2025年12月23日·1 分
SaaS API のレート制限:ユーザー、組織、IP 別のパターン
ユーザー別・組織別・IP別の SaaS API レート制限パターン。ヘッダー、エラーボディ、段階的ロールアウトのヒントを顧客に分かりやすく解説します。
ユーザー別・組織別・IP別の SaaS API レート制限パターン。ヘッダー、エラーボディ、段階的ロールアウトのヒントを顧客に分かりやすく解説します。
レートリミットとクォータは似て聞こえるため、同じものだと扱われがちです。レートリミットは API をどれだけ速く呼べるか(秒あたり、分あたりのリクエスト数)を意味します。クォータはより長い期間(1日、1か月、請求サイクル)でどれだけ使えるかを示します。両方は普通ですが、ルールが見えないとランダムに感じられます。
典型的な不満は「昨日は動いていた」です。使用はめったに安定しません。短いスパイクで線を越えることがあり、日次合計が問題なさそうでもブロックされます。例えば、普段は 1 日に 1 回レポートを走らせる顧客が、今日タイムアウトの後にリトライして 2 分で 10 倍の呼び出しをしてしまい、API にブロックされる—これだけが示されて突然の失敗に見えます。
エラーが曖昧だと混乱は悪化します。API が 500 を返したり一般的なメッセージだと、顧客はサービスが落ちていると考えます。緊急チケットを上げたり回避策を作ったり、プロバイダを変えたりします。たとえ 429 Too Many Requests であっても、次に何をすればいいか示されていなければ苛立ちを招きます。
ほとんどの SaaS API は二つの理由でトラフィックを制限します:
これらを混ぜると設計が悪くなります。濫用対策は多くの場合 IP やトークン単位で厳しくなりがちです。通常の利用調整はユーザー単位や組織単位で行い、どの制限がヒットしたか、いつリセットされるか、どうすれば回避できるかを明確に示すべきです。
顧客が制限を予測できれば、それに合わせて計画できます。予測できないと、どんなスパイクも API の故障に見えます。
レートリミットは単なるスロットルではなく安全装置です。数値を決める前に、何を守ろうとしているのかを明確にしてください。目的によって異なる制限と期待値が生まれます。
可用性は通常優先されます。数クライアントのスパイクで API がタイムアウトに陥ると全員に影響します。ここでの制限はバースト時にサーバーを応答可能に保ち、リクエストを溜め込むのではなく速やかに失敗させるべきです。
コストは多くの API の背後にある静かな要因です。リクエストの中には安価なものもあれば、高コストなもの(LLM 呼び出し、ファイル処理、ストレージ書き込み、有料サードパーティ参照)があります。例えば Koder.ai のようなプラットフォームでは、1 人のユーザーがチャットベースのアプリ生成経由で多くのモデル呼び出しを引き起こすことがあります。高コストの操作を追跡する制限は、予期せぬ請求を防ぎます。
濫用は正当な大量利用とは見た目が異なります。認証情報詰め合わせ、トークン推測、スクレイピングは狭い IP 範囲やアカウントから多数の小さなリクエストとして現れます。ここでは厳しい制限と迅速なブロッキングが望まれます。
マルチテナント環境では公平性が重要です。一人のノイジーな顧客が他を劣化させるべきではありません。実務では制御を重ねることが多く、分単位のバーストガード、コスト向けのガード、認証や不審なパターンに焦点を当てた濫用ガード、そしてある組織が他を圧迫しないようにする公平性ガードなどが組み合わさります。
簡単なテスト: ひとつのエンドポイントを選び「このリクエストが 10× に増えたら何が最初に壊れるか?」と問います。答えが守るべき目的と、どの次元(ユーザー、組織、IP)に制限を置くべきかを示してくれます。
多くのチームは最初に一つの制限だけを入れ、後でそれが間違った人々に不利益をもたらすと気づきます。目的は、実際の利用に合う次元を選ぶこと:誰が呼んでいるのか、誰が支払っているのか、不正らしい振る舞いはどれか。
SaaS でよく使われる次元:
ユーザー別はテナント内の公平性に関するものです。ある人が大きなエクスポートを走らせたら、その人が他のチームより先に抑えられるべきです。
