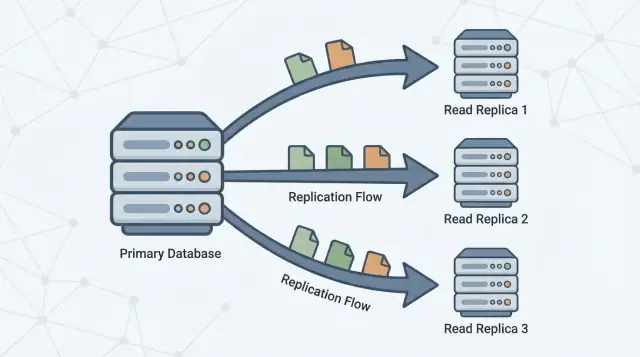
Cos’è (e cosa non è) una replica di lettura
Una replica di lettura è una copia del tuo database principale (spesso chiamato primario) che si mantiene aggiornata ricevendo continuamente le modifiche da esso. La tua applicazione può inviare query di sola lettura (come SELECT) alla replica, mentre il primario continua a gestire tutte le scritture (come INSERT, UPDATE e DELETE).
La promessa di base
La promessa è semplice: più capacità di lettura senza mettere più pressione sul primario.
Se la tua app ha molto traffico di “fetch” — homepage, pagine prodotto, profili utente, dashboard — spostare alcune di quelle letture su una o più repliche può liberare il primario per concentrarsi sul lavoro di scrittura e sulle letture critiche. In molti casi questo si fa con cambiamenti minimi nell’applicazione: tieni un database come fonte di verità e aggiungi repliche come posti aggiuntivi dove interrogare i dati.
Cosa non è una replica di lettura
Le repliche sono utili, ma non sono una bacchetta magica. Esse non:\n
- Aumentano la capacità di scrittura. Tutte le scritture arrivano ancora al primario.\n- Risolvono query lente. Se una query è inefficiente (indici mancanti, scan di tabelle grandi, join sbagliati), probabilmente sarà lenta anche sulle repliche—solo che avverrà altrove.\n- Sostituiscono un buon schema e design dei dati. Le repliche non sistemano hot spot, righe sovradimensionate o una tabella “tutto in uno”.\n- Eliminano la necessità di monitoraggio. Le repliche aggiungono parti mobili: lag, limiti di connessione e comportamenti di failover.
Impostare le aspettative per il resto della guida
Considera le repliche come uno strumento di scalabilità delle letture con compromessi. Il resto di questo articolo spiega quando aiutano davvero, i modi comuni in cui possono fallire e come concetti come replication lag e consistenza eventuale influenzano ciò che gli utenti vedono quando leggi da una copia invece che dal primario.
Perché esistono le repliche di lettura
Un singolo server database primario spesso sembra “abbastanza grande” all’inizio. Gestisce le scritture (inserimenti, aggiornamenti, cancellazioni) e risponde anche a ogni richiesta di lettura (SELECT) dalla tua app, dashboard e strumenti interni.
Con la crescita dell’uso, le letture di solito aumentano più velocemente delle scritture: ogni visualizzazione di pagina può innescare diverse query, le schermate di ricerca possono amplificarsi in molte lookup e le query di tipo analytics possono scansionare molte righe. Anche se il volume di scrittura è moderato, il primario può comunque diventare un collo di bottiglia perché deve svolgere due lavori contemporaneamente: accettare cambiamenti in modo sicuro e rapido, e servire un crescente flusso di letture con bassa latenza.
Separare letture e scritture
Le repliche esistono per dividere quel carico. Il primario rimane focalizzato sul processare le scritture e mantenere la “fonte di verità”, mentre una o più repliche gestiscono query di sola lettura. Quando la tua applicazione può instradare alcune query verso le repliche, riduci CPU, memoria e pressione I/O sul primario. Questo tipicamente migliora la reattività complessiva e lascia più spazio per picchi di scrittura.
