2026年1月16日·1 分
ドキュメント中心のワークフロー:データモデルとUIパターン
バージョン管理、プレビュー、メタデータ、明確なステータスを実務で使えるデータモデルとUIパターンで解説する、ドキュメント中心ワークフロー入門。
バージョン管理、プレビュー、メタデータ、明確なステータスを実務で使えるデータモデルとUIパターンで解説する、ドキュメント中心ワークフロー入門。
ドキュメント中心のアプリは、ユーザーが作成・確認・依存する対象がドキュメントそのもの(PDF、画像、スキャン、領収書など)である場合です。ファイルが単なる添付物として扱われるフォーム中心の体験ではなく、ファイルを中心に設計された体験です。
ドキュメント中心のワークフローでは、人は文書の中で実際に作業します:開いて何が変わったか確認し、文脈を追加し、次に何をするか判断します。文書が信用できなければ、アプリは役に立たなくなります。
多くのドキュメント中心アプリは、早い段階でいくつかの核となる画面が必要です:
問題はすぐに現れます。ユーザーが同じ領収書を二度アップロードする。誰かがPDFを編集して何も説明せずに再アップロードする。スキャンに日付やベンダー、所有者がない。数週間後、どのバージョンが承認されたのか、決定は何に基づくのか誰もわからない。
良いドキュメント中心アプリは速く、信頼できる感触があります。ユーザーは次の質問に数秒で答えられるべきです:
その明確さは定義から来ます。画面を作る前に、アプリ内で「バージョン」「プレビュー」「メタデータ」「ステータス」が何を意味するか決めてください。これらの用語が曖昧だと、重複、混乱した履歴、実際の作業に合わないレビュー・フローが生まれます。
UIはシンプル(一覧、ビューワ、いくつかのボタン)に見えますが、実際の重みはデータモデルが担います。コアオブジェクトが正しければ、監査履歴、速いプレビュー、信頼できる承認がずっと簡単になります。
まず「ドキュメントレコード」と「ファイルコンテンツ」を分離してください。レコードはユーザーが話題にするもので(ACMEの請求書、タクシーの領収書)、コンテンツはバイト列(PDF、JPG)で、差し替えや再処理、移動が可能でもアプリ内での意味は変わらないものです。
実用的なモデル化対象のセット:
変わらないIDが何に付くかを決めてください。便利なルールは:Document IDは永続的に生きる、FilesやPreviewsは再生成可能。Versionsも安定したIDが必要です。人は「昨日はどう見えたか」を参照するため、監査トレイルが必要だからです。
関係性を明示的にモデル化してください。Documentは多くのVersionsを持ち、各Versionは複数のPreviewsを持てます。これにより一覧画面は軽量なプレビューデータを読み込み、詳細画面は必要時にフルファイルを読み込むようにできます。
例:ユーザーがしわくちゃの領収書写真をアップロードしたら、Documentを作り、元のFileを保存し、サムネイルPreviewを生成してVersion 1を作成します。後でクリアなスキャンを上げたら、それはVersion 2になり、コメントや承認、検索はDocumentに紐づいたまま維持されます。
ドキュメントは時間とともに変化しても「別アイテムに変わる」べきではありません。そのために身元(Document)と内容(VersionとFiles)を分離します。
まず、決して変わらない安定した document_id を用意してください。ユーザーが同じPDFを再アップロードしたり、ぼやけた写真を差し替えたり、修正スキャンを上げても、それは同じDocumentレコードであるべきです。コメント、割り当て、監査ログは一つの永続IDに綺麗に結び付きます。
意味のある変更ごとに新しい version 行を作成します。各バージョンは誰がいつ作ったかを記録し、ストレージポインタ(file key、checksum、size、page count)や、そのファイルに結びつく派生成果物(OCRテキスト、プレビュー画像)を保持してください。インプレース編集は見た目は簡単ですが、トレーサビリティを壊し、バグの原因になります。
