2026年1月04日·1 分
Goのコンテキストタイムアウト:高速APIのための実践レシピ
Goのコンテキストのタイムアウトは、遅いDB呼び出しや外部リクエストの積み重なりを防ぎます。デッドラインの伝播、キャンセル、そして安全なデフォルトを学びましょう。
Goのコンテキストのタイムアウトは、遅いDB呼び出しや外部リクエストの積み重なりを防ぎます。デッドラインの伝播、キャンセル、そして安全なデフォルトを学びましょう。
単一の遅いリクエストはたいてい「ただ遅い」だけではありません。待っている間、ゴルーチンを維持し、バッファやレスポンスオブジェクトのためのメモリを占有し、しばしばデータベース接続やプール内のスロットも占有します。遅いリクエストが十分に積み重なると、限られたリソースが待ち続けるためにAPIは有益な作業を行えなくなります。
通常は三つの場所で影響を感じます。ゴルーチンが蓄積してスケジューリングオーバーヘッドが増え、結果として全体のレイテンシが悪化します。データベースプールの空き接続が尽きると、速いクエリですら遅いクエリの後ろにキューイングされます。インフライトのデータや未完成のレスポンスからメモリが増え、GCの負荷が上がります。
サーバーを増やすだけではしばしば解決になりません。各インスタンスが同じボトルネック(小さなDBプール、遅い上流、共有レート制限)に当たるなら、キューを移動させてコストだけ増え、エラーは依然として増えます。
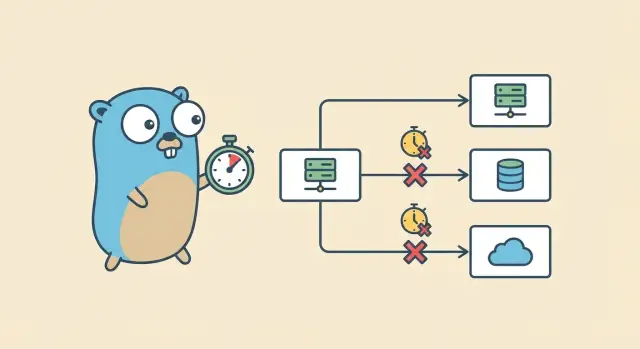
ハンドラがファンアウトする例を想像してください:PostgreSQLからユーザーを読み込み、支払いサービスを呼び、次にレコメンドサービスを呼び出す。もしレコメンド呼び出しがハングして何もキャンセルしなければ、リクエストは決して終わりません。DB接続は返るかもしれませんが、ゴルーチンやHTTPクライアントのリソースは縛られたままです。それが数百件のリクエストに掛かると、遅延のメルトダウンになります。
目的は単純です:明確な時間制限を設定し、時間が切れたら作業を止め、リソースを解放し、予測可能なエラーを返すこと。Goのコンテキストタイムアウトは各ステップにデッドラインを与え、ユーザーがもう待っていないときに作業が止まるようにします。
context.Context は呼び出しチェーンに渡す小さなオブジェクトで、全てのレイヤーが一つのことに合意できます:「このリクエストをいつまでに止めるか」。タイムアウトは、遅い依存関係がサーバーを占有するのを防ぐ一般的な方法です。
コンテキストは三種類の情報を運べます:デッドライン(作業を止める時刻)、キャンセル信号(誰かが早めに止めることを決めた)、そしていくつかのリクエストスコープの値(これは控えめに使い、大きなデータには使わないでください)。
キャンセルは魔法ではありません。コンテキストは Done() チャネルを露出します。それが閉じると、リクエストはキャンセルされたか時間切れです。コンテキストを尊重するコードは Done() をチェックし(多くは select で)、早期に戻ります。ctx.Err() をチェックすれば終了理由(通常は context.Canceled や context.DeadlineExceeded)がわかります。
context.WithTimeout は「X秒後に止める」用途に使います。正確な打ち切り時刻が既に分かっている場合は context.WithDeadline を使います。親条件で早めに止めたい(クライアント切断、ユーザーが離れた、既に答えがある等)場合は context.WithCancel を使います。
コンテキストがキャンセルされたときに正しい振る舞いは地味ですが重要です:作業を止め、遅いI/Oの待機を止め、明確なエラーを返すこと。ハンドラがデータベースクエリを待っていてコンテキストが終われば、速やかに返し、もしドライバがコンテキストをサポートしていればデータベース呼び出しを中断させてください。
遅いリクエストを止める最も安全な場所は、トラフィックがサービスに入る境界です。リクエストがタイムアウトするなら、それは予測可能かつ早い段階で起こるべきで、ゴルーチンやDB接続、メモリを占有した後ではいけません。
