07 nov 2025·8 min
Le scoperte di Geoffrey Hinton sulle reti neurali spiegate
Una guida chiara alle idee chiave di Geoffrey Hinton—dalla retropropagazione e le macchine di Boltzmann ai deep net e AlexNet—e a come hanno plasmato l'IA moderna.
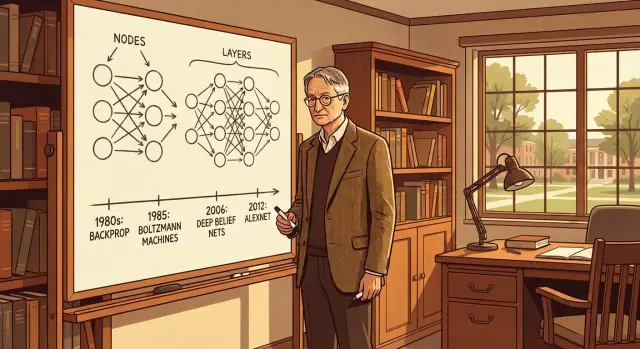
Una guida chiara alle idee chiave di Geoffrey Hinton—dalla retropropagazione e le macchine di Boltzmann ai deep net e AlexNet—e a come hanno plasmato l'IA moderna.
Questa guida è pensata per lettori curiosi e non tecnici che sentono dire che “le reti neurali hanno cambiato tutto” e vogliono una spiegazione chiara e concreta di cosa significhi davvero—senza bisogno di calcolo o programmazione.
Farai un giro in parole semplici delle idee che Geoffrey Hinton ha aiutato a portare avanti, perché erano importanti all'epoca e come si collegano agli strumenti di IA che la gente usa oggi. Pensalo come una storia su modi migliori per insegnare ai computer a riconoscere schemi—parole, immagini, suoni—imparando dagli esempi.
Hinton non ha “inventato l'IA” e nessuna singola persona ha creato il machine learning moderno. La sua importanza sta nel fatto che più volte ha contribuito a far funzionare le reti neurali nella pratica, quando molti le consideravano vicoli ciechi. Ha apportato concetti chiave, esperimenti e una cultura di ricerca che ha posto l'apprendimento di rappresentazioni (caratteristiche interne utili) come problema centrale—invece di codificare regole a mano.
Nelle sezioni seguenti spiegheremo:
In questo articolo, un breakthrough è uno spostamento che rende le reti neurali più utili: si addestrano con più affidabilità, imparano caratteristiche migliori, generalizzano più accuratamente su nuovi dati o scalano a compiti più grandi. È meno una demo appariscente e più il trasformare un'idea in un metodo affidabile.
Le reti neurali non sono nate per “sostituire i programmatori”. La promessa iniziale era più specifica: costruire macchine che potessero imparare rappresentazioni interne utili da input reali e disordinati—immagini, parole e audio—senza che gli ingegneri dovessero codificare ogni regola.
Una foto è solo milioni di valori di pixel. Una registrazione è una sequenza di misure di pressione. La sfida è trasformare quei numeri in concetti che interessano le persone: bordi, forme, fonemi, parole, oggetti, intenzioni.
Prima che le reti neurali diventassero pratiche, molti sistemi si affidavano a caratteristiche costruite a mano—misure progettate come “rilevatori di bordi” o “descrittori di texture”. Funzionava in contesti ristretti, ma spesso falliva quando cambiava la luce, l'accento o l'ambiente.
Le reti neurali puntavano a risolvere questo imparando automaticamente le caratteristiche, strato dopo strato, dai dati. Se un sistema può scoprire i giusti mattoni intermedi da solo, può generalizzare meglio e adattarsi a nuovi compiti con meno lavoro manuale.
L'idea era attraente, ma diversi ostacoli hanno impedito alle reti neurali di mantenere la promessa per molto tempo:
Anche quando le reti neurali erano fuori moda—soprattutto negli anni '90 e nei primi anni 2000—ricercatori come Geoffrey Hinton continuarono a insistere sulla representation learning. Propose idee (a partire dagli anni '80) e riprese concetti più vecchi (come i modelli basati sull'energia) finché hardware, dati e metodi non si sono allineati.
