2025年8月18日·1 分
ソフトデリート vs ハードデリート:実際のアプリで重要なトレードオフ
ソフトデリートとハードデリートの実務上のトレードオフを解説。分析、サポート、GDPR 風の削除、クエリの複雑さと安全な復元パターンについて学びます。
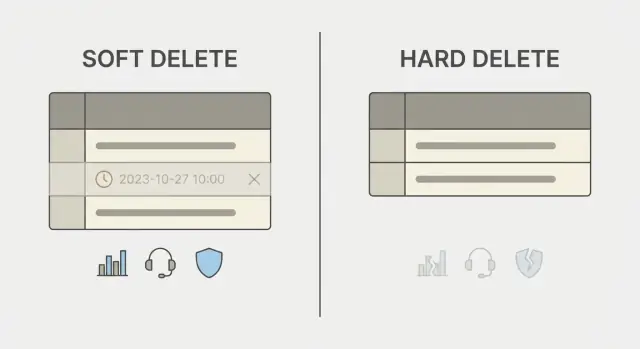
ソフトデリートとハードデリートが本当に意味すること
データベースで「削除」ボタンが意味することは、実は二通り以上あります。
ハードデリートは行を削除します。その後、そのレコードはバックアップやログ、レプリカがない限り消えます。考え方は単純ですが、取り消せません。
ソフトデリートは行を残しつつ削除済みとしてマークします。通常は deleted_at や is_deleted のようなフィールドで示し、アプリはマークされた行を表示しないようにします。関連データを保ち、履歴を残し、場合によってはレコードを復元できます。
この選択は人々が思うより日々の仕事に影響します。「先月の収益が減ったのはなぜ?」「削除したプロジェクトを戻せますか?」「GDPR に基づく削除依頼が来た——個人データは本当に削除されているのか?」などに答える方法を左右します。UI における「削除」の意味も変わります。多くのユーザーは元に戻せると想定しますが、戻せないことに気づくまでそれを期待します。
実用的な目安:
- ユーザーが元に戻せることを期待する場合、サポートがミスを回復する必要がある場合、または監査トレイルが求められる場合はソフトデリートを使う。
- データを保持することが法的・セキュリティ上のリスクになったり、明確な価値のない保存コストだけが発生する場合はハードデリートを使う。
- 「ゴミ箱」期間を設けたいなら両方を使う:まずソフトデリートして、後で完全にパージする。
例:顧客がワークスペースを削除し、あとでその中に会計で必要な請求書があったと気づいたとします。ソフトデリートならサポートは復元できます(復元が安全にできる設計であれば)。ハードデリートだと、バックアップや復元の説明をする羽目になり、対応に時間や制約が出ます。
どちらが「最良」かは一概には言えません。ユーザーの信頼、レポートの正確さ、プライバシー遵守など、何を守るべきかによって最も痛みが少ない選択は変わります。
分析のトレードオフ:正確さ vs 履歴の保持
削除の選択は分析にもすぐに影響します。有効ユーザー、コンバージョン、収益を追い始めると、「削除済み」は単純な状態ではなく報告ルールの問題になります。
ハードデリートをすると、削除されたレコードがクエリから消えるため多くの指標はクリーンに見えます。しかし過去のサブスクリプションやチームサイズ、前月のファネルがどうだったかといった文脈を失います。削除された顧客により過去のチャートが再実行時に変わると、財務やグロースのレビューで問題になります。
ソフトデリートをすると履歴は残りますが、数値が膨らむリスクがあります。「COUNT users」だけだと退会した人も含まれるかもしれません。deleted_at をチャーンとみなすレポートと無視するレポートが混在すると二重カウントが起きます。請求書は残るがアカウントが削除済みとマークされると収益の扱いも複雑になります。
うまくいくのは、一貫した報告パターンを決めて守ることです:
- 「現在の状態」指標(有効ユーザー、現行MRR)では削除済みをフィルタする。
- 時間ベースのダッシュボードにはスナップショットテーブルを使い、エンティティが後で削除されても履歴が変わらないようにする。
- 事実(支払い、ログイン)を示す不変のイベント行は保持し、ユーザーレコードは隠す。
- 「削除」はライフサイクルの状態として日付を付けて明示的に報告する(作成、アクティブ化、削除)。
- 保持ウィンドウを定義する:ソフトデリートされたデータがいつ真に削除されるか。
重要なのはドキュメント化です。アナリストが推測しないように「有効」の定義、ソフトデリート済みユーザーを含めるか、アカウント削除後の収益帰属ルールを書き残してください。
