2025年12月31日·1 分
相関IDのエンドツーエンド:ログでユーザー操作をたどる
相関IDのエンドツーエンド運用について、フロントエンドで1つのIDを作りAPIを通して渡し、ログに含めることでサポートが迅速に問題を追跡できる方法を解説します。
相関IDのエンドツーエンド運用について、フロントエンドで1つのIDを作りAPIを通して渡し、ログに含めることでサポートが迅速に問題を追跡できる方法を解説します。
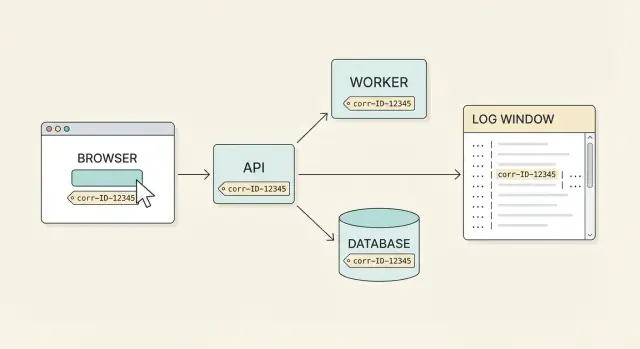
サポートに届くバグ報告がきれいにまとまっていることはほとんどありません。ユーザーは「Payをクリックしたら失敗した」と言いますが、その1回のクリックはブラウザ、APIゲートウェイ、決済サービス、データベース、バックグラウンドジョブなど複数の箇所に触れます。各パーツは別々のタイミングと別々のマシンでログを残します。共通のラベルがなければ、どのログ行が一緒に属するかを推測することになってしまいます。
相関IDはその共通ラベルです。1つのユーザー操作(または1つの論理ワークフロー)に紐づけられる1つのIDで、すべてのリクエスト、リトライ、サービス間のホップを通して運びます。本当にエンドツーエンドでカバーできていれば、ユーザーからの苦情を出発点にしてシステム全体のタイムラインを引き出せます。
よく似たIDが混同されがちなので、ここで整理します。
理想的な運用はシンプルです: ユーザーが問題を報告し、UIに表示された(またはサポート画面で見つけた)相関IDを教えてもらえば、チームの誰でも数分で全体の流れを見つけられます。フロントエンドのリクエスト、APIの応答、バックエンドの処理、データベースの結果がすべて1つに紐づきます。
何かを生成する前に、いくつかのルールに合意してください。各チームが異なるヘッダー名やログフィールドを選ぶと、結局サポートは推測する羽目になります。
まず1つの標準名を決めてどこでも使いましょう。一般的には X-Correlation-Id のようなHTTPヘッダーと、ログ用の構造化フィールド correlation_id を選びます。つづりと大文字小文字を1つに決め、ドキュメント化し、リバースプロキシやゲートウェイがヘッダー名を書き換えたり削除したりしないよう確認してください。
チケットやチャットで共有しやすく作成が簡単なフォーマットを選びます。UUIDは一意で扱いやすいため適しています。コピーしやすい長さを保ちつつ衝突リスクが高くならないようにしてください。凝ったものより一貫性が優先です。
また、人間が実際に使える場所にIDが出るように決めておきます。現実的には、リクエスト、ログ、エラー出力に現れ、チームが使うツールで検索可能であることを意味します。
1つのIDがどのくらい生きるべきかも定義してください。良いデフォルトは1つのユーザー操作(例: 「Payをクリック」や「プロフィールを保存」)です。サービスやキューをまたぐ長いワークフローなら、そのワークフローが終わるまで同じIDを使い、次のアクションでは新しいIDを使います。セッション全体で1つのIDを使う運用は避けてください。検索がすぐにノイズだらけになります。
重要なルール: IDに個人情報を入れてはいけません。メール、電話番号、ユーザーID、注文番号などは入れず、必要なら別フィールドに適切なプライバシー管理で記録してください。
相関IDを生み出す最も簡単な場所は、ユーザーが重要な操作を始めた瞬間です: 「保存」クリック、フォーム送信、複数のリクエストを引き起こすフローのトリガーなど。バックエンドに生成を任せると、UIエラーやリトライ、キャンセルされたリクエストなど最初の部分を見失いがちです。
ランダムで一意なフォーマットを使いましょう。UUID v4は生成が簡単で衝突しにくいため一般的です。IDは不透明にして(ユーザー名やメール、タイムスタンプを含めない)、ヘッダーやログに個人情報を漏らさないようにします。
「ワークフロー」は、検証、アップロード、レコード作成、一覧の更新など複数のリクエストを引き起こす1つのユーザー操作と考えます。ワークフローが始まったときに1つのIDを作り、成功・失敗・キャンセルのいずれかで終了するまで保持します。簡単なパターンは、コンポーネントのステートや軽量のリクエストコンテキストオブジェクトに保存する方法です。
