26 ago 2025·8 min
Come costruire prodotti AI-first con modelli nella logica dell'app
Guida pratica per costruire prodotti AI-first in cui il modello guida le decisioni: architettura, prompt, strumenti, dati, valutazione, sicurezza e monitoraggio.
Cosa significa costruire un prodotto AI-first
Costruire un prodotto AI-first non significa “aggiungere una chatbot”. Significa che il modello è una parte reale e funzionante della logica della tua applicazione—proprio come un motore di regole, un indice di ricerca o un algoritmo di raccomandazione.
La tua app non si limita a usare l'AI; è progettata attorno al fatto che il modello interpreterà gli input, sceglierà azioni e produrrà output strutturati di cui il resto del sistema si fida.
In termini pratici: invece di codificare a mano ogni percorso decisionale (“se X allora fai Y”), lasci al modello le parti sfumate—linguaggio, intento, ambiguità, prioritizzazione—mentre il tuo codice gestisce ciò che deve essere preciso: permessi, pagamenti, scritture sul database e applicazione delle policy.
Quando AI-first è adatto (e quando non lo è)
AI-first funziona meglio quando il problema ha:
- Molti input validi (testo libero, documenti disordinati, obiettivi utente vari)
- Troppi casi limite per mantenere regole manuali
- Valore nel giudizio, riassunto o sintesi anziché nella determinazione perfetta
L'automazione basata su regole è di solito migliore quando i requisiti sono stabili e precisi—calcoli fiscali, logica di inventario, controlli di idoneità o workflow di conformità dove l'output deve essere lo stesso ogni volta.
Obiettivi di prodotto comuni che AI-first supporta
I team tipicamente adottano una logica guidata dal modello per:
- Aumentare la velocità: generare risposte, estrarre campi, instradare richieste più rapidamente
- Personalizzare le esperienze: adattare spiegazioni, piani o raccomandazioni
- Supportare decisioni: evidenziare compromessi, generare opzioni, riassumere evidenze
I compromessi da accettare (e progettare per)
I modelli possono essere imprevedibili, a volte sbagliando con sicurezza, e il loro comportamento può cambiare quando variano prompt, provider o contesto recuperato. Aggiungono anche costo per richiesta, possono introdurre latenza e sollevare problemi di sicurezza e fiducia (privacy, output dannosi, violazioni di policy).
La mentalità giusta è: un modello è un componente, non una scatola magica. Trattalo come una dipendenza con specifiche, modalità di fallimento, test e monitoraggio—così ottieni flessibilità senza scommettere il prodotto su speranze.
Scegli il caso d'uso giusto e definisci il successo
Non ogni funzionalità beneficia di mettere un modello al volante. I migliori casi d'uso AI-first iniziano con un chiaro job-to-be-done e terminano con un risultato misurabile che puoi monitorare settimana dopo settimana.
Parti dal lavoro, non dal modello
Scrivi una user story in una frase: “Quando ___, voglio ___, così posso ___.” Poi rendi l'outcome misurabile.
Esempio: “Quando ricevo una lunga email cliente, voglio una risposta suggerita che rispetti le nostre policy, così posso rispondere in meno di 2 minuti.” Questo è molto più azionabile di “aggiungi un LLM alle email”.
Mappa i punti decisionali
Identifica i momenti in cui il modello sceglierà le azioni. Questi punti decisionali devono essere espliciti così puoi testarli.
Punti decisionali comuni includono:
- Classificare l'intento e instradare al workflow giusto
- Decidere se fare una domanda di chiarimento o procedere
- Selezionare strumenti (ricerca, lookup CRM, redazione, creazione ticket)
- Decidere quando scalare a un umano
Se non sai nominare le decisioni, non sei pronto per rilasciare una logica guidata dal modello.
Scrivi criteri di accettazione per il comportamento
Tratta il comportamento del modello come qualsiasi altro requisito di prodotto. Definisci cosa significa “buono” e cosa significa “cattivo” in linguaggio chiaro.
Per esempio:
- Buono: usa l'ultima policy, cita l'ID ordine corretto, fa una sola domanda chiara se manca info
- Cattivo: inventa sconti, fa riferimento a località non supportate o risponde senza controllare i dati richiesti
Questi criteri diventano la base per il tuo insieme di valutazione più avanti.
