2025年8月27日·1 分
Go のワーカープールでバックグラウンドジョブを扱う:リトライ、キャンセル、シャットダウン
Go のワーカープールは、小さなチームが重いインフラを導入する前に、単純なパターンでリトライ、キャンセル、クリーンなシャットダウンを備えたバックグラウンドジョブを実行するのに役立ちます。
なぜバックグラウンドジョブはすぐにややこしくなるのか
小さな Go サービスでは、バックグラウンド処理はたいてい単純な目的から始まります:HTTP レスポンスをすばやく返して、遅い処理はあとで行う。メール送信、画像リサイズ、別の API への同期、検索インデックスの再構築、夜間レポートの実行などが該当します。
問題は、これらのジョブは本番の仕事であるにもかかわらず、リクエスト処理で自然に得られるガードレールが欠けていることです。HTTP ハンドラからキックした goroutine は一見問題なさそうに見えますが、タスクの途中でデプロイが入ったり、上流 API が遅くなったり、同じリクエストが再送されてジョブが二重に走ったりすると途端に厄介になります。
最初に出てくる問題点は予測可能です:
- 詰まるジョブ:一つの呼び出しがハングして、ワーカーが進まなくなる。\n- 重複作業:HTTP 層のリトライで同じジョブが再実行される。\n- シャットダウン計画がない:プロセスが終了して作業が失われたり中途半端になる。\n- サイレントな失敗:エラーが一度だけログに残る(あるいはまったく残らない)まま消える。\n- リトライ嵐:失敗したジョブが即座にリトライして依存先を圧倒する。
ここで小さく明示的なパターン、たとえば Go のワーカープールが役に立ちます。並行処理を明確な選択(ワーカー数 N)にし、「あとでやる」を明確なジョブタイプに変え、リトライ、タイムアウト、キャンセルを一か所で扱えるようにします。
例:SaaS アプリで請求書を送る必要があるとします。バッチインポートのあとに 500 件同時に送信したくないし、リクエストがリトライされたために同じ請求書を再送したくもありません。ワーカープールはスループットを制限し、「請求書 #123 を送る」を追跡可能な単位の仕事として扱えます。
ワーカープールは、クラッシュをまたいで生き残る必要がある、将来にスケジュールする必要がある、複数のサービスで処理する必要がある、といった耐久性のあるクロスプロセスな保証が必要な場合には最適な道具ではありません。その場合は永続化されたジョブ状態とキューが必要になることが多いです。
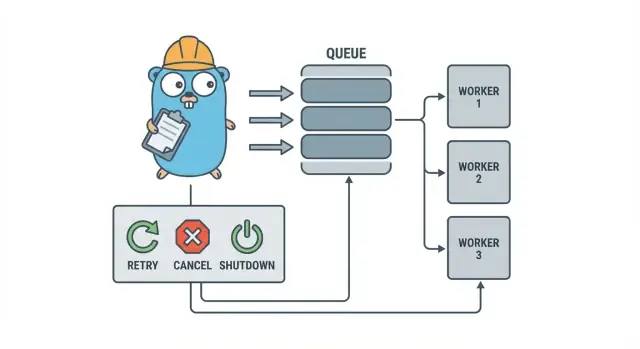
ワーカープールのモデル(やさしく説明)
Go のワーカープールはあえて退屈に作ります:仕事をキューに入れ、固定数のワーカーがそれを取り出し、全体がきれいに停止できるようにするだけです。
基本用語:
- Job(ジョブ):一つの作業単位(例:「この画像をリサイズする」「この請求書のメールを送る」)。
- Queue(キュー):ジョブが待つ場所。\n- Worker(ワーカー):繰り返しジョブを取り出して実行する goroutine。\n- Dispatcher(ディスパッチャ):ジョブを受け取りキューに流す役割。
多くのプロセス内デザインでは、Go の channel がキューになります。バッファつきチャネルは、プロデューサーがブロックされる前に限定数のジョブを保持できます。そのブロックがバックプレッシャーで、トラフィックのスパイク時に無制限に仕事を受け付けてメモリを使い果たすのを防ぎます。
バッファサイズはシステムの感触を変えます。小さいバッファは負荷をすぐ可視化します(呼び出し側が早く待たされる)。大きいバッファは短いバーストを平滑化しますが、過負荷を後回しに隠してしまうことがあります。完璧な数値はなく、耐えられる待ち時間に合った数を選びます。
プールサイズを固定にするか変動にするかも選択肢です。固定プールは理由づけが簡単でリソース使用が予測可能です。ワーカーを自動スケールするのは負荷の不均衡に有効ですが、いつスケールするか、いくつ増やすか、いつ戻すかという判断を保守する必要が出ます。
最後に、プロセス内プールでの「ack(完了確認)」は通常「ワーカーがジョブを終えてエラーを返さないこと」を意味します。外部ブローカーによる配信確認はないので、何を「完了」と見なすか、失敗やキャンセル時にどうするかはコード側で定義します。
設計目標:リトライ、キャンセル、クリーンなシャットダウン
ワーカープールは機械的にはシンプルです:固定数のワーカーを動かし、ジョブを供給して処理する。価値は制御にあります:並行数が予測可能で、失敗処理が明確で、半端に終わらないシャットダウン経路があること。
