2025年7月14日·1 分
メモリ管理戦略:言語における性能と安全性のトレードオフ
ガベージコレクション、所有権、参照カウントが速度、レイテンシ、セキュリティに与える影響と、目的に合った言語を選ぶ方法を解説します。
ガベージコレクション、所有権、参照カウントが速度、レイテンシ、セキュリティに与える影響と、目的に合った言語を選ぶ方法を解説します。
メモリ管理は、プログラムがメモリを要求し、それを使い、戻すための規則と仕組みの集合です。実行中のプログラムは変数、ユーザーデータ、ネットワークバッファ、画像、中間結果などのためにメモリを必要とします。メモリは有限で OS や他プロセスと共有されるため、言語は「誰が」それを解放するか、そして「いつ」それが行われるかを決める必要があります。
その決定は、多くの人が気にする二つの結果に影響を与えます:プログラムの体感速度(どれだけ速く感じるか)と、負荷下でどれだけ信頼できるか(安定性)です。
性能は単一の数値ではありません。メモリ管理は次の点に影響を与えます:
高速に割り当てるがときどきクリーンアップのためにポーズする言語はベンチマーク上は良く見えても、対話的なアプリではジャギーに感じられるかもしれません。ポーズを避けるモデルは、リークやライフタイムのミスを防ぐためにより慎重な設計を要求することがあります。
安全性は、次のようなメモリ関連の失敗を防ぐことです:
多くの著名なセキュリティ問題は、use-after-free やバッファオーバーフローといったメモリのミスに起因します。
この記事は技術的に深入りしすぎない形で、主要なメモリモデル(各言語で使われるもの)が何を最適化しているか、そしてどのようなトレードオフを受け入れることになるかを説明します。
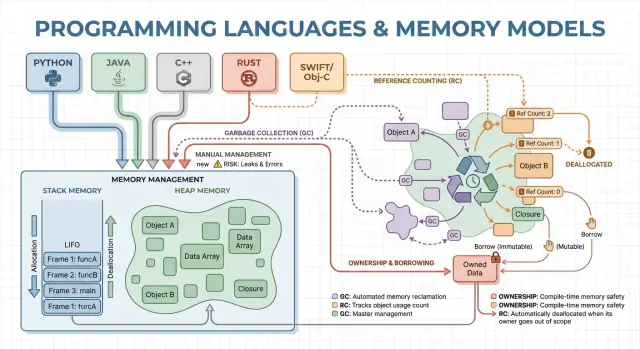
メモリはプログラムが実行中にデータを保持する場所です。多くの言語はこれを主に二つの領域で整理します:スタックとヒープ。
スタックは現在の作業用の付箋のきれいな束のようなものです。関数が始まると、その関数のローカル変数のための小さな「フレーム」がスタック上に割り当てられます。関数が終わると、そのフレーム全体が一度に取り除かれます。
これは高速で予測可能ですが、値のサイズが既知で、ライフタイムが関数呼び出しと共に終わる場合にしか使えません。
ヒープは、必要なだけオブジェクトを保存できる倉庫のようなものです。可変長のリスト、文字列、プログラムの異なる部分で共有されるオブジェクトなどに向きます。
ヒープオブジェクトは単一の関数の寿命を超えて生きられるため、重要なのは「誰がそれを解放する責任を持つか、そしていつか」です。これが言語の“メモリ管理モデル”です。
ポインタや参照はオブジェクトに間接的にアクセスする方法です—倉庫の棚番号を持っているようなものです。箱が捨てられたのに棚番号だけ残っていると、ゴミデータを読み取ったりクラッシュしたりします(典型的な use-after-free バグ)。
ループで顧客レコードを作り、メッセージを整形して破棄する状況を想像してください:
いくつかの言語はこれらの詳細を隠して自動でクリーンアップしますが、他の言語は明示的に解放するか、誰がオブジェクトを所有するかのルールに従う必要があります。以下では、これらの選択が速度、ポーズ、そして安全性にどう影響するかを見ていきます。
手動メモリ管理は、プログラム(つまり開発者)が明示的にメモリを要求し、後で解放することを意味します。実際には C の malloc/free や C++ の new/delete のような形です。システムプログラミングでは、いつメモリを獲得・返却するかを正確に制御する必要があるため、今でも広く使われています。
オブジェクトが現在の関数呼び出しより長く生きる必要がある場合、動的に成長する(例:リサイズ可能なバッファ)、あるいはハードウェアやOS、ネットワークプロトコルとの相互運用のために特定のレイアウトが必要な場合に割り当てます。
バックグラウンドでガベージコレクタが走らないため、意図しないポーズは少なくなります。カスタムアロケータ、プール、固定サイズバッファと組み合わせれば、割り当て・解放を非常に予測可能にできます。
手動制御はオーバーヘッドを減らすこともでき、トレーシング段階やライトバリアが不要だったり、オブジェクトごとのメタデータが少なかったりします。慎重に設計されたコードでは厳しいレイテンシ目標に到達し、メモリ使用量を厳密に管理できます。