Replicazione in una frase
La replicazione è il meccanismo che mantiene le repliche aggiornate copiando le modifiche dal primario ad altri server. Il primario registra le modifiche e le repliche le applicano in modo da poter rispondere alle query utilizzando dati quasi uguali.
Questo schema è comune in molti sistemi database e servizi gestiti (per esempio PostgreSQL, MySQL e varianti cloud). L’implementazione esatta differisce, ma l’obiettivo è lo stesso: aumentare la capacità di lettura senza costringere il primario a scalare verticalmente all’infinito.
Come funziona la replicazione (modello mentale semplice)
Pensa al database primario come alla “fonte di verità”. Accetta ogni scrittura—creazione di ordini, aggiornamento profili, registrazione pagamenti—e assegna a quei cambiamenti un ordine definito.
Una o più repliche quindi seguono il primario, copiando quelle modifiche in modo da poter rispondere a query di lettura (come “mostrami la mia cronologia ordini”) senza sovraccaricare ulteriormente il primario.
Il flusso di base
- Il primario accetta scritture e le registra in un log durevole (il nome esatto varia per database).\n2. Le repliche streamano o recuperano quelle voci di log dal primario.\n3. Le repliche riproducono le stesse modifiche nello stesso ordine, recuperando gradualmente il ritardo.
Le letture possono essere servite dalle repliche, ma le scritture vanno sempre al primario.
Replicazione sincrona vs asincrona (livello alto)
La replicazione può avvenire in due modalità principali:
- Sincrona: il primario aspetta che una replica (o una maggioranza) confermi di aver ricevuto la modifica prima che la scrittura sia considerata “committed.” Questo riduce le letture obsolete, ma può aumentare la latenza delle scritture e rendere le scritture più sensibili a problemi di replica/rete.\n- Asincrona: il primario committa la scrittura immediatamente e le repliche si aggiornano dopo. Questo mantiene le scritture veloci e resilienti, ma le repliche possono temporaneamente rimanere indietro.
Replication lag e “consistenza eventuale”
Quel ritardo—le repliche che rimangono indietro rispetto al primario—si chiama replication lag. Non è automaticamente un errore; spesso è il compromesso normale che accetti per scalare le letture.
Per gli utenti, il lag si manifesta come consistenza eventuale: dopo una modifica, il sistema diventerà consistente ovunque, ma non necessariamente all’istante.
Esempio: aggiorni la tua email e ricarichi la pagina del profilo. Se la pagina è servita da una replica che ha un ritardo di qualche secondo, potresti vedere brevemente l’email precedente—finché la replica non applica l’aggiornamento e “recupera”.
Quando le repliche di lettura aiutano davvero
Le repliche aiutano quando il database primario è sano per le scritture ma è satura nel servire traffico di lettura. Sono più efficaci quando puoi scaricare una parte significativa del carico di SELECT senza cambiare come scrivi i dati.
Segnali che sei limitato dalle letture (non dalle scritture)
Cerca pattern come:
- CPU alta sul primario durante i picchi di traffico, mentre il throughput di scrittura non è anomalo\n- Rapporto molto alto di query
SELECT rispetto a INSERT/UPDATE/DELETE\n- Query di lettura che rallentano nei picchi anche se le scritture restano stabili\n- Saturazione dei pool di connessione guidata da endpoint a lettura pesante (pagine prodotto, feed, risultati di ricerca)
Come confermare che il problema sono le letture (metriche da controllare)
Prima di aggiungere repliche, valida con segnali concreti:
- CPU vs I/O: la CPU del primario è al massimo quando la latenza di lettura aumenta? Oppure il collo di bottiglia è l’I/O disco di lettura?\n- Mix di query: percentuale di tempo trascorsa in
SELECT (dal slow query log/APM).\n- p95/p99 latenza delle letture: monitora gli endpoint di lettura e la latenza delle query separatamente.\n- Hit rate di buffer/cache: un hit rate basso può significare che le letture forzano l’accesso al disco.\n- Top query per tempo totale: una query costosa può dominare il “carico di lettura.”