同じ操作をユーザーが2回開始したら、2回目は新しい相関IDを生成してください。これにより「同じクリックをリトライした」ケースと「別々の2回の送信」を区別できます。
ワークフローで発生するすべてのAPI呼び出しにIDを追加します。通常は X-Correlation-ID のようなヘッダーで渡します。共有のAPIクライアント(fetchラッパー、Axiosインスタンスなど)を使っているなら、IDを一度渡してクライアント側で全呼び出しに注入させると楽です。
// 1) when the user action starts
const correlationId = crypto.randomUUID(); // UUID v4 in modern browsers
// 2) pass it to every request in this workflow
await api.post('/orders', payload, {
headers: { 'X-Correlation-ID': correlationId }
});
await api.get('/orders/summary', {
headers: { 'X-Correlation-ID': correlationId }
});
UIがポーリング、分析送信、自動更新などアクションに無関係なバックグラウンドリクエストを行う場合は、それらにワークフローIDを再利用しないでください。相関IDは1つのストーリーに集中させるべきです。
ブラウザで相関IDを生成したら、やるべきことは単純です: すべてのリクエストでフロントエンドから出し、すべてのAPI境界で変わらず到着させること。新しいエンドポイント、クライアント、ミドルウェアを追加するとここが壊れやすくなります。
安全なデフォルトは、すべての呼び出しでHTTPヘッダー(例: X-Correlation-Id)を使うことです。ヘッダーは1か所(fetchラッパー、Axiosインターセプター、モバイルのネットワーキングレイヤー)で追加しやすく、ペイロード変更が不要です。
クロスオリジンのリクエストがある場合は、APIがそのヘッダーを許可しているか確認してください。そうしないとブラウザがヘッダーを送信できず、送っていると思っていて実は送れていない、ということが起こります。
やむを得ずクエリ文字列やリクエストボディにIDを入れなければならない場合(サードパーティツールやファイルアップロードなどで強制されることがあります)は、一貫性を保ち、ドキュメント化してください。エンドポイントごとに correlationId、requestId、cid と混在させないこと。
リトライもよくある落とし穴です。同じユーザー操作のリトライなら同じ相関IDを使うべきです。例: ユーザーが「保存」をクリックし、ネットワークが切れてクライアントがPOSTを再試行する場合、サポートは1本のつながった軌跡を見るべきで、3つのバラバラのトレイルを見てはいけません。ユーザーの新しいクリック(あるいは新しいバックグラウンドジョブ)は新しいIDを得ます。
WebSocketの場合は、最初のハンドシェイクだけでなく、メッセージエンベロープごとにIDを含めてください。1つの接続が多数のユーザー操作を運ぶことがあるためです。
簡単な信頼性チェックの方針は次の通りです:
correlationId フィールドを含める。APIエッジ(ゲートウェイ、ロードバランサ、または最初にトラフィックを受けるWebサービス)は、相関IDが信頼できるかどうかを決める場所です。ここをソースオブトゥルースとして扱ってください。
クライアントがIDを送ってきたら受け入れ、常にあるとは限らないことを前提にしてください。欠けている場合は即座に新しいIDを生成し、そのリクエストの残りに使います。こうすることで古いクライアントや設定ミスのあるクライアントとも動作を保てます。
ログを汚さないために軽いバリデーションを行ってください。許容的に: 長さと許可文字をチェックしつつ、実際のトラフィックを拒否してしまわないようにします。例えば16〜64文字、英数字、ダッシュ、アンダースコアを許可すると良いでしょう。バリデーションに失敗したら新しいIDで置き換えて続行します。
