2025年12月23日·1 分
小さなチームのためのエラーバジェット: 現実的なSLOと習慣
小さなチーム向けに:初期プロダクトで現実的なSLOを設定し、どのインシデントが重要か判断し、シンプルな週次の信頼性ルーティンを回す方法を学びます。
小さなチーム向けに:初期プロダクトで現実的なSLOを設定し、どのインシデントが重要か判断し、シンプルな週次の信頼性ルーティンを回す方法を学びます。
小さなチームは速く出す必要があるからこそ速く出します。問題は劇的な大停⽌ではなく、同じ小さな失敗の繰り返しです:不安定なサインアップ、時々失敗するチェックアウト、たまに1画面だけ壊すデプロイ。どれも時間を奪い、信頼を削り、リリースをコイントスにしてしまいます。
エラーバジェットは、小さなチームが「信頼性は勝手に高まる」と気取らず、速く動くためのシンプルな手段を与えます。
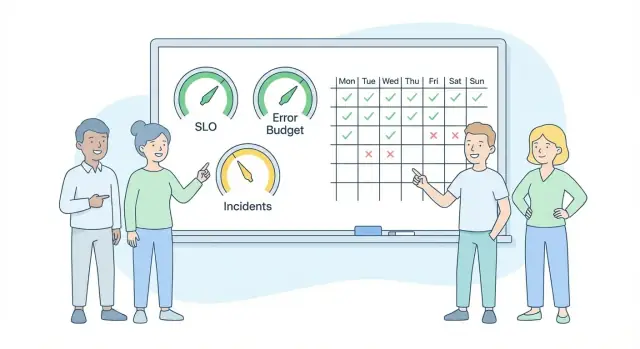
SLO(サービスレベル目標)は、ユーザー体験についての明確な約束で、時間窓を通した数値で表します。例:「過去7日間でチェックアウトの成功率が少なくとも99.5%である」。エラーバジェットはその約束の中で許される「悪い」量です。SLOが99.5%なら、週次のバジェットは0.5%の失敗です。
これは完璧主義や見せかけの稼働率のためではありません。重いプロセスや終わらない会議、誰も更新しないスプレッドシートでもありません。「十分に良い」を合意し、流れが悪くなったときに気づき、次に取るべき行動を落ち着いて決めるための方法です。
小さく始めましょう:最も重要なジャーニーに結びついたユーザー向けのSLOを1~3個選び、既にあるシグナル(エラー、レイテンシ、失敗した支払い)で測り、週に一度だけ短いレビューを行ってバジェット消費を見て1つのフォローアップを決めます。習慣がツールより重要です。
信頼性をダイエット計画のように考えてください。完璧な日々は要りません。目標、測り方、現実生活の余白があればいいのです。
SLI(サービスレベル指標)は見るべき数値で、「成功したリクエストの割合」や「p95のページ読み込み時間が2秒未満」などです。SLOはその数値の目標で、「99.9%のリクエストが成功する」といった具合。エラーバジェットはSLOをどれだけ外しても許容されるかです。
例:SLOが99.9%の可用性ならバジェットは0.1%のダウンタイムです。1週間(10,080分)では0.1%は約10分になります。だからといって「その10分を使い切ろう」という意味ではなく、使ったときは信頼性を犠牲にして実験や機能作業をしているというトレードオフだと意識するという意味です。
価値はここにあります:信頼性を報告作業ではなく意思決定の道具に変えること。水曜日までにバジェットの大半を使っていたらリスクの高い変更を止めて壊れているものを直します。ほとんど使っていなければ安心して出荷できます。
すべてに同じSLOが必要なわけではありません。公開の顧客向けアプリは99.9%が必要かもしれません。社内管理ツールなら緩めで済むことが多いです。
すべてを測ることから始めないでください。ユーザーがプロダクトが動いているかどうかを判断する瞬間を守ることから始めましょう。
信頼を担う1~3のユーザージャーニーを選びます。それらが堅ければ、ほとんどの他の問題は小さく感じられます。良い候補は最初の接触(サインアップやログイン)、お金の瞬間(チェックアウトやアップグレード)、コアアクション(公開、作成、送信、アップロード、重要なAPI呼び出し)です。
「成功」が何を意味するかを平易な言葉で書きましょう。ユーザーが開発者でない限り「200 OK」のような技術的な表現は避けてください。
適応できるいくつかの例:
変更の速さに合わせた測定ウィンドウを選びます。日々出荷して素早いフィードバックが欲しいなら7日間ウィンドウが有効です。リリースがあまり頻繁でないかデータがノイジーなら28日が落ち着いています。
