2025年8月31日·1 分
expand/contract パターンによるゼロダウンタイムのスキーマ変更
expand/contract パターンでゼロダウンタイムのスキーマ変更を学ぶ:カラムの安全な追加、段階的バックフィル、互換性あるコードのデプロイ、古い経路の削除。
expand/contract パターンでゼロダウンタイムのスキーマ変更を学ぶ:カラムの安全な追加、段階的バックフィル、互換性あるコードのデプロイ、古い経路の削除。
データベース変更によるダウンタイムは、いつも明確でわかりやすい障害として現れるわけではありません。ユーザーからするとページが永遠に読み込み中になったり、チェックアウトが失敗したり、アプリが「何か問題が発生しました」と表示するように見えることがあります。チームにとってはアラート、エラーレートの上昇、そして後処理が必要な失敗した書き込みの山として現れます。
スキーマ変更が危険なのは、データベースがアプリのすべての稼働バージョンで共有されているからです。リリース中は古いコードと新しいコードが同時に動いていることが多く(ローリングデプロイ、複数インスタンス、バックグラウンドジョブ)、正しく見えるマイグレーションでもそのどれかを壊してしまうことがあります。
よくある故障モードには次のようなものがあります。
コードが正しくても、実際の問題はタイミングとバージョン間の互換性なのでリリースが止まります。
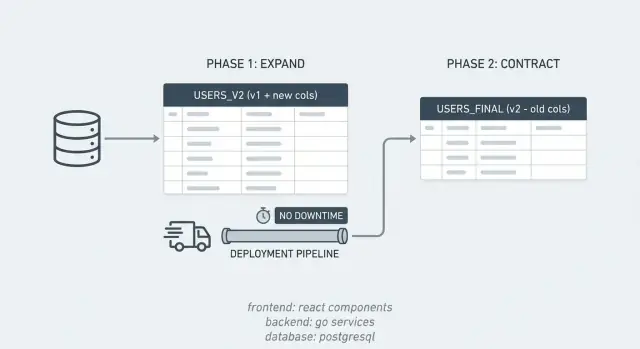
ゼロダウンタイムのスキーマ変更は一つのルールに尽きます:中間のどの状態も古いコードと新しいコードの両方に対して安全であること。データベースを変えつつ既存の読み書きを壊さないようにし、両方の形を扱えるコードを出荷し、最後に古いパスを依存がなくなってから削除します。
これは本番トラフィックが多い、SLA が厳しい、あるいは多数のアプリインスタンスやワーカーがいる場合に特に価値があります。小さな内部ツールで静かなデータベースなら、計画的なメンテナンスウィンドウの方が簡単なこともあります。
多くのデータベース関連のインシデントは、アプリがデータベースの変更を即時に起きるものと期待している一方で、実際のデータベース変更には時間がかかることから起こります。expand/contract パターンは、この問題をより小さく安全なステップに分解することで回避します。
しばらくの間、システムは二つの「方言」を同時にサポートします。まず新しい構造を導入し、古いものを動かしたままにしておき、徐々にデータを移し、最後にクリーンアップします。
パターンはシンプルです。
これはローリングデプロイと相性が良いです。サーバーを1台ずつ更新する場合、古いバージョンと新しいバージョンが短時間共存します。expand/contract はその重なりの間、データベースが両方と互換性を保つようにします。
またロールバックも怖くなくなります。新リリースにバグがあれば、データベースをロールバックせずにアプリだけを戻せます。expand の間は古い構造が残っているからです。
例:full_name カラムを first_name と last_name に分割したいとします。まず新しいカラムを追加し(expand)、古いコードと新しいコードの両方で読み書きできるようにし、旧行をバックフィルし、full_name を何も使わなくなったら削除します(contract)。
