워커는 불균형한 부하에 도움이 되지만, 언제 확장하고 얼마나 확장하며 언제 축소할지 같은 추가 결정을 요구합니다.
마지막으로 인프로세스 풀에서의 “확인(ack)”은 보통 단순히 “워커가 작업을 끝내고 오류를 반환하지 않았다”는 의미입니다. 외부 브로커가 전달을 확인해 주지 않으므로, "완료"의 정의와 실패 또는 취소 시의 동작은 코드가 결정합니다.
설계 목표: 재시도, 취소, 그리고 깔끔한 종료
워커 풀은 기계적으로는 간단합니다: 고정 수의 워커를 실행하고 작업을 공급해 처리하세요. 가치 있는 점은 제어력입니다: 예측 가능한 동시성, 명확한 실패 처리, 반쪼가 된 작업을 남기지 않는 종료 경로를 제공합니다.
작은 팀이 안정적으로 유지하려면 세 가지 목표가 중요합니다:
- 동시성을 제한해 한 번의 급증이 DB나 외부 API를 망가뜨리지 않도록 하기.
- 작업 손실을 피하거나(또는 최소한 어떤 것이 왜 버려졌는지 정확히 알기).
- 디버깅이 가능하게 유지: 모든 작업은 로그와 몇 가지 카운터로 추적 가능해야 합니다.
대부분의 실패는 단순합니다만, 서로 다르게 처리하고 싶습니다:
- 일시적 오류: 네트워크 문제, 레이트 리밋 등 재시도가 의미 있는 경우.
- 영구 오류: 잘못된 입력, 누락된 레코드 등 재시도하면 안 되는 경우.
- 타임아웃: 의존성이 멈춰 있는 경우 워커가 막히지 않도록 잘라내야 합니다.
취소는 오류와 같지 않습니다. 사용자가 취소했거나 배포로 인해 프로세스가 교체되었거나 서비스가 종료되는 결정입니다. Go에서는 컨텍스트 취소를 1급 신호로 취급하고, 각 작업이 비용이 큰 일을 시작하기 전에 그리고 실행 중 안전한 지점들에서 컨텍스트를 확인하도록 하세요.
깊게 고착되는 지점은 종료입니다. 미리 “안전”의 의미를 정하세요: 진행 중인 작업을 완료할 것인가, 아니면 빠르게 중단하고 나중에 재실행할 것인가? 현실적인 흐름은 다음과 같습니다:
- 새 작업 수락을 중단합니다.
- 워커들에게 현재 작업 후 중지하라고 알리거나 즉시 중지하라고 합니다.
- 기한까지 기다리되, 그 이후엔 강제 종료합니다.
이 규칙을 미리 정하면 재시도, 취소, 종료가 자잘한 골치거리가 아니라 작고 예측 가능한 것으로 유지됩니다.
단계별: 기본 워커 풀 만들기
워커 풀은 채널에서 작업을 꺼내 실행하는 여러 고루틴일 뿐입니다. 중요한 부분은 기본을 예측 가능하게 만드는 것입니다: 작업이 어떻게 생겼는지, 워커가 어떻게 멈추는지, 모든 작업이 끝났음을 어떻게 알 수 있는지.
간단한 Job 타입으로 시작하세요. 로그용 ID, 처리할 페이로드, 재시도 카운터(나중에 유용), 타임스탬프, 작업별 컨텍스트 데이터를 저장할 장소가 있으면 됩니다.
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := \u00026Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i \u0003c size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case \u0003c-p.ctx.Done():
return
case job, ok := \u0003c-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case \u0003c-p.ctx.Done():
return context.Canceled
case p.jobs \u0003c- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
즉시 결정해야 할 몇 가지 실용적인 선택:
- 얼마나 기다릴 수 있는지에 따라 큐 크기를 정하세요.
- 백프레셔가 호출자에게 무엇을 의미하는지 결정하세요: 블록, 오류 반환, 또는 드롭.
Stop()과Wait()를 분리해 먼저 수신을 중단하고 그다음 진행 중인 작업을 기다리게 하세요.