Identifica i vincoli in anticipo
Elenca i vincoli che influenzano le tue scelte di design:
- Tempo (obiettivi di latenza di risposta)
- Budget (costo per task)
- Conformità (gestione PII, requisiti di audit)
- Locali supportati (lingue, tono, aspettative culturali)
Definisci metriche di successo che puoi monitorare
Scegli un piccolo set di metriche legate al job:
- Tasso di completamento del task
- Accuratezza (o aderenza alla policy) su casi rappresentativi
- CSAT o valutazione qualitativa degli utenti
- Tempo risparmiato per task (o tempo di risoluzione)
Se non puoi misurare il successo, finisci a discutere di sensazioni invece di migliorare il prodotto.
Progetta il flusso utente guidato dall'AI e i confini di sistema
Un flusso AI-first non è “una schermata che chiama un LLM”. È un percorso end-to-end dove il modello prende certe decisioni, il prodotto le esegue in sicurezza e l'utente resta orientato.
Mappa il ciclo end-to-end
Inizia disegnando la pipeline come una semplice catena: input → modello → azioni → output.
- Input: cosa fornisce l'utente (testo, file, selezioni) più il contesto dell'app (livello account, workspace, attività recenti).
- Passo modello: cosa il modello deve decidere (classificare, redigere, riassumere, scegliere l'azione successiva).
- Azioni: cosa può fare il tuo sistema (ricerca, creare un task, aggiornare un record, inviare un'email).
- Output: cosa vede l'utente (una bozza, una spiegazione, una schermata di conferma, un errore con i passaggi successivi).
Questa mappa obbliga a chiarire dove l'incertezza è accettabile (bozze) e dove non lo è (modifiche di fatturazione).
Disegna i confini di sistema: modello vs codice deterministico
Separa i percorsi deterministici (controlli permessi, regole di business, calcoli, scritture su DB) dalle decisioni guidate dal modello (interpretazione, prioritizzazione, generazione in linguaggio naturale).
Una regola utile: il modello può consigliare, ma il codice deve verificare prima di qualsiasi azione irreversibile.
Decidi dove gira il modello
Scegli un runtime in base ai vincoli:
- Server: ideale per dati privati, tooling coerente, log di audit.
- Client: utile per assistenza leggera e privacy tramite elaborazione locale, ma più difficile da controllare.
- Edge: latenza globale più bassa, ma dipendenze limitate.
- Ibrido: rilevamento rapido dell'intento all'edge e lavoro pesante sul server.
Pianifica latenza, costi e permessi dei dati
Imposta un budget per richiesta di latenza e costi (inclusi retry e chiamate a strumenti), poi progetta l'UX attorno a esso (streaming, risultati progressivi, “continua in background”).
Documenta le fonti dati e i permessi necessari a ogni passo: cosa il modello può leggere, cosa può scrivere e cosa richiede conferma esplicita dell'utente. Questo diventa un contratto per ingegneria e fiducia.
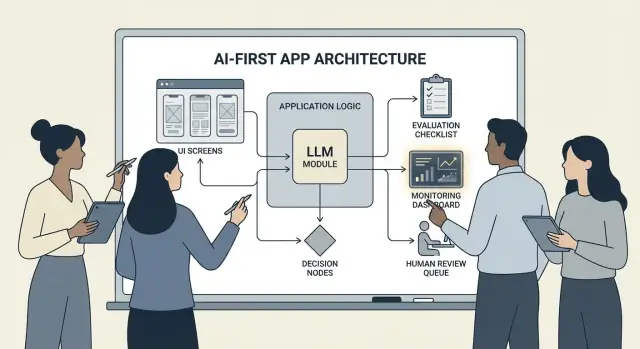
Pattern architetturali: orchestrazione, stato e tracce
Quando un modello fa parte della logica dell'app, “architettura” non è solo server e API—è come esegui in modo affidabile una catena di decisioni modellistiche senza perdere il controllo.
Orchestrazione: il direttore del lavoro AI
L'orchestrazione è lo strato che gestisce come un task AI si esegue end-to-end: prompt e template, chiamate a strumenti, memoria/contesto, retry, timeout e fallback.
Buoni orchestratori trattano il modello come un componente in una pipeline. Decidono quale prompt usare, quando chiamare uno strumento (ricerca, DB, email, pagamento), come comprimere o recuperare contesto e cosa fare se il modello restituisce qualcosa di invalido.
