2025年12月17日·1 分
PostgreSQL のコネクションプーリング:アプリ内プール vs PgBouncer
PostgreSQL のコネクションプーリング:Go バックエンドでのアプリ内プールと PgBouncer の比較、監視すべき指標、レイテンシスパイクを引くミス設定について解説します。
PostgreSQL のコネクションプーリング:Go バックエンドでのアプリ内プールと PgBouncer の比較、監視すべき指標、レイテンシスパイクを引くミス設定について解説します。
データベース接続はアプリと Postgres の間の電話線のようなものです。開くには両側で時間と作業がかかります:TCP/TLS のセットアップ、認証、メモリ確保、Postgres 側のバックエンドプロセス。コネクションプールはこれらの「電話線」を少数開いたままにしておき、リクエストごとに毎回ダイヤルし直す代わりに再利用します。
プーリングが無効かサイズが合っていないと、最初にわかりやすいエラーが出ることは稀です。代わりにランダムな遅延が起きます。普段 20–50 ms のリクエストが突然 500 ms や数秒になり、p95 が跳ね上がります。次にタイムアウトが出て、「too many connections」が出たり、アプリ内で空き接続を待つキューが生じます。
接続上限は小さなアプリでも重要です。トラフィックはバーストするからです。マーケティングメール、cron ジョブ、少数の遅いエンドポイントが同時にデータベースへ数十のリクエストをぶつけることがあります。各リクエストが新しい接続を開くと、Postgres はクエリ実行の代わりに接続の受け入れと管理に多くの能力を使ってしまいます。既にプールがあっても、それが大きすぎると多すぎるアクティブなバックエンドで Postgres を過負荷にし、コンテキストスイッチやメモリ圧迫を引き起こします。
早期の兆候に注意してください:
プーリングは接続の churn を減らし、Postgres がバーストを処理しやすくします。ただし遅い SQL を直すわけではありません。クエリがフルテーブルスキャンをしているかロック待ちをしている場合、プーリングは主にシステムの失敗の仕方(早めにキューイングし、遅めにタイムアウトする)を変えるだけで、速くはしません。
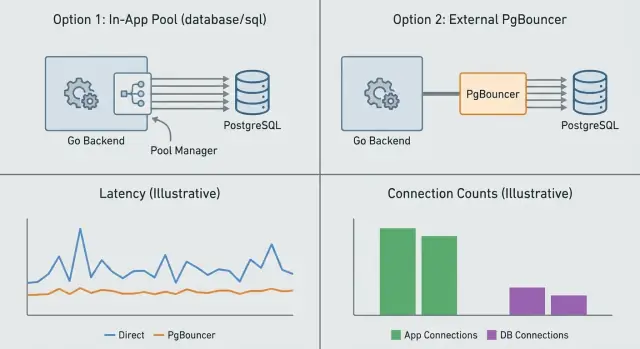
コネクションプーリングは、一度に存在するデータベース接続数とそれらの再利用方法を制御することです。これはアプリ内(アプリレベルのプーリング)で行うか、Postgres の前に別のサービス(PgBouncer)を置いて行うかのどちらかです。両者は関連するが異なる問題を解きます。
アプリレベルのプーリング(Go では通常組み込みの database/sql プール)はプロセスごとに接続を管理します。いつ新しい接続を開くか、いつ再利用するか、アイドル接続をいつ閉じるかを決めます。これにより各リクエストでセットアップ費用を払わずに済みます。ただし複数のアプリインスタンス間で調整できるわけではありません。10 レプリカを動かしているなら、実質的に 10 個の独立したプールを持つことになります。
PgBouncer はアプリと Postgres の間に立ち、多くのクライアントに代わってプーリングを行います。短命なリクエストが多い場合、アプリのインスタンスが多数ある場合、またはトラフィックがスパイクする場合に最も有用です。大量のクライアント接続が一度に来ても、PgBouncer は Postgres 側の接続数を上限で抑えます。
責任範囲を簡単に分けると:
両方は明確な目的がある限り、いわゆる「二重プーリング」の問題なく共存できます:各 Go プロセスに現実的な database/sql プールを置き、PgBouncer でグローバルな接続予算を強制する、といった構成です。
よくある誤解は「プールを増やせば容量が増える」というものです。通常は逆です。各サービス、ワーカー、レプリカが大きなプールを持つと総接続数が爆発し、キューイング、コンテキストスイッチ、突発的な遅延スパイクを招きます。
database/sql プーリングは実際どう振る舞うかGo では sql.DB が接続プールマネージャです。db.Query や db.Exec を呼ぶと、database/sql はアイドル接続を再利用しようとします。再利用できなければ新しい接続を開く(上限まで)か、呼び出し元を待たせます。
その「待ち」がミステリーな遅延の発生源になることが多いです。プールが飽和するとリクエストはアプリ内でキューに入り、外から見ると Postgres が遅くなったように見えますが、実際の時間は空き接続を待っている時間です。
調整の多くは次の四つの設定に帰着します:
MaxOpenConns: 開かれる接続の上限(アイドル+使用中)。これに達すると呼び出し側はブロックされます。MaxIdleConns: 再利用のために待機できる接続数。低すぎると頻繁に再接続が発生します。ConnMaxLifetime: 定期的に接続をリサイクルする設定。ロードバランサや NAT タイムアウト対策に有用ですが短すぎるとチャーンを引き起こします。ConnMaxIdleTime: 長時間使われていない接続を閉じます。接続の再利用は通常レイテンシと DB の CPU を下げます(TCP/TLS、認証、セッション初期化の繰り返しを避けるため)。しかし過大なプールは逆効果です:Postgres がうまく処理できる以上に同時クエリを許してしまい、競合やオーバーヘッドが増えます。
プロセスごとではなく合計で考えてください。もし各 Go インスタンスが 50 の開放接続を許可していて 20 インスタンスにスケールすると、実際には 1,000 接続を許可したことになります。その数を Postgres サーバが問題なく扱えるか比較してください。
実践的な出発点は、MaxOpenConns をインスタンスごとの想定同時実行数に結びつけ、上げる前にプール指標(in-use、idle、wait time)で検証することです。
PgBouncer はアプリと PostgreSQL の間に立つ小さなプロキシです。サービスは PgBouncer に接続し、PgBouncer は Postgres への実際のサーバ接続を有限数保持します。スパイク時は PgBouncer がクライアントの仕事をキューに入れ、即座により多くの Postgres バックエンドを作る代わりに待たせます。そのキューが制御された遅延とデータベースのダウンの差を生むことがあります。
PgBouncer には三つのモードがあります:
セッションプーリングは直接 Postgres に接続するのに最も近い振る舞いで、最も驚きが少ない代わりにバースト時に節約できるサーバ接続は少なめです。
典型的な Go の HTTP API では、トランザクションプーリングが強力なデフォルトとなることが多いです。多くのリクエストは小さなクエリか短いトランザクションを実行して終わるため、トランザクションプーリングは多数のクライアント接続を小さな Postgres 接続予算で共有させられます。
代償はセッション状態です。トランザクションモードでは、単一のサーバ接続にピン留めされることを前提にした以下のような処理が壊れたり挙動が変わったりします:
SET、SET ROLE、search_path)アプリがその種の状態に依存するならセッションプーリングのほうが安全です。ステートメントプーリングは最も制約が強く、ウェブアプリにはほとんど合いません。
実用的なルール:各リクエストが必要なものを一つのトランザクション内で準備できるなら、トランザクションプーリングは負荷時にレイテンシを安定させやすいです。長期的なセッション振る舞いが必要ならセッションプーリングを使い、アプリ側の上限を厳しくしてください。
database/sql を使う Go サービスを運用しているなら、既にアプリ側のプーリングが働いています。多くのチームにとってそれで十分な場合があります:インスタンスが少数でトラフィックが安定しており、クエリが極端にスパイクしないなら、Go プールのチューニングだけで済みます。
PgBouncer はデータベースが一度にあまりに多くのクライアント接続で叩かれているときに役立ちます。これは多くのアプリインスタンス(あるいはサーバーレス風のスケール)、バーストトラフィック、短いクエリが多い状況で現れます。
誤ったモードで使うと PgBouncer が害になることもあります。コードがセッション状態に依存している(テンポラリテーブル、準備済みステートメントの跨り、アドバイザリロック、セッション設定など)のにトランザクションプーリングを使うと、不可解な失敗が起きます。本当にセッション挙動が必要ならセッションプーリングを使うか PgBouncer を使わずアプリプールを慎重にサイズしてください。
目安として:
接続上限は予算です。それを一度に全部使ってしまうと新しいリクエストは待たされ、テールレイテンシが跳ね上がります。目標は同時実行を制限しつつスループットを維持することです。
現在のピークとテールレイテンシを測る。 ピークのアクティブ接続数(平均ではなくピーク)、リクエストや重要クエリの p50/p95/p99 を記録します。接続エラーやタイムアウトもメモします。
アプリの安全な Postgres 接続予算を設定する。 max_connections から管理用接続、マイグレーション、バックグラウンドジョブ、スパイク用の余裕を差し引きます。複数サービスが DB を共有するなら予算を意図的に分配します。