小さなチームが健全でいるための三つの目標:
- 並行性を制限して、一度のスパイクで DB や外部 API を壊さない。\n- 作業の損失を避ける(少なくとも何が落ちたかを正確に知れる)。\n- デバッグしやすく保つ:各ジョブはログやいくつかのカウンタで追跡できる。
大半の失敗は単純ですが、それでも区別して扱いたい:
- 一時的エラー(ネットワークの瞬断、レート制限)はリトライする価値がある。\n- 永続的エラー(入力不正、レコード未存在)はリトライしない。\n- タイムアウト(依存先がハング)は切り捨ててワーカーが詰まらないようにする。
キャンセルは「エラー」と同じではありません。ユーザーがキャンセルした、デプロイでプロセスが差し替えられた、サービスがシャットダウンしている、といった決定の表明です。Go ではコンテキストのキャンセルを一次のシグナルとして扱い、各ジョブが高コストな処理を始める前や安全なポイントでチェックするようにします。
クリーンなシャットダウンで多くのプールが破綻します。ジョブごとに「安全」とは何かを早めに決めてください:インフライトの仕事を完了するのか、それともすばやく止めて後で再実行するのか。実用的な流れは:
- 新しいジョブの受け付けを止める。\n- ワーカーに現在のジョブ後で止まるか即時に止まるかを伝える。\n- 期限まで待ち、それを過ぎたら強制終了する。
これらのルールを早めに定義すれば、リトライ、キャンセル、シャットダウンは大きく膨らまずに済みます。
ステップバイステップ:基本的なワーカープールを作る
ワーカープールはチャネルからジョブを取り出して処理する一群の goroutine にすぎません。重要なのは基本を予測可能にすること:ジョブがどのような形か、ワーカーがどう停止するか、全作業が終わったとどうやって分かるか。
まずシンプルな Job 型から始めます。ログ用の ID、処理すべきペイロード、リトライで使う試行回数、タイムスタンプ、ジョブごとのコンテキストデータの置き場所を持たせます。
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := \u00026Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i \u0003c size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case \u0003c-p.ctx.Done():
return
case job, ok := \u0003c-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case \u0003c-p.ctx.Done():
return context.Canceled
case p.jobs \u0003c- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
ここで早めに決める実務的な選択:
- 耐えられる待ち時間に基づいてキューサイズを選ぶ。\n- バックプレッシャー時に呼び出し側がどうなるか(ブロックするか、エラーを返すか、ドロップするか)を決める。\n-
Stop()とWait()を分けておき、まず受け付けを止めてからインフライト作業が終わるのを待つようにする。
重厚なフレームワークにしないリトライの追加
リトライは有用ですが、ワーカープールを面倒にする部分でもあります。目標を狭く保ちます:成功の見込みがある場合のみリトライし、見込みがないときはすぐやめる。
まず何がリトライ可能かを決めます。ネットワークの瞬断やタイムアウト、後で再試行してください系のレスポンスなどの一時的な問題はリトライする価値があります。入力不正やレコード未存在、権限拒否などは永続的な問題でありリトライしない。
小さなリトライポリシーで十分です:
- エラーをリトライ可能/不可でマークする(例:
Retryable(err)ヘルパーでラップ)。\n- 最大試行回数を設定する(通常は 3〜5 回)。それ以上は時間の無駄になることが多い。\n- ジッターを伴う指数バックオフを使い、ジョブが同時にリトライしないようにする。\n- 待ち時間は上限を設ける(たとえば最大 30 秒)。\n- リトライ時は試行回数、次の遅延、ジョブ ID をログに出す。
バックオフは複雑にする必要はありません。よくある形は:delay = min(base * 2^(attempt-1), max) にジッター(±20% など)を加えること。ジッターは多くのワーカーが同時に失敗して同時に再試行するのを防ぎます。