組織別は予算と容量に関するものです。十人が同時にジョブを実行しても、組織がサービスや価格想定を壊すレベルにスパイクしてはいけません。
IP 別は安全ネットとして扱うのがベターです。IP は共有されることがある(オフィス NAT、モバイルキャリア)ので、緩やかに設定し、明らかな濫用を止めるために使います。
次元を組み合わせるときは、複数の制限が適用された場合にどれが「勝つ」のかを決めてください。実用的なルールは: 関連するいずれかの制限を超えたらリクエストを拒否し、最も実行可能な理由を返す、というものです。ワークスペースが組織クォータを超えているなら、ユーザーや IP のせいにしないでください。
例: Koder.ai の Pro プランのワークスペースは、組織単位でのビルドリクエストの定常フローを許可しつつ、個々のユーザーが 1 分間に何百回もトリガーするのを制限することがあります。共有トークンを使うパートナー統合なら、トークン別の制限で対話型ユーザーを圧倒するのを防げます。
多くのレート制限問題は数学の問題ではなく、顧客がどのように API を呼ぶかに合わせた挙動を選び、負荷下でも予測可能にすることです。
トークンバケットは短いバーストを許しながら長期の平均を強制するため一般的なデフォルトです。ダッシュボードを更新するときに数回素早くリクエストが発生するような場面で有効です。トークンを貯めて一気に消費できるため、短期的な操作が許容され、その後ゆっくりと制限されます。
リ―キーバケットはより厳格で、トラフィックを一定の流出に平滑化します。バックエンドがスパイクを処理できない場合に有効ですが、バーストはより早く感じられ、キューイングや拒否が発生しやすくなります。
ウィンドウベースのカウンタは単純ですが細部が重要です。固定ウィンドウは境界で鋭いエッジが生まれます(12:00:59 にバーストし、12:01:00 にまたバーストできる)。スライディングウィンドウはより公平に感じられますが、状態管理やデータ構造が必要です。
別カテゴリの制限として同時実行数(in-flight リクエスト)があります。これは遅いクライアント接続や長時間のエンドポイントから守ります。顧客は 1 分あたりのリクエスト数は守っていても、200 のリクエストを同時に開いてシステムを圧迫することがあります。
実際には、トークンバケット(全体的なリクエスト率)、同時実行キャップ(重いエンドポイント向け)、エンドポイントグループ別の別予算(安価な読み取り対コストの高いエクスポート)を組み合わせることが多いです。リクエスト数だけで制限すると、ある高コストのエンドポイントがすべてを圧迫し、API がランダムに壊れたように感じられます。
良いクォータは公平で予測可能に感じられるべきです。顧客がブロックされた後に初めてルールを知るべきではありません。
区別を明確に保ちます:
多くの SaaS チームは両方を使います: バーストを止める短期レート制限と、価格に紐づく月次クォータ。
ハード制限とソフト制限は主にサポートの選択です。ハード制限は即時ブロック、ソフト制限はまず警告して後でブロックします。ソフト制限はユーザーがバグを修正したりアップグレードする時間を与えるので、顧客の怒りを減らせます。
オーバーしたときの挙動は守ろうとしているものに一致させます。過剰利用が他テナントを傷つけたりコストを爆発させるならブロックが適切です。処理を遅くする(優先度を下げる)ことで動きを維持したい場合は劣化させます。予測可能で既に課金フローがある場合は「後で請求」も実現可能です。
ティア別の制限は、各ティアに「期待される利用形状」が明確にあるときに最も有効です。無料ティアは小さな月次クォータと低いバースト率を許容し、ビジネス/エンタープライズは高いクォータと高いバースト制限を与えてバックグラウンドジョブを素早く終わらせられるようにします。これは Koder.ai の Free/Pro/Business/Enterprise のように、各ティアで期待値を分けるやり方に似ています。
エンタープライズ向けに早い段階でカスタム制限をサポートする価値はあります。実装の一つのやり方は「プランごとのデフォルト、顧客ごとのオーバーライド」です。組織ごと(場合によってはエンドポイントごと)に管理者設定のオーバーライドを保存し、プラン変更後も保持されるようにします。誰が変更を依頼でき、どれくらい早く反映されるかも決めてください。