expand フェーズは古いものを削除するのではなく、新しい選択肢を追加することが目的です。
一般的な最初の一手は新しいカラムを追加することです。PostgreSQL では、通常は NULL 許容でデフォルト無しにするのが安全です。NOT NULL かつデフォルトを付けると、Postgres のバージョンや変更の内容によってはテーブルの書き換えや重いロックを引き起こすことがあります。より安全な手順は:NULL 許容で追加→寛容なコードをデプロイ→バックフィル→後で NOT NULL を強制、です。
インデックスは注意が必要です。通常のインデックス作成は意外と長く書き込みをブロックすることがあります。可能なら並行(CONCURRENT)でインデックスを作成して、読み書きが止まらないようにしてください。時間はかかりますが、リリースを止めるロックを避けられます。
expand は新しいテーブルを追加することも意味します。単一カラムから多対多の関係に移行する場合、古いカラムを残したままジョインテーブルを追加することがあります。古いパスが動き続ける間に新しい構造がデータを受け取り始められます。
実務では expand に次のような作業が含まれます。
expand 後は、古いバージョンと新しいバージョンのアプリが同時に動いても驚かないようにするべきです。
リリースでの問題の多くは中間の段階で起きます:一部のサーバーは新しいコードを実行し、他はまだ古いコードを実行している間にデータベースが既に変化している、という状況です。目標は明確で、どのバージョンも古いスキーマと拡張後のスキーマの両方で動くようにすることです。
一般的なアプローチは デュアルライト です。新しいカラムを追加したら、新しいアプリは古いカラムと新しいカラムの両方に書き込みます。古いアプリは引き続き古いカラムだけに書き込みますが、それで問題ありません。まずは新しいカラムをオプショナルにしておき、すべてのライターがアップグレードされるまで厳しい制約は遅らせます。
読み取りは通常、書き込みより慎重に切り替えます。しばらくの間は完全に埋まっている古いカラムで読みを維持し、バックフィルと検証が終わったら新しいカラムを優先的に読むようにし、欠けている場合は古いカラムにフォールバックする形にします。
また、データベースの下で内部フィールドを追加しても API の出力は安定させておいてください。内部フィールドを導入しても、すべてのクライアント(ウェブ、モバイル、統合先)が準備できるまでレスポンスの形を変えないようにします。
ロールバックに優しいロールアウトはしばしば次のようになります。
重要な考え方は、不可逆な最初のステップ(古い構造を削除する)を最後まで遅らせることです。
バックフィルで多くの「ゼロダウンタイム」移行が失敗します。既存行を新しいカラムで埋めたいが、長いロック、遅いクエリ、負荷のスパイクを避けたい、というのが問題です。
バッチ処理が重要です。各バッチは数秒で終わるようにしてください(数分かかると長すぎる)。バッチが小さければ、一時停止や再開、チューニングが容易でリリースをブロックしません。
進捗を追うには安定したカーソルを使いましょう。PostgreSQL では主キーがよく使われます。行を順に処理し、最後に処理した id を記録するか、id 範囲で処理します。こうするとジョブが再起動したときに高コストな全表スキャンを避けられます。
単純なパターンの例:
UPDATE my_table
SET new_col = ...