프레임워크로 커지지 않게 재시도 추가하기
재시도는 유용하지만 워커 풀이 복잡해지는 지점이기도 합니다. 목표를 좁게 유지하세요: 다시 시도하면 실제로 성공 가능성이 있는 경우에만 재시도하고, 가능성이 없을 때는 빠르게 중단합니다.
먼저 무엇이 재시도 가능한지 정하세요. 일시적 문제(네트워크 문제, 타임아웃, "나중에 다시 시도하세요" 응답)는 보통 재시도할 만합니다. 잘못된 입력이나 누락된 레코드 같은 영구 오류는 재시도하면 안 됩니다.
작은 재시도 정책이면 충분합니다:
- 오류를 재시도 가능/불가능으로 표시하세요(예:
Retryable(err)헬퍼로 래핑). - 최대 시도 횟수를 정하세요(대개 3~5회). 그 이상은 보통 시간 낭비입니다.
- 지터가 있는 지수 백오프를 사용해 작업이 동기화되어 재시도되지 않게 하세요.
- 지연 시간의 상한을 정하세요(예: 30초 이상 대기하지 않음).
- 로그에는 시도 횟수, 다음 지연 시간, 작업 ID를 포함해 재시도를 기록하세요.
백오프는 복잡할 필요 없습니다. 흔한 형태는 delay = min(base * 2^(attempt-1), max)을 사용하고 지터로 +/-20% 정도 무작위화하는 것입니다. 지터는 중요합니다. 그렇지 않으면 많은 워커가 동시에 실패하고 동시에 재시도합니다.
지연을 어디에 둘지 결정하세요. 작은 시스템에서는 워커 내부에서 sleep하는 것이 괜찮지만, 그건 워커 슬롯을 묶어둡니다. 재시도가 드물면 괜찮습니다. 재시도가 빈번하거나 지연이 길다면 재시도 작업을 "실행 시간(run after)"이 있는 상태로 재큐잉해 워커가 다른 작업을 처리하게 하는 것을 고려하세요.
최종 실패에 대해선 명확히 하세요. 실패한 작업과 마지막 오류를 보관해 검토할 수 있게 하거나, 재생할 수 있도록 충분한 컨텍스트를 로그에 남기거나 정기적으로 확인하는 데드 리스트로 보내세요. 실패를 은닉하는 풀은 재시도조차 없는 것보다 나쁩니다.
실제로 작업을 멈추는 취소와 타임아웃
생성된 소스 코드 소유하기
직접 소유하고 확장할 수 있는 완전한 Go, React, 데이터베이스 코드를 제공합니다.
워커 풀은 멈출 수 있을 때만 안전하게 느껴집니다. 가장 단순한 규칙은: 블로킹할 수 있는 모든 레이어에 context.Context를 전달하는 것입니다. 이는 제출, 실행, 정리 단계 모두를 포함합니다.
실용적인 구성은 두 가지 시간 제한을 사용합니다:
- 작업별 타임아웃: 한 작업이 워커를 영원히 점유하지 못하게 함.
- 종료 타임아웃: 일부 작업이 협조하지 않아도 프로세스가 종료될 수 있게 함.
컨텍스트를 끝까지 사용하기
각 작업에 워커의 컨텍스트에서 파생한 별도의 컨텍스트를 부여하세요. 그러면 모든 느린 호출(DB, HTTP, 큐, 파일 I/O)이 그 컨텍스트를 사용해 일찍 반환할 수 있게 해야 합니다.
func worker(ctx context.Context, jobs \u0003c-chan Job) {
for {
select {
case \u0003c-ctx.Done():
return
case job, ok := \u0003c-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
Run이 DB나 API를 호출한다면 해당 호출들에 컨텍스트를 연결하세요(예: QueryContext, NewRequestWithContext 또는 컨텍스트를 받는 클라이언트 메서드). 한 곳이라도 무시하면 취소는 "최선의 노력"이 되어 비협조적일 때 보통 실패합니다.
부분 작업과 "재시도해도 안전한" 단계들
작업 도중 취소가 발생할 수 있으니 부분 작업이 정상이라는 가정 하에 설계하세요. 재실행해도 중복이 발생하지 않도록 단계들을 아이도맷하게 만드세요. 흔한 접근법으로는 고유 키를 사용한 삽입(또는 업서트), 진행 상황 마커(시작/완료) 기록, 진행 중 결과를 저장한 뒤 다음 단계로 넘어가기, 단계 사이에 ctx.Err()를 확인하기 등이 있습니다.