代償として、ランタイムが自動的に防いでくれないミスをプログラムが犯す可能性があります:
これらのバグはクラッシュ、データ破損、セキュリティ脆弱性を生む可能性があります。
チームは次のようにリスクを下げます:
std::unique_ptr)で所有権をエンコードする手動メモリ管理は組み込みソフトウェア、リアルタイムシステム、OS コンポーネント、パフォーマンス重視のライブラリなど、厳密な制御と予測可能なレイテンシが開発者の利便性より重要な場面に強い選択肢です。
ガベージコレクション(GC)は自動メモリクリーンアップです:開発者が手動で free する代わりに、ランタイムがオブジェクトを追跡し、もはや到達可能でないものを回収します。これにより動作やデータフローに集中でき、ほとんどの割り当てと解放の判断をシステムが引き受けます。
多くのコレクタはまず「生存している(live)オブジェクト」を特定し、残りを回収します。
トレーシングGC はルート(スタック変数、グローバル参照、レジスタなど)から始め、参照をたどって到達可能なものにマークを付け、未マークのオブジェクトをスイープして解放します。何からも参照されないオブジェクトが回収対象になります。
世代別GC(Generational GC) は多くのオブジェクトが若いうちに死ぬという観察に基づき、ヒープを世代に分け、短命領域を頻繁に収集します。これが通常は効率を改善します。
並行GC(Concurrent GC) はコレクションの一部をアプリケーションスレッドと並行して実行し、長いポーズを減らすことを目指します。そのため、実行中にメモリの一貫性を保つための追加の帳票処理が必要になります。
GC は通常「手動制御」を「ランタイムの作業」へと置き換えます。あるシステムはスループットを重視して多くの作業をこなす代わりに止まることがある一方、別のシステムはポーズを最小化してレイテンシに敏感なアプリ向けに設計されていますが、その分通常動作でのオーバーヘッドが増えることがあります。
GC はライフタイムに関するクラスのバグ(特に use-after-free)を取り除くため、ミスによる解放忘れによるリークも減ります(ただし参照を長く持ち続ければリークのように振る舞うことはあり得ます)。大規模コードベースで所有権を手動で追うのが難しい場合、生産性の向上につながります。
GC ランタイムは JVM(Java、Kotlin)、.NET(C#、F#)、Go、ブラウザや Node.js の JavaScript エンジンで一般的です。
参照カウントは各オブジェクトが何本の“所有者”(参照)を持つかを追跡し、カウントがゼロになると即座に解放する戦略です。その即時性は直感的で、到達不能になったらほぼすぐにメモリが返るという感触があります。
参照をコピー/格納するたびにカウントが増え、参照が消えるたびに減ります。ゼロになれば即クリーンアップです。
そのためリソース管理は分かりやすく、使い終わった瞬間にメモリが戻ることでピークメモリが小さくなる場合や、遅延した回収を避けられる場合があります。
参照カウントは一定の継続的なオーバーヘッドを持つ傾向があります:代入や関数呼び出しのたびにインクリメント/デクリメントが発生します。そのオーバーヘッドは小さいことが多いですが、どこでも発生します。
利点は、トレーシングGCのような大きな stop-the-world ポーズが通常発生しないことです。レイテンシは概して滑らかになりますが、大きなオブジェクトグラフが一気に参照を失ったときに大量の解放が発生して短時間負荷が高まることはあり得ます。
参照カウントは循環参照を回収できません。A が B を参照し、B が A を参照していると、両方のカウントはゼロにならず、外部から到達不能でもメモリは解放されません—これがメモリリークになります。
対処法:
所有権と借用は Rust に最も結びついたモデルです。コンパイラがルールを強制することで、ダングリングポインタ、二重解放、多くのデータ競合をランタイムの GC に頼らず回避します。
各値は同時にちょうど一つの“所有者”を持ちます。所有者がスコープを抜けると、その値は即座に予測可能にクリーンアップされます。これによりメモリやファイルハンドル、ソケットといったリソースの決定的な管理が可能になります。
所有権は移動(move)することもあります:値を新しい変数に代入したり関数に渡すと責任が移り、移動後の古いバインディングは使えなくなります。これにより use-after-free が構造的に防止されます。