エッジ(ロードバランサ、APIゲートウェイ、リバースプロキシ)で、すべてのリクエストが許される最長時間のハードキャップを設定してください。それはハンドラがタイムアウトを忘れてもGoサービスを守ります。
Goサーバー内では、サーバーが遅いクライアントや応答の停滞を永遠に待たないようにHTTPタイムアウトを設定してください。最低でもヘッダ読み取り、リクエストボディの読み取り、レスポンス書き込み、アイドル接続の保持についてタイムアウトを構成します。
プロダクトに合わせたリクエストのデフォルト予算を選んでください。多くのAPIでは、一般的なリクエストに対して1〜3秒が妥当な出発点で、エクスポートのような既知の遅い操作にはより長い上限を設けます。正確な数値より重要なのは一貫性を持ち、計測し、例外のルールを明確にすることです。
ストリーミングレスポンスは追加の配慮が必要です。サーバーが接続を開いたまま小さなチャンクを書き続けたり、最初のバイトが出る前に永遠に待ってしまうような事故的な無限ストリームを作るのは簡単です。エンドポイントが本当にストリームかどうかを事前に決めてください。そうでなければ、総合の最大時間と最初のバイトまでの最大時間を強制してください。
境界に明確なデッドラインがあれば、リクエスト全体にそのデッドラインを伝播するのはずっと簡単になります。
最も簡単に始められる場所はHTTPハンドラです。1つのリクエストがシステムに入る場所なので、ここでハードリミットを設定するのが自然です。
デッドライン付きの新しいコンテキストを作り、必ずキャンセルを呼んでください。それからそのコンテキストをデータベース作業、HTTP呼び出し、または遅い計算などブロッキングしうるあらゆるものに渡します。
func (s *Server) GetUser(w http.ResponseWriter, r *http.Request) {
ctx, cancel := context.WithTimeout(r.Context(), 2*time.Second)
defer cancel()
userID := r.URL.Query().Get("id")
if userID == "" {
http.Error(w, "missing id", http.StatusBadRequest)
return
}
user, err := s.loadUser(ctx, userID)
if err != nil {
writeError(w, ctx, err)
return
}
writeJSON(w, http.StatusOK, user)
}
ctx を渡す良いルールは:関数がI/Oで待ちうるなら context.Context を受け取るべきです。ハンドラは読みやすさを保つために loadUser のような小さなヘルパーに詳細を押し出してください。
func (s *Server) loadUser(ctx context.Context, id string) (User, error) {
return s.repo.GetUser(ctx, id) // repo should use QueryRowContext/ExecContext
}
デッドラインに達した(またはクライアントが切断した)場合は作業を止め、ユーザーフレンドリーな応答を返してください。一般的なマッピングは context.DeadlineExceeded を 504 Gateway Timeout に、context.Canceled を「クライアントがいなくなった」(多くはボディを返さない)にすることです。
func writeError(w http.ResponseWriter, ctx context.Context, err error) {
if errors.Is(err, context.DeadlineExceeded) {
http.Error(w, "request timed out", http.StatusGatewayTimeout)
return
}
if errors.Is(err, context.Canceled) {
// Client went away. Avoid doing more work.