Non saltare le soluzioni più economiche
Spesso la prima mossa migliore è ottimizzare: aggiungi l’indice giusto, riscrivi una query, riduci chiamate N+1 o utilizza caching per letture calde. Questi cambiamenti possono essere più veloci ed economici rispetto all’operare repliche.
Checklist rapida: repliche vs ottimizzazione
Scegli repliche se:\n
- La maggior parte del carico è lettura e le letture sono già ragionevolmente ottimizzate\n- Puoi tollerare occasionali letture obsolete per le query scaricate\n- Hai bisogno di capacità aggiuntiva velocemente senza cambi rischiosi allo schema/alle query
Scegli ottimizzazione prima se:\n
- Poche query dominano il tempo totale di lettura\n- Indici mancanti o join inefficienti sono ovvi\n- Le letture sono lente anche a basso traffico (segno di problemi di progettazione delle query)
Casi d’uso migliori
Le repliche sono più preziose quando il primario è occupato a gestire scritture (checkout, registrazioni, aggiornamenti), ma una grande parte del traffico è a lettura pesante. In un’architettura primario–replica, indirizzare le query giuste alle repliche migliora le prestazioni del database senza cambiare le funzionalità dell’app.
1) Dashboard e analytics che non devono rallentare le transazioni
I dashboard spesso eseguono query lunghe: raggruppamenti, filtri su ampia finestra temporale o join multipli. Quelle query possono competere per CPU, memoria e cache con il lavoro transazionale.
Una replica è un buon posto per:\n
- Carichi di reporting interni\n- Dashboard amministrativi\n- Viste metriche giornaliere/settimanali
Mantieni il primario concentrato su transazioni veloci e prevedibili mentre le letture analitiche scalano indipendentemente.
2) Pagine di ricerca e navigazione con letture pesanti
Browsing cataloghi, profili utente e feed di contenuti possono generare un alto volume di query simili. Quando la pressione di scala delle letture è il collo di bottiglia, le repliche possono assorbire il traffico e ridurre picchi di latenza.
Questo è particolarmente efficace quando le letture hanno molti cache-miss (molte query uniche) o quando non puoi fare affidamento solo su una cache applicativa.
3) Job in background che scansionano molti dati
Export, backfill, ricalcolo di sommari e job “trova ogni record che soddisfa X” possono martellare il primario. Eseguire queste scansioni contro una replica è spesso più sicuro.
Assicurati però che il job tolleri la consistenza eventuale: con il replication lag potrebbe non vedere gli aggiornamenti più recenti.
4) Letture multi-regione per latenza più bassa (con avvertenze sulla staleness)
Se servi utenti globali, posizionare repliche di lettura più vicine a loro può ridurre il tempo di round-trip. Il compromesso è una maggiore esposizione a letture obsolete durante il lag o problemi di rete, quindi è meglio per pagine dove “quasi aggiornato” è accettabile (browse, raccomandazioni, contenuti pubblici).
Dove le repliche possono ritorcersi contro
Plan Replica Ready Architecture
Use Koder.ai to sketch a primary-replica plan before you write a line of backend code.
Le repliche funzionano bene quando “abbastanza vicino” è sufficiente. Tornano contro quando il tuo prodotto presuppone implicitamente che ogni lettura rifletta l’ultima scrittura.
Il sintomo classico: “L’ho appena aggiornato, perché non è cambiato?”
Un utente modifica il profilo, invia un modulo o cambia impostazioni — e il caricamento successivo viene servito da una replica qualche secondo indietro. L’aggiornamento è stato eseguito, ma l’utente vede dati vecchi e ritenta, invia doppi invii o perde fiducia.
Questo è particolarmente doloroso in flussi dove l’utente si aspetta conferma immediata: cambiare email, attivare/disattivare preferenze, caricare un documento o pubblicare un commento e poi essere reindirizzato.
Schermate che devono essere correnti (non giocare qui)
Alcune letture non possono tollerare nemmeno una breve obsolescenza:\n
- Carrelli e totali di checkout\n- Saldi wallet, punti fedeltà, conteggi di inventario\n- Schermate “Il mio pagamento è andato a buon fine?”