借用は値を所有せずに使うことを許します。
共有借用は読み取り専用で、自由にコピーできます。
可変借用は更新を許しますが排他でなければなりません:可変借用が存在する間は他が同じ値を読んだり書いたりしてはいけない、というルールがコンパイル時にチェックされます。
ライフタイムが追跡されることで、コンパイラはデータが参照より先に破棄されるようなコードを拒否できます。これによりダングリング参照の多くが排除され、同じルールは並行コードにおける多数のレース条件も防ぎます。
代償は学習曲線と設計上の制約です。データフローを再構築したり、所有権境界を明確にしたり、共有可変状態のために特殊な型を使う必要が出ることがあります。
このモデルは、システムコード、サービス、組み込み、ネットワーキング、パフォーマンス敏感なコンポーネントなど、GC ポーズなしで予測可能なクリーンアップと低レイテンシが必要な領域に非常に向いています。
大量の短命オブジェクト(パーサの AST ノード、ゲームのフレーム内エンティティ、ウェブリクエストの一時データ)を作ると、個々のオブジェクトを一つずつ割り当て・解放するコストが実行時間を支配することがあります。アリーナ(リージョン)やプールは、細粒度の解放を高速な一括管理に置き換えるパターンです。
アリーナは多くのオブジェクトを割り当てておき、最後に一度にすべてを解放したりリセットしたりするメモリ領域です。
個々のオブジェクトのライフタイムを追跡する代わりに、ライフタイムを明確な境界に結びつけます:「このリクエストで割り当てられたすべて」や「この関数をコンパイルしている間に割り当てられたすべて」など。
アリーナは通常、次のような理由で高速です:
これによりスループットが改善され、頻繁な解放やアロケータ競合によるレイテンシスパイクを減らせます。
アリーナ/プールは次のような場面で使われます:
主要なルールは単純です:あるリージョンが所有するメモリからの参照を、そのリージョンの寿命を越えて外に出さないこと。もしアリーナ内で割り当てたものがグローバルに保存されたり、アリーナの寿命より後に返されたりすると use-after-free の危険があります。
言語やライブラリはこれを様々に扱います:規律と API に頼るもの、リージョン境界を型にエンコードするものなど。
アリーナやプールは GC や所有権の代替ではなく補完として使われることが多いです。GC 言語でもホットパス用にオブジェクトプールを使いますし、所有権ベースの言語でもアリーナを使って割り当てをグループ化し、ライフタイムを明示できます。注意深く使えば、デフォルトで高速な割り当てを実現しつつメモリ解放のタイミングについての明確さを保てます。
言語のメモリモデルは性能と安全性の話の一部に過ぎません。現代のコンパイラとランタイムは、割り当てを減らし、早く解放し、余分な帳票処理を避けるようにプログラムを書き換えます。だから「GC は遅い」や「手動メモリが最速」といった単純な常識は、実際のアプリケーションでは当てはまらなくなることが多いのです。
多くの割り当ては単に関数間でデータを渡すためだけに存在します。エスケープ解析により、コンパイラはオブジェクトが現在のスコープを出ないことを証明できれば、そのオブジェクトをスタックにとどめることができます。
これによりヒープ割り当てが丸ごと不要になり、GC の追跡や参照カウントの更新、アロケータロックに伴うコストを削減できます。マネージド言語で小さなオブジェクトが思ったより安くなる主な理由の一つです。
関数をインライン化すると、コンパイラは抽象化の層を透かして見ることができ、次のような最適化を可能にします:
よく設計された API は、最適化後には「ゼロコスト」になり得ます。ソース上は割り当てが多そうに見えても、生成されたコードでは不要な割り当てが削られることがあります。
JIT(実行時コンパイル)ランタイムは実際の運用データを使ってホットパスや典型的なオブジェクトサイズ、割り当てパターンに基づいて最適化できます。これによりスループットが向上することが多い一方、ウォームアップ時間や再コンパイルや GC のための一時的なポーズが発生することがあります。
**AOT(事前コンパイル)**は事前に多くを決定しますが、起動時間の予測可能性と安定したレイテンシを提供します。
GC ベースのランタイムはヒープサイズ、ポーズ時間の目標、世代閾値などの設定を公開します。これらは測定による根拠(例:レイテンシのスパイクやメモリ圧迫)がある場合に調整すべきで、最初の手順で設定をいじるべきではありません。