初期プロダクトには制約があります:トラフィックが少ない(悪いデプロイ一回で数字が歪む)、フローが頻繁に変わる、テレメトリが薄いなど。それで構いません。まずは単純なカウント(試行回数対成功回数)から始め、ジャーニー自体が落ち着いたら定義を厳密にします。
今日出しているものから始めて、望む理想から始めないでください。1〜2週間、各重要ジャーニーのベースラインを取ってください:どれくらい成功してどれくらい失敗するか。実際のトラフィックがあればそれを使い、なければ自分たちのテストやサポートチケット、ログを使いましょう。これで「普通」を大まかに把握します。
最初のSLOは大半の週で達成できるものにしましょう。ベースライン成功率が98.5%なら99.9%を設定して期待するのはやめて、98%か98.5%に設定して後で締め上げます。
レイテンシは魅力的ですが、初期は気を散らすことがあります。多くのチームはまず成功率SLO(エラーなくリクエストが完了する)から得られる価値の方が大きいです。ユーザーが明らかに遅さを感じていて、データが安定してからレイテンシを追加しましょう。
役立つフォーマットは1行でジャーニーを書くこと:誰が、何を、ターゲット、時間窓。
請求や認証などの信頼が重要な瞬間にはウィンドウを長めに、日常のフローには短めにします。SLOを楽に満たせるようになったら少しずつ上げてください。
小さなチームは些細なつまずきがすべて火事だとされると信頼性に多くの時間を失います。目標は単純です:ユーザーが見る痛みがバジェットを消費し、それ以外は通常の作業で処理する。
十分な少数のインシデント種別で十分です:完全停止、部分的停止(重要なフローが壊れる)、性能低下(動くが遅い)、悪いデプロイ(リリースで失敗が出る)、データ問題(間違い、欠損、重複)。
スケールは小さく保ち、毎回使います。
何をバジェットにカウントするか決めましょう。ユーザーが見る失敗を消費とみなします:壊れたサインアップやチェックアウト、ユーザーが感じるタイムアウト、ジャーニーを止める5xxの急増。計画済みのメンテナンスは、事前に告知して期待通りの振る舞いならカウントしません。
議論を終わらせる簡単なルール:実際の外部ユーザーが気づいて保護されたジャーニーを完了できないなら、それはカウントする。そうでなければカウントしない。
このルールはよくあるグレーゾーンもカバーします:サードパーティの障害は自分たちのジャーニーを壊す場合のみカウント、低トラフィック時間でもユーザーに影響があればカウント、内部テスターだけならドッグフーディングが主要な使用法でない限りカウントしない。
目的は完璧な測定ではなく、共有された繰り返し可能なシグナルで「信頼性が高くついているか」を教えてくれることです。
各SLOについて1つの信頼できる情報源を選び、それを継続して使います:モニタリングダッシュボード、アプリログ、1つのエンドポイントに当てるシンセティックチェック、または「成功したチェックアウト/分」のような単一メトリクス。後で測定方法を変えるなら日付を記録し、リセットとして扱って比較のミスマッチを避けましょう。
アラートはバジェット消費を反映するようにし、すべての小さな問題で鳴らさないでください。短時間のスパイクは迷惑ですが、月間バジェットにほとんど影響しないなら誰も起こすべきではありません。よく使われるパターンは「高速消費」と「低速消費」に対するアラートです。
小さな信頼性ログを付けて記憶に頼らないようにします。インシデントごとに1行で十分:日付と期間、ユーザー影響、原因と思われること、変更点、フォローアップの担当と期限。
例:二人チームがモバイルアプリ向けの新しいAPIを出す。SLOは「成功リクエストが99.5%」で、一つのカウンタで測る。悪いデプロイで成功率が20分間97%に落ちる。高速消費アラートが鳴り、ロールバックして「デプロイ前にカナリアチェックを追加する」というフォローアップが残る。
大きなプロセスは不要です。信頼性を目に見える状態に保ちながら開発時間を浪費しない小さな習慣が必要です。20分のチェックインは有効です。すべてを一つの問いに還元します:想定より早く信頼性を消費しているか?