종료를 기한처럼 다루세요: 새 작업 수락을 멈추고 워커 컨텍스트를 취소한 뒤, 진행 중인 작업이 종료되기를 종료 타임아웃까지 대기합니다.
깔끔한 종료: 프로세스 종료 시 해야 할 일
깔끔한 종료의 목적은 새 작업 수락을 중단하고 진행 중인 작업에 중지를 지시하며 시스템을 이상한 상태로 남기지 않고 종료하는 것입니다.
시그널부터 시작하세요. 대부분 환경에서 로컬은 SIGINT를, 프로세스 매니저나 컨테이너 런타임은 SIGTERM을 보냅니다. 시그널이 도착했을 때 취소되는 종료용 컨텍스트를 만들고 이를 풀과 작업 핸들러에 전달하세요.
다음으로 새 작업 수락을 멈추세요. 아무도 읽지 않는 채널에 제출하려고 호출자가 영원히 블록되지 않도록 제출을 단일 함수 뒤에 숨기고 종료 컨텍스트를 선택지로 확인한 뒤 전송하세요.
큐에 있는 작업에 대해선 다음 두 가지 선택이 있습니다:
- 드레인(Draining): 이미 큐에 있는 것은 마저 처리하지만 새 제출은 거절.
- 드롭(Drop): 아직 시작되지 않은 것은 모두 버림.
결제나 이메일 같은 경우 드레인이 더 안전합니다. 캐시 재계산처럼 "있으면 좋은" 작업에는 드롭이 괜찮습니다.
실용적인 종료 순서:
- SIGINT/SIGTERM을 잡아 공유 컨텍스트를 취소합니다.
- 제출을 중단합니다(작업 채널 전체를 닫을 필요는 없음).
- 워커들이 컨텍스트에 따라 완료하거나 중단하게 합니다.
- WaitGroup으로 워커를 기다립니다.
- 기한을 강제 적용하고 그 이후엔 종료합니다.
기한은 중요합니다. 예를 들어 진행 중인 작업에 10초를 주고 그 이후에도 남아 있다면 무엇이 실행 중인지 로깅한 뒤 종료하세요. 이렇게 하면 배포가 예측 가능해지고 프로세스가 멈추는 것을 방지합니다.
워커 풀용 로깅과 간단한 메트릭
로깅 및 기본 메트릭 추가
큐 깊이, 지연, 실패를 추적할 수 있게 로그와 몇 가지 카운터를 생성하세요.
워커 풀이 고장날 때 보통 크게 실패하지 않습니다. 작업이 느려지고 재시도가 쌓이며 누군가가 "아무 것도 안 되고 있다"고 보고합니다. 로깅과 몇 가지 기본 카운터가 이를 명확한 이야기로 바꿉니다.
각 작업에 안정적인 ID를 부여(또는 제출 시 생성)하고 모든 로그 라인에 포함하세요. 로그 형식을 일관되게 유지하세요: 작업 시작 시 한 줄, 완료 시 한 줄, 실패 시 한 줄. 재시도하면 시도 횟수와 다음 지연을 기록하세요.
간단한 로그 형태:
- 시작: job_id, worker_id, attempt, kind
- 완료: job_id, worker_id, attempt, duration_ms
- 실패/재시도: job_id, worker_id, attempt, err, next_delay_ms
메트릭은 최소한으로 유지해도 효과적입니다. 큐 길이, 진행 중인 작업 수, 성공/실패 총계, 작업 지연(최소한 평균과 최대)을 추적하세요. 큐 길이는 계속 증가하는데 진행 중이 워커 수는 워커 수에 고정되어 있다면 포화 상태입니다. 제출자가 작업 채널에 전송하려고 블록된다면 백프레셔가 호출자에게 도달하고 있다는 신호입니다. 항상 나쁜 것은 아니지만 의도적인 동작이어야 합니다.
"작업이 막혔다"고 느껴지면 프로세스가 여전히 작업을 수신하는지, 큐 길이가 증가하는지, 워커가 살아 있는지, 어떤 작업이 가장 오래 실행 중인지 확인하세요. 실행 시간이 길다면 누락된 타임아웃, 느린 의존성, 또는 멈추지 않는 재시도 루프를 의심하세요.