具体例:ワークスペースが誤って削除され、復元されたケース。ダッシュボードがワークスペースをフィルタせずにカウントしていると、実際には起きていない急な落ち込みと回復が表示されます。スナップショットを使えば履歴チャートは安定したまま、製品側ビューでは削除済みを隠せます。
サポートと監査トレイル:あとで何を復元できるか
削除に関するサポートチケットは大抵似ています:「誤って削除した」「私のレコードはどこ?」。削除戦略がサポートが数分で答えられるか、それとも「消えました」が正直な回答になるかを決めます。
ソフトデリートがあれば通常は何が起きたかを確認して元に戻せます。ハードデリートだとサポートはバックアップに頼るしかなく、それは遅く不完全で、単一アイテムの復旧は不可能なことが多いです。だからこの選択は単なるデータベースの詳細ではありません。問題発生後に製品がどれだけ「助けになる」かを形作ります。
シンプルな監査トレイル(保存すべき項目)
本当にサポートが必要なら、削除イベントを説明するいくつかのフィールドを追加してください:
deleted_at(タイムスタンプ)deleted_by(ユーザーID または system)delete_reason(任意、短いテキスト)deleted_from_ipまたはdeleted_from_device(任意)restored_atとrestored_by(復元をサポートするなら)
完全なアクティビティログがなくても、これらの詳細があればサポートは「誰が」「いつ」削除したか、事故だったのか自動削除だったのかを答えられます。
ハードデリートがサポートにもたらす意味
ハードデリートは一時データには問題ありませんが、ユーザー向けレコードに使うとサポートのできることが変わります。
サポートは単一のレコードを簡単に復元できません。リサイクルビンを別に作っていない限り、フルバックアップの復元が必要になり、それは他のデータにも影響します。さらに何が起きたか証明するのが難しくなり、長いやり取りが増えます。
復元機能があると作業量も変わります。ユーザーが一定期間自己復元できればチケットは減ります。復元にサポートの手作業が必要だとチケットは増えるかもしれませんが、個別調査ではなく速く繰り返せる作業になります。
GDPR 風の削除:ソフトデリートは完全な削除ではない
「忘れられる権利」は通常、個人データの処理を停止し、まだ使える形で残っている場所から削除することを意味します。必ずしもすべての集計を即座に消す必要はありませんが、法的根拠がないのに識別可能なデータを「念のために」保持してはいけません。
ここでソフトデリート vs ハードデリートは単なるプロダクトの選択以上の意味を持ちます。ソフトデリート(deleted_at の設定など)はアプリからはレコードを隠しますが、データベースには残り、管理者がクエリ可能で、エクスポート、検索インデックス、分析テーブルに残っていることが多いです。多くの GDPR 削除要求に対して、それは消去には当たりません。
次のような場合はパージ(完全削除/匿名化)が必要です:
- ユーザーが削除を求め、保持の正当な理由がない場合(請求ルールなどがないとき)。
- 特別カテゴリデータを保存していて方針で削除が定められている場合。
- レコードがユーザー向けエクスポートに現れる、またはサポートで回復可能な場合。
- サードパーティのプロセッサ(メール、分析、サポートツール)がまだ保持している場合。
チームが忘れがちなのはバックアップとログです。暗号化されたバックアップから単一行を削除できない場合がありますが、ルールを決めておけば対処できます:バックアップは短期間で有効期限が切れるようにし、復元後は削除イベントを再適用してからシステムを公開する。ログには可能な限り生の個人データを記録しない、保持期間を明確にする、といった対策を取りましょう。
実用的なポリシー例は二段階の削除です:
- まず即座にソフトデリートする(製品上の挙動を正しくし、アカウントを無効化し、誤操作の復元を可能にする)。
- 保持タイマーを開始する(例:7〜30日)とともに、パージジョブをスケジュールして個人情報フィールドをハードデリートまたは匿名化する。
- 何が行われたかを非識別マーカー(タイムスタンプ、理由コード)で監査トレイルに記録し、サポートが説明できるようにする。