Se una replica è indietro, puoi mostrare il totale sbagliato del carrello, vendere oltre lo stock o visualizzare un saldo non aggiornato. Anche se il sistema si corregge dopo, l’esperienza utente (e il volume di supporto) ne risente.
Strumenti admin e operativi hanno bisogno della verità più fresca
I dashboard interni spesso guidano decisioni reali: revisione frodi, supporto clienti, evasione ordini, moderazione e risposta a incidenti. Se uno strumento admin legge dalle repliche, rischi di agire su dati incompleti—ad esempio rimborsare un ordine già rimborsato o perdere l’ultimo stato.
Fix pratico: instradare le letture “read-your-writes” al primario
Un pattern comune è l’instradamento condizionale:\n
- Dopo che un utente scrive, invia le sue letture di conferma al primario per una breve finestra (secondi o minuti).\n- Mantieni su repliche le letture background, anonime o non critiche.
Questo preserva i benefici delle repliche senza trasformare la consistenza in un gioco d’azzardo.
Capire il replication lag e le letture obsolete
Il replication lag è il ritardo tra quando una scrittura è committata sul primario e quando quella stessa modifica diventa visibile su una replica. Se la tua app legge da una replica durante quel ritardo, può restituire risultati “obsoleti” — dati veri poco prima, ma non più.
Perché il lag succede
Il lag è normale e di solito cresce sotto stress. Cause comuni includono:\n
- Picchi di carico sul primario: molte scritture significano più modifiche da inviare e applicare.\n- Replica sottodimensionata o occupata: la replica non riesce ad applicare le modifiche alla stessa velocità (CPU, I/O disco).\n- Latenza o jitter di rete: ritardi nel trasferire il flusso di replica.\n- Transazioni grandi / aggiornamenti in blocco: una singola modifica pesante può richiedere tempo per essere serializzata, trasferita e riapplicata.
Come le letture obsolete si manifestano nel prodotto
Il lag non riguarda solo la “freschezza”—influisce sulla correttezza dal punto di vista dell’utente:\n
- Un utente aggiorna il profilo e vedrà il valore vecchio al refresh.\n- Badge “messaggi non letti” o contatori scivolano perché i conteggi sono calcolati su righe leggermente vecchie.\n- Schermate admin/reporting perdono gli ultimi ordini, rimborsi o cambi di stato.
Modi pratici per gestirlo
Decidi cosa può tollerare la tua feature:\n
- Aggiungi una finestra di tolleranza: “I dati possono avere fino a 30 secondi di ritardo” è accettabile per molti dashboard.\n- Instrada read-after-write al primario: dopo una modifica, leggi quell’entità dal primario per un breve periodo.\n- Messaggistica UI: indica lo stato (“Aggiornamento in corso…”, “Potrebbe impiegare qualche secondo per apparire”).\n- Logica di retry: se una lettura critica non trova un record appena scritto, riprova contro il primario o riprova dopo un breve ritardo.
Cosa monitorare e allertare
Monitora il lag della replica (tempo/byte), la velocità di applicazione delle repliche, errori di replica e CPU/disk I/O delle repliche. Allerta quando il lag supera la tolleranza stabilita (es. 5s, 30s, 2m) e quando il lag continua a crescere nel tempo (segno che la replica non riuscirà a recuperare senza intervento).
Scaling delle letture vs scaling delle scritture (compromessi chiave)
Build Read Heavy Features Fast
Prototype read-heavy pages and dashboards fast, then decide what can tolerate stale reads.
Le repliche sono uno strumento per la scalabilità delle letture: aggiungere più punti da cui servire query SELECT. Non sono uno strumento per la scalabilità delle scritture: aumentare quante operazioni INSERT/UPDATE/DELETE il sistema può accettare.