毎週同じ時間に予定を入れ、追記していく共有ノートを一つだけ持ちます(書き直さない)。一貫性が詳細より勝ります。
簡単なアジェンダ:
フォローアップとコミットメントの間で、今週のリリースルールを決めて単純に保ちます:
サインアップで短時間の障害が2回あってバジェットを大半消費していれば、サインアップ関連の変更だけを凍結して、他の作業は続けるといった運用ができます。
エラーバジェットは翌週の行動を変えないと意味がありません。目的は完璧な稼働率ではなく、次に何をするかを明確にすることです:機能を出すのか、信頼性負債を返すのか?
口に出して言える方針:
これは罰ではなく、公然のトレードオフです。ブレーキをかけるときは「安定性を改善する」などの曖昧なタスクを避け、次の結果を変える具体的な変更を選びます:ガードレール(タイムアウト、入力検証、レート制限)、バグを検出できたテストの改善、ロールバックを簡単にする、最も多いエラー源を直す、あるいはユーザージャーニーに結びついたアラートを追加する。
報告と責任追及は切り分けます。インシデント報告は早い方が良い。細部が乱れていても速やかな報告を奨励してください。最悪なのは、誰も何が変わったか覚えていない遅い報告です。
よくある罠は、初日から金ぴかのSLO(99.99%など)を設定し、現実に直面すると静かに無視されることです。スターターSLOは現在の人員とツールで達成可能でないと、背景ノイズになってしまいます。
別の誤りは間違ったものを測ることです。サービスやデータベースのグラフを5個見ているのに、ユーザーが感じるジャーニー(サインアップ、チェックアウト、保存)が見えていないことがあります。SLOをユーザー視点で1文で説明できないなら、それは多分内部的すぎます。
アラート疲れは本番を直せる唯一の人を燃え尽きさせます。小さなスパイクで誰かを呼び出すと、それが「普通」になり、本物の火事を見逃します。ユーザー影響でページングし、その他は日次チェックに回すべきです。
静かな殺し屋は一貫性のないカウントです。ある週は2分の遅延をインシデントとして数え、次の週は数えないとバジェットが議論の的になります。ルールを書いて一貫して適用しましょう。
役立つガードレール:
もしデプロイでログインが3分壊れたら、速く直せても毎回カウントしてください。継続性がバジェットを有用にします。
タイマーを10分にセットして共有ドキュメントを開き、次の5つに答えてください:
まだ測れないなら、すぐに見られるプロキシで始めてください:失敗した支払い、500エラー、または「checkout」とタグ付けされたサポートチケットなど。追跡が改善したらプロキシを置き換えます。
例:二人チームが今週パスワードリセットが3件失敗したのを見たとします。もしパスワードリセットが保護されたジャーニーなら、それはインシデントです。短いノートを書き(何が起こったか、何人、何をしたか)フォローアップを1つ選びます:リセット失敗のアラートを追加するか、リトライを入れるか。
MayaとJonは二人で週に一度リリースするスタートアップを運営しています。彼らは速く動きますが、最初の有料ユーザーは一つのことを気にします:プロジェクトを作成してチームメンバーを招待できるか。
先週、彼らは一つの大きな障害を経験しました:悪いマイグレーションの後、"Create project"が22分間失敗しました。また画面が8〜12秒回り続ける「遅いが死んでいない」状態が3回あり、ユーザーから苦情が出ましたが、遅さを「ダウン」とみなすかどうかで議論が続きました。
彼らは一つのジャーニーを測定可能にしました:
月曜に彼らは20分のルーティンを実行しました。同じ時間、同じドキュメントです。起こったこと、どれだけバジェットを消費したか、何が繰り返されたか、繰り返しを防ぐための一つの変更は何か、を答えました。