読み取りを速くするために、Documentに current_version_id を持たせてください。ほとんどの画面は「最新」だけを必要とするので、毎回バージョンをソートする必要がありません。履歴が必要なときは別途バージョンを読み込み、綺麗なタイムラインで表示します。
ロールバックはポインタを切り替えるだけです。何かを削除するのではなく current_version_id を古いバージョンに戻す。これは速く、安全で、監査トレイルも残ります。
履歴を分かりやすく保つために、各バージョンが存在する理由を記録してください。小さく一貫した reason フィールド(オプションでノート)を持たせると、謎の更新で満たされたタイムラインを防げます。よくある理由は再アップロード置き換え、スキャンのクリーンアップ、OCR修正、編集による赤字化、承認編集などです。
例:経理チームが領収書写真をアップロードし、クリアなスキャンに差し替え、さらにOCRを修正して合計金額が読みやすくなった。各ステップが新しいバージョンだが、ドキュメントはインボックス内で一つのアイテムのまま。もしOCR修正が誤りなら、current_version_id を切り替えるだけでワンクリックでロールバックできます。
ドキュメント中心ワークフローでは、プレビューがユーザーの主なインタラクションになることが多いです。プレビューが遅いか不安定だと、アプリ全体の評価が落ちます。
プレビュー生成はアップロード画面が待つ処理にせず、別のジョブとして扱ってください。元ファイルはまず保存し、ユーザーに操作を返し、バックグラウンドでプレビューを生成します。UIはレスポンシブを保ち、再試行も安全になります。
複数サイズのプレビューを保存してください。一つのサイズでは十分でないことが多いです:一覧用の小さなサムネイル、分割ビュー用の中サイズ、詳細レビュー用のフルページ画像(PDFならページごと)を用意します。
プレビュー状態を明示的に追跡して、UIが何を表示すべきか常に分かるようにします:pending、ready、failed、needs_retry。UIにはユーザーフレンドリーなラベルを使いつつ、データ内の状態は明確に保ちます。
レンダリングを速くするには、プレビュー記録に派生値をキャッシュしておき、その都度再計算しないでください。よくあるフィールドはページ数、プレビュー幅・高さ、回転(0/90/180/270)、サムネイルに適した「ベストページ」などです。
遅くて扱いにくいファイルを想定した設計をしてください。200ページのスキャンPDFやしわだらけの領収書写真は処理に時間がかかることがあります。プログレッシブローディングを使い、最初に準備できたページをすぐ表示し、残りを順次埋めていきます。
例:ユーザーが30枚の領収書写真をアップロードしたら、一覧はサムネイルを「保留(pending)」として表示し、各カードはプレビュー完了時に「準備完了(ready)」に切り替わります。破損した画像で数点失敗しても、バッチ全体をブロックせずに明確な再試行アクションを提示します。
メタデータは単なるファイルの山を検索・並べ替え・レビュー・承認できるものに変えます。人が素早く答えたい簡単な質問(これは何か、誰からか、有効か、次に何をするか)に答えられるようにします。
メタデータをきれいに保つ実用的な方法は、出所ごとに分けることです:
これらの区分があれば後で議論になりません。合計金額が間違っている場合、それがOCR由来か人の編集かを確認できます。
領収書や請求書では、少数のフィールドを一貫して使うと効果的です(同じ名前、同じフォーマット)。一般的なアンカーフィールドは vendor、date、total、currency、document_number です。最初はオプショナルにしておいてください。部分的なスキャンやぼやけた写真がよくあるため、あるフィールドが欠けていることで進行を止めると全体のワークフローが遅くなります。
未知の値を第一級で扱ってください。null/unknownのような明示的な状態と、必要なら理由(ページ欠落、読取不能、該当なし)を持たせます。これにより、ドキュメントは進められつつ、レビュアーに何が注意点かを示せます。
抽出フィールドには出所と信頼度を保存してください。出所は user、OCR、import、API など、信頼度は 0-1 のスコアや high/medium/low の小さなセットが使えます。OCRが"$18.70"を低信頼で読み取った場合、UIはそれを強調して簡易確認を促せます。