Scalare le letture: cosa fanno bene le repliche
Quando aggiungi repliche, aumenti la capacità di lettura. Se la tua applicazione è limitata da endpoint a lettura pesante (pagine prodotto, feed, lookup), puoi distribuire quelle query su più macchine.
Questo spesso migliora:\n
- Latenza delle query sotto carico (meno contesa sul primario)\n- Throughput per le letture (più CPU/memoria/I/O disponibili per i
SELECT)\n- Isolamento per letture pesanti, come reporting, così non interferiscono con il traffico transazionale
Scalare le scritture: cosa non fanno le repliche
Un’equivoco comune è “più repliche = più throughput di scrittura.” In un setup primario-replica tipico, tutte le scritture vanno ancora al primario. Anzi, più repliche possono aumentare leggermente il lavoro del primario, perché deve generare e inviare i dati di replica a ogni replica.
Se il tuo problema è il throughput di scrittura, le repliche non lo risolveranno. Di solito servono altri approcci (ottimizzazione query/indici, batching, partizionamento/sharding o cambi di modello dati).
Limiti di connessione e pooling: il collo di bottiglia nascosto
Anche se le repliche aumentano la CPU disponibile per le letture, puoi comunque raggiungere prima i limiti di connessione. Ogni nodo database ha un numero massimo di connessioni concorrenti e aggiungere repliche può moltiplicare i luoghi a cui la tua app potrebbe connettersi—senza ridurre la domanda totale.
Regola pratica: usa connection pooling (o un pooler) e mantieni intenzionali i conteggi di connessioni per servizio. Altrimenti, le repliche possono semplicemente diventare “più database da sovraccaricare”.
Costi: la capacità non è gratuita
Le repliche aggiungono costi reali:\n
- Più nodi (costi compute)\n- Più storage (ogni replica tipicamente memorizza una copia completa)\n- Più lavoro operativo (monitoraggio del lag, strategia backup/restore, modifiche di schema, risposta agli incidenti)
Il compromesso è semplice: le repliche ti comprano margine sulle letture e isolamento, ma aggiungono complessità e non spostano il tetto delle scritture.
Alta disponibilità e failover: cosa possono fare le repliche
Le repliche possono migliorare la disponibilità di lettura: se il primario è sovraccarico o temporaneamente non disponibile, puoi comunque servire parte del traffico di sola lettura dalle repliche. Questo può mantenere pagine rivolte ai clienti reattive (per contenuti che tollerano un po’ di obsolescenza) e ridurre l’impatto di un incidente sul primario.
Quello che le repliche non forniscono da sole è un piano completo di alta disponibilità. Una replica in genere non è pronta ad accettare scritture automaticamente, e una “copia leggibile esiste” è diversa da “il sistema può accettare scritture in modo sicuro e rapido”.
Il failover tipicamente significa: rilevare il fallimento del primario → scegliere una replica → promuoverla a nuovo primario → reindirizzare le scritture (e di solito le letture) al nodo promosso.
Alcuni servizi gestiti automatizzano la maggior parte di questo, ma l’idea centrale resta: stai cambiando chi può accettare scritture.
Rischi chiave da pianificare
- Dati obsoleti nella replica: la replica potrebbe essere indietro. Se la promuovi, potresti perdere le scritture più recenti che non sono mai state replicate.\n- Evitare split-brain: devi impedire che due nodi accettino scritture contemporaneamente. Per questo le promozioni sono solitamente controllate da un’autorità singola (control plane gestito, sistema di quorum o procedure operative rigide).\n- Routing e cache: la tua app ha bisogno di un modo affidabile per cambiare target—connection string, DNS, proxy o un router per database. Assicurati che il traffico di scrittura non continui ad andare per errore al vecchio primario.
Testalo come una feature
Tratta il failover come qualcosa da praticare. Esegui game-day test in staging (e con cautela in produzione in finestre a basso rischio): simula la perdita del primario, misura il tempo di recupero, verifica il routing e conferma che la tua app gestisce periodi di sola lettura e reconnessioni in modo pulito.