その予算をインスタンスごとの Go 制限にマップする。 アプリ予算をインスタンス数で割って MaxOpenConns を設定(少し下回る)します。MaxIdleConns は常時再接続を避ける程度に高めにし、ライフタイムは接続を適度にリサイクルするがチャーンを起こさないように設定します。
必要なら PgBouncer を追加し、モードを選ぶ。 セッション状態が必要ならセッションプーリング、互換性があり最大のサーバ接続削減を望むならトランザクションプーリングを選びます。
段階的に導入し、ビフォーアフターを比較する。 一度に複数変更をせず、カナリ―で検証してから比較します。テールレイテンシ、プール待ち時間、DB CPU を見てください。
例:Postgres がサービスに安全に 200 接続を割り当てられるなら、10 インスタンス運用の場合は各インスタンスで MaxOpenConns=15-18 から始めるとよいでしょう。これでスパイク時の余裕が残り、全インスタンスが同時に上限に達する確率を下げられます。
プーリング問題は「接続が多すぎる」から始まることは少なく、まず待ち時間の緩やかな上昇があり、その後急な p95/p99 のジャンプが来ます。
まずは Go アプリが報告する値を見てください。database/sql では open connections、in-use、idle、wait count、wait time を監視します。トラフィックが平坦なのに wait count が上がるなら、プールが小さすぎるか接続が長時間占有されています。
DB 側ではアクティブ接続と max、CPU、ロックアクティビティを追います。CPU が低いのにレイテンシが高い場合は、キューイングやロックが疑わしいです。
PgBouncer を使っているなら三つ目の視点を追加します:クライアント接続数、Postgres へのサーバ接続数、キュー深度。サーバ接続が安定しているのにキューが伸びているなら、予算が飽和している明確なサインです。
アラートの良い指標:
プーリングの問題はしばしばバースト時に現れます:リクエストが接続を待つために溜まり、その後しばらくして何事もなかったように戻ります。根本原因は一つのインスタンスでは妥当でも、サービスを多数動かすと危険になる設定であることが多いです。
よくある原因:
MaxOpenConns をグローバル予算に合わせていない。 インスタンス当たり 100 を 20 インスタンスで動かすと潜在的に 2,000 接続になります。ConnMaxLifetime / ConnMaxIdleTime が短すぎる。 多数の接続が同時にリサイクルして再接続の嵐を起こすことがあります。スパイクを減らす単純な方法は、プーリングをアプリローカルのデフォルトではなく共有制限と見なすことです:全インスタンス合計の接続を上限にし、適度なアイドルプールを保ち、ライフタイムは同期した再接続を避ける程度に長めに設定します。
トラフィックが急増すると通常三つのどれかになります:リクエストが空き接続を待ってキュー化される、リクエストがタイムアウトする、あるいは全体が遅くなってリトライが積み重なる。
キューイングは厄介です。ハンドラはまだ実行中ですが接続待ちで停止しています。その待ち時間がレスポンスタイムになります。小さなプールがあると 50 ms のクエリが負荷下では数秒のエンドポイントになることがあります。
分かりやすいモデル:プールに使える接続が 30 あり、突如 300 並列リクエストが全て DB を必要とすると、270 が待ちになります。各リクエストが 100 ms 接続を占有すると、テールレイテンシはすぐに数秒に達します。
明確なタイムアウト予算を設定して守ってください。アプリのタイムアウトは DB のタイムアウトよりわずかに短くして、早めに失敗させて負荷を下げます。
statement_timeout を設定して一つの遅いクエリが接続を独占しないようにするその上でバックプレッシャーをかけ、プールに負荷を掛けすぎないようにします。選ぶ手段は一つか二つに絞ると良いです:エンドポイントごとの同時実行制限、明確なエラーでのレイション(429 等)、バックグラウンドジョブの分離など。
最後に、まずは遅いクエリを直してください。プーリング圧力下では遅いクエリが接続を長時間占有し、待ちが増え、タイムアウトが増え、リトライが発生するというフィードバックループで「少し遅い」状態が「全部遅い」状態に変わります。
負荷テストは接続予算を検証するために行ってください。単なるスループット確認ではありません。目的はプーリングが本番と同じようにストレス下で振る舞うことを確認することです。