プラットフォームがソースコードのエクスポートやデータエクスポートをサポートしている場合、エクスポートされたファイルもデータストアとして扱い、保管場所、アクセス制限、削除時期を定義してください。
クエリの複雑さとプロダクト挙動:隠れたコスト
準備ができたらソースをエクスポート
アプリを生成したら、コードベースをエクスポートして完全に管理します。
ソフトデリートは簡単に聞こえます:deleted_at(または is_deleted)フラグを追加して行を隠すだけ。ただし隠れたコストは、データを読むすべての場所でそのフラグを意識する必要があることです。一度でも見落とすと、合計に削除済みが含まれる、検索にゴースト結果が出る、ユーザーが消えたはずのものを見てしまう、などの奇妙なバグが出ます。
UI/UX の端のケースはすぐに出ます。チームが「Roadmap」というプロジェクトを削除し、後で同じ名前の新しい「Roadmap」を作ろうとすると、もし名前にユニーク制約がかかっていると削除済み行が残っているせいで作成に失敗します。リストでは削除済みを隠しているのにグローバル検索では隠していないと、ユーザーはアプリが壊れていると思います。
ソフトデリートのフィルタはよく漏れるところ:
- 管理ダッシュボードやサポートツール
- バックグラウンドジョブ(メール、リマインダー、クリーンアップ)
- 分析クエリとエクスポート
- 権限チェック(「このレコードは存在するか?」)
- オートコンプリートや検索
パフォーマンスは最初は問題になりませんが、条件が増える分だけ作業量は増えます。ほとんどの行が有効状態なら deleted_at IS NULL は安いですが、削除済みの行が多いとスキップするコストが増えます。平たく言えば:現行ドキュメントを探すのに古いものも混ざった引き出しを毎回探すようなものです。
「アーカイブ」専用エリアは混乱を減らします。デフォルトビューは有効なレコードのみ表示し、削除済みは明確にラベル付けして時間窓を設けてまとめておきましょう。内部ツールを素早く作るとき(例えば Koder.ai のようなツールで)この設計判断がクエリのトリックよりも多くのサポートチケットを防ぐことがよくあります。
ソフトデリートの一般的なデータモデル
ソフトデリートは単一の機能ではなく、データモデルの選択です。どのモデルを選ぶかで、クエリルール、復元挙動、「削除」がプロダクトでどう扱われるかが決まります。
モデル1:deleted_at と deleted_by
最も一般的なのは nullable なタイムスタンプです。削除時に deleted_at をセットし、多くの場合 deleted_by にユーザーIDを入れます。有効なレコードは deleted_at が null のものです。
復元が必要な場合は、復元は deleted_at と deleted_by をクリアするだけで済むためわかりやすい復元が可能です。サポートの監査信号としてもシンプルです。
モデル2:明示的なステータス状態
タイムスタンプの代わりに status フィールドで active、archived、deleted のような明確な状態を使うチームもあります。archived が実際のプロダクト状態(例:多くの画面から隠すが請求にはカウントする)であるときに有用です。
コストはルールです。各状態が検索、通知、エクスポート、分析で何を意味するかをどこでも定義しなければなりません。
モデル3:高価値レコードのための分離ストレージ
機密性の高い、または高価値のオブジェクトでは、削除された行を別テーブルに移すか、追記専用のログにイベントを記録することがあります。
- タイムスタンプ方式:
deleted_at,deleted_by - ステートマシン: 名前付き状態を持つ
status - 削除専用テーブル: 「有効」テーブルを小さく保つ
- イベントログ: フル行を永遠に残さずに「誰が何をしたか」を保持する
復元を厳密にコントロールしたい場合や、日常のクエリに削除データを混ぜたくない場合に使われます。
子レコードにも意図的なルールが必要です。ワークスペースが削除されたらプロジェクト、ファイル、メンバーシップはどうなるか?