Se vuoi muoverti più velocemente dall'idea a un'orchestrazione funzionante, un workflow di vibe-coding può aiutare a prototipare queste pipeline senza ricostruire lo scheletro dell'app da zero. Per esempio, Koder.ai permette ai team di creare app web (React), backend (Go + PostgreSQL) e anche app mobile (Flutter) via chat—poi iterare su flussi come “input → modello → chiamate a strumenti → validazioni → UI” con funzionalità come planning mode, snapshot e rollback, più esportazione del codice sorgente quando sei pronto a possedere il repo.
State machine per task multi-step
Esperienze multi-step (triage → raccogliere info → confermare → eseguire → riassumere) funzionano meglio se le modelli come un workflow o una macchina a stati.
Un pattern semplice è: ogni passo ha (1) input ammessi, (2) output attesi e (3) transizioni. Questo evita conversazioni vaganti e rende espliciti i casi limite—come cosa succede se l'utente cambia idea o fornisce info parziali.
Ragionamento single-shot vs multi-turn
Il single-shot funziona bene per task contenuti: classificare un messaggio, redigere una breve risposta, estrarre campi da un documento. È più economico, più veloce e più facile da validare.
Il multi-turn è migliore quando il modello deve fare domande chiarificatrici o quando gli strumenti sono necessari in modo iterativo (es., pianificare → cercare → perfezionare → confermare). Usalo intenzionalmente e limita i loop con limiti di tempo/step.
Idempotenza: evita effetti collaterali ripetuti
I modelli fanno retry. Le reti falliscono. Gli utenti fanno doppio click. Se uno step AI può innescare effetti collaterali—inviare un'email, prenotare, addebitare—rendilo idempotente.
Tattiche comuni: allega una chiave di idempotenza a ogni azione “esegui”, memorizza il risultato dell'azione e assicurati che i retry restituiscano lo stesso esito invece di ripeterlo.
Tracce: rendi ogni passo debuggabile
Aggiungi tracciabilità così puoi rispondere: Cosa ha visto il modello? Cosa ha deciso? Quali strumenti hanno girato?
Logga una traccia strutturata per esecuzione: versione del prompt, input, ID del contesto recuperato, richieste/risposte agli strumenti, errori di validazione, retry e output finale. Questo trasforma “l'AI ha fatto qualcosa di strano” in una timeline auditabile e correggibile.
Prompting come logica di prodotto: contratti e formati chiari
Quando il modello fa parte della logica dell'app, i tuoi prompt smettono di essere “copy” e diventano specifiche eseguibili. Trattali come requisiti di prodotto: ambito esplicito, output prevedibili e controllo delle modifiche.
Inizia con un system prompt che definisca il contratto
Il tuo system prompt dovrebbe impostare il ruolo del modello, cosa può e non può fare e le regole di sicurezza rilevanti per il prodotto. Mantienilo stabile e riutilizzabile.
Includi:
- Ruolo e obiettivo: chi è (es., “assistente di triage supporto”) e cosa significa successo.
- Confini di scope: quali richieste deve rifiutare o scalare.
- Regole di sicurezza: gestione PII, disclaimer medici/legali, nessuna supposizione.
- Policy sugli strumenti: quando chiamare strumenti vs rispondere direttamente.
Struttura i prompt con input/output chiari
Scrivi prompt come definizioni di API: elenca gli input esatti che fornisci (testo utente, livello account, locale, frammenti di policy) e gli output esatti che ti aspetti. Aggiungi 1–3 esempi che corrispondono al traffico reale, inclusi casi limite complessi.
Un pattern utile è: Contesto → Compito → Vincoli → Formato output → Esempi.
Usa formati vincolati per risultati leggibili dalla macchina
Se il codice deve agire sull'output, non affidarti alla prosa. Richiedi JSON che corrisponda a uno schema e rifiuta qualsiasi altra cosa.
{
"type": "object",
"properties": {
"intent": {"type": "string"},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"actions": {
"type": "array",
"items": {"type": "string"}
},
"user_message": {"type": "string"}
},
"required": ["intent", "confidence", "actions", "user_message"],
"additionalProperties": false
}
Versiona i prompt e distribuisci in sicurezza
Conserva i prompt in controllo versione, tagga release e distribuisci come feature: deployment graduale, A/B dove appropriato e rollback rapido. Logga la versione del prompt con ogni risposta per il debug.
Costruisci una suite di test per i prompt
Crea un piccolo set rappresentativo di casi (happy path, richieste ambigue, violazioni di policy, input lunghi, locali diversi). Eseguili automaticamente a ogni modifica del prompt e fai fallire la build quando gli output rompono il contratto.
