2025年4月15日·2 分
採用パイプラインと面接のための Web アプリを作る方法
HR チームが採用ステージ、面接、フィードバック、権限、統合、レポートを管理するウェブアプリの計画、設計、構築方法を学びます。
HR チームが採用ステージ、面接、フィードバック、権限、統合、レポートを管理するウェブアプリの計画、設計、構築方法を学びます。
画面設計や技術選定を始める前に、誰 のために作るのか、どの痛み を取り除くのかを明確にしてください。HR チーム、リクルーター、採用マネージャー、面接官は同じ採用プロセスでも見方やニーズが大きく異なります。よくある「万人向け」のアプリは、結局誰も満足させられないことが多いです。
現在の摩擦を短く書き出します:
「採用マネージャーが候補者の状況を見られず、面接の調整に時間がかかりすぎる」といった具体的な文を目指してください。
“パイプライン” は単純なステージ一覧(Applied → Screen → Onsite → Offer)を指すこともあれば、役割や拠点によって変わる詳細なワークフローを意味することもあります。同様に“面接管理”はスケジューリングのみを指す場合もあれば、準備(誰が面接するか、何を評価するか)、フィードバック収集、最終決定までを含む場合もあります。
次のような実例をいくつか取り込んで定義を固めてください:
既存の応募者トラッキングシステムで設定可能な範囲と自社で構築する場合を比較します。ユニークなワークフロー、より深い統合、特定の企業規模向けによりシンプルな体験が必要な場合はビルドが正当化されます。
ビルドするなら、アプリの差別化ポイントを明文化してください(例:「スケジューリングの往復を減らす」「マネージャー中心の可視化」)。
日常業務に結びつく 3~5 の指標を選びます。例:
これらの目標は、権限設計、スケジューリング、分析など後の意思決定を導きます(詳細は /blog/create-reporting-and-analytics-hr-will-trust)。
画面設計や機能選定の前に、実際に組織内で採用がどう進むかを明確にしてください。よく整理されたワークフローは「どこで不明点が生じるか」「ステージ名の不整合」「候補者の停滞」を防ぎます。
多くのチームは次のコアパスに従います:ソーシング → スクリーニング → 面接 → オファー。各ステップで「完了」とは何か(例:「スクリーニング完了」は電話スクリーニングが記録され、合否決定が残されている状態)を定義してください。
ステージ名は行動を示す具体的な名称にします。「Interview」は曖昧なので「Hiring Manager Interview」「Panel Interview」のように分けると報告しやすくなります。
部署ごとに必要なステップは異なります。営業ではロールプレイ、エンジニアは提出課題、役員職は追加承認が必要かもしれません。
一つの巨大なパイプラインを作る代わりに:
これによりレポーティングの一貫性を保ちながら、現実のワークフローにもフィットさせられます。
各ステージごとに次を記録します:
候補者が滞留しやすい箇所(よくあるのは「スクリーニング→スケジュール」や「面接→決定」)に注目します。ここは後で自動化を入れる絶好のポイントです。
アプリが誰かに促すべきタイミングを列挙します:
リマインダーはステージのオーナーに結びつけ、記憶やメール探索に頼らない運用にします。
HR ウェブアプリはすぐに応募者トラッキングシステム級に膨らみます。早く価値を出す最速ルートは、厳密な MVP に合意し、次のリリース計画を示して利害関係者に何が来るか(そして v1 に故意に含めないもの)を明確にすることです。
MVP はチームが実際に候補者を「applied」から「hired」へ移せることを目標にします。実用的なベースラインは:
ステージ移動や調整の効率化に寄与しない機能は MVP ではない可能性が高いです。
「候補者スループット/時間削減」を一軸に、「開発複雑さ」をもう一軸にした単純なマトリクスを作ります。v1 の 必須 は信頼できるパイプラインステータス、実際に機能するスケジューリング、提出しやすいフィードバックです。
自動化ルール、高度な分析、AI 要約などの あると良い機能 は後回しにします。特にコンプライアンスやデータリスクを増やすものは慎重に扱います。
HR は同じやり方で働かないことが多いので、初日から管理者が設定できる項目を定義します:
設定は限定して UI をシンプルかつ保守しやすく保ちます。
短いユーザーストーリーを用意します:
これらは v1 の受け入れ基準と v2/v3 の階層化されたロードマップになります。
採用アプリはデータモデル次第で生き残り方が変わります。関係性が明確なら、新しいステージ、スケジュール、レポートを追加しても全体を書き換える必要が減ります。