Pattern pratici di instradamento (separazione letture/scritture)
Le repliche aiutano solo se il traffico raggiunge effettivamente le repliche. Il “read/write splitting” sono le regole che inviano le scritture al primario e le letture idonee alle repliche—senza rompere la correttezza.
Pattern 1: Split nell’applicazione
L’approccio più semplice è l’instradamento esplicito nel tuo data access layer:\n
- Tutte le scritture (
INSERT/UPDATE/DELETE, modifiche di schema) vanno al primario.\n- Solo alcune letture selezionate possono usare una replica.
Questo è facile da ragionare e da rollbackare. È anche il luogo dove puoi codificare regole di business come “dopo il checkout, leggi sempre lo stato dell’ordine dal primario per un po’.”
Pattern 2: Split tramite proxy o driver
Alcuni team preferiscono un proxy database o un driver smart che conosce gli endpoint primario vs replica e instrada in base al tipo di query o alle impostazioni di connessione. Questo riduce i cambi nel codice applicativo, ma attenzione: i proxy non possono sapere affidabilmente quali letture sono “sicure” dal punto di vista del prodotto.
Scegliere quali query possono andare alle repliche
Buoni candidati:\n
- Analytics, reporting, carichi di lavoro di dashboard\n- Pagine di ricerca/navigazione dove dati leggermente obsoleti sono accettabili\n- Job background che ritentano e non hanno bisogno del valore più recente
Evita di instradare letture che seguono immediatamente una scrittura dell’utente (es. “update profile → reload profile”) a meno che tu non abbia una strategia di consistenza.
Transazioni e consistenza di sessione
Dentro una transazione, mantieni tutte le letture sul primario.
Fuori dalle transazioni, considera sessioni “read-your-writes”: dopo una scrittura, vincola quell’utente/sessione al primario per un breve TTL, o instrada query di follow-up specifiche al primario.
Parti con piccoli passi e misura
Aggiungi una replica, instrada un set limitato di endpoint/query e confronta prima/dopo:\n
- CPU del primario e IOPS di lettura\n- Utilizzo della replica\n- Tasso di errori e percentili di latenza\n- Incidenti legati a letture obsolete
Espandi l’instradamento solo quando l’impatto è chiaro e sicuro.
Monitoraggio e operazioni di base
Get Credits for Shipping
Share what you build with Koder.ai and earn credits through the content program.
Le repliche non sono “configura e dimentica”. Sono server database extra con limiti di performance, modalità di guasto e compiti operativi propri. Un po’ di disciplina nel monitoraggio è spesso la differenza tra “le repliche hanno aiutato” e “le repliche hanno aggiunto confusione”.
Cosa osservare (le poche metriche che contano)
Concentrati su indicatori che spiegano i sintomi visibili agli utenti:\n
- Replica lag: quanto una replica è indietro rispetto al primario (secondi, byte o posizione WAL/LSN a seconda del database). Questo è il tuo avviso precoce per letture obsolete.\n- Errori di replica: connessioni rotte, problemi di autenticazione, disco pieno o problemi con gli slot di replica. Tratta questi come incidenti, non come “rumore”.\n- Latenza query (p50/p95) su repliche vs primario: le repliche possono essere lente anche quando il primario va bene (stato di cache differente, hardware diverso, report lunghi).\n- Hit rate della cache: una replica che perde costantemente la cache può mostrare latenza più alta dopo riavvii o spostamenti di traffico.
Pianificazione capacità: quante repliche servono?
Parti con una replica se l’obiettivo è scaricare le letture. Aggiungi altre repliche quando hai un vincolo chiaro:\n
- Throughput di lettura: una replica potrebbe non reggere il picco di QPS o query analitiche pesanti.\n- Isolamento: dedica una replica al reporting così i dashboard non sottraggono risorse al traffico utente.\n- Geografia: una replica per regione può ridurre la latenza di lettura, ma aumenta l’overhead operativo.
Regola pratica: scala le repliche solo dopo aver confermato che le letture sono il collo di bottiglia (non indici, query lente o caching dell’app).