同じ「アルゴリズム」を実装していても、隠れた割り当て回数、一時オブジェクト、ポインタの追跡量が異なることで、最終的な振る舞いは実装次第で大きく変わります。これらの差はオプティマイザ、アロケータ、キャッシュ挙動と相互作用するため、性能比較は測定(プロファイリング)によるべきで、想定に頼るべきではありません。
メモリ管理の選択はコードの書き方を変えるだけでなく、いつ作業が行われるか、どれだけのメモリを確保すべきか、ユーザーにとっての性能の一貫性に影響します。
スループットは「単位時間当たりどれだけ仕事をこなせるか」です。例えば夜間バッチジョブで1000万件を処理するなら、GC や参照カウントによる小さなオーバーヘッドがあっても開発効率が高ければ全体では最速になることがあります。
レイテンシは「一つの操作がエンドツーエンドでどれだけかかるか」です。Web リクエストでは一回の応答が遅いとユーザー体験が悪化します。メモリ回収のために時折ポーズが入るランタイムはバッチ処理では許容されても、対話的なアプリでは問題になります。
大きなメモリフットプリントはクラウドコストを増やし、プログラムを遅くすることがあります。ワーキングセットが CPU キャッシュに収まらないとき、CPU は RAM からのデータ待ちで多く待たされます。ある戦略は速度のために余分なメモリを使い(例:解放したオブジェクトをプールに保持する)、別の戦略はメモリを減らす代わりに帳票処理を増やします。
断片化は空きメモリが小さな隙間に分散することで発生します—まるで散らばった小さなスペースにバンを停めようとするような状態です。アロケータは空きスペースを探すのに時間を使い、メモリが増えていくことがあります。
キャッシュ局所性は関連データが近くに配置されていることを意味します。プールやアリーナ割り当てはしばしば良い局所性を生み、長く残るヒープで混在したオブジェクトサイズが混ざると配置が劣化することがあります。
ゲーム、オーディオアプリ、トレーディングシステム、組み込みコントローラなど一貫した応答時間が必要な場合は、「ほとんど速いが時々遅い」より「やや遅いが一貫している」方が望ましいことがあります。こうした場面では決定的な解放パターンや割り当ての厳密な制御が重要になります。
メモリエラーは単なる "プログラマのミス" ではありません。多くの実システムでは、それらがセキュリティ問題に発展します:突然のクラッシュ(DoS)、解放済みや初期化されていないメモリの読み出しによる意図しないデータ露出、攻撃者がプログラムを不正な挙動に誘導する状況などです。
異なるメモリ管理戦略はそれぞれ異なる失敗の仕方をします:
並行性は脅威モデルを変えます:あるスレッドで問題ないメモリが別スレッドで解放や変更されると危険になります。共有に関するルールを強制したり、明示的な同期を要求するモデルは、状態破壊や間欠的クラッシュ、データ漏洩につながるレース条件の可能性を減らします。
どのメモリモデルもリスクをゼロにするわけではありません—ロジックバグ(認可ミス、不適切な検証、設定ミス)は起きます。強いチームはサニタイザ、堅牢な標準ライブラリ、入念なコードレビュー、ファジング、unsafe/FFI の周りの厳格な境界などで多層的に防御します。メモリ安全は攻撃面を大きく減らすものであって、保証ではありません。
メモリの問題は、その不具合が導入された変更の近くで捕まえるほど修正が楽です。重要なのはまず測定し、次に問題に応じた適切なツールで原因を絞ることです。
まず「速度」を追うのか「メモリ増加」を追うのかを決めます。
性能ならウォールクロック時間、CPU 時間、割り当て率(bytes/sec)、GC/アロケータに費やす時間を測ります。メモリならピークRSS、定常時RSS、時間経過でのオブジェクト数を追います。常に同一の入力でワークロードを実行してください;小さな差が割り当ての変動を隠すことがあります。
よくある兆候:単一リクエストが予想よりずっと多く割り当てるか、スループットが安定しているのにメモリがトラフィック増加とともに上がり続ける。対策はバッファ再利用、短命オブジェクトにアリーナ/プールを使う、オブジェクトグラフを簡素化して不必要にオブジェクトが GC 世代をまたがないようにすることなどです。
最小入力で再現し、最も厳しいランタイムチェック(サニタイザ/GC 検証)を有効にしてから、次を取得します:
最初の修正は実験と考え、変更が割り当てを減らしたりメモリを安定化させたかを測定で確認してください—問題が別箇所に移動していないかも確認します。詳しい解釈については /blog/performance-trade-offs-throughput-latency-memory-use を参照してください。
言語選択は構文やエコシステムだけの問題ではありません—そのメモリモデルは日々の開発速度、運用リスク、実トラフィック下での性能予測性を形作ります。
製品要件をメモリ戦略にマッピングするには、実務的な質問に答えましょう:
モデルを切り替えるなら摩擦を計画してください:既存ライブラリへの呼び出し(FFI)、混在するメモリ慣習、ツールチェインの差、採用市場の違い。プロトタイプであらかじめ隠れたコスト(ポーズ、メモリ増加、CPU オーバーヘッド)を発見するのが現実的です。
実務的なアプローチとしては、検討している環境で同じ機能をプロトタイプし、代表的な負荷で割り当て率、テールレイテンシ、ピークメモリを比較することです。チームは Koder.ai のような環境で小さな React フロントエンドと Go + PostgreSQL のバックエンドを素早く立ち上げ、実際のトラフィック形状で GC ベースのサービスがどう振る舞うかを検証してソースをエクスポートする、という評価を行うことがあります。
上位3〜5の制約を定義し、薄いプロトタイプを作り、測定でメモリ使用、テールレイテンシ、失敗モードを評価してください。
| モデル | デフォルトでの安全性 | レイテンシ予測性 | 開発速度 | 典型的な落とし穴 |
|---|---|---|---|---|
| 手動 | 低–中 | 高 | 中 | リーク、解放後使用 |
| GC | 高 | 中 | 高 | ポーズ、ヒープ増加 |
| RC | 中–高 | 高 | 中 | サイクル、オーバーヘッド |
| 所有権 | 高 | 高 | 中 | 学習コスト |
メモリ管理とは、プログラムがデータ(オブジェクト、文字列、バッファなど)用にメモリを割り当て、不要になったら解放する仕組みです。
それが影響する点:
「スタック」は高速で自動的、関数呼び出しに紐づきます:関数が返るとそのスタックフレームは一度に取り除かれます。
「ヒープ」は動的で長寿命のデータ向けですが、誰がいつ解放するかという戦略が必要です。
覚えやすい指針:スタックは短命で固定サイズのローカル向け、ヒープは寿命やサイズが予測できないもの向けです。
参照/ポインタはオブジェクトに間接的にアクセスする手段です。問題は、オブジェクトが解放された後も参照が残っている場合です。
それは次のような結果を招きます:
メモリを明示的に割り当て・解放します(例:malloc/free、new/delete)。
主に次の用途で使われます:
代償として、所有権やライフタイムを正しく管理しないとバグが増えます。
設計が良ければ手動管理は非常に予測可能なレイテンシを出せます。背景でGCが走ることがないため、意図しないポーズが発生しにくいからです。
最適化手段の例:
ただし、断片化、ロック競合、細かい頻繁な alloc/free が原因で高コストパターンに陥りやすい点には注意が必要です。
ガベージコレクションは到達不能になったオブジェクトを自動で見つけて回収します。
多くのトレーシングGCは一般に次の流れです:
これにより解放後使用の多くを回避できますが、コレクタの設計次第では実行時コストや一時的なポーズが発生します。
参照カウントは各オブジェクトが何本の参照を持っているかを数え、0になったら即座に解放します。
利点:
欠点:
多くの環境は弱参照でサイクルを断つか、サイクル検出を組み合わせてこれに対処します。
所有権と借用は Rust によく知られるモデルで、コンパイル時にルールを適用してダングリングや二重解放、多くのデータ競合を防ぎます。
主な考え方:
これにより多くの実行時メモリエラーをコンパイル時に排除できますが、学習コストや設計の制約が伴います。
アリーナ(領域)/プールは多数の短命オブジェクトをまとめて素早く割り当て、まとめて解放するパターンです。
利点:
用途例:コンパイラの抽象構文木、リクエスト単位の一時データ、ゲームのフレーム内オブジェクト等。
安全上の注意:アリーナの寿命を越えて参照を外に逃がさないこと(逃すと解放後使用になる)。
まずは実測から始めてください。代表的な負荷で以下を測りましょう:
その上で:
ランタイム設定(GCパラメータ等)は、測定で問題が確認されてから調整してください。