WHERE new_col IS NULL
AND id > $last_id
ORDER BY id
LIMIT 1000;
更新を条件付きにして(例えば WHERE new_col IS NULL)ジョブを冪等にしてください。再実行はまだ処理が必要な行だけに触れるので不要な書き込みを減らせます。
バックフィル中に新しいデータが到着することを想定してください。通常の順序は次の通りです。
良いバックフィルは地味です:安定して測定可能で、DB が熱くなったら簡単に止められること。
最もリスクが高い瞬間は新しいカラムを追加することではなく、それに依存して良いと判断することです。
contract に移る前に二つを証明してください:新しいデータが完成していること、そして本番がそれを安全に読んでいること。
まずは速く再現可能な完成度チェックから始めます。
デュアルライトを使っているなら、サイレントなバグを見つけるための整合性チェックを追加してください。例えば毎時 old_value <> new_value を検出するクエリを実行して、ゼロでないならアラートを上げるといった具合です。これは、まだ古いカラムしか更新していないライターを発見する最短の方法になることが多いです。
マイグレーション中は基本的な本番の指標を監視してください。クエリ時間やロック待ちが急増するなら、検証クエリ自体が負荷を追加しているかもしれません。特にデプロイ直後は新しいカラムを読むコードパスのエラー率を監視してください。
両方のパスをどれくらい維持すべきか?少なくとも1回のフルリリースサイクルとバックフィルの再実行を乗り切るだけの期間です。多くのチームは 1~2 週間、あるいは古いアプリバージョンが確実に動いていないと確信できるまで保持します。
contract はチームが緊張する段階で、ポイント・オブ・ノーリターンのように感じられます。expand が正しくできていれば contract は主にクリーンアップで、小さく低リスクなステップに分けて実行できます。
実施する時期は慎重に選んでください。バックフィルが終わった直後に何かを削除するのは避けて、少なくとも一回フルのリリースサイクルを待ち、遅延ジョブやエッジケースが表面化する時間を与えます。
安全な contract の典型的な手順は次のようになります。
可能なら contract を二つのリリースに分けて、まずコード参照を削除(追加ログを残す)し、後でデータベースオブジェクトを削除すると良いでしょう。その分離によりロールバックやトラブルシューティングが楽になります。
PostgreSQL の細かい点も重要です。カラム削除はほとんどメタデータ操作ですが短時間の ACCESS EXCLUSIVE ロックを取ることがあります。静かな時間を計画し、マイグレーションを素早く終わらせるようにしてください。追加したインデックスは DROP INDEX CONCURRENTLY を使って削除する方が書き込みをブロックしません(これはトランザクションブロック内で実行できないので、マイグレーションツールが対応している必要があります)。
ゼロダウンタイムのマイグレーションが失敗するのは、データベースとアプリが許容される状態について合意を失ったときです。パターンが機能するのは、中間のどの状態も古いコードと新しいコードの両方に安全な場合だけです。
よくあるミスは次の通りです。
現実的なシナリオ:API から full_name を書くようになったが、ユーザーを作るバックグラウンドジョブはまだ first_name と last_name しか設定していない。夜間にそのジョブが動いて full_name = NULL の行を挿入し、後でその full_name が常に存在する前提のコードが問題を起こす、という具合です。
各ステップを数日走るかもしれないリリースとして扱ってください。
繰り返し使えるチェックリストがあれば、あるデータベース状態でしか動かないコードを出荷するのを防げます。
デプロイ前に、データベース側が既に拡張された要素(新カラム/テーブル、低ロック方式で作られたインデックス)を持っていることを確認します。次にアプリが寛容であることを確認します:古い形、拡張された形、半分だけバックフィルされた状態のどれでも動くこと(ワーカーや管理ツールも含めて)。
チェックリストは短く保ちます。
マイグレーションは、読み取りが新しいデータを使い、書き込みが古いデータを維持しなくなり、バックフィルを少なくとも一つの簡単なチェック(件数やサンプリング)で検証できたときに初めて完了とみなします。
customers テーブルにフォーマットのばらつきや空欄が混じる phone カラムがあり、これを phone_e164 に置き換えたいとします。リリースを止められない状況です。
クリーンな expand/contract の流れは次の通りです。