呼び出し元にIDを見えるようにしてください。レスポンスヘッダーに常に入れ、エラー本文にも含めます。これによりユーザーがUIからコピーしたり、サポートがIDを尋ねて正確なログ追跡を行いやすくなります。
実用的なエッジポリシーの例:
X-Correlation-ID(または選んだヘッダー)を読む。X-Correlation-ID を追加する。例: サポートがチケットやスクリーンショットで見るべきエラー本文:
{
"error": {
"code": "PAYMENT_FAILED",
"message": "We could not confirm the payment.",
"correlation_id": "c3a8f2d1-9b24-4c61-8c4a-2a7c1b9c2f61"
}
}
リクエストがバックエンドに届いたら、相関IDはリクエストコンテキストの一部として扱い、グローバル変数に忍ばせないでください。グローバルは2つのリクエストを同時に扱ったり、レスポンス後も非同期処理が続いたりする場合に壊れます。
スケールするルール: ログを出したり別サービスを呼ぶ可能性のある関数は、IDを含むコンテキストを受け取るようにします。Goのサービスでは通常 context.Context をハンドラやビジネスロジック、クライアントコードに渡します。
Service AがService Bを呼ぶときは、同じIDをアウトゴーイングリクエストにコピーしてください。途中で新しいIDを生成するなら、元のIDを別フィールド(例: parent_correlation_id)として保持しない限りやめてください。IDを変えてしまうと、サポートはストーリーをたどれなくなります。
伝播が見落とされがちな箇所は決まっています: リクエスト中にキックされるバックグラウンドジョブ、クライアントライブラリ内のリトライ、後から呼ばれるWebhook、扇状に広がる呼び出しなどです。非同期メッセージ(キュー/ジョブ)にはIDを載せ、リトライロジックはそれを保持するようにしてください。
ログは correlation_id のような安定したフィールド名で構造化してください。requestId、req_id、traceId を混在させると検索が難しくなります。もし複数使うなら明確な対応関係を定義してください。
可能であれば、データベースの可視性にもIDを含めてください。実用的な方法はクエリコメントやセッションメタデータに入れておくことです。そうすればスロークエリログにも相関IDが出て、サポートは「保存ボタンで10秒止まった」と言われたときに correlation_id=abc123 で検索してAPIログ、下流サービス呼び出し、原因となった遅いSQLを見つけられます。
相関IDは人が見つけて追跡できなければ役に立ちません。IDをメッセージ文字列に埋め込むのではなく、第一級のログフィールドにし、サービス間でログエントリの形式を揃えてください。
相関IDに加えて、いつ・どこで・何が・誰が(ユーザー安全な形で)わかる小さなフィールドセットを添えると使いやすくなります。多くのチームでは次のようなものが実用的です:
timestamp(タイムゾーン付き)service と env(api、worker、prod、stagingなど)route(または操作名)と methodstatus と duration_msaccount_id またはハッシュ化したユーザーID、メールは不可)これがあれば、サポートはIDで検索して正しいリクエストか確認し、どのサービスが処理したかを見られます。
リクエストごとに大量にログを残すのではなく、辿るための有力な足跡をいくつか残すのを目標にしてください。
rows=12)。ノイズを避けるため、デバッグレベルの詳細はデフォルトで出さないようにし、問題の発見に役立つイベントだけをInfoレベルに上げてください。問題の場所や影響を示さない行はInfoレベルには不要かもしれません。
マスキング(リダクション)も構造と同じくらい重要です。相関IDやログにPIIを含めないでください: メール、氏名、電話番号、完全な住所、生のトークンなどは記録しないでください。ユーザーを特定する必要があるなら内部IDか一方向ハッシュを使ってください。
ユーザーがサポートに「チェックアウトでPayを押したら失敗した」とメッセージを送ってきたとします。サポートが最初に聞くべき簡単な質問は: 「エラー画面に表示されている相関IDを貼ってもらえますか?」です。ユーザーが cid=9f3c2b1f6a7a4c2f と返信したとします。