- カスケード: 子も同時に削除済みにする
- 制限: 子を処理するまで削除をブロックする
- アーカイブ: 子を
archivedに変換する(削除ではない) - 切り離し: リレーションを外すが子は保持する
関係ごとにルールを一つ選び、文書化して一貫性を保ってください。復元で問題が起きる多くは親子レコードで「削除」の意味が異なることが原因です。
安全な復元機能を実装する(ステップバイステップ)
復元ボタンは単純に聞こえますが、権限を壊したり、古いデータを間違った場所に戻したり、ユーザーを混乱させたりします。まず製品が約束する正確な内容を書き出してください。
実用的な復元フロー
小さく厳格な手順を使い、復元を予測可能かつ監査可能にします。
- 「復元」の意味を定義する。 レコードは同じ ID を保つか?同じ親(ワークスペース、プロジェクト)に戻すか?メンバーシップ、役割、可視性はどうなるかを決める。
- ユーザーに確認させ、理由を取得する。 復元されるもの(名前、所有者、最終更新日)を表示し、明確な確認を求める。サポート向けには短い理由欄(「誤削除」「チケット対応」)で十分なことが多い。
- 何も変更する前に衝突をチェックする。 よくある問題:古い名前が再利用されている、ユーザーの権限が変わっている、関連レコードがハードデリートされている。復元をブロックして明確なメッセージを出すか、保留状態(要レビュー)で復元するかを選ぶ。
- 復元アクションをログに残す。 誰がいつどこから(UI、API)復元したか、何が変わったかを記録する。監査とサポートに役立ち、「なぜ戻ったのか?」という問いに答えるために必須。
- 期間制限を設ける。 多くのアプリは 30 日や 90 日の復元期間を許容し、その後は別の復旧プロセスを要求するか恒久的扱いにする。
Koder.ai のようなチャット駆動ツールで素早くアプリを作る場合、これらのチェックを生成ワークフローの一部にして、画面やエンドポイントすべてが同じルールを守るようにしてください。
よくあるミスと落とし穴
削除のエッジケースをテストする
スキーマを確定する前に、元に戻すウィンドウや一意フィールド衝突を試してください。
ソフトデリートによる最大の痛みは削除自体ではなく、レコードが「消えた」ことを忘れているすべての場所です。多くのチームは安全のためにソフトデリートを選びますが、検索結果やバッジ、合計に削除済みが表示されてしまうことに気づいていません。ユーザーは「12 件のプロジェクト」と表示されているがリストに 11 件しかないとすぐに気づきます。
次に多いのはアクセス制御の抜けです。ユーザー、チーム、ワークスペースがソフトデリートされているならログインや API 呼び出し、通知を受け取るべきではありません。ログインチェックがメールで検索して行を見つけるが削除フラグを確認しないと、これが漏れます。
後でサポートチケットを生む典型的な落とし穴:
- 読み取りパスのどこかで削除フィルタを忘れている(管理ビュー、エクスポート、検索、バックグラウンドジョブ)。
- 一意フィールド(メール、ユーザー名、スラッグ、請求書番号)と復元が衝突する。
- 親を削除して子を「有効」のままにする、あるいは親は生きているのに子を削除する。
- 分析、クォータ、請求計算に削除済み行をカウントしてしまう。
- 統合や同期ジョブが「削除」を理解せず、削除済みデータを第三者に送ってしまう。
復元時の一意性衝突は特に厄介です。古いアカウントがソフトデリート中に誰かが同じメールで新規アカウントを作ると、復元は失敗するか誤って別人を上書きする可能性があります。事前にルールを決めてください:パージまで再利用をブロックする、再利用は許すが復元は禁止する、復元時に新しい識別子を使う、など。
よくあるシナリオ:サポートがソフトデリートされたワークスペースを復元します。ワークスペースは戻るがメンバーは削除されたまま、統合が古いレコードをパートナーに同期し始める。ユーザーから見ると復元は「半分成功」で新たな混乱を招きます。
リリース前に次の点を明確にしてください:
- ログイン、APIアクセス、通知について「削除」がどう扱われるか
- 復元が一意フィールドや所有権をどう扱うか
- 関連レコードが親にどう従うか(一斉復元が驚きよりはマシ)
- エクスポートと統合が削除データをどう扱うか(除外、ラベル付け、トゥームストーン送信)
現実的な例:誤って削除されたワークスペース
ある B2B SaaS チームに「ワークスペース削除」ボタンがあります。ある金曜、管理者がクリーンアップを実行し、使われていないように見えた 40 件のワークスペースを削除しました。月曜日に 3 件の顧客からプロジェクトが消えたと苦情が来て即時復元を求められます。
チームは単純な判断になるだろうと考えていましたが、そうではありませんでした。
最初の問題:本当に削除されたものはサポートで復元できません。ワークスペース行がハードデリートされ、プロジェクト、ファイル、メンバーシップがカスケードで消えた場合、唯一の選択肢はバックアップです。時間とリスクがかかり、顧客への答えは気まずくなります。