例: 顧客が月末に 50,000 レコードをインポートする場合、月次クォータがほぼ使い切られているときに 80–90% でソフト警告を出すと一時停止する余地ができます。秒単位のレート制限はインポートが API を洪水させるのを防ぎます。承認された組織オーバーライド(一時的または恒久的)はビジネスを前に進めます。
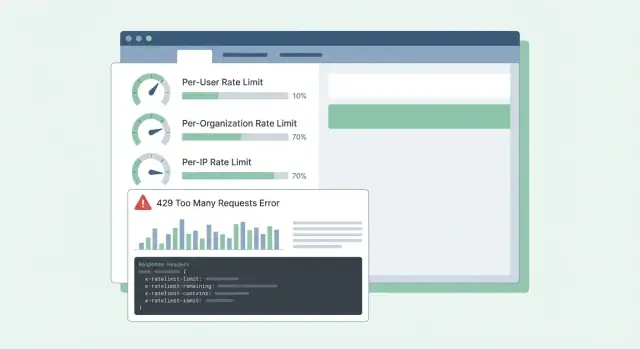
まず何をカウントし、それが誰に帰属するかを書き出します。多くのチームは最終的に三つの識別子を使います: サインインしたユーザー、顧客組織(ワークスペース)、クライアント IP。
実用的な計画:
制限を設定するときは、グローバルな一つの数値ではなくティアとエンドポイントグループで考えてください。よくある失敗は複数のアプリサーバ間でインメモリカウンタに頼ることです。カウンタが一致せずユーザーは「ランダムな」429 を見ることになります。Redis のような共有ストアがインスタンス間で制限を安定させ、TTL がデータを小さく保ちます。
ロールアウトが重要です。まずは「報告のみ」モード(ブロックされるはずだったものをログに残す)、次に一つのエンドポイントグループで強制、そして拡大します。これによりサポートチケットの嵐で目を覚ます事態を避けられます。
顧客が制限に達したとき、最悪の結果は混乱です: 「API が落ちているのか、自分が間違っているのか?」 明確で一貫したレスポンスはサポートチケットを減らし、クライアントの行動修正を助けます。
積極的にブロックする場合は HTTP 429 Too Many Requests を使ってください。レスポンスボディは予測可能な形にして SDK やダッシュボードが読み取れるようにします。
ここに per-user、per-org、per-IP 制限でうまく機能するシンプルな JSON 形を示します:
{
"error": {
"code": "rate_limit_exceeded",
"message": "Rate limit exceeded for org. Try again later.",
"limit_scope": "org",
"reset_at": "2026-01-17T12:34:56Z",
"request_id": "req_01H..."
}
}
ヘッダーは現在のウィンドウとクライアントが次に何をするべきかを説明すべきです。最初は次を追加してください: RateLimit-Limit、RateLimit-Remaining、RateLimit-Reset、Retry-After、X-Request-Id。
例: 顧客の cron ジョブが毎分走り突然失敗し始めたとします。429 と共に RateLimit-Remaining: 0 と Retry-After: 20 が返れば、これは故障ではなく制限だとすぐに分かり、リトライを 20 秒遅らせることができます。X-Request-Id をサポートに共有すれば、そのイベントを素早く見つけられます。
もう一つの詳細: 成功レスポンスにも同じヘッダーを返してください。顧客はブロックされる前にどれだけ近いかを知ることができます。
良いクライアントは制限を公平に感じさせます。悪いクライアントは一時的な制限を障害に変えてしまいます。
429 を受け取ったら減速の合図と受け取ってください。レスポンスで再試行時刻が示されていれば(例: Retry-After)、その間は待ちます。示されていなければ指数バックオフにジッターを加えて、千のクライアントが同時に再試行しないようにします。
リトライは上限を設けてください: 試行間の遅延上限(例: 30–60 秒)や総リトライ時間(例: 2 分で打ち切り)を決め、発生をログに残して開発者が後から調整できるようにします。
すべてを再試行してはいけません。多くのエラーは修正やユーザー操作なしでは成功しません: 400(バリデーションエラー)、401/403(認証エラー)、404、ビジネス上の 409(競合)など。