Quella perseveranza ha aiutato a mantenere vivo l'obiettivo centrale: macchine che imparano le rappresentazioni giuste, non soltanto la risposta finale.
La retropropagazione (spesso abbreviata in “backprop”) è il metodo che permette a una rete neurale di migliorare imparando dagli errori. La rete fa una previsione, si misura quanto è sbagliata e poi si aggiustano le “manopole” interne (i pesi) per fare un po' meglio la volta successiva.
Immagina una rete che cerca di etichettare una foto come “gatto” o “cane”. Indovina “gatto”, ma la risposta giusta è “cane”. La retropropagazione parte da quell'errore finale e lavora all'indietro attraverso gli strati della rete, capendo quanto ogni peso ha contribuito all'errore.
Un modo pratico per pensarci:
Quegli aggiustamenti avvengono solitamente con un algoritmo chiamato discesa del gradiente, che significa “fare piccoli passi in discesa sull'errore”.
Prima della sua adozione diffusa, addestrare reti multistrato era inaffidabile e lento. La retropropagazione ha reso possibile addestrare reti più profonde perché offriva un modo sistematico e ripetibile per sintonizzare molti strati insieme—invece di modificare solo l'ultimo strato o provare aggiustamenti a caso.
Questo cambiamento è stato cruciale per le scoperte successive: una volta che puoi addestrare più strati efficacemente, le reti possono imparare caratteristiche più ricche (ad esempio: bordi → forme → oggetti).
La retropropagazione non è la rete che “pensa” o “capisce” come una persona. È un feedback guidato dalla matematica: un modo per aggiustare i parametri in modo che corrispondano meglio agli esempi.
Inoltre, la retropropagazione non è un singolo modello—è un metodo di addestramento che si può usare su molti tipi di reti neurali.
Se vuoi andare più a fondo sulla struttura delle reti, vedi l'approfondimento sulle reti neurali spiegate.
Le macchine di Boltzmann sono stati uno dei passi chiave di Geoffrey Hinton verso l'idea che le reti neurali potessero imparare rappresentazioni interne utili, non solo dare risposte.
Una macchina di Boltzmann è una rete di unità semplici che possono essere accese/spente (o, in versioni moderne, assumere valori reali). Invece di predire direttamente un output, assegna un’energia a una configurazione completa di unità. Bassa energia significa “questa configurazione ha senso”.
Un'analogia utile è un tavolo coperto di piccole buche e valli. Se lasci cadere una biglia sulla superficie, rotolerà e si sistemerà in un punto basso. Le macchine di Boltzmann cercano di fare qualcosa di simile: dato un'informazione parziale (alcune unità visibili impostate dai dati), la rete “si agita” nelle sue unità interne finché non si stabilizza in stati a bassa energia—stati che ha imparato a considerare probabili.
Addestrare le macchine di Boltzmann classiche richiedeva campionare ripetutamente molte possibili configurazioni per stimare cosa il modello riteneva probabile rispetto ai dati. Questo campionamento può essere dolorosamente lento, soprattutto per reti grandi.
Tuttavia, l'approccio è stato influente perché:
La maggior parte dei prodotti moderni si basa su reti feedforward addestrate con retropropagazione perché sono più rapide e più facili da scalare.
L'eredità delle macchine di Boltzmann è più concettuale che pratica: l'idea che buoni modelli imparino “stati preferiti” del mondo—e che l'apprendimento si può vedere come spostare massa di probabilità verso quelle valli a bassa energia.
Le reti neurali non hanno solo migliorato l'adattamento di funzioni—they hanno imparato a inventare le caratteristiche giuste. Questo è il cuore della representation learning: invece di progettare cosa cercare, il modello impara descrizioni interne (rappresentazioni) che rendono il compito più semplice.
Una rappresentazione è il modo in cui il modello riassume l'input grezzo. Non è ancora un'etichetta come “gatto”; è la struttura utile verso quell'etichetta—schemi che catturano ciò che tende a contare. I primi strati possono rispondere a segnali semplici, mentre gli strati successivi li combinano in concetti più significativi.