結果は明白になりました:障害と遅延で週のバジェットをほとんど使っていたので、翌週の「大きな機能」は「DBインデックスを追加し、マイグレーションを安全にし、create-project失敗のアラートを入れる」に変わりました。
結果は完璧な信頼性ではありません。繰り返す問題が減り、イエス/ノーの判断が明確になり、何が「十分に悪いか」を事前に合意していたため深夜の対応が減りました。
一つのユーザージャーニーを選び、そこでシンプルな信頼性の約束を作ってください。エラーバジェットは完璧ではなく、退屈で繰り返しやすいときに最もよく機能します。
まずは一つのSLOと一つの週次ルーティンから始めます。1か月経っても楽なら2つ目を追加し、重く感じるなら縮小してください。
算数は単純に(週次か月次)。目標は今の状況に現実的であること。SLOと測定法、インシデントの定義、今週のオンポイント、チェックインの時間、バジェットが速く燃えるときのデフォルト動作を答える1ページの信頼性ノートを書きましょう。
もしKoder.ai(koder.ai)のようなプラットフォーム上で構築しているなら、スナップショットとロールバックを組み合わせて高速な反復と安全習慣を両立できます。「最後の良い状態に戻す」が普通の、練習された動きであることが役立ちます。
ループを短く保ってください:一つのSLO、一つのノート、一つの短い週次チェックイン。目的はインシデントを無くすことではなく、早く気づき、落ち着いて判断し、ユーザーが実際に感じる少数のことを守ることです。
SLOはユーザー体験に関する信頼性の約束で、一定の期間(例:7日や30日)で測ります。
例:「過去7日間でチェックアウトの成功率が99.5%」
エラーバジェットはSLOの中で許容される「悪い部分」の量です。
もしSLOが99.5%の成功率なら、その期間の失敗は0.5%まで許容されます。バジェットを早く使い切っていると判断したら、リスクの高い変更を止めて原因を直します。
まずは1~3つのジャーニーを守ることから始めましょう:
これらが安定していれば、他の問題は小さく感じられ、優先順位付けが楽になります。
現状で達成できるベースラインから始めましょう。
今日98.5%なら、99.9%と宣言して無視されるより98–98.5%から始めるほうが有用です。
監視が弱いかトラフィックが少ない場合は、試行回数と成功回数の単純なカウントを使います。
良い出発点:
完璧な可観測性を待たず、信頼できるプロキシで始めて一貫性を保ちましょう。
外部のユーザーが気づいて保護されたジャーニーを完了できないなら、それはインシデントとしてカウントします。
予算にカウントする例:
内部だけの不便は、内部利用が主でない限りカウントしません。
ルールは簡単:バジェット消費に対してアラートを出す。すべての小さなブリップで人を起こさないように。
有効な2種類のアラート:
こうしてアラート疲れを減らし、出荷方針を変えるような問題に集中できます。
20分、同じ時間、同じドキュメントで行う短い習慣にします:
最後に週間のリリース方針を決めます:Normal(通常)、Cautious(注意)、Freeze(該当領域のみ凍結)
デフォルトのポリシーで簡単に判断できるようにします:
これは罰ではなく、公然のトレードオフです。曖昧な「安定性の改善」ではなく、次の結果を変える具体的な変更を選びましょう(タイムアウト、入力検証、ロールバックの簡素化など)。
いくつかの実践的なガードレール:
Koder.aiのようなプラットフォーム上で構築しているなら、「最後の良い状態に戻す」を普通の手順にし、繰り返されるロールバックはテストやデプロイチェックへの投資サインにしましょう。