小さく欠かせない「真実の源」テーブル/コレクションを計画します:
実務上、Application がステージ変更、面接、決定、オファーなどのワークフローデータの中心になります。
候補者は複数のポジションに応募することがあり、ポジションは多数の候補者を持ちます。次のようにモデル化します:
これにより候補者データの重複を避け、ポジション固有のステータスや給与期待値、決定履歴をトラッキングできます。
履歴書や添付ファイルはメタデータを DB に保持し、バイナリはオブジェクトストレージに保存します(ファイル名、タイプ、サイズ、uploaded_by、タイムスタンプ)。
メモやメッセージはファーストクラスのレコードにします:
こうした構造にすると検索やレポーティングが楽になります。
早期に AuditEvent テーブルを追加して、ステージ、オファー、評価の変更を記録します:
これにより「なぜこの候補者が Rejected に移されたのか?」といった問いに説明でき、デバッグや説明責任の観点で有益です。
権限は HR アプリが信頼されるか失うかの分岐点です。明確なアクセスモデルは給与情報の過剰共有を防ぎ、コラボレーションをスムーズにします。
まず実際の意思決定フローに合う小さなロールセットで始めます:
ロールは一貫して保ち、多数のカスタムロールを作る代わりに「オーバーライド」で細かい例外を扱う方が運用しやすいです。
すべての候補者データを全員が見られるわけではありません。カテゴリ/フィールドごとに権限ルールを定義します:
実践的なパターン:多くのユーザーは候補者プロフィールを閲覧できるが、敏感情報の参照・編集は特定のロールだけにします。
採用は通常セグメント化されています。次のような「スコープ」を追加してアクセスを限定できます:
これにより別リージョンのリクルーターが誤って別の地域の候補者にアクセスするのを防げます。
ステークホルダーは素早くプロフィールを見たいが、コピーで回ると管理が効かなくなります。制御された共有を提供します:
これにより候補者情報がメールスレッドで拡散するのを抑えられます。
忙しいリクルーターが一目で状況を把握し、次のアクションを迷わず実行できるかどうかが採用アプリの生命線です。画面は少数に絞り、操作は予測可能で「次に何が起こるか」が明確であるべきです。
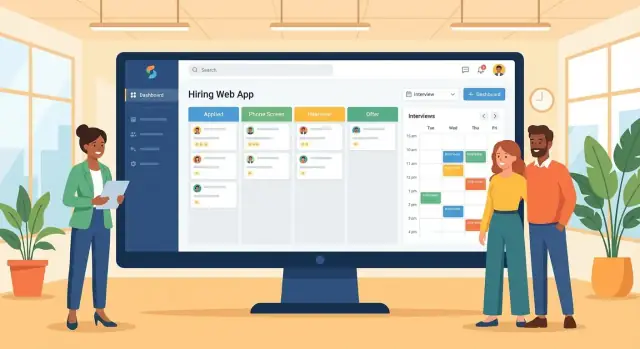
パイプラインボード(カンバン式): 各ジョブのステージを列で表示し、候補者カードは名前、現在のステージ、最終アクティビティ日、オーナー、主要タグ(例:「スケジュール要」)を表示します。ボードは判断に必要な情報のみに絞り、詳細は別画面へ。
候補者プロフィール: その人が誰で、プロセス上どこにいて、次に何をすべきかが回答できる 1 ページ。ヘッダー要約、ステージタイムライン、メモ/活動フィード、ファイル(履歴書)、“Interviews” ブロックを配置します。
ジョブページ: ジョブ詳細、採用チーム、ステージ定義、ファネルの概況。管理者がステージ名や必須フィードバックをここで調整します。
面接カレンダー: 面接官とリクルーター向けのカレンダービュー。空き状況、面接タイプ、ビデオ/場所の詳細に素早くアクセスできるようにします。
各画面は上位 3~5 のアクションを目立たせます:ステージ移動、面接をスケジュール、フィードバック要求、メッセージ送信、オーナー割当。ビューごとにメインのプライマリボタンを 1 つにし、配置を統一します。却下や撤回などの破壊的操作は確認を入れます。
大量採用の職種にはバルク Reject/Tag/Assign owner が必須です。選択カウンタ、Undo トースト、確認ダイアログ(例:「23 件の候補者を却下します」)や理由テンプレートを実装してミスを減らします。
パイプラインボードでのキーボード操作、フォーカス状態の可視化、十分なコントラスト、読みやすいラベルをサポートします。エラーメッセージは具体的に(例:「面接時間が必要です」)し、色に頼りすぎない設計にします。
面接スケジューリングは採用パイプラインが止まりやすい箇所です:往復メール、タイムゾーンの誤り、所有権の不明確さ。アプリはガイド付きワークフローで次の一手を示しつつ、現場での柔軟な上書きを許容するべきです。
まずは多くのチームをカバーするテンプレートを用意し、管理者が後から編集できるようにします:
各タイプはデフォルトの所要時間、必要面接官ロール、場所(ビデオ/対面)、候補者準備資料の要否を定義します。
実用的なフローの要素:
ラストミニットの面接官差し替え、分割パネル、確保枠の期限切れなどのエッジケースにも対応できる設計にします。
統合では競合チェックとイベント作成の 2 点に注力します:
統合がなくても recruiters が外部ミーティングリンクを貼って「scheduled」とマークできる手動モードを必ず用意してください。
面接のばらつきを減らすために、各イベントにブリーフィングパックを自動生成します。内容:
このパックを候補者プロフィールと面接イベントの両方から 1 クリックで参照できるようにします。
フィードバックは採用パイプラインが信頼を得られるか摩擦を生むかの分水嶺です。HR チームは構造化された評価を、簡単に提出できて、面接官間で一貫性があり、後で監査可能であることを求めます。
役割と面接タイプ(スクリーニング、技術、マネージャー面接、カルチャーフィット等)ごとにスコアカードを作り、短く明確な評価基準と評価スケール(例:1–4、アンカー付き)を設定します。面接官に観察した根拠を書かせる「エビデンス」欄を用意し、曖昧な意見を避けます。
スコアカードは検索可能かつレポート可能にして、HR 分析ダッシュボードに手作業でクレンジングせずとも取り込めるようにします。
面接官は下書きが必要です。以下をサポートします:
これにより誤った情報共有を防ぎ、役割ベースのアクセス制御を保てます。
遅いスコアカードは意思決定とスケジュールに遅延を生むため、自動的な催促を入れます:面接後のリマインド、決定会議前の再通知、それでも未提出なら採用マネージャーへのエスカレーション。期限はステージごとに設定可能にします。
意思決定ビューでは平均評価や基準ごとの集計、強み/リスクの要約、未提出フィードバックのアラートを示します。アンカリングを減らすために、面接官が自分の提出を完了するまで他者の評価を隠す設定や、スコアと一緒に証拠となる抜粋を表示する仕組みを検討してください。
適切に設計すれば、このモジュールが「単一の信頼できる意思決定基盤」となり、チャットやメールでのやり取りを減らします。
パイプラインが完璧でも、リクルーターが素早く連絡し、適切な候補者を見つけられず、出来事の記録が散らばっていれば採用は遅れます。こうした「小さな」ツールが実運用での採用を支えます。
日常的に繰り返される瞬間(応募確認、面接招待、フォローアップ、空き確認、却下)用の編集可能なテンプレートを用意します。テンプレートは役割/チーム単位で編集可能にし、差し込み(名前、役職、勤務地)を許容します。
同時に、送受信のすべてをログ化し、候補者プロフィール上に送受信タイムラインを保持します。これにより「連絡したか?」をメール検索に頼らずに確認できます。添付や送信者、時間もメタデータとして残します。
ステータス更新は簡単にしつつ標準化します。不採用理由は制御されたリスト(例:「給与ミスマッチ」「スキル不足」「利用不可」「辞退」)を用意し、任意メモを添えられるようにします。
これによりレポートが正確になり、チーム内の文言差異を減らせます。内部専用フィールドと外部共有フィールドは分けて扱ってください。
スキル、職位、言語、セキュリティクリアランス、ソースチャンネルなどの柔軟なタグを追加し、次のような高速検索・フィルタを提供します:
シングルジョブ/全職種で「10 秒で見つかる」を目標にします。
HR チームは依然としてスプレッドシートを使います。バックフィル用の CSV インポートと監査や共有のための CSV エクスポートを提供します。フィールドマッピング、バリデーション(重複、メール欠損)を備え、エクスポートは権限を尊重します。
これらのツールは後にバルク操作や日常業務の基盤にもなります。
採用アプリは氏名、履歴書、面接メモ、場合によっては平等性や健康情報といった非常にセンシティブなデータを扱います。プライバシーとセキュリティは機能ではなくコア要件として扱ってください。
適用される規制と後で証明する必要があることを文書化します。多くのチームでは GDPR / UK GDPR とローカルの雇用法が関連します。
明確にしておくべき点:
デフォルトで収集するフィールドを最小限にします。評価に不要な情報は求めないでください。
多様性モニタリングや配慮事項など機微データは採用メインレコードから分離し、アクセスを厳格に制限します。これにより偶発的な露出を減らし、必要性に応じたアクセスが可能になります。
最低限、データは転送時(TLS)と保存時に暗号化します。添付ファイル(履歴書、ポートフォリオ、ID 書類)はプライベートバケットに保存し、有効期限付きの署名付き URL で提供、公開アクセスは不可にします。
ダウンロードと共有を制御します:
誰が候補者プロフィールやファイルを見た・エクスポートしたかのアクセスログを残します。HR は調査や監査のためにこれが必要になります。
また、データ主体の権利に対応する運用を整えます:
良いコンプライアンス設計はアプリの信頼性を高め、監査時の防御を容易にします。