書き込みエンドポイント(作成、課金、メール送信など)はリトライが危険です。タイムアウトでクライアントが再試行すると重複を生む可能性があります。冪等性キーを使って、クライアントが論理的な操作ごとに一意のキーを送り、サーバーが同じキーの繰り返しに対して同じ結果を返すようにしてください。
良い SDK は開発者に必要な情報を分かりやすく提供できます: ステータス(429)、どれくらい待つか、リクエストが安全にリトライ可能か、そして “Rate limit exceeded for org. Retry after 8s or reduce concurrency.” のような実用的なメッセージです。
制限に関するサポートチケットの多くは、制限自体ではなく“驚き”が原因です。ユーザーが次に何が起きるか予測できないと、API が壊れているか不公平だと考えます。
IP ベースのみの制限は頻繁に問題を起こします。多くのチームは一つの公開 IP の背後にいます(オフィス Wi‑Fi、モバイルキャリア、クラウド NAT)。IP で厳しく制限すると、一人の忙しい顧客が同じネットワーク上の全員をブロックしてしまいます。ユーザー別と組織別を優先し、IP は主に明らかな濫用を止めるための安全ネットにしてください。
また全エンドポイントを同等に扱うのも問題です。安価な GET と重いエクスポートを同じバケットに入れると、通常のブラウズで許容量を使い切り、本当にやりたいタスクでブロックされます。エンドポイント群でバケットを分けるか、リクエストにコストの重み付けを行ってください。
リセットタイミングも明確にする必要があります。「日次でリセット」は不十分です。どのタイムゾーンか? ローリングウィンドウか深夜リセットか? カレンダーリセットをするならタイムゾーンを示し、ローリングウィンドウならウィンドウ長を示してください。
最後に、曖昧なエラーは混乱を生みます。500 や一般的な JSON を返すと、人々はより強く再試行します。429 と RateLimit ヘッダーを使って、クライアントが賢くバックオフできるようにしてください。
例: 企業ネットワークから共有コネクションで Koder.ai インテグレーションを作ると、IP のみのキャップがその企業全体をブロックし、ランダムな障害のように見えます。明確な次元と 429 レスポンスがあれば混乱は避けられます。
全ユーザーに制限を有効化する前に、予測可能性に焦点を当てて最終確認を行ってください:
Retry-After と RateLimit ヘッダー(Limit、Remaining、Reset)を含める。JSON ボディには短いメッセージ、どの制限がヒットしたか、いつ再試行できるかを含める。直感的な確認: 製品に Free、Pro、Business、Enterprise のようなティアがあるなら、通常の顧客が分あたりと日あたりに何ができるかを平易な言葉で説明でき、どのエンドポイントが異なる扱いを受けるかを説明できるべきです。
429 を明確に説明できなければ、顧客は API が壊れていると想定します。保護しているとは考えません。
B2B SaaS を想像してください。人々はワークスペース(組織)内で作業し、一部のパワーユーザーは重いエクスポートを実行し、多くの従業員が一つの共有オフィス IP の背後に座っています。IP のみで制限すると企業全体をブロックします。ユーザーのみで制限すると、単一のスクリプトがワークスペース全体を傷つける可能性があります。
実用的な組合せ:
誰かが制限に達したら、メッセージは何が起きたか、次に何をすべきか、いつ再試行できるかを伝えるべきです。サポートは次のような文言を裏付けられる必要があります:
“Request rate exceeded for workspace ACME. You can retry after 23 seconds. If you are running an export, reduce concurrency to 2 or schedule it off-peak. If this blocks normal use, reply with your workspace ID and timestamp and we can review your quota.”