複数ページのドキュメントでは、どの情報がドキュメント全体に属するか、ページ単位のものかを決める必要があります。合計やベンダーは通常ドキュメント全体の属性です。ページごとの注記、赤字、回転、ページ単位の分類はページレベルに保持することが多いです。
ステータスは一つの質問に答えます:「このドキュメントはプロセスのどこにいるか?」小さくて退屈なものにしてください。新しいステータスをその都度追加すると、誰も信頼しないフィルタの山になります。
実務に合う実用的なビジネス状態の例:
「処理中」はビジネスステータスに入れないでください。OCR実行やプレビュー生成はシステムが行っていることであり、人が次に何をすべきかを示すものではありません。これらは別の処理状態として保存します。
割り当て(assignee_id、team_id、due_date)はステータスと分けてください。ドキュメントは承認済みでもフォローアップのために割り当てられていることがあり得ますし、要レビューの状態でもまだ担当者が割り当てられていないことがあります。
ステータス履歴(現在値だけでなく)を記録してください。単純なログ(from_status、to_status、changed_at、changed_by、reason)があれば「誰がこの領収書を却下したのか?なぜ?」に答えられます。
最後に、各ステータスでどのアクションが許可されるかを決めてください。ルールはシンプルに:Imported は Needs review に移行できる;Approved は読み取り専用(新しいバージョンが作られた場合を除く);Rejected は再開可能だが以前の理由を残す、など。
ほとんどの時間は一覧をスキャンし、一つを開き、いくつかのフィールドを直して先へ進むことに費やされます。良いUIはそれらのステップを迅速かつ予測可能にします。
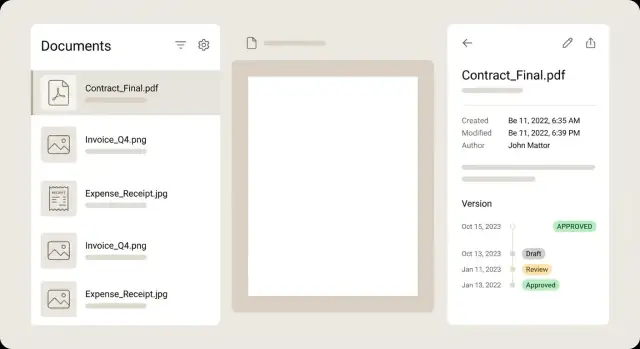
ドキュメント一覧では、各行を要約カードとして扱い、ユーザーがすべてを開かずに判断できるようにします。強い行表示は小さなサムネイル、明確なタイトル、いくつかのキー項目(merchant、date、total)、ステータスバッジ、注意が必要な場合のさりげない警告を含みます。
詳細ビューは落ち着いてスキャンしやすくしてください。一般的なレイアウトは左にプレビュー、右にメタデータで、各フィールド横に編集コントロールを置くものです。ユーザーはズーム、回転、ページめくりをしてもフォームの位置を失わないべきです。OCRから抽出されたフィールドなら小さな信頼度ヒントを表示し、フィールドにフォーカスしたときにプレビュー上の該当箇所をハイライトできると理想的です。
バージョンはドロップダウンではなくタイムラインで見せると扱いやすいです。誰がいつ何を変えたかを示し、過去の任意バージョンを読み取り専用で開けるようにします。差分表示を提供する場合は、ピクセル単位のPDF比較ではなく、メタデータの違い(金額が変わった、ベンダーが修正された)に焦点を当ててください。
レビュー・モードはスピード重視にしてください。キーボード中心のトリアージフローが有効です:クイックな承認/却下アクション、一般的なフィールドを素早く直すUI、却下時の短いコメント欄など。
空の状態も重要です。ドキュメントはしばしば処理途中です。空白のボックスの代わりに「プレビューを生成中です」「OCRを実行中です」「このファイルタイプはまだプレビューがありません」のように何が起きているかを説明してください。
単純なワークフローは「アップロード、確認、承認」の流れです。内部ではファイル自体(バージョンとプレビュー)を業務的な意味(メタデータとステータス)から切り離すと最もうまく働きます。
ユーザーがPDF、写真、領収書スキャンをアップロードすると、インボックス一覧に即座に表示されます。処理完了を待たないでください。ファイル名、アップロード時刻、"Processing" のような明確なバッジを表示します。既にソースがわかっている(メール取り込み、モバイルカメラ、ドラッグ&ドロップ)ならそれも示してください。