二つ目の問題:分析が壊れて見えます。ダッシュボードは deleted_at IS NULL で「アクティブなワークスペース」を数えているため、誤削除で採用数の急落が表示されます。週次レポートが先週と比較して偽のチャーンスパイクを示すかもしれません。データが失われたわけではないが、誤った場所で除外されてしまったのです。
三つ目の問題:影響を受けたユーザーのうちの一人からプライバシー削除の要請が来ます。純粋なソフトデリートでは不十分です。チームは個人フィールド(名前、メール、IP ログ)をパージする計画を立てる必要がありますが、請求合計や請求番号のような個人を特定しない集計は残すことも考慮します。
四つ目の問題:誰が削除ボタンを押したのか。トレイルがなければサポートは説明できません。
より安全なパターンは削除をメタデータ付きのイベントとして扱うことです:
- ワークスペースを削除済みとしてマークし(製品上は非表示にする)
deleted_by、deleted_at、理由かチケットIDを記録する- 影響範囲(プロジェクト数、席数、ストレージ)をログに残す
- 一定期間内なら復元を許し、その後必要に応じて個人フィールドをパージする
これはチームが Koder.ai のようなプラットフォームで素早く構築しがちなワークフローの例で、削除ポリシーは機能と同じくらい設計が必要だと後で気づくことが多い部分です。
正しい削除戦略を選ぶためのクイックチェックリスト
削除ポリシーを設計する
構築前にリストア、パージ、監査ルールをプランモードで定義しましょう。
ソフトデリートかハードデリートかの選択は好みの問題ではなく、レコードが「消えた」後にアプリが保証すべきことに関する問題です。クエリを書く前に次を自問してください。
- 本当に消去が必要になることはあるか? プライバシーや法的要求を満たす必要があるなら完全削除(バックアップやエクスポート、キャッシュも含む)を計画する。ソフトデリートのフラグだけでは「完全に削除する」要件は満たせない。
- 復元ボタンは必要か、必要ならどのくらいの期間か? 元に戻すことが重要なら復元ウィンドウ(7日、30日、永久など)と期限切れ後の扱いを決める。
- 削除後もレポーティングに古いデータが必要か? 一部のチームはチャートに現在の見え方を反映したい。別のチームは財務や成長分析のために履歴カウントが必要。削除の選択は「有効ユーザー」や「総収益」の意味を変える。
- サポートは推理なしに何が起きたか説明できるか? 「プロジェクトが消えた」と聞かれたら、誰がいつどこで削除したかを示すトレイルが必要か。
- 挙動をどこでも一貫して保てるか? ソフトデリートは隠れたルールを生みやすい:すべてのクエリが削除フィルタを行い、すべての結合が期待通りに振る舞い、すべての画面が「削除」の意味に同意する必要がある。
決定を検証する簡単な方法は、1つの現実的なインシデントを選んで通しで考えることです。例えば:誰かが金曜夜にワークスペースを誤削除した。月曜にサポートは削除イベントを確認し、安全に復元し、残すべきデータを誤って復元しないようにする。Koder.ai のようなプラットフォームで作るなら、これらのルールを早めに定義して生成されるバックエンドと UI が一貫したポリシーに従うようにしてください。
次のステップ:ポリシーを決めて安全に実装する
チームとサポートに共有できるシンプルなポリシーを書いてアプローチを決めてください。書かれていなければポリシーは揺らぎ、ユーザーは不整合を感じます。
まず平易なルールセットから始めましょう:
- 何をソフトデリートするか(どの程度の期間復元可能にするか)
- 何を即時ハードデリートするか(その理由)
- ソフトデリートデータをいつパージするか(例:X 日後)
- 誰が復元できるか、証拠や承認は必要か
- プライバシー由来の削除要求をエンドツーエンドでどう扱うか
次に混じらない2つの明確なパスを作ります:間違い用の「管理者復元」パスと、実際の削除用の「プライバシーパージ」パス。復元パスは可逆でログを残す。パージパスは最終処理で、識別可能な関連データをすべて削除または匿名化する(方針で要求される場合はバックアップやエクスポートも含む)。
削除データが製品に漏れ戻らないようにガードレールを追加してください。最も簡単な方法は「削除」をテストで第一級の状態として扱うことです。新しいクエリ、一覧ページ、検索、エクスポート、分析ジョブにはレビューのチェックポイントを追加しましょう。良いルールは:画面がユーザー向けデータを表示するなら、削除レコードについて明確な決定(非表示、ラベル付き表示、管理者限定)を必ず持つことです。
プロダクトの初期段階なら、スキーマを確定する前に両方のフローをプロトタイプしてください。Koder.ai では計画モードで削除ポリシーをスケッチし、基本的な CRUD を生成して復元とパージのシナリオを素早く試し、スキーマに確定を入れる前に調整できます。