遅延をどこで持たせるか?小さなシステムではワーカー内で sleep するのが簡単ですが、そのワーカーのスロットが埋まります。リトライが稀であればそれでも構いません。リトライが頻繁や遅延が長い場合、ジョブを再キューして“実行予定時刻”を持たせ、ワーカーが別の仕事を処理できるようにすることを検討します。
最終的に失敗した場合は明確に扱います。失敗したジョブ(と最後のエラー)を保存してレビューできるようにする、再実行できるように十分なコンテキストをログに残す、定期的に確認するデッドリストに入れるなど、サイレントドロップを避けてください。失敗を隠すプールは存在しないより悪いです。
実際に停止するキャンセルとタイムアウト
生成されたソースコードを所有
Go、React、データベースのフルコードを入手して所有・拡張できます。
ワーカープールが安全に感じられるのは、確実に止められるときです。最も単純なルールは:ブロックしうる全ての層に context.Context を渡すこと。これにはサブミッション、実行、クリーンアップが含まれます。
実務的な設定では二つの時間制限を使います:
- ジョブ毎のタイムアウト:一つのタスクがワーカーを永遠に占有しないようにする。\n- シャットダウンのタイムアウト:一部のジョブが協力しなくてもプロセスを終了できるようにする。
Context を端から端まで使う
各ジョブにワーカーのコンテキストから派生したコンテキストを与えます。そして遅い呼び出し(DB、HTTP、キュー、ファイル I/O)にはそのコンテキストを使わせ、早期に戻れるようにします。
func worker(ctx context.Context, jobs \u0003c-chan Job) {
for {
select {
case \u0003c-ctx.Done():
return
case job, ok := \u0003c-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
Run が DB や API を呼ぶなら、それらの呼び出しにコンテキストを渡してください(例:QueryContext、NewRequestWithContext、またはコンテキストを受け取るクライアントメソッド)。これを一つでも無視すると、キャンセルは“ベストエフォート”になり、もっとも必要なときに失敗します。
部分的な作業と「再試行して安全な」ステップ
キャンセルはジョブの途中で発生するので、部分的な作業を前提に設計します。再実行しても重複が起きないようにステップを冪等にするのが一般的なアプローチです。よくある方法は、挿入に一意キーを使う(または upsert)、進捗マーカー(started/done)を書く、先に結果を保存してから続ける、実行中に ctx.Err() をチェックする、などです。
シャットダウンは締め切りのように扱ってください:新しいジョブの受け付けを止め、ワーカーのコンテキストをキャンセルし、インフライトジョブが終了するまでシャットダウンタイムアウトだけ待ちます。
クリーンシャットダウン:プロセス終了時にやること
クリーンシャットダウンの目的は一つ:新しい仕事を受けず、インフライトの仕事に停止を伝えて、システムを変な状態に残さずに終了することです。
まずシグナルから始めます。多くの環境ではローカルで SIGINT、プロセスマネージャやコンテナランタイムからは SIGTERM を受けます。シグナル到着でキャンセルされるシャットダウンクオンテキストを作り、それをプールとジョブハンドラに渡します。
次に新規受け付けを止めます。誰も読まなくなったチャネルへの送信で呼び出しが永遠にブロックされないようにしてください。送信を一つの関数でまとめ、その関数がクローズフラグを確認するかシャットダウンクオンテキストを選択してから送るようにします。
キュー内の作業に対しては次のどちらかを決めます:
- ドレイン:既にキューにあるものは終わらせるが新規は拒否する。\n- ドロップ:まだ開始されていないものは破棄する。
支払い処理やメール送信などはドレインが安全です。キャッシュの再計算のような「やれたらいい」タスクならドロップで構いません。
実用的なシャットダウン手順:
- SIGINT/SIGTERM を捕まえて共有コンテキストをキャンセルする。\n- サブミッションを止める(送信経路を閉じるが必ずしも作業チャネルを閉じる必要はない)。\n- ワーカーをコンテキストに従って終了させるか途中で中止させる。\n- WaitGroup でワーカーを待つ。\n- 期限を設け、それを越えたらログを残して終了する。