return
}
http.Error(w, "internal error", http.StatusInternalServerError)
}
このパターンは積み重なりを防ぎます。タイマーが切れるとチェーン全体のコンテキスト対応関数が同じ停止信号を受け取り、速やかに終了できます。
ハンドラにデッドライン付きのコンテキストがあるとき、最も重要なルールは単純です:その同じ ctx をデータベース呼び出しの中まで使ってください。そうすることでタイムアウトが単にハンドラの待ちを止めるだけでなく、実際の作業を止めます。
database/sql ではコンテキスト対応メソッドを優先して使ってください:
func (s *Server) getUser(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
row := s.db.QueryRowContext(ctx,
"SELECT id, email FROM users WHERE id = $1",
r.URL.Query().Get("id"),
)
var id int64
var email string
if err := row.Scan(&id, &email); err != nil {
// handle below
}
}
ハンドラ予算が2秒なら、データベースにはその一部しか与えないでください。JSONエンコードや他の依存性、エラーハンドリングのための時間を残します。単純な出発点は総予算の30%〜60%をPostgresに与えることです。2秒のハンドラ予算なら800ms〜1.2sが目安になるでしょう。
コンテキストがキャンセルされるとドライバはPostgresにクエリ停止を依頼します。通常は接続がプールに戻され再利用されます。キャンセル中にネットワークが不調だとドライバがその接続を破棄し、後で新しい接続を開くことがあります。いずれにしてもゴルーチンが永遠に待つことを避けられます。
エラーをチェックする際は、タイムアウトと他のDB障害を区別してください。errors.Is(err, context.DeadlineExceeded) なら時間切れでタイムアウトを返すべきです。errors.Is(err, context.Canceled) ならクライアントが離れたので静かに止めるべきです。他のエラーは通常のクエリ障害(SQLエラー、行なし、権限など)です。
ハンドラにデッドラインがあるなら、外向けHTTP呼び出しもそれを守るべきです。そうでないとクライアントは諦めてもサーバー側は遅い上流を待ち続け、ゴルーチンやソケット、メモリを占有し続けます。
親コンテキストでアウトバウンドリクエストを作ればキャンセルは自動的に伝搬します:
func fetchUser(ctx context.Context, url string) ([]byte, error) {
// Add a small per-call cap, but never exceed the parent deadline.
ctx, cancel := context.WithTimeout(ctx, 800*time.Millisecond)
defer cancel()
req, err := http.NewRequestWithContext(ctx, http.MethodGet, url, nil)
if err != nil {
return nil, err
}
resp, err := http.DefaultClient.Do(req)
if err != nil {
return nil, err
}
defer resp.Body.Close() // always close, even on non-200
return io.ReadAll(resp.Body)
}
その呼び出しごとのタイムアウトは安全装置です。親リクエストのデッドラインが本当の支配者であり、全体のための一つの時計と、リスクの高いステップごとの小さな上限を併用するイメージです。
トランスポートレベルでもタイムアウトを設定してください。コンテキストはリクエストをキャンセルしますが、トランスポートのタイムアウトは遅いハンドシェイクやヘッダを一切送らないサーバーから守ってくれます。
チームを悩ませる細かい点:レスポンスボディはすべての経路で必ず閉じる必要があります。早期に戻る(ステータスコードチェック、JSONデコードエラー、コンテキストタイムアウト)場合でもボディを閉じてください。ボディをリークすると接続プールが枯渇し、原因不明のレイテンシスパイクに繋がります。
具体例:あなたのAPIが決済プロバイダを呼ぶ。クライアントは2秒でタイムアウトするが上流は30秒ハングする。リクエストキャンセルとトランスポートタイムアウトがなければ、放棄された各リクエストでその30秒を払い続けることになります。
単一のリクエストは通常複数の遅い要素に触れます:ハンドラ作業、DBクエリ、そして一つ以上の外部API。各ステップに寛大なタイムアウトを与えると合計時間が静かに膨らみ、ユーザーがそれを感じ、サーバーが積み重なっていきます。
予算管理が最も簡単な修正です。一つの親デッドラインを設定し、それから各依存先に小さなスライスを与えます。子のデッドラインは親より早く設定して、早く失敗してクリーンなエラーを返す時間を確保します。
実務で有効な経験則:
互いに争うようなタイムアウトを積み重ねるのは避けてください。ハンドラコンテキストが2秒でHTTPクライアントが10秒のタイムアウトなら安全ですが混乱を招きます。逆にクライアントの方が短いと無関係な理由で早期に切られることがあります。
バックグラウンド作業(監査ログ、メトリクス、メールなど)にはリクエストのコンテキストを再利用しないでください。クライアントのキャンセルで重要なクリーンアップが殺されないよう、独自の短いタイムアウトを持つ別のコンテキストを使います。
大抵のタイムアウトバグはハンドラではなく、その下の一つか二つのレイヤーで起きます。境界でタイムアウトを設定しても途中で無視されると、クライアントが去った後でもゴルーチン、DBクエリ、HTTP呼び出しが走り続けます。
よく見かけるパターンは単純です:
context.Background()(または TODO)で呼んでしまう。これでクライアントキャンセルやハンドラのデッドラインと切断される。ctx.Done() をチェックせずにスリープ、リトライ、ループを行う。リクエストはキャンセルされてもコードは待ち続ける。context.WithTimeout を付ける。タイマーが多くなりデッドラインがわかりにくくなる。ctx を付け忘れる。ハンドラのタイムアウトは依存先が無視するなら何もしない。古典的な失敗例:ハンドラで2秒のタイムアウトを追加したのに、リポジトリがデータベースクエリで context.Background() を使っている。負荷下では遅いクエリがクライアント放棄後も走り続け、積み重なります。
基本を直してください:コールスタックの最初の引数として ctx を渡すこと。長時間かかる作業の中では select { case <-ctx.Done(): return ctx.Err() default: } のような短いチェックを入れてください。context.DeadlineExceeded をタイムアウト応答(多くは504)に、context.Canceled をクライアントキャンセル風の応答(環境によって499や408)にマップします。
タイムアウトは発生が見え、システムがきれいに回復するかを確認できないと役に立ちません。何かが遅いとき、リクエストは止まり、リソースは解放され、APIは応答性を保つべきです。
すべてのリクエストで同じ小さなフィールドセットをログに残して、通常のリクエストとタイムアウトを比較できるようにします。コンテキストのデッドライン(存在するなら)と何が作業を終わらせたかを含めてください。
有用なフィールドはデッドライン(なければ "none")、合計経過時間、キャンセル理由(タイムアウトかクライアント切断か)、短い操作ラベル("db.query users"、"http.call billing")、リクエストIDなどです。
最小パターンの例:
start := time.Now()
deadline, hasDeadline := ctx.Deadline()
err := doWork(ctx)
log.Printf("op=%s hasDeadline=%t deadline=%s elapsed=%s err=%v",
"getUser", hasDeadline, deadline.Format(time.RFC3339Nano), time.Since(start), err)
ログは個々のリクエストのデバッグに役立ちます。メトリクスは傾向を示します。
トレンドとして早めに表れる信号をいくつか追跡してください:ルートや依存先ごとのタイムアウト件数、インフライトリクエスト数(負荷下で安定するはず)、DBプールの待ち時間、成功とタイムアウトに分けたレイテンシのパーセンタイル(p95/p99)など。
遅さを予測可能にします。デバッグ用に一つのハンドラに遅延を入れる、DBクエリを意図的に待たせる、外部呼び出しをスリープするテストサーバーでラップするなどして、二つのことを確認してください:タイムアウトエラーが見えること、キャンセル後に作業がすぐ止まること。
小さな負荷テストも有効です。30〜60秒間、20〜50並列リクエストを投げて一つの依存先を遅くする。ゴルーチン数とインフライト数は上がってから頭打ちになるはずです。もし増え続けるなら、どこかがコンテキストキャンセルを無視しています。
タイムアウトはリクエストが待ちうる箇所すべてに適用されて初めて効きます。デプロイ前にコードベースを一巡して同じルールが各ハンドラで守られているか確認してください。
context.DeadlineExceeded と context.Canceled をチェックしている。http.NewRequestWithContext(または req = req.WithContext(ctx))を使い、クライアント/トランスポートには接続、TLS、レスポンスヘッダのタイムアウトが設定されている。本番系では http.DefaultClient に依存しない。リリース前に「遅い依存先」ドリルを1回やるだけの価値があります。あるSQLクエリに人工的な2秒遅延を入れ、三つを確認してください:ハンドラが定時に返ること、DB呼び出しが実際に止まること(ハンドラだけが止まるのではないこと)、ログがDBタイムアウトだったと明確に示すこと。
GET /v1/account/summary のようなエンドポイントを想像してください。1つのユーザー操作がトリガーするのは、PostgreSQLクエリ(アカウントと最近のアクティビティ)と外部HTTP呼び出しが2つ(例:課金ステータスチェックとプロファイル補完)です。
リクエスト全体に厳格な2秒の予算を与えると、予算がなければ一つの遅い依存先がゴルーチン、DB接続、メモリを縛り続け、API全体がタイムアウトし始めます。
単純な分配はDBに800ms、外部Aに600ms、外部Bに600msです。
デッドラインが分かればそれを下に伝えてください。各依存先は自分の小さなタイムアウトを持ちますが、親からのキャンセルも受け継ぎます。
func AccountSummary(w http.ResponseWriter, r *http.Request) {
ctx, cancel := context.WithTimeout(r.Context(), 2*time.Second)
defer cancel()
dbCtx, dbCancel := context.WithTimeout(ctx, 800*time.Millisecond)
defer dbCancel()
aCtx, aCancel := context.WithTimeout(ctx, 600*time.Millisecond)
defer aCancel()
bCtx, bCancel := context.WithTimeout(ctx, 600*time.Millisecond)
defer bCancel()
// Use dbCtx for QueryContext, aCtx/bCtx for outbound HTTP requests.