サポートはそのIDを手掛かりにUI、API、データベースの流れをたどれます。目標は、その操作に関するすべてのログ行が同じIDを持っていることです。
サポートが 9f3c2b1f6a7a4c2f でログを検索すると次のような流れが見つかります:
frontend INFO cid=9f3c2b1f6a7a4c2f event="checkout_submit" cart=3 items
api INFO cid=9f3c2b1f6a7a4c2f method=POST path=/api/checkout user=1842
api ERROR cid=9f3c2b1f6a7a4c2f msg="payment failed" provider=stripe status=502
ここからエンジニアは同じIDで次のホップを追います。バックエンドサービス呼び出し(およびキューのジョブ)もIDを転送していることが重要です。
payments INFO cid=9f3c2b1f6a7a4c2f action="charge" amount=49.00 currency=USD
payments ERROR cid=9f3c2b1f6a7a4c2f err="timeout" upstream=stripe timeout_ms=3000
db INFO cid=9f3c2b1f6a7a4c2f query="insert into failed_payments" rows=1
問題は具体的になります: paymentsサービスが3秒後にタイムアウトし、失敗レコードが書かれています。エンジニアは最近のデプロイを確認し、タイムアウト設定の変更を調べ、リトライが発生しているかをチェックできます。
ループを閉じるために、次の4点を確認してください:
相関IDを無効にする最速の方法はチェーンを壊すことです。多くの失敗は、開発中には無害に思える小さな判断から発生し、サポートが必要になったときに響きます。
古典的なミスは、各ホップで新しいIDを生成することです。ブラウザがIDを送ってきたら、APIゲートウェイはそれを保持し、置き換えてはいけません。内部で別のIDが本当に必要な場合(キューメッセージやバックグラウンドジョブなど)は、元のIDを parent_correlation_id のように保持してください。
別のよくあるギャップは部分的なログです。チームが最初のAPIにだけIDを付けて、ワーカーやスケジュールジョブ、DBアクセス層に付け忘れることがあります。結果として行き止まりが発生します: リクエストがシステムに入ったのは見えるが、その後どこに行ったかが見えません。
IDがすべての場所に存在していても、各サービスが別のフィールド名や形式を使っていたら検索が難しくなります。フロントエンド、API、ログを通して1つの名前(例: correlation_id)を選び守ってください。フォーマットも1つ(多くはUUID)にし、コピー&ペーストが確実に動くよう大文字小文字を区別して扱ってください。
問題が起きたときにIDを失わないでください。APIが500やバリデーションエラーを返す場合でも、エラー応答に相関IDを含め(可能ならレスポンスヘッダーにも)、ユーザーがサポートチャットにそのIDを貼れるようにしてください。そうすればチームは即座に全経路を追跡できます。
サポートが1つのIDから関係するすべてのログ行(失敗を含む)をたどれるか、という簡単なテストを用意してください。
これを使って「ログを検索すれば良い」とサポートに言う前に整合性を確認してください。すべてのホップが同じルールに従っているときだけ、この仕組みは機能します。
correlation_id をリクエスト関連ログの構造化フィールドとして含めている。チェーンを途切れさせないために最小の変更で直してください。
correlation_id を保持し、詳細が必要なら別の span_id を追加する。穴を見つける簡単なテスト: デベロッパーツールを開いて1つの操作をトリガーし、最初のリクエストから相関IDをコピーして、それが関連するAPIリクエストとすべてのログ行に同じ値で現れるか確認する。