Prima di questo cambiamento, molti sistemi dipendevano da feature progettate da esperti: rilevatori di bordi per immagini, indicatori audio fatti a mano per il parlato o statistiche testuali ingegnerizzate. Queste feature funzionavano, ma spesso si rompevano quando le condizioni cambiavano (illuminazione, accenti, parole).
La representation learning ha permesso ai modelli di adattare le caratteristiche ai dati stessi, migliorando l'accuratezza e rendendo i sistemi più resistenti agli input reali rumorosi.
Il filo comune è la gerarchia: schemi semplici si combinano in schemi più complessi.
Nel riconoscimento di immagini, una rete può prima imparare pattern simili a bordi (cambiamenti luce-oscurità). Poi combina i bordi in angoli e curve, poi in parti come ruote o occhi e infine in oggetti interi come “bicicletta” o “viso”.
Le scoperte di Hinton hanno reso pratica questa costruzione a strati—ed è una grande ragione per cui il deep learning ha iniziato a vincere su compiti importanti.
I deep belief networks (DBN) sono stati un passo importante verso le reti profonde come le conosciamo oggi. A grandi linee, un DBN è una pila di strati in cui ogni livello impara a rappresentare quello sotto—partendo dagli input grezzi e costruendo progressivamente concetti più astratti.
Immagina di insegnare a un sistema a riconoscere la scrittura a mano. Invece di imparare tutto insieme, un DBN prima apprende pattern semplici (come tratti e bordi), poi combinazioni di quei pattern (anelli, angoli), e infine forme superiori che assomigliano a parti delle cifre.
L'idea chiave è che ogni livello prova a modellare i pattern nel suo input senza conoscere ancora la risposta corretta. Poi, una volta che la pila ha appreso queste rappresentazioni sempre più utili, puoi mettere a punto tutta la rete per un compito specifico come la classificazione.
Reti profonde inizializzate casualmente spesso faticavano ad addestrarsi bene. I segnali di addestramento potevano indebolirsi o diventare instabili passando attraverso molti strati, e la rete poteva incastrarsi in configurazioni poco utili.
Il pre-addestramento strato per strato ha dato al modello un “avvio ragionevole”. Ogni livello cominciava con una comprensione minima della struttura dei dati, così l'intera rete non cercava alla cieca.
Il pre-addestramento non ha risolto tutto, ma ha reso la profondità praticabile in un periodo in cui i dati, la potenza di calcolo e i trucchi di addestramento erano più limitati di oggi.
I DBN hanno dimostrato che apprendere buone rappresentazioni su più strati poteva funzionare—e che la profondità non era solo teoria, ma una strada praticabile.
Le reti neurali possono essere sorprendentemente brave a “studiare per l'esame” nel modo peggiore: memorizzano i dati di addestramento invece di imparare il concetto sottostante. Questo problema si chiama overfitting e si manifesta quando un modello sembra eccellente sui dati di prova ma delude su esempi nuovi e reali.
Immagina di prepararti per un esame di guida memorizzando alla perfezione il percorso usato dall'istruttore l'ultima volta—ogni svolta, ogni buca. Se l'esame segue lo stesso percorso, andrai benissimo. Se il percorso cambia, peggiorerai perché non hai imparato a guidare in generale; hai imparato uno script specifico.
Questo è l'overfitting: alta accuratezza su esempi familiari, risultati peggiori su quelli nuovi.
Il dropout è stato reso popolare da Geoffrey Hinton e colleghi come un trucco di addestramento sorprendentemente semplice. Durante l'addestramento, la rete spegne casualmente (dropout) alcune delle sue unità a ogni passaggio sui dati.
Questo costringe il modello a non fare affidamento su un singolo percorso o su un gruppo “preferito” di caratteristiche. Deve distribuire l'informazione su molte connessioni e imparare pattern che reggono anche quando parti della rete mancano.
Un modello mentale utile: è come studiare perdendo a volte l'accesso a pagine casuali degli appunti—sei spinto a capire il concetto, non a memorizzare una formulazione particolare.
