2025年10月23日·1 分
サーバー側 vs クライアント側 フィルタリング — 判断チェックリスト
データ量、レイテンシ、権限、キャッシュを基準に、UIの情報漏えいや遅延を防ぐためのサーバー側/クライアント側フィルタリングの選択チェックリスト。
データ量、レイテンシ、権限、キャッシュを基準に、UIの情報漏えいや遅延を防ぐためのサーバー側/クライアント側フィルタリングの選択チェックリスト。
UIでのフィルタリングは単なる検索ボックス以上のものです。通常、テキスト検索(名前、メール、注文ID)、ファセット(ステータス、担当者、日付範囲、タグ)、ソート(新着、高額、最終活動)など、関連するいくつかの操作が組み合わさって表示内容を変えます。
重要な問いは「どちらの手法が良いか」ではなく、フルデータセットがどこにあり、誰がそれにアクセスできるかです。ブラウザがユーザーに見せてはいけないレコードを受け取ると、見えなくしていてもUIから機密データが露出する可能性があります。
サーバー側とクライアント側のフィルタリングに関する議論の多くは、実際にはユーザーがすぐに気づく2つの失敗への反応です:
さらに厄介なのは結果の不一致です。あるフィルタはクライアントで、別はサーバーで動くと、ユーザーはカウントやページ、合計が合わないのを見ます。特にページネーションがある場合、信頼が急速に壊れます。
実践的なデフォルトは単純です:ユーザーがフルデータセットにアクセスできないならサーバー側でフィルタする。アクセスが許され、かつデータセットが短時間で読み込めるほど小さいならクライアント側フィルタでも問題ありません。
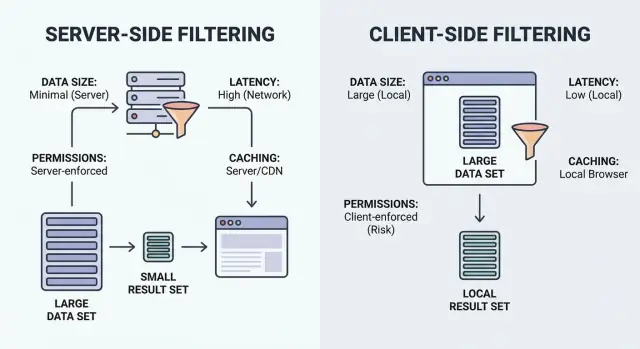
フィルタリングは「条件に合う項目を見せて」というだけです。重要なのは「一致の処理がどこで行われるか」:ユーザーのブラウザ(クライアント)か、バックエンド(サーバー)か。
クライアント側フィルタリングはブラウザで動きます。アプリは一連のレコード(多くはJSON)をダウンロードしてからローカルでフィルタを適用します。データが読み込まれた後は瞬時に感じられることがありますが、データ量が小さく安全に公開できる場合に限ります。
サーバー側フィルタリングはバックエンドで動きます。ブラウザがフィルタ入力(例えば status=open, owner=me, createdAfter=Jan 1)を送り、サーバーは一致する結果だけを返します。実務では、フィルタを受け取りデータベースクエリを組み立て、ページネーションされたリストと合計を返すAPIエンドポイントになることが多いです。
シンプルな頭の中のモデル:
ハイブリッドな構成は一般的です。良いパターンは、サーバーで「大きな」フィルタ(権限、所有権、日付範囲、検索)を強制し、UI上の小さなトグル(アーカイブを隠す、簡易タグ、列の表示/非表示)をローカルで処理して追加リクエストを避けることです。
ソート、ページネーション、検索も同じ判断に含めるべきです。ペイロードサイズ、ユーザー体感、公開するデータに影響します。
まず実用的な問い:クライアントでフィルタする場合にブラウザにどれだけのデータを送ることになるか?正直な答えが「数画面分より多い」なら、ダウンロード時間、メモリ使用、操作の遅さで代償を払います。
完璧な見積もりは要りません。桁感覚を掴んでください:ユーザーが見る可能性のある行数と、行ごとの平均サイズはどれくらいか。短いフィールド数個の500件と、長いノートやリッチテキスト、ネストされたオブジェクトを含む50,000件は全く異なります。
ワイドなレコードは静かなるペイロードキラーです。行数は少なく見えても、各行に多くのフィールド、大きな文字列、結合データ(担当者+企業+最終活動+住所全文+タグ)が含まれると重くなります。表示は3列でも、チームが「念のため全部送ろう」とするとペイロードが膨らみます。
また成長にも注意してください。今日問題ないデータセットが数ヶ月で耐え難くなることがあります。データが急速に増えるなら、クライアント側フィルタを短期的な抜け道と考え、デフォルトにしないでください。
経験則:
最後のポイントはパフォーマンス以上に重要です。「ブラウザにフルデータセットを送れるか?」はセキュリティの問いでもあります。自信を持って「はい」と言えないなら送らないでください。
フィルタリングの選択は正確さで失敗するより体感で失敗することが多いです。ユーザーはミリ秒を測りません。入力時の停止、フリッカー、結果が打鍵中に飛んだりするのを感じます。
時間は異なる場所で失われます:
この画面で「十分に速い」とは何かを定義してください。リストビューは入力時の応答性とスムーズなスクロールが必要なことが多く、レポートページは最初の結果が素早く出れば短い待ち時間を許容できます。
オフィスのWi‑Fiだけで判断しないでください。遅い接続では、クライアント側フィルタは初回ロード後は快適に感じますが、その初回ロード自体が遅い可能性があります。サーバー側はペイロードを小さく保ちますが、各キー入力でリクエストを発行すると遅延を感じさせることがあります。
人間の入力を設計に組み込みましょう。タイピング中はリクエストをデバウンスしてください。大きな結果セットでは段階的読み込みを使い、ページが何かを素早く表示してスクロール中もスムーズに保つようにします。
権限は速度よりもフィルタリングアプローチを決めるべきです。ブラウザがユーザーに見せてはいけないデータを受け取った時点で問題です。ボタンを無効にする、列を折りたたむなどの見せ方はアクセス制御にはなりません。
この画面で何が機密かをまず名付けてください。明らかなフィールド(メール、電話、住所)もあれば、見落としやすいものもあります:内部メモ、コストやマージン、特別価格ルール、リスクスコア、モデレーションフラグなど。
最大の落とし穴は「クライアントでフィルタするが、許可された行だけ表示する」と考えることです。フルデータセットをダウンロードしてしまっていれば、誰でもネットワークレスポンスを調べたり、データを保存できます。UIで列を隠すだけではアクセス制御になりません。
ユーザーごとに権限が異なるとき(特に異なるユーザーが異なる行やフィールドを見られる場合)は、サーバー側フィルタが安全なデフォルトです。
簡単なチェック:
いずれかが「はい」なら、フィルタとフィールド選択はサーバー側で適用してください。検索、ソート、ページネーション、エクスポートにも同じルールを適用すること。
例:CRMの連絡先リストで、営業担当は自分のアカウントのみを見られ、マネージャーはチーム全体を見られるとします。ブラウザが全連絡先をダウンロードしてローカルでフィルタすると、営業担当でもレスポンスから隠されたアカウントを復元できてしまいます。サーバー側フィルタはそのような行をそもそも送らないことで防げます。
キャッシュは画面を瞬時に感じさせますが、間違った真実を見せることもあります。重要なのは何をどれくらい再利用できるか、どのイベントで無効化するかを決めることです。
まずキャッシュ単位を選んでください。フルリストをキャッシュするのは簡単ですが帯域の無駄で陳腐化しやすいです。無限スクロールにはページ単位のキャッシュがよく合います。クエリ結果(フィルタ+ソート+検索)をキャッシュすると正確ですが、ユーザーが多くの組み合わせを試すと項目数が急増します。
鮮度はドメインによって重要度が変わります。データが頻繁に変わる(在庫、残高、配送状況)なら30秒のキャッシュでもユーザーを混乱させます。遅く変わるデータ(アーカイブ済みレコード、参照データ)なら長めのキャッシュで問題ないことが多いです。
コードを書く前に無効化計画を立ててください。時間経過以外に、どの操作で必ずリフレッシュするかを決めます:作成/編集/削除、権限変更、一括インポートやマージ、ステータス遷移、アンドゥ/ロールバック、ユーザーがフィルタするフィールドを更新するバックグラウンドジョブなど。
またキャッシュの場所も決めてください。ブラウザメモリは戻る/進むを速くしますが、ユーザーや組織をキー化していないとアカウント間でデータを漏らします。バックエンドキャッシュは権限と一貫性面で安全ですが、フィルタ署名と呼び出し元の識別を含めないと結果が混ざるリスクがあります。
目標は譲れません:画面は速く感じ、データを漏らさないこと。
多くのチームは同じパターンで躓きます:デモでは綺麗に見えたUIが、実データ、実権限、実ネットワーク速度で欠点を露呈します。
最も深刻なのはフィルタリングを単なる表示処理と扱うことです。ブラウザが見てはいけないレコードを受け取った時点で負けです。
よくある原因:
例:インターンは自分の地域のリードのみ見るべきなのに、APIが全地域を返し、Reactでドロップダウンでフィルタしていると、インターンはフルリストを抽出できます。
遅延は多くの場合仮定から生まれます:
もう一つ微妙で痛い問題はルールの不一致です。サーバーが「前方一致」、UIが「部分一致」を使うなどの差で、カウントが合わない、リフレッシュ後にアイテムが消えるといった現象が起きます。
好奇心旺盛なユーザーと、回線の悪い日の2つの視点で最終確認をしてください。