アップロード時に Document レコード(長期のエンティティ)と Version レコード(この特定ファイル)を作ります。current_version_id を新しいバージョンにセットし、preview_state = pending、extraction_state = pending を設定してUIが何が準備できているか正直に伝えられるようにします。
詳細ビューはすぐ開けますが、代わりにプレースホルダービューアと「プレビュー準備中」の明確なメッセージを表示してください。
バックグラウンドジョブがサムネイルや表示可能なプレビュー(PDFのページ画像、写真のリサイズ)を作り、別ジョブがメタデータ(merchant、date、total、currency、document type)を抽出します。それぞれのジョブが終わるたびにその状態とタイムスタンプだけを更新し、失敗の再試行を局所的に行えるようにします。
UIはコンパクトに:プレビュー状態、データ状態を表示し、信頼度の低いフィールドをハイライトします。
プレビューが準備できたら、レビュアーはフィールドを修正し、ノートを追加し、ドキュメントを Imported -> Needs review -> Approved(または Rejected) と進めます。誰がいつ何を変えたかをログに記録します。
レビュアーが修正ファイルをアップロードした場合、それは新しい Version になり、ドキュメントは自動的に Needs review に戻ります。
エクスポート、会計同期、内部レポートは current_version_id と承認されたメタデータのスナップショットを参照してください。「最新の抽出」をそのまま読むと、半処理状態の再アップロードで数値が変わるリスクがあります。
ドキュメント中心ワークフローが失敗する理由は地味です:初期の手抜きが、ユーザーが重複をアップロードしたり修正したりしたときに日々の問題になります。
ファイル名をドキュメントのIDとして扱うのは典型的な誤りです。名前は変わるし、ユーザーは再アップロードするし、カメラは IMG_0001 のような重複を生みます。各ドキュメントに安定したIDを与え、ファイル名はラベルとして扱ってください。
元ファイルを上書きするのも問題を引き起こします。見た目は簡単ですが監査トレイルが失われ、「何が承認されたか」「何が編集されたか」「何が送られたか」が答えられなくなります。バイナリを不変に保ち、新しいバージョンレコードを追加してください。
ステータスの混同は微妙なバグを生みます。「OCR実行中」は「要レビュー」と同じではありません。処理状態はシステムの作業を表し、ビジネスステータスは人が次にすべきことを表します。混同するとドキュメントが誤ったバケツに残ります。
UIの決定も摩擦を生むことがあります。プレビュー生成まで画面をブロックすると、アップロード自体は成功しているのにアプリが遅いと感じられます。ドキュメントを即座に表示し、準備できたらサムネイルで差し替えてください。
最後に、メタデータは出所を保存しないと信頼できなくなります。合計がOCR由来ならそれを示してください。タイムスタンプも保持しましょう。
チェックリスト:
例:領収書アプリでユーザーがクリアな写真を再アップロードしたら、バージョンを作成し古い画像を保持し、OCRを再処理中にして Needs review のままにします。
ドキュメント中心ワークフローは、人が見たものを信頼でき、問題が起きたときに復旧できるようになって初めて「完成」です。ローンチ前に、汚い実データ(ぼやけた領収書、回転したPDF、重複アップロード)でテストしてください。
見落としがちな五つのチェック:
現実テスト:誰かに似た領収書を3つレビューしてもらい、わざと一つを間違って変更してもらう。現在のバージョンを見分け、ステータスを理解し、1分以内に修正できればかなり完成に近いです。
月次の領収書精算はドキュメント中心作業のわかりやすい例です。従業員が領収書をアップロードし、2人のレビュアー(マネージャー、経理)が確認します。領収書がプロダクトなので、アプリはバージョン管理、プレビュー、メタデータ、明確なステータスにかかっています。