Tool Calling: lascia decidere il modello, lascia eseguire il codice
Spedisci l'intero stack dell'app
Crea un'app web React più backend in Go e PostgreSQL da una singola conversazione.
Il tool calling è il modo più pulito per separare responsabilità: il modello decide cosa deve accadere e quale capacità usare, mentre il codice applicativo esegue l'azione e restituisce risultati verificati.
Questo mantiene fatti, calcoli ed effetti collaterali (creazione ticket, aggiornamenti, invio email) in codice deterministico e auditabile—invece di fidarsi di testo libero.
Progetta un set di strumenti piccolo e intenzionale
Inizia con poche tool che coprano l'80% delle richieste e siano facili da mettere in sicurezza:
- Search (i tuoi documenti/centro assistenza) per rispondere a domande sul prodotto
- DB lookup (prima solo in lettura) per stato utente/account/ordine
- Calculator per prezzi, totali, conversioni e calcoli basati su regole
- Ticketing per aprire richieste di supporto quando serve follow-up umano
Mantieni lo scopo di ogni tool stretto. Uno strumento che fa “qualsiasi cosa” diventa difficile da testare e facile da usare male.
Valida input e sana output
Tratta il modello come un chiamante non affidabile.
- Valida input degli strumenti con schemi rigidi (tipi, range, enum). Rifiuta o ripara argomenti non sicuri (es., ID mancanti, query troppo ampie).
- Sana output degli strumenti prima di ridarlo al modello: rimuovi segreti, normalizza formati e restituisci solo i campi necessari.
Questo riduce il rischio di prompt-injection tramite testo recuperato e limita perdite accidentali di dati.
Aggiungi permessi e rate limit per ogni tool
Ogni strumento dovrebbe applicare:
- Controlli di permesso (chi può accedere a quali record, quali azioni)
- Rate limit (per utente/sessione/strumento) per ridurre abusi e loop incontrollati
Se uno strumento può cambiare stato (ticketing, rimborsi), richiedi autorizzazioni più forti e scrivi un log di audit.
Supporta sempre un percorso “nessun tool”
A volte la migliore azione è non fare nulla: rispondere dal contesto esistente, fare una domanda chiarificatrice o spiegare i limiti. Rendi “nessun tool” un risultato di prima classe così il modello non chiami strumenti solo per farsi vedere occupato.
Dati e RAG: radica il modello nella tua realtà
Se le risposte del tuo prodotto devono corrispondere a policy, inventario, contratti o conoscenze interne, hai bisogno di un modo per ancorare il modello ai tuoi dati—non solo al suo training generale.
RAG vs fine-tuning vs contesto semplice
- Contesto semplice (incolla qualche paragrafo nel prompt) funziona quando la conoscenza è piccola, stabile e puoi permetterti di inviarla ogni volta (es., una breve tabella prezzi).
- RAG (Retrieval-Augmented Generation) è migliore quando l'informazione è ampia, cambia frequentemente o richiede citazioni (es., articoli centro assistenza, doc di prodotto, dati account-specifici).
- Fine-tuning è ideale quando vuoi stile/format coerente o pattern di dominio—non come modo primario per “memorizzare fatti”. Usalo per migliorare come il modello scrive e segue le regole; abbinalo a RAG per la verità aggiornata.
Basi di ingestione: chunking, metadata, freschezza
La qualità del RAG è perlopiù un problema di ingestione.
Suddividi i documenti in pezzi adatti al tuo modello (spesso poche centinaia di token), idealmente allineati a confini naturali (intestazioni, voci FAQ). Memorizza metadata come: titolo documento, intestazione sezione, prodotto/versione, audience, locale e permessi.
Pianifica la freschezza: schedula il re-indexing, traccia “ultimo aggiornamento” ed esegui l'expire dei chunk vecchi. Un chunk obsoleto che scala alto degraderà lentamente tutta la feature.
Citazioni e risposte calibrate
Fai sì che il modello citi le fonti restituendo: (1) risposta, (2) una lista di ID snippet/fonte, e (3) una dichiarazione di confidenza.
Se il recupero è debole, istruisci il modello a dire ciò che non può confermare e offrire passi successivi (“Non ho trovato quella policy; ecco chi contattare”). Evita che compensi i vuoti con congetture.