}
外部呼び出しBが遅れて2.5秒かかった場合、ハンドラは600msで待つのをやめ、インフライト作業をキャンセルしてクライアントに明確なタイムアウト応答を返すべきです。クライアントは長いハングの代わりに速い失敗を受け取れます。
ログはどこが予算を使ったかを明確にするべきです。例えば:DBは速く終わり、外部Aは成功し、外部Bは上限に達して context deadline exceeded を返した、のように。
一つの実際のエンドポイントでタイムアウトとキャンセルがうまく動くようになったら、それを再利用可能なパターンに変えましょう。ハンドラデッドライン、DB呼び出し、外部HTTPをエンドツーエンドで適用し、次のエンドポイントにも同じ構造をコピーします。
退屈な部分を集約すると速く動けます:境界タイムアウトヘルパー、ctx をDBやHTTP呼び出しに渡すラッパー、一貫したエラーマッピングとログフォーマット。
このパターンを素早くプロトタイプしたければ、Koder.ai (koder.ai) はチャットプロンプトからGoハンドラとサービス呼び出しを生成し、ソースをエクスポートして自分のタイムアウトヘルパーや予算を適用できます。目的は一貫性です:遅い呼び出しが早めに止まり、エラーの見た目が揃い、デバッグが誰が書いたかに依存しないようにすること。
遅いリクエストは待っている間に限られたリソースを占有します:ゴルーチン、バッファやレスポンス用のメモリ、そして多くの場合はデータベース接続やHTTPクライアント接続です。多数のリクエストが同時に待つとキューが発生し、全体のレイテンシが上がり、そのサービスは各リクエストが最終的に完了するかどうかにかかわらず失敗することがあります。
リクエスト境界(プロキシ/ゲートウェイとサーバー内)で明確なデッドラインを設定し、ハンドラ内でタイム付きの ctx を導出して、すべてのブロッキング呼び出し(DBや外部HTTP)にその ctx を渡すことです。デッドラインに達したら迅速に一貫したタイムアウト応答を返し、キャンセル可能な進行中作業を停止します。
context.WithTimeout(parent, d) は「指定した期間後に止める」用途で最も一般的です。既に固定の打ち切り時刻がある場合は context.WithDeadline(parent, t) を使います。内部条件で早めに止めたい場合(たとえば「もう答えが揃った」や「クライアントが切断した」など)は context.WithCancel(parent) を使います。
派生したコンテキストを作ったら、通常はすぐに defer cancel() を呼び出してください。キャンセルはタイマーを解放し、早く抜けるコードパスでも明確な停止信号を子作業に伝えるために重要です。
ハンドラで一度リクエスト用の ctx を作り、それをブロッキングしうる関数の最初の引数として渡してください。context.Background() や context.TODO() がリクエスト経路に残っていないか検索するのは、デッドラインが下層まで届いているか確認する簡単なチェックです。
QueryContext、QueryRowContext、ExecContext のようなコンテキスト対応のDBメソッドを使ってください。コンテキストが終了するとドライバはPostgresにクエリ停止を要求し、不要に時間や接続を消費し続けることを防げます。
親リクエストの ctx を http.NewRequestWithContext(ctx, ...) で外向けリクエストに添付し、接続、TLS、レスポンスヘッダ待ちに対するクライアント/トランスポートのタイムアウトも設定してください。エラーや非200応答でも必ず resp.Body.Close() を呼んで接続をプールに戻すことを忘れないでください。
まずリクエスト全体の予算を決め、それを各依存先に小分けにします。ハンドラオーバーヘッドやエンコードのためのバッファを残し、複数外部呼び出しがある場合はそれぞれに上限を付けます。親コンテキストの残り時間が短ければ、実行に間に合わない重い作業を開始しないでください。
context.DeadlineExceeded は一般に 504 Gateway Timeout にマップし短いメッセージ(例:「request timed out」)を返すのが一般的です。context.Canceled は通常クライアント切断を意味するので、無駄に処理を続けずにボディを書かずに終えるのがよい場合が多いです(環境によっては 499 や 408 を使うこともあります)。
よくあるミスは、リクエストの ctx を破棄して context.Background() を使うこと、ctx.Done() をチェックせずにスリープやリトライを行うこと、ブロッキング呼び出しに ctx を渡し忘れることです。また、無関係に多くのタイムアウトを積み重ねると失敗原因が理解しにくくなります。