Jamie がタクシーの領収書写真をアップロードすると、システムは Document #1842 を作り、Version v1(元ファイル)、サムネイルとプレビュー、merchant、date、currency、total、OCR信頼度といったメタデータを紐づけます。ドキュメントは Imported からプレビューと抽出が完了したら Needs review に移ります。
後で Jamie が同じ領収書を誤って再アップロードした場合、重複チェック(ファイルハッシュ+類似の merchant/date/total)で「#1842 に似ています。添付する/破棄する」を提示できます。添付する場合は同じ Document に別の File として保存し、レビューのスレッドとステータスを一つに保ちます。
レビュー中、マネージャーはプレビューと重要フィールド、警告を確認します。OCRが合計を $18.00 と推定したが画像では $13.00 に見える場合、Jamie が合計を修正します。履歴は上書きしないでください。Version v2 を作り、v1 はそのままにして「Total corrected by Jamie」とログを残します。
Koder.ai (koder.ai) を使えば、チャットベースの設計からアプリの最初のバージョンを生成する手助けができますが、同じルールが当てはまります:まずオブジェクトと状態を定義し、その後で画面を作ること。
実践的な次のステップ:
ドキュメントが主役で、添付物ではなくユーザーが開いて信頼し、変更点を確認して次のアクションを決める対象であることを指します。ユーザーは文書を開き、何が変わったかを理解し、次に何をすべきかを判断できる必要があります。
インボックス/一覧、速いプレビュー付きのドキュメント詳細、承認/却下/差し戻しなどの簡単なレビュー操作エリア、そしてエクスポートや共有の手段から始めてください。これら四つの画面で「探す・開く・判断する・引き渡す」の一般的なループをカバーできます。
永続的に変わらない安定したDocumentレコードを持ち、実際のファイルバイトは別のFileオブジェクトとして保存します。さらに、特定のファイルとその派生物を結びつけるスナップショットとしてVersionを使います。この分離により、ファイルが置き換えられてもコメントや割り当て、履歴が保たれます。
意味のある変更ごとに新しいバージョンを作成し、インプレース編集は避けてください。ドキュメントに current_version_id を持たせて最新を素早く参照できるようにし、古いバージョンは監査とロールバック用に残します。これにより「何が承認されたか」を明確に保てます。
元ファイルを保存した後で非同期にプレビューを生成することで、アップロードを即時に完了させられます。プレビュー状態(pending/ready/failed)を追跡し、複数サイズを保存して一覧は軽量に、詳細は高解像度で表示できるようにします。
メタデータを三つのバケットに分けて保存します:システム(ファイル名・サイズ・タイプ)、抽出(OCRフィールドと信頼度)、ユーザー入力の修正。出所を記録しておけば、ある値がOCR由来か人間の修正かを後で判別できます。
人が次に何をすべきかを示す小さく扱いやすいビジネスステータス(例:Imported、Needs review、Approved、Rejected、Archived)を使い、処理中(OCRやプレビュー生成など)は別の処理状態として管理してください。人の作業と機械処理を混同するとドキュメントが誤ったバケットに残ります。
アップロード時に不変のファイルチェックサムを保存し、既知のフィールド(ベンダー/日付/金額)と照合する二次チェックを行います。重複の疑いがある場合は「#1842と重複の可能性があります。添付する/破棄する」を明確に提示して、レビュースレッドを分けないようにします。
誰がいつ何をしたかを記録するステータス履歴(from_status, to_status, changed_at, changed_by, reason)と、タイムラインで読めるバージョンを保持します。ロールバックは古いバージョンへのポインタ変更にして削除しないことが重要です。
まずオブジェクトと状態を定義してからUIを作ること。Koder.ai を使う場合でも、Document/Version/File、プレビューや抽出の状態、ステータス規則を明確に伝えておけば、生成される画面が実際のワークフローにきれいに合います。