Dati privati: controllo accessi e redazione
Applica il controllo accessi prima del recupero (filtra per permessi utente/org) e di nuovo prima della generazione (redigi campi sensibili).
Tratta embeddings e indici come archivi sensibili con log di audit.
Quando il recupero fallisce: fallback eleganti
Se i risultati top sono irrilevanti o vuoti, fallback a: fare una domanda chiarificatrice, instradare al supporto umano o passare a una modalità non-RAG che spiega i limiti invece di indovinare.
Affidabilità: guardrail, validazione e caching
Quando un modello è dentro la logica dell'app, “abbastanza buono la maggior parte delle volte” non basta. Affidabilità significa che gli utenti vedono comportamento coerente, il sistema può consumare gli output in sicurezza e i fallimenti degradano con grazia.
Definisci obiettivi di affidabilità (prima di aggiungere fix)
Scrivi cosa significa “affidabile” per la feature:
- Output coerenti: input simili dovrebbero produrre risposte comparabili (tono, livello di dettaglio, vincoli).
- Formati stabili: la risposta deve essere sempre parsabile (JSON, elenco puntato, campi specifici).
- Comportamento limitato: limiti chiari su ciò che il modello deve fare (no supposizioni, cita fonti, fare una domanda quando incerto).
Questi obiettivi diventano criteri di accettazione per prompt e codice.
Guardrail: valida, filtra e applica policy
Tratta l'output del modello come input non affidabile.
- Validazione di schema: richiedi un formato rigoroso (es., JSON con chiavi obbligatorie) e rifiuta tutto ciò che non parse.
- Filtri di contenuto: esegui controlli su parolacce, rilevatori PII o validator di policy sia sull'input utente sia sull'output del modello.
- Regole di business: applica vincoli in codice (range di prezzo, regole di idoneità, azioni ammesse), anche se il prompt le menziona.
Se la validazione fallisce, restituisci un fallback sicuro (fai una domanda chiarificatrice, passa a un template più semplice o instrada a un umano).
Retry che aiutano davvero
Evita ripetizioni cieche. Ritenta con un prompt diverso che affronti la modalità di errore:
- “Restituisci solo JSON valido. Niente markdown.”
- “Se incerto, imposta
confidencesu basso e fai una domanda.”
Limita i retry e logga il motivo di ogni fallimento.
Post-processing deterministico
Usa il codice per normalizzare ciò che il modello produce:
- canonicalizza unità, date e nomi
- de-duplica elementi
- applica regole di ranking o soglie
Questo riduce la varianza e rende gli output più testabili.
Caching senza creare problemi di privacy
Cache risultati ripetibili (es., query identiche, embedding condivisi, risposte di tool) per ridurre costi e latenza.
Preferisci:
- TTL brevi per dati specifici dell'utente
- chiavi di cache che escludono PII raw (o hash in modo sicuro)
- flag “do not cache” per flussi sensibili
Fatto bene, il caching migliora la coerenza preservando la fiducia degli utenti.
Sicurezza e fiducia: ridurre il rischio senza compromettere l'UX
Portalo su mobile
Aggiungi un'app mobile Flutter al tuo prodotto AI-first usando lo stesso workflow via chat.
La sicurezza non è uno strato di conformità che aggiungi alla fine. Nei prodotti AI-first, il modello può influenzare azioni, formulazioni e decisioni—quindi la sicurezza deve far parte del contratto di prodotto: cosa l'assistente può fare, cosa deve rifiutare e quando deve chiedere aiuto.
Preoccupazioni chiave di sicurezza su cui progettare
Nomina i rischi che la tua app affronta realmente, poi mappa ciascuno a un controllo:
- Dati sensibili: identificatori personali, credenziali, documenti privati e qualsiasi cosa regolamentata.
- Consigli dannosi: istruzioni che potrebbero favorire autolesionismo, violenza, attività illegali o azioni mediche/finanziarie pericolose.
- Bias e risultati ingiusti: qualità del servizio, raccomandazioni o decisioni incoerenti tra gruppi.
Argomenti permessi/bloccati + percorsi di escalation
Scrivi una policy esplicita che il prodotto può applicare. Rendila concreta: categorie, esempi e risposte attese.
Usa tre livelli:
- Permesso: rispondere normalmente.
- Limitato: rispondere con vincoli (es., informazioni generali solo, niente istruzioni dettagliate).