Il beneficio principale è una migliore generalizzazione: la rete diventa più affidabile su dati non visti prima. Nella pratica, il dropout ha reso più facile addestrare reti più grandi senza che cadessero nella trappola della memorizzazione, diventando uno strumento standard in molte configurazioni di deep learning.
Prima di AlexNet, il “riconoscimento di immagini” non era solo una demo interessante—era una competizione misurabile. Benchmark come ImageNet ponevano una domanda semplice: data una foto, il tuo sistema sa dire cosa c'è dentro?
La differenza era la scala: milioni di immagini e migliaia di categorie. Quella scala contava perché separava le idee che funzionavano solo in esperimenti piccoli dai metodi che reggevano quando il mondo diventava complesso.
I progressi in queste leaderboard erano solitamente incrementali. Poi arrivò AlexNet (costruito da Alex Krizhevsky, Ilya Sutskever e Geoffrey Hinton) e i risultati smisero di sembrare una salita lenta per diventare un salto netto.
AlexNet ha mostrato che una rete convoluzionale profonda poteva battere le migliori pipeline tradizionali di visione artificiale quando si combinavano tre ingredienti:
Non era soltanto «un modello più grande». Era una ricetta pratica per addestrare reti profonde efficacemente su compiti reali.
Immagina di far scorrere una piccola “finestra” su una foto—come muovere un francobollo sull'immagine. Dentro quella finestra la rete cerca un pattern semplice: un bordo, un angolo, una striscia. Lo stesso rilevatore viene riutilizzato ovunque nell'immagine, così può trovare pattern simili indipendentemente dalla posizione.
Impilando abbastanza di questi strati ottieni una gerarchia: i bordi diventano texture, le texture diventano parti (come ruote) e le parti diventano oggetti (come biciclette).
AlexNet ha fatto percepire il deep learning come qualcosa in cui valeva la pena investire. Se le reti profonde potevano dominare un benchmark pubblico difficile, probabilmente potevano migliorare anche i prodotti: ricerca, tagging automatico delle foto, funzioni della fotocamera, strumenti di accessibilità e altro.
Ha trasformato le reti neurali da “ricerca promettente” a una direzione ovvia per i team che costruiscono sistemi reali.
Il deep learning non è “comparso da un giorno all’altro”. Ha cominciato a sembrare drammatico quando pochi ingredienti finalmente si sono messi insieme—dopo anni di lavoro che mostrava idee promettenti ma difficili da scalare.
Più dati. Il web, gli smartphone e dataset etichettati di grandi dimensioni (come ImageNet) hanno permesso alle reti di imparare da milioni di esempi invece che migliaia. Con dataset piccoli, i modelli grandi tendono a memorizzare.
Più potenza di calcolo (soprattutto GPU). Addestrare una rete profonda significa ripetere la stessa matematica miliardi di volte. Le GPU hanno reso quel processo abbastanza veloce e accessibile da permettere l'iterazione. Ciò che prima richiedeva settimane poteva richiedere giorni o ore, così i ricercatori potevano provare più architetture e iperparametri.
Migliori trucchi di addestramento. Miglioramenti pratici hanno ridotto la casualità del “si addestra... o non si addestra”:
Nessuno di questi ha cambiato l'idea centrale delle reti neurali; hanno cambiato l'affidabilità con cui riuscivi a farle funzionare.
Una volta che calcolo e dati hanno raggiunto una soglia, i miglioramenti hanno iniziato ad accumularsi. Risultati migliori hanno attirato più investimenti, che hanno finanziato dataset più grandi e hardware più veloce, che hanno permesso risultati ancora migliori. Dall'esterno sembra un salto; dall'interno è compounding.
Scala significa costi reali: più consumo energetico, addestramenti più costosi e più sforzo per distribuire i modelli in modo efficiente. Aumenta anche il divario tra ciò che un piccolo team può prototipare e ciò che solo laboratori ben finanziati possono addestrare da zero.
Le idee chiave di Hinton—imparare rappresentazioni utili dai dati, addestrare reti profonde con affidabilità e prevenire l'overfitting—non sono “funzionalità” che puoi toccare in un'app. Sono il motivo per cui molte funzionalità quotidiane appaiono più veloci, accurate e meno frustranti.