この文言を Retry-After と一貫した RateLimit ヘッダーと組み合わせれば、顧客は推測せずに対処できます。
サプラントを避けるロールアウト: まず観測のみ、次にヘッダーとソフト警告を出す、次に 429 で強制(明確な再試行時刻付き)、その後ティア別にしきい値を調整、そして大きなローンチや顧客オンボーディングの後にレビューする、という順で進めてください。
これらのアイデアを実際のコードに素早く落とし込む方法を探すなら、Koder.ai のような vibe-coding プラットフォームが短いレート制限仕様を下書きし、Go ミドルウェアを生成してサービス間で一貫して適用する手助けになります。
レートリミットはリクエストの「速さ」を制限します(秒ごとや分ごとのリクエスト数)。クォータは長い期間(1日、1月、請求サイクル)での「利用量」を制限します。
「昨日は動いていたのに」という驚きを減らすには、両方を明示してリセット時刻をはっきりさせ、顧客が挙動を予測できるようにしてください。
防ぎたい障害を起点に考えてください。バーストでタイムアウトが発生するなら短期のバースト制御、特定のエンドポイントがコストを押し上げるならコストベースの予算、ブルートフォースやスクレイピングが見られるなら厳しい不正対策が必要です。
短く試す方法は、「このエンドポイントが 10× に増えたら何が壊れるか:レイテンシ、コスト、それともセキュリティ?」と問うことです。優先すべき保護目標と、どの次元(ユーザー、組織、IP)で制限すべきかが決まります。
1)ユーザー別は、1 人の重い利用がチーム全体を遅くしないようにするため、2)組織(ワークスペース)別は課金や容量の上限を明確にするため、3)トークン(API キー)別は共有インテグレーションやパートナー用途で有効です。
IP 別は漏洩トークンやボットを補足するセーフティネットとして扱ってください。共有ネットワーク(オフィス NAT、モバイル回線)では誤検知で無実のユーザーをブロックしやすいので、寛容に設定します。
トークンバケットは短いバーストを許容しつつ長期の平均を守るためのデフォルトとして良い選択です。ダッシュボードの更新などで数回連続してリクエストが飛ぶ場面に向いています。
バックエンドがスパイクをまったく許容できない場合はリキーディング(leaky bucket)や明示的なキューイングがより一貫した挙動を与えますが、バーストに対して厳しくなります。ウィンドウカウンタ(固定ウィンドウ、スライディングウィンドウ)や同時実行数(in-flight)も用途に応じて選んでください。
同時実行数(in-flight)の問題が主なら、秒あたりリクエスト数ではなく同時接続数の上限を追加してください。これは遅いエンドポイント、長いポーリング、ストリーミング、大量エクスポート、ネットワーク状況が悪いクライアントでよく問題になります。
同時実行の上限は「1 分あたり 60 件の範囲にいるが 200 件の接続を張り続けている」といった状況から保護します。
積極的にブロックする場合は HTTP 429 を返し、どのスコープ(user、org、IP、token)がヒットしたかと再試行時刻を含む明確なエラー本文を返してください。最も役立つヘッダーは Retry-After です。これがあればクライアントは正確に待機できます。
成功レスポンスにもレート制限ヘッダーを付けて、顧客が境界に近づいていることを事前に把握できるようにしましょう。
Retry-After があればその期間は最低でも待ちます。なければ指数バックオフにジッター(ランダム性)を加えて、多数のクライアントが同時に再試行しないようにします。
リトライは上限を設け、総待機時間(例:2 分で打ち切り)や最大遅延(例:30–60 秒)を決めてください。認証エラーや検証エラーなど、クライアント側の修正が必要なものは再試行しないでください。
他の顧客に害を与えたりコストを即座に増加させたりするならハードリミット(即ブロック)を、まず警告して修正やアップグレードの時間を与えたいならソフトリミット(警告→後で強制)を使います。
現実的な運用では 80–90% で警告を出し、さらに進んだら強制するパターンがよく使われます。
IP ベースだけの制限は誤って正当なユーザーをブロックし、"ランダム" な障害に見える原因になります。多くの企業ユーザーが一つのパブリック IP を共有しているため、IP 制限は緩めにして不正行為の保護(バックストップ)として扱ってください。
通常の利用形状の調整はユーザー別や組織別が望ましく、IP は補助的に使います。
段階的にロールアウトして影響を確認してください。まずは「報告のみ」モードで何がブロックされるかをログに取り、次に一部のエンドポイントやテナントで強制を始め、徐々に拡大します。
429 の急増、制限によるレイテンシ増、主要ブロッキーなキーの検出などの指標を監視して、しきい値や次元が間違っていないかを判断してください。