현실적인 예: 작은 SaaS의 백그라운드 큐
주문이 PAID로 변경되는 작은 SaaS를 상상해 보세요. 결제 직후 송장 PDF를 생성해 고객에게 이메일을 보내고 내부 팀에 알림을 보낼 필요가 있습니다. 웹 요청을 블록하고 싶지 않습니다. 이 경우 작업은 실제로 중요한 일이지만 시스템은 여전히 작기 때문에 워커 풀이 적합합니다.
작업 페이로드는 최소한으로 유지하세요: DB에서 나머지를 가져오기 위한 충분한 정보만 담습니다. API 핸들러는 주문 업데이트와 동일한 트랜잭션에서 jobs(status='queued', type='send_invoice', payload, attempts=0) 같은 행을 쓰고, 백그라운드 루프는 큐 작업을 폴링해 워커 채널에 푸시합니다.
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
워커가 작업을 가져가면 정상 경로는 간단합니다: 주문을 불러와 송장을 생성하고 이메일 프로바이더를 호출한 다음 작업을 완료로 표시합니다.
재시도가 현실을 만드는 지점입니다. 이메일 프로바이더에 일시적 장애가 있다면 1,000개의 작업이 영원히 실패하거나 매초 프로바이더를 두들기는 상황을 원치 않습니다. 실용적인 접근 방식은 다음과 같습니다:
- 네트워크 오류와 5xx 응답은 재시도 가능으로 취급합니다.
- 지수 백오프를 사용하되 최대 지연을 둡니다(예: 5s, 15s, 45s, 2m).
- 시도 횟수를 제한합니다(예: 10) 이후엔 실패로 표시합니다.
- 마지막 오류를 기록해 지원팀이 원인을 확인할 수 있게 합니다.
장애 동안 작업은 queued -> in_progress -> 다시 queued(미래 실행 시간과 함께)로 이동합니다. 프로바이더가 복구되면 워커들이 자연스럽게 백로그를 처리합니다.
이제 배포를 상상하세요. SIGTERM을 보냅니다. 프로세스는 새 작업 수락을 중단하고 진행 중인 작업은 완료하게 합니다. 폴링을 멈추고 워커 채널에 더 이상 푸시하지 않으며, 워커들을 데드라인까지 기다립니다. 완료된 작업은 완료로 표시됩니다. 데드라인에 남아 있는 작업은 다시 queued로 표시하거나 워치독과 함께 in_progress로 남겨 새 버전이 시작된 뒤 픽업되게 합니다.
흔한 실수와 함정
백그라운드 처리의 대부분 버그는 작업 로직에서 나오지 않습니다. 부하가 걸리거나 종료 중에만 드러나는 조정 문제에서 나옵니다.
고전적인 함정 하나는 채널을 여러 곳에서 닫는 것입니다. 재현하기 어려운 패닉이 발생합니다. 각 채널의 소유자(보통 생산자)를 정해 그곳만 close(jobs)를 호출하게 하세요.
재시도도 선의가 문제를 일으키는 영역입니다. 모든 것을 재시도하면 영구 실패까지 재시도하게 됩니다. 시간 낭비이고 부하를 증가시키며 작은 문제를 장애로 바꿉니다. 오류를 분류하고 재시도를 제한하는 정책을 세우세요.
중복은 주의하더라도 발생합니다. 워커가 작업 중 크래시할 수 있고, 타임아웃이 작업 완료 후에 발생할 수 있으며, 배포중 재큐잉될 수 있습니다. 작업이 아이도맷하지 않다면 중복은 실제 피해를 줍니다: 송장이 두 통 가거나 환불이 두 번 발생하는 식입니다.
자주 발생하는 실수들:
- 여러 고루틴에서 같은 채널을 닫음.
- 영구 실패를 재시도하고 이를 표출하지 않음.
- 아이도맷시 키가 없어 중복으로 부작용 발생.
- 메모리까지 성장하는 무제한 인메모리 큐.
context.Context를 무시해 종료 시작 후에도 작업이 계속됨.