phone_e164 を NULL 許容でデフォルト無しで追加する。厳しい制約はまだ付けない。phone と phone_e164 の両方に書き込むが、ユーザーに見える読み取りは phone のままにして変化を起こさない。phone_e164 をまず読むようにし、NULL の場合は phone にフォールバックするコードをデプロイする。phone_e164 を使っていると確信できたらフォールバックを削除し、phone をドロップして必要なら厳しい制約を追加する。各ステップが後方互換であればロールバックは単純です。読み替えで問題が出たらアプリをロールバックでき、データベースは両カラムを保持しているので安全です。バックフィルが負荷を引き起こすならジョブを一時停止してバッチサイズを小さくし、後で再開します。
チームの整合性を保つには、計画を一箇所に文書化してください:正確な SQL、どのリリースで読み替えるか、完了の測定方法(例:phone_e164 が NULL でない割合)、各ステップのオーナー。
expand/contract はルーチンに感じられると最も効果を発揮します。チームが毎回使える短いランブックを書いておきましょう。理想は 1 ページ程度で、新しいメンバーでも辿れる具体性があることです。
実用的なテンプレートは次を含みます。
所有者を事前に決めてください。「誰かがやるだろう」と思って誰もやらない、というのが古いカラムや機能フラグが何ヶ月も残る原因です。
バックフィルがオンラインで走るなら、負荷が比較的低い時間帯にスケジュールしてください。バッチを小さく保ち、DB 負荷を監視し、遅延が上がったらすぐ止められる方が楽です。
もし Koder.ai (koder.ai) でビルドとデプロイをしているなら、Planning Mode は本番に手を加える前にフェーズとチェックポイントをマッピングする有用な方法です。同じ互換性ルールが適用されますが、手順を書き出しておくとアウトテージを防ぐ退屈な手順を省略しにくくなります。
なぜならデータベースはアプリの全ての稼働バージョンで共有されているからです。ローリングデプロイやバックグラウンドジョブの間、古いコードと新しいコードが同時に動いていることが多く、名前の変更、カラムの削除、制約の追加などが、その時点のスキーマに対応していないバージョンを壊すことがあります。
中間のどの状態でも古いコードと新しいコードの両方で動くように設計することを指します。まず新しい構造を追加し、しばらく両方のパスで動かし、何も依存していないことを確認してから古い構造を取り除きます。
Expand は新しいカラムやテーブル、インデックスを追加して既存のものを削除しない段階です。Contract は新しいパスが正しく動いていると確認できた後に、古いカラムや古い読み書き、同期ロジックを取り除くクリーンアップ段階です。
最初はデフォルト無しで NULL 許容のカラムを追加するのが一般的に最も安全です。これなら重いロックやテーブル書き換えを避けられる可能性が高く、古いコードもそのまま動きます。その後、コードで NULL を許容する形にし、段階的にバックフィルしてから NOT NULL を適用します。
新しいアプリバージョンが移行期間中に古いフィールドと新しいフィールドの両方に書き込む方式です。これにより、古いインスタンスやジョブがまだ古いフィールドしか知らない場合でもデータ整合性を保てます。
短時間で終わる小さなバッチでバックフィルを行い、各バッチを冪等(同じ処理を複数回実行しても影響がない)にしてください。クエリ時間、ロック待ち、レプリケーション遅延を監視し、DB に負荷が出たら一時停止するかバッチサイズを小さくします。
まず新しいカラムに NULL が残っていないかなど完成度をチェックします。サンプルで古い値と新しい値を比較したり、コストが許せば継続的に old_value <> new_value のような整合性チェックを走らせておきます。また、デプロイ後のエラー率も監視して、まだ古いスキーマを参照している経路を見つけます。
NOT NULL を早すぎに追加したり、大きなトランザクションで一括バックフィルしたり、デフォルト値が裏でテーブル書き換えを引き起こすことを見落としたりすると失敗します。リネームやドロップは危険で、ローリングデプロイで古いコードがまだ参照していることを忘れがちです。
古いフィールドへの書き込みを止め、新しいフィールドに切り替えてフォールバックを削除した後、十分な時間(多くのチームは少なくとも 1〜2 週間や少なくとも 1 回のリリースサイクル)待って古いバージョンが動いていないことを確認してからが安全です。多くの場合、これを別リリースとして扱うとロールバックが簡単になります。
トラフィックが少なくメンテナンスウィンドウを取れるなら単発の移行で十分な場合もありますが、本番ユーザーが多い、複数のアプリインスタンスやワーカーがある、SLA が厳しい場合は expand/contract を使う価値が高いです。Koder.ai の Planning Mode のように手順とチェックを事前に書き出しておくと、重要な手順を省略しにくくなります。