レポーティングは採用アプリが信頼を得るか、永遠に数値の確認作業に追われるかを決めます。検証しやすく、時系列で一貫性があり、各数値の定義が明確である分析を目指してください。
パイプラインの健全性とスピードに焦点を当てます:
これらは職種ごとに表示します。大量採用のサポート職とシニアエンジニアではベンチマークを同じにすべきではありません。
2 レベルのビューを提供します:
フィルタはシンプルに(期間、ジョブ、部署、勤務地、ソース)。フィルタが数値を変える場合はその旨を明示します。
多くの報告上の争いは定義の不明確さから生じます。ツールチップや「定義」ドロワーで次を明記します:
可能なら、HR が指標をクリックして基の候補者一覧にドリルダウンできるようにします(例:「Onsite > 14 日の 12 人を表示」)。
実務に合ったエクスポートを用意します:スプレッドシート用の CSV、会議用の PDF スナップショット、スケジュールされたメールレポート。エクスポートにはフィルタと定義ヘッダーを含め、文脈を失わないようにします。
もし一つの北極星ビューを作るなら、保存済みレポートテンプレート(例:「四半期採用レビュー」「多様性ファネル(有効な場合)」)を /reports ページに用意して HR が再利用できるようにします。
統合と展開の判断は採用率に直結します。これらを製品機能として扱い、明確なスコープ、安定した挙動、継続的サポート体制を用意してください。
リクルーターが普段使うシステムから始めます:
各データタイプの「ソース・オブ・トゥルース」を定義して競合を避けます。
後で統合する場合でも今設計しておきます:
HR チームを苛立たせる失敗に集中します:
ワークフロー(パイプラインボード、スケジューリング、スコアカード、権限)を早く検証したいなら、Koder.ai のようなバイブコーディングプラットフォームは有効です。チャットで採用ワークフローを説明し、画面を反復して、React ベースのフロントエンドと Go + PostgreSQL のバックエンドを内包した動く社内アプリを生成できます。準備ができたらソースコードをエクスポートして自社へ移管できます。プランニングモード、スナップショット、ロールバック機能は、HR ステークホルダーと MVP 検証を行う際に特に役立ちます。
まず 2~4 の主要ユーザーグループ(HR 管理者、リクルーター、採用マネージャー、面接官)に名前を付け、各グループごとに具体的な課題を 1 つ書きます。
その後、利害関係者と検証できる一文の問題定義を作成します。例:「採用マネージャーが候補者の状況を把握できず、面接の調整に時間がかかりすぎる。」
次を書き出します:
これにより「どこで手順が抜けるか」「ステージ名の不整合」「候補者が止まる箇所」を防げます。
次を用意します:
ステージ名は「Interview」ではなく「Hiring Manager Interview」など、行動ベースで分かりやすくして報告が一定になるようにします。
日々の業務に結びつく 3〜5 の指標を選びます(バニティ指標は避ける):
これらは権限設定やスケジューリング、分析の選択を導きます。
実際の採用ループをサポートする実用的な MVP を含めます:
コアループが確実に動くまで、高度な自動化や AI 機能は後回しにします。
Candidate と Job を別エンティティとしてモデル化し、ワークフローのアンカーとして Application を使います。
これにより候補者が複数ポジションに応募する現実(many-to-many)を扱え、ポジションごとのステータスや判断履歴を正しく紐付けられます。
まず小さく一貫した役割セットで始めます:
給与情報や内部メモ、EEO/多様性情報などの機微なフィールドはフィールドレベルで保護し、部署/職務/勤務地単位のスコープでアクセス制御をかけます。
案内フロー:
Google/Microsoft カレンダーを統合して競合チェックとイベント作成を行うが、統合がないチーム向けに手動モードも用意します。
短く役割/面接タイプ別のスコアカードを使い、明確な基準と簡潔な評価スケールを用います。
期限切れフィードバックにはリマインダーとエスカレーションを設定し、アンカリングを避けるために他者の評価を自分が提出するまで隠すオプションを検討します。
各指標をクリックすると基になる候補者リストに辿れるようにし、主要計算の定義を明示します(ステージ入場の扱い、撤回・不採用の処理、オンホールド中の時間計測など)。
CSV/PDF エクスポートや保存済みレポートテンプレートを用意して、一貫したビューを簡単に再利用できるようにします。詳細は /blog/create-reporting-and-analytics-hr-will-trust を参照してください。