I sistemi moderni di ricerca non si limitano ad abbinare parole chiave. Imparano rappresentazioni di query e contenuti così che “migliori cuffie con cancellazione del rumore” possano far emergere pagine che non ripetono esattamente quella frase. La stessa representation learning aiuta i feed di raccomandazione a capire che due elementi sono “simili” anche quando le descrizioni differiscono.
La traduzione automatica è migliorata drasticamente quando i modelli hanno imparato pattern stratificati (da caratteri a parole a significato). Anche se il tipo di modello è evoluto, il playbook di addestramento—grandi dataset, ottimizzazione attenta e regolarizzazione nata dal deep learning—continua a guidare come i team costruiscono funzionalità linguistiche affidabili.
Assistenti vocali e dettatura si basano su reti neurali che mappano audio disordinato in testo pulito. La retropropagazione è il motore che regola questi modelli, mentre tecniche come il dropout aiutano a evitare che memorizzino i difetti di uno specifico parlante o microfono.
Le app per le foto possono riconoscere volti, raggruppare scene simili e permettere di cercare “spiaggia” senza etichettatura manuale. Questo è representation learning in azione: il sistema impara caratteristiche visive (bordi → texture → oggetti) che rendono possibile il tagging e il recupero su larga scala.
Anche se non stai addestrando modelli da zero, questi principi compaiono nel lavoro quotidiano: parti da rappresentazioni solide (spesso tramite modelli pretrained), stabilizzi addestramento e valutazione e usa la regolarizzazione quando i sistemi iniziano a “memorizzare il benchmark”.
Questo è anche il motivo per cui gli strumenti moderni di “vibe-coding” possono sembrare così capaci. Piattaforme come Koder.ai sfruttano LLM di generazione corrente e workflow agent per aiutare i team a trasformare specifiche in linguaggio naturale in app funzionanti—spesso più velocemente dei processi tradizionali—pur permettendo di esportare il codice sorgente e distribuire come in un normale flusso di ingegneria.
Per un'intuizione più alta sull'addestramento, vedi l'approfondimento sulla retropropagazione.
Grandi scoperte spesso diventano storie semplici. Questo le rende facili da ricordare—ma crea anche miti che nascondono cosa è successo davvero e cosa conta ancora oggi.
Hinton è una figura centrale, ma le reti neurali moderne sono il frutto di decenni di lavoro di molti gruppi: ricercatori che hanno sviluppato metodi di ottimizzazione, persone che hanno costruito dataset, ingegneri che hanno reso pratiche le GPU e team che hanno dimostrato le idee su scala.
Anche all'interno del lavoro di Hinton, i suoi studenti e collaboratori hanno avuto ruoli fondamentali. La vera storia è una catena di contributi che si sono finalmente allineati.
Le reti neurali sono studiate fin dalla metà del XX secolo, con periodi di entusiasmo e delusioni. Ciò che è cambiato non è l'esistenza dell'idea, ma la capacità di addestrare modelli più grandi in modo affidabile e dimostrare vittorie chiare su problemi reali.
L'era del “deep learning” è più una rinascita che un'invenzione improvvisa.
Modelli più profondi possono aiutare, ma non sono magia. Tempo di addestramento, costi, qualità dei dati e rendimenti decrescenti sono vincoli reali. A volte modelli più piccoli battono quelli grandi perché sono più facili da sintonizzare, meno sensibili al rumore o più adatti al compito.
La retropropagazione è un modo pratico per aggiustare i parametri usando feedback etichettato. Gli esseri umani imparano con molti meno esempi, usano conoscenze pregresse ricche e non si basano sugli stessi segnali d'errore espliciti.
Le reti neurali possono essere ispirate dalla biologia senza essere repliche accurate del cervello.
La storia di Hinton non è solo un elenco di invenzioni. È un modello: conserva un'idea semplice di apprendimento, testala senza sosta e aggiorna gli ingredienti circostanti (dati, calcolo e trucchi di addestramento) finché non funziona su scala.