期限は重要です。たとえばインフライトジョブに 10 秒与えるとします。それを越えたらまだ動いているものをログに残して終了します。これでデプロイが予測可能になり、プロセスが詰まるのを避けられます。
ワーカープールのログと簡単なメトリクス
Goでクリーンなシャットダウンを構築
シグナル処理とコンテキストのタイムアウトを数分でチャットプロンプトから作成します。
ワーカープールが壊れたとき、大抵は大きな障害で止まるのではなく、ジョブが遅くなり、リトライが積み上がり、「何も進んでいない」と報告されます。ログといくつかの基本カウンタがあれば、何が起きているかが明確になります。
各ジョブに安定した ID を与え(送信時に生成するなど)、その ID をすべてのログ行に含めます。ログの形を一貫させてください:ジョブ開始時に一行、完了時に一行、失敗時に一行。リトライするなら試行回数と次の遅延もログに残します。
シンプルなログ項目の例:
- start: job_id, worker_id, attempt, kind\n- finish: job_id, worker_id, attempt, duration_ms\n- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
メトリクスは最小限でも効果があります。キュー長、インフライトジョブ数、成功/失敗の合計、ジョブ遅延(平均と最大)を追いましょう。もしキュー長が伸び続けていてインフライトがワーカー数に張り付いているなら飽和しています。送信側が jobs チャネルへの送信でブロックしているなら、バックプレッシャーが呼び出し側に達していることになります。必ずしも悪いわけではありませんが、意図的であるべきです。
「ジョブが詰まっている」場合は、プロセスがまだジョブを受け取っているか、キュー長が伸びているか、ワーカーが生きているか、どのジョブが最も長く実行されているかを確認してください。長時間実行はタイムアウトの欠如、依存先の遅さ、あるいは止まらないリトライループが原因であることが多いです。
現実的な例:小さな SaaS のバックグラウンドキュー
ある SaaS で注文が PAID に変わったとします。支払い直後に請求書 PDF を作り、顧客にメールを送り、社内に通知する必要があります。これらをウェブリクエストでブロックしたくないので、ワーカープールの出番です。
ジョブのペイロードは最小限でよい:データベースから必要なものを取得するためのキーだけ持っていれば十分です。API ハンドラは同一トランザクション内で jobs(status='queued', type='send_invoice', payload, attempts=0) のように行を挿入し、バックグラウンドループがキューイングされたジョブをポーリングしてワーカーチャネルに流します。
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
ワーカーがジョブを拾ったとき、幸せなパスは単純です:注文を読み込み、請求書を生成し、メールプロバイダーを呼び、ジョブを完了としてマークします。
リトライが本領を発揮するのはここです。メールプロバイダーが一時的に落ちているなら、1,000 件のジョブを永遠に失敗させたり、毎秒プロバイダーを叩き続けたりしたくありません。実用的なアプローチは:
- ネットワークエラーや 5xx レスポンスはリトライ可能と扱う。\n- 指数バックオフに上限を設ける(例:5 秒、15 秒、45 秒、2 分)。\n- 試行回数に上限を設け、例えば 10 回で最終的に失敗にする。\n- 最後のエラーを記録してサポートが確認できるようにする。
障害の間、ジョブは queued -> in_progress -> queued(将来実行時刻付き)と移動します。プロバイダーが回復すると、ワーカーは自然にバックログを捌きます。
デプロイを想像してください。SIGTERM が入ります。プロセスは新しい仕事を受け付けず、インフライトの仕事を終わらせます。ポーリングを止め、ワーカーチャネルへの投入を止め、WaitGroup でワーカーを期限付きで待ちます。完了したジョブは done にマークされ、期限が来てまだ実行中のジョブは queued に戻す(またはウォッチドッグを使って in_progress のままにする)ことで、新しいバージョンが起動した後に拾えるようにします。
よくあるミスと罠
バックグラウンド処理のバグの多くはジョブログック以外に隠れています。負荷がかかったときやシャットダウン時にだけ現れる調整ミスです。