現実的なトラフィックでテストしてください:同じリクエストのミックス、バーストパターン、本番と同じ台数のアプリインスタンス。単一エンドポイントのベンチマークはプール問題を隠しがちです。
ウォームアップを入れてコールドキャッシュやランプアップ効果を測定に混ぜないようにし、プールが通常サイズに達してから記録を始めてください。
戦略比較をするなら作業負荷は同一に保ち、次を実行します:
database/sql、PgBouncer なし)各実行後にスコアカードを残してください:
これを続けるとキャパシティ計画は再現可能で推測ではなくなります。
プールサイズに触る前に一つの数字を書き留めてください:接続予算です。これはその環境(dev、staging、prod)で安全に許せるアクティブな Postgres 接続の最大数で、バックグラウンドジョブや管理用接続も含みます。これを言えないなら推測している状態です。
クイックチェックリスト:
MaxOpenConns) が予算(または PgBouncer のキャップ)に収まることを確認するmax_connections と予約接続が計画と整合しているか確認するロールアウトプラン(ロールバックを簡単に保つ):
もしあなたが Koder.ai (koder.ai) 上で Go + PostgreSQL アプリを構築・ホストしているなら、Planning Mode は変更と測定項目のマップ作成を助け、スナップショットとロールバック機能でテールレイテンシが悪化した場合の復旧を容易にします。
次の一手:次のトラフィック増加前に一つの測定を追加してください。多くの場合、アプリ内の「接続待ちに費やした時間」を計測することが最も有用で、ユーザが感じる前にプーリング圧力を示してくれます。
プールは少数の PostgreSQL 接続を開いたままにして、複数のリクエストで使い回します。TCP/TLS、認証、バックエンドプロセスのセットアップといったコストを繰り返さないため、バースト時のテールレイテンシを安定させるのに役立ちます。
プールが枯渇すると、リクエストはアプリ内で空き接続を待ち、その待ち時間が遅延として現れます。平均は問題なさそうでも、p95/p99 がバースト時に跳ね上がるのでまず“ランダムな遅さ”として現れます。
いいえ。プーリングは再接続の無駄や同時実行数の制御で振る舞いを改善しますが、フルテーブルスキャンやロック待ち、インデックス不足などでクエリ自体が遅い場合は速くなりません。遅いクエリはまず直す必要があります。
アプリ側のプーリングはプロセス単位で接続を管理するので、各インスタンスが独立したプールを持ちます。PgBouncer は Postgres の前に立って多くのクライアントに代わりプーリングを行い、全体の接続予算を守ります。大量のレプリカやバーストに有効です。
インスタンスが少なく総接続数がデータベース上限を十分に下回るなら、Go の database/sql のみをチューニングするだけで十分なことが多いです。多数のインスタンスやオートスケール、バーストが総接続数を押し上げそうなら PgBouncer を追加します。
サービス全体の接続予算を決め、それをインスタンス数で割って MaxOpenConns を少し下回る値に設定するのが良い出発点です。小さく始めて待ち時間と p95/p99 を監視し、データベースに余裕があることを確認してから増やしてください。
多くの HTTP API ではトランザクションプーリングがデフォルトの良い選択です。短いクエリや短いトランザクションが多い場合、クライアント接続を少ないサーバ接続で共有できます。セッション状態に依存するならセッションプーリングを選んでください。
準備済みステートメント、テンポラリテーブル、アドバイザリロック、セッションレベル設定などは、クライアントが毎回同じサーバ接続を得られないと挙動が変わる可能性があります。そうした機能が必要ならセッションプーリングか、リクエスト内で完結するトランザクションにまとめてください。
p95/p99 の上昇と合わせてアプリ側のプール待ち時間(waiting for a connection)を監視するのが早期検知に有効です。Postgres 側はアクティブ接続、CPU、ロックを見てください。PgBouncer があるならクライアント接続、サーバ接続、キュー深度を追います。
まず無制限に待たせないことです。リクエスト全体のデッドラインと DB 呼び出しに短めのタイムアウトを設定し、statement_timeout を使って一つの遅いクエリが接続を占有し続けないようにします。次に DB 集中処理のエンドポイントで同時実行数を制限するか、負荷を遮断(429 を返す等)してバックプレッシャーをかけます。接続ライフタイムが短すぎると再接続の嵐になるので避けてください。