相関IDは、皆が同じやり方で常に使うときにだけ役に立ちます。相関IDの扱いを「必要条件」として出荷プロセスに組み込みましょう。単なるログ改善ではなく出荷基準の一部にしてください。
新しいエンドポイントやUIアクションを追加する際に、小さなトレーサビリティのステップをDefinition of Doneに加えます。IDがどのように生成(または再利用)され、フロー中どこに保持され、どのヘッダーで運ばれ、ヘッダーが無いときに各サービスがどうするかをカバーします。
軽量なチェックリストで十分です:
correlation_id)を一貫させる。サポートにもデバッグが速く再現可能になる簡単なスクリプトを用意してください。ユーザーにIDがどこに出るか(例: エラーダイアログの「デバッグIDをコピー」ボタン)を決め、サポートが尋ねるべきことと検索すべき場所を書き出します。
本番で頼る前に、実際の使用に近いフローをステージ環境で実行してください: ボタンをクリックし、検証エラーを起こし、続けて操作を完了する。ブラウザリクエストからAPIログ、背景ワーカー、(記録しているなら)データベース呼び出しログまで同じIDをたどれるか確認します。
もしKoder.aiでアプリを構築しているなら、Planning Modeに相関IDのヘッダーとロギングコンベンションを書き込み、生成されるReactフロントエンドやGoサービスが最初から一貫した設定になるようにすると便利です。
相関IDは、ブラウザ、API、サービス、ワーカーにまたがる一つのユーザー操作やワークフローに関連するすべてをタグ付けする共通の識別子です。サポートはこの1つのIDから全体のタイムラインを引き出せるため、どのログ行が関連するかを推測する必要がなくなります。
「Payをクリックして失敗した」のような1件のインシデントをエンドツーエンドでデバッグしたいときに相関IDを使います。セッションIDは多くの操作にまたがって広すぎますし、リクエストIDは1つのHTTPリクエストだけを識別するため、リトライで変わってしまう点で狭すぎます。
ベストプラクティスは、ワークフローが始まったとき、すなわちフォーム送信やボタンクリックなどフロントエンド側で作成することです。これによりUIエラーやリトライ、キャンセルなど、最初の部分の記録を失わずに済みます。
コピーしやすくサポートチケットで共有しても安全な、UUIDに類する不透明な値を使うのが良いです。個人情報やメール、注文番号、タイムスタンプをIDに埋め込してはいけません。必要な文脈は別のログフィールドで扱い、適切なプライバシー管理を行ってください。
1つの正式なヘッダー名を決めてどこでも使うことが重要です。例えば X-Correlation-ID を使い、ログでは一貫して correlation_id のような構造化フィールドに記録します。名前の一貫性が、サポートが探すものを予測可能にします。
同じユーザー操作に対するリトライでは同じ相関IDを使い続けるべきです。ログがつながったままになり、調査が容易になります。ユーザーが後で別の試行を行った場合は新しい相関IDを生成してください。
APIエントリポイントは、受信ヘッダーがあれば使い、無ければ新しいIDを生成するべきです。無効な値は検証して新しいIDに置き換え、レスポンスヘッダーやエラー本文に相関IDを必ず返してください。ユーザーとサポートがUIからコピーできるようにするためです。
リクエストコンテキストに相関IDを入れて、すべての下流呼び出しにコピーしてください。内部で新しい相関IDを生成するとチェーンが切れるので避けてください。詳細が必要なら別の内部IDを追加し、元の相関IDは保持してください。キューやジョブにもIDを渡すことを忘れないでください。
相関IDをメッセージ文字列に埋め込むのではなく、構造化フィールドとして最初のクラスでログに含めてください。サービス名、ルート、ステータス、処理時間、ユーザーを特定できる安全な識別子など、実用的なフィールドとペアにしておくと、サポートがIDで検索して現状を把握しやすくなります。失敗時にも必ず記録してください。
簡単なテストは、1つの操作を実行して、最初のリクエストやエラー画面から相関IDをコピーし、関連するすべてのリクエストヘッダーとサービスのログ行に同じ値があるか確認することです。ワーカーやリトライ、エラー応答でIDが消えるなら、それが修正すべき最初のギャップです。