古典的な罠の一つは複数箇所からチャネルを close することです。再現が難しい panic を引き起こします。チャネルの所有者(通常はプロデューサー)を一つにして、その場所だけで close(jobs) を呼ぶようにしてください。
リトライも良かれと思ってやると障害を招く領域です。すべてをリトライすると永続的な失敗までリトライして無駄な負荷をかけ、ちょっとした問題をインシデントに拡大します。エラーを分類し、リトライに上限を設ける明確なポリシーが必要です。
重複は注意していても起きます。ワーカーがジョブの途中でクラッシュする、タイムアウトが仕事完了後に発生する、デプロイ中に再キューされる、などが原因です。ジョブが冪等でないと重複は実害になります:請求書が二重に送られる、歓迎メールが二度送られる、返金が二重に行われる、といったことです。
よく見かけるミス:
- 複数の goroutine から同じチャネルを close してしまう。\n- 永続的な失敗をリトライしてしまう。\n- 冪等性キーがないため重複で副作用が二重発生する。\n- メモリが増え続ける無限キュー。\n-
context.Contextを無視してシャットダウン後も作業が続いてしまう。
無限のキューは特に厄介です。スパイクで RAM に静かに積もり、気づいたときにはメモリが吹き飛ぶことがあります。バッファつきチャネルを使い、満杯になったときにブロックするのかドロップするのかエラーを返すのかを決めましょう。
本番投入前の簡単チェックリスト
ログと基本的なメトリクスを追加
キュー深度、レイテンシ、失敗を追うログとカウンタを生成します。
ワーカープールを本番に出す前に、ジョブのライフサイクルを言葉で説明できることが必要です。「このジョブは今どこにある?」と聞かれて、推測で答えるようではダメです。
実用的なプレフライトチェックリスト:
- 各状態と遷移を名前で言える:queued, picked up, running, finished, failed(それぞれどう移るか)。\n- 並行性は一つのノブ(
workerCountのような)で変えられ、コードを書き換えずに変えられる。\n- リトライは境界がある:最大試行回数が明確、バックオフは増え、永続失敗は意図した場所に行く。\n- シャットダウン動作が実証済み:受け付けを止め、インフライトを終わらせ、ハードなタイムアウトがある。\n- ログが基本を答えられる:job ID、試行回数、所要時間、エラー理由。
リリース前に一度本番に近いドリルをやってみてください:100 件の「レシートメール送信」ジョブをキューし、そのうち 20 件を強制的に失敗させ、実行中にサービスを再起動します。リトライが期待通り動くか、重複副作用がないか、締め切りでキャンセルが本当に止めるかを確認します。
どれか曖昧なら今すぐ締めてください。ここでの小さな修正が後で何日も節約します。
次のステップ:重いインフラを追加すべきとき(とそうでないとき)
プロダクトが若いうちはシンプルなプロセス内プールで十分なことが多いです。ジョブが「あると良い」性質(メール送信、キャッシュ更新、レポート生成)で再実行可能なら、ワーカープールは理解しやすく保守もしやすいです。
プロセス内プールを使い続けられない兆候
次の点に注意してください:
- 複数のアプリインスタンスを実行していて、どれか一つだけがジョブを拾う必要がある。\n- 耐久性が必要(クラッシュやデプロイを跨いでジョブが残ること)。\n- 監査トレイルが必要(誰が何をいつキューしたか、結果はどうだったか)。\n- サービス間でのバックプレッシャー制御が必要。\n- 厳密なスケジューリングや長時間(数時間〜数日)の遅延で確実な再開が必要。
これらが当てはまらなければ、重いツールは手間倒れになることがあります。
リライトせず段階的に移行する
安定したジョブインターフェース(小さなペイロード型、ID、明確な結果を返すハンドラ)を維持するのが最良のヘッジです。そうすればキューバックエンドを後で入れ替えても(メモリ内チャネル → DB テーブル → 専用キュー)ビジネスロジックを変えずに済みます。
実用的な中間ステップは、PostgreSQL のテーブルからジョブを読み取り、ロックでクレームし、ステータスを更新する小さな Go サービスを作ることです。こうすれば耐久性と基本的な監査性を得つつワーカーのロジックは同じままにできます。
もしすぐプロトタイプしたければ、Koder.ai (koder.ai) は Go + PostgreSQL のスターターをチャットプロンプトから生成でき、バックグラウンドジョブテーブルとワーカーループ、スナップショットとロールバック機能があるためリトライやシャットダウンの調整時に役立ちます。