Le abitudini più trasferibili sono pratiche:
È facile leggere il titolo come “i modelli più grandi vincono”. È una visione incompleta.
Inseguire la dimensione senza obiettivi chiari porta spesso a:
Una strategia migliore è: parti in piccolo, dimostra valore, poi scala—e scala solo la parte che limita chiaramente le prestazioni.
Se vuoi trasformare queste lezioni in pratica quotidiana, questi approfondimenti sono utili:
Dalla regola di apprendimento base della retropropagazione, alle rappresentazioni che catturano il significato, ai trucchi pratici come il dropout, fino a una demo di rottura come AlexNet—l'arco è coerente: impara caratteristiche utili dai dati, rendi l'addestramento stabile e verifica i progressi con risultati reali.
Questo è il playbook da tenere a mente.
Geoffrey Hinton è importante perché, più volte, ha contribuito a far sì che le reti neurali funzionassero nella pratica proprio quando molti ricercatori le consideravano vie senza uscita.
Piuttosto che “inventare l’AI”, il suo impatto deriva dal promuovere la representation learning, migliorare i metodi di addestramento e contribuire a una cultura di ricerca che punta a imparare caratteristiche dai dati invece di codificare regole a mano.
In questa guida, per “breakthrough” si intende che le reti neurali sono diventate più affidabili e utili: si addestrano con più stabilità, imparano rappresentazioni interne migliori, generalizzano meglio su dati nuovi o scalano a compiti più difficili.
Non si tratta tanto di una dimostrazione appariscente quanto di trasformare un’idea in un metodo ripetibile di cui i team possono fidarsi.
Le reti neurali hanno lo scopo di trasformare input grezzi e rumorosi (pixel, forme d’onda audio, token testuali) in rappresentazioni utili—caratteristiche interne che catturano ciò che conta.
Invece di far progettare ogni caratteristica da un ingegnere, il modello impara strati di caratteristiche dagli esempi, il che tende a essere più robusto quando cambiano le condizioni (illuminazione, accenti, formulazioni).
La retropropagazione è un metodo di addestramento che migliora una rete imparando dagli errori:
Funziona insieme ad algoritmi come la discesa del gradiente, che fa piccoli passi per diminuire l’errore nel tempo.
La retropropagazione ha reso possibile sintonizzare molti strati in modo sistematico.
Questo è importante perché reti più profonde possono costruire gerarchie di caratteristiche (per esempio: bordi → forme → oggetti). Senza un modo affidabile per addestrare più strati, la profondità spesso non dava benefici reali.
Le macchine di Boltzmann assegnano un’energia (un punteggio) a configurazioni intere di unità; bassa energia significa “questa configurazione ha senso”.
Sono state influenti perché:
Oggi sono meno comuni nei prodotti perché l’addestramento classico scala lentamente.
La representation learning significa che il modello impara le proprie caratteristiche interne che rendono il compito più semplice, invece di puntare su feature progettate dall’uomo.
Nella pratica, questo migliora la robustezza: le caratteristiche apprese si adattano alle variazioni reali dei dati (rumore, diverse fotocamere, voci diverse) meglio delle pipeline rigide progettate a mano.
I deep belief network (DBN) hanno reso la profondità più praticabile usando un pre-addestramento strato per strato.
Ogni livello impara prima la struttura del proprio input (spesso senza etichette), dando alla rete completa un “avvio caldo”. Dopo di che, l’intera pila viene messa a punto per un compito specifico come la classificazione.
Dropout combatte l'overfitting spegnendo casualmente alcune unità durante l'addestramento.
Questo impedisce alla rete di dipendere troppo da un singolo percorso e la costringe a imparare caratteristiche che funzionano anche quando parti del modello mancano—il risultato è spesso una migliore generalizzazione su dati reali e nuovi.
AlexNet ha mostrato una ricetta pratica che funzionava: reti convoluzionali profonde + GPU + molti dati etichettati (ImageNet).
Non era solo “un modello più grande”: ha dimostrato in modo convincente che il deep learning poteva battere le pipeline tradizionali su un benchmark pubblico difficile, scatenando investimenti industriali su larga scala.