Compiti operativi comuni
- Backup: decidi dove eseguire i backup. Fare backup da una replica può ridurre il carico sul primario, ma verifica i requisiti di consistenza e che la replica sia sana.\n- Cambi di schema: testa le migrazioni pensando alla replicazione (DDL a lunga durata può aumentare il lag). Coordina rollout in modo che app e schema restino compatibili durante la propagazione.\n- Finestre di manutenzione: patchare o riavviare repliche riduce temporaneamente la capacità di lettura. Pianifica la rotazione così da non scendere sotto la capacità richiesta.
Checklist troubleshooting: “le repliche sono lente”
- Controlla il replica lag: se è alto, gli utenti potrebbero ritentare o vedere dati obsoleti.\n2. Confronta i slow query log su replica vs primario: le query di reporting spesso emergono qui.\n3. Verifica CPU, memoria, disk I/O e rete sull’host replica.\n4. Cerca contenzione di lock o transazioni lunghe sul primario che ritardano la replica.\n5. Conferma che il tuo routing delle letture non stia sovraccaricando una singola replica (bilanciamento di carico non uniforme).\n6. Valida che gli indici esistano sulle repliche (devono rispecchiare il primario) e che le statistiche siano aggiornate.
Alternative e un semplice framework decisionale
Le repliche sono uno strumento per scalare le letture, ma raramente sono la prima leva da tirare. Prima di aggiungere complessità operativa, verifica se una soluzione più semplice ottiene lo stesso risultato.
Alternative da provare prima
Caching può rimuovere intere classi di letture dal database. Per pagine “read-mostly” (dettagli prodotto, profili pubblici, configurazioni), una cache applicativa o una CDN può ridurre drasticamente il carico—senza introdurre lag di replica.
Indice e ottimizzazione delle query spesso battono le repliche per il caso comune: poche query costose che consumano CPU. Aggiungere l’indice giusto, ridurre le colonne SELECT, evitare N+1 e sistemare join pessimi può trasformare “abbiamo bisogno di repliche” in “avevamo solo bisogno di un piano migliore”.
Materialized views / pre-aggregazione aiutano quando il carico è intrinsecamente pesante (analytics, dashboard). Invece di rieseguire query complesse, memorizzi risultati calcolati e li aggiorni a intervalli.
Quando considerare sharding/partizionamento
Se le scritture sono il collo di bottiglia (righe hot, contesa per lock, limiti I/O di scrittura), le repliche non aiutano molto. Qui entra in gioco il partizionamento per tempo/tenant o lo sharding per ID cliente, che distribuiscono il carico di scrittura. È un passo architetturale più grande, ma risolve il vincolo reale.
Un semplice framework decisionale
Fatti quattro domande:\n
- Qual è l’obiettivo? Ridurre latenza delle letture, scaricare reporting o migliorare alta disponibilità?\n2. Quanto devono essere fresche le letture? Se non tolleri letture obsolete, le repliche possono creare problemi visibili all’utente.\n3. Qual è il budget? Le repliche aggiungono costi infrastrutturali e operativi.\n4. Quanta complessità puoi assorbire? Separare letture/scritture, gestire la consistenza eventuale e testare il failover non è banale.
Se stai prototipando un nuovo prodotto o lanciando un servizio rapidamente, aiuta incorporare questi vincoli nell’architettura fin dall’inizio. Per esempio, i team che costruiscono su Koder.ai (una piattaforma vibe-coding che genera app React con backend Go + PostgreSQL da un’interfaccia chat) spesso partono con un singolo primario per semplicità, poi passano alle repliche non appena dashboard, feed o reporting interno iniziano a competere con il traffico transazionale. Usare un flusso di lavoro basato sulla pianificazione rende più semplice decidere in anticipo quali endpoint possono tollerare la consistenza eventuale e quali devono essere “read-your-writes” dal primario.
Se vuoi aiuto per scegliere una strada, vedi /pricing per le opzioni, o consulta le guide correlate in /blog.