무제한 큐는 특히 교활합니다. 작업 급증이 메모리에 조용히 쌓일 수 있습니다. 버퍼가 제한된 채널을 선호하고, 채워졌을 때 호출자가 블록될지 드롭할지 오류를 반환할지 결정하세요.
배포 전 빠른 체크리스트
백그라운드 워커 배포
실행 준비가 되면 호스팅 지원과 함께 Go 앱을 배포하세요.
워커 풀을 프로덕션에 배포하기 전, 작업 라이프사이클을 소리 내어 설명할 수 있어야 합니다. 누군가가 "지금 이 작업은 어디에 있나요?"라고 물었을 때 추측이 아닌 답이 나와야 합니다.
실용적인 사전 점검 목록:
- 각 상태와 전이를 이름으로 말할 수 있다: queued, picked up, running, finished, failed(그리고 무엇이 상태를 이동시키는지).
- 동시성은 단일 조절값(예:
workerCount)으로 관리되고 값 변경이 코드 재작성 없이 가능하다. - 재시도는 제한되어 있다: 최대 시도 횟수, 증가하는 백오프, 영구 실패는 의도된 곳으로 간다.
- 종료 동작이 검증되었다: intake를 멈추고 진행 중인 작업을 완료하게 하며 하드 타임아웃을 둔다.
- 로그로 기본 질문에 답할 수 있다: job ID, 시도 횟수, 소요 시간, 오류 사유.
출시 전에 현실적인 연습을 하나 하세요: 100개의 "영수증 이메일 전송" 작업을 큐에 넣고 20개를 실패시키고, 그 중간에 서비스를 재시작하세요. 재시도가 예상대로 동작하고 중복 부작용이 없으며 기한 도달 시 취소가 실제로 작업을 중단하는지 확인해야 합니다.
어떤 항목이 불명확하면 지금 바로 정리하세요. 여기서의 작은 수정이 나중에 수일을 절약합니다.
다음 단계: 무거운 인프라를 추가할 시기(그리고 추가하지 말아야 할 때)
제품 초기에는 간단한 인프로세스 풀이 충분한 경우가 많습니다. 작업이 "있으면 좋은" 수준(이메일 전송, 캐시 새로고침, 리포트 생성)이고 재실행 가능하다면 워커 풀이 시스템을 이해하기 쉽게 유지합니다.
인프로세스 풀을 벗어났다는 신호
다음 압박 포인트를 주시하세요:
- 여러 앱 인스턴스를 실행 중인데 그중 하나만 작업을 가져가야 할 때.
- 내구성이 필요할 때(작업이 크래시를 견뎌야 함).
- 누가 언제 무슨 작업을 큐에 넣었고 결과가 어땠는지에 대한 감사 기록이 필요할 때.
- 서비스 간 백프레셔 제어가 필요할 때.
- 엄격한 스케줄링이나 수시간/수일 단위의 긴 지연과 신뢰성 있는 깨우기가 필요할 때.
이 중 어느 것도 해당하지 않는다면 무거운 도구는 오히려 이동 부품을 늘려 가치를 떨어뜨릴 수 있습니다.
리팩터 없이 점진적 이전하기
가장 좋은 대비책은 안정적인 작업 인터페이스입니다: 작은 페이로드 타입, ID, 명확한 결과를 반환하는 핸들러. 그러면 나중에 큐 백엔드를 인메모리 채널에서 데이터베이스 테이블로, 그다음 전용 큐로 바꾸더라도 비즈니스 코드를 바꿀 필요가 적습니다.
실용적인 중간 단계는 PostgreSQL에서 작업을 읽고 잠금을 통해 클레임하고 상태를 업데이트하는 작은 Go 서비스를 두는 것입니다. 이렇게 하면 내구성과 기본 감사 기능을 얻으면서 동일한 워커 로직을 유지할 수 있습니다.
빠르게 프로토타입하려면 Koder.ai (koder.ai)가 Go + PostgreSQL 스타터를 채팅 프롬프트에서 생성해 백그라운드 작업 테이블과 워커 루프를 포함한 코드를 제공할 수 있고, 스냅샷과 롤백 기능이 재시도와 종료 동작을 조율할 때 도움이 됩니다.