簡単なテスト:制限付きのレコードを作り、広くフィルタしたりフィルタをクリアしても、そのレコードがペイロード、合計、キャッシュに一度も現れないことを確認してください。
200,000件の連絡先があるCRMを想像してください。営業は自分のアカウントのみ、マネージャーはチーム全体、管理者は全てを見ることができます。画面には検索、フィルタ(ステータス、担当者、最終活動)、ソートがあります。
ここではクライアント側フィルタはすぐに破綻します。ペイロードが重くなり初回ロードが遅くなり、データ漏えいのリスクが高まります。UIが行を隠してもブラウザはデータを受け取っています。さらにデバイスに負担をかけます:大きな配列、重いソート、繰り返しのフィルタ実行、高メモリ使用、古い端末でのクラッシュ。
安全なアプローチはページネーション付きのサーバー側フィルタです。クライアントはフィルタ選択と検索テキストを送り、サーバーはユーザーが許可された行だけをフィルタ・ソートして返します。
実践パターン:
小さな例外として、微小で静的なデータはクライアント側で問題ありません。8個の値しかない「連絡先ステータス」ドロップダウンは一度読み込めばローカルでフィルタしてもほとんどリスクもコストもありません。
チームが一度の誤採用で燃えるわけではありません。同じ画面ごとに別の選択をして、漏えいや遅いページを差し迫った中で直そうとすることで痛手を被ります。
画面ごとに短い決定メモを書いてください:フィルタ一覧、データサイズ、ブラウザに送るコスト、「十分な速さ」の基準、機密フィールド、キャッシュ方針(するかしないか)など。サーバーとUIを揃えて、フィルタで「二つの真実」が生まれないようにします。
Koder.ai (koder.ai)で画面を素早く作っているなら、どのフィルタをバックエンドで強制し(権限や行レベルアクセス)、どの小さなUIトグルをReact側に残すかを事前に決める価値があります。その1つの選択が後で最も高価な書き直しを防ぎます。
デフォルトでは、ユーザーごとに表示できるデータが異なる場合、大きなデータセットがある場合、またはページネーションや合計が一貫している必要がある場合はサーバー側を採用してください。クライアント側は、全データセットが小さく、公開しても安全で、ダウンロードが速い場合のみ使用します。
ブラウザが受け取ったものは誰でも確認できます。UI上で行や列を隠していても、ネットワークレスポンス、キャッシュ、メモリ内オブジェクトからデータを取得される可能性があります。
主に、過剰なデータを送って大きな配列を毎キーストロークでフィルタ・ソートするか、入力ごとにサーバーリクエストを送ってデバウンスしない場合に発生します。ペイロードを小さく保ち、各入力変更で重い処理を行わないでください。
「真の」フィルタを一元化してください:権限、検索、ソート、ページネーションはサーバーでまとめて適用します。クライアント側のロジックは、基礎データセットを変えない小さなUI用の切り替えに限定します。
クライアント側キャッシュは古いデータを表示したり、アカウント間でデータを漏らす可能性があります。サーバー側キャッシュは権限に安全ですが、フルのフィルタ署名と呼び出し元の識別(ユーザー/組織/ロール)を含めてキー化し、結果が混ざらないようにしてください。
現実的にユーザーが持ちうる行数と、各行のバイト数を考えてください。一般的なモバイル接続や古い端末で快適に読み込めないなら、クライアント側は避け、サーバーでページネーションしてください。
サーバー側です。役割やチーム、リージョン、所有権ルールで表示される行やフィールドが変わる場合、サーバーが行とフィールドのアクセスを強制すべきです。クライアントはユーザーが見るべきレコードとフィールドだけを受け取ります。
先にAPIの契約を定義してください:受け付けるフィルタ項目、デフォルトのソート、ページネーションルール、検索の一致ルール(大文字小文字、アクセント、部分一致など)。そのロジックをバックエンドで一貫して実装し、合計やページが一致するかテストします。
タイピングのデバウンスで無駄なリクエストを防ぎ、古い結果を新しい結果が来るまで表示してフリッカーを抑えます。ページネーションや段階的読み込みで、巨大なレスポンスを待たずにユーザーに何かを早く見せてください。
権限を先に適用し、その後フィルタとソートを行って1ページ分だけ(例:50行)と合計数を返すのが安全です。「念のため」に追加フィールドを送らないでください。キャッシュキーにはユーザー/組織/ロールを含め、営業担当がマネージャー向けのデータを受け取らないようにします。