- Bloccato: rifiutare e instradare a un percorso di escalation (supporto, risorse o un agente umano).
L'escalation deve essere un flusso di prodotto, non solo un messaggio di rifiuto. Fornisci un'opzione “Parla con una persona” e assicurati che il passaggio includa il contesto già condiviso dall'utente (con consenso).
Revisione umana per azioni ad alto impatto
Se il modello può innescare conseguenze reali—pagamenti, rimborsi, cambi account, cancellazioni, cancellazione dati—aggiungi un checkpoint.
Buoni pattern includono: schermate di conferma, “bozza poi approva”, limiti (cap massimi), e una coda di revisione umana per casi limite.
Informative, consenso e policy testabili
Dì agli utenti quando stanno interagendo con AI, quali dati vengono usati e cosa viene memorizzato. Chiedi il consenso quando necessario, soprattutto per salvare conversazioni o usare i dati per migliorare il sistema.
Tratta le policy interne di sicurezza come codice: versionale, documenta le motivazioni e aggiungi test (prompt di esempio + risultati attesi) così la sicurezza non regredisca a ogni modifica di prompt o modello.
Valutazione: testa il modello come qualsiasi componente critico
Se un LLM può cambiare ciò che fa il tuo prodotto, hai bisogno di un modo ripetibile per dimostrare che funziona ancora—prima che gli utenti scoprano regressioni per te.
Tratta prompt, versioni modello, schemi strumenti e impostazioni di retrieval come artefatti degni di release che richiedono test.
Costruisci un set di valutazione dai dati reali
Raccogli intenti utente reali da ticket di supporto, query di ricerca, log di chat (con consenso) e chiamate commerciali. Trasformali in casi di test che includano:
- Richieste comuni in happy-path
- Prompt ambigui che richiedono domande chiarificatrici
- Casi limite (dati mancanti, vincoli conflittuali, formati insoliti)
- Scenari sensibili alle policy (dati personali, contenuto non consentito)
Ogni caso dovrebbe includere il comportamento atteso: la risposta, la decisione presa (es., “chiama lo strumento A”) e qualsiasi struttura richiesta (campi JSON presenti, citazioni incluse, ecc.).
Scegli metriche che corrispondono al rischio di prodotto
Un singolo punteggio non catturerà la qualità. Usa un piccolo set di metriche che mappano a risultati utente:
- Accuratezza / successo del task: ha risolto l'obiettivo dell'utente?
- Groundedness: le affermazioni sono supportate dal contesto o dalle fonti fornite?
- Validità del formato: l'output rispetta il contratto (JSON, tabella, bullet)?
- Tasso di rifiuto: rifiuta quando dovrebbe—e evita di farlo quando non dovrebbe?
Monitora costo e latenza insieme alla qualità; un “modello migliore” che raddoppia i tempi di risposta può peggiorare la conversione.
Esegui valutazioni offline a ogni cambiamento
Esegui valutazioni offline prima del rilascio e dopo ogni modifica a prompt, modello, strumento o retrieval. Tieni i risultati versionati così puoi confrontare esecuzioni e individuare rapidamente cosa è cambiato.
Aggiungi test online con guardrail
Usa A/B online per misurare risultati reali (tasso di completamento, modifiche, valutazioni utente), ma metti guardrail di sicurezza: definisci condizioni di stop (es., picchi di output non validi, rifiuti o errori strumenti) e rollback automatico quando le soglie sono superate.
Monitoraggio in produzione: drift, fallimenti e feedback
Costruisci pipeline di orchestrazione
Trasforma input → modello → chiamate a strumenti in un vero flusso applicativo testabile end-to-end.
Rilasciare una feature AI-first non è il traguardo. Con utenti reali, il modello affronterà nuove formulazioni, casi limite e dati che cambiano. Il monitoraggio trasforma “funzionava in staging” in “continua a funzionare il prossimo mese”.
Logga ciò che conta (senza raccogliere segreti)
Cattura abbastanza contesto per riprodurre i fallimenti: intento utente, versione del prompt, chiamate a strumenti e output finale del modello.
Logga input/output con redazione privacy-safe. Tratta i log come dati sensibili: rimuovi email, numeri di telefono, token e testi free-form che potrebbero contenere dettagli personali. Mantieni una “debug mode” che puoi abilitare temporaneamente per sessioni specifiche anziché loggare tutto al massimo di default.
Osserva i segnali giusti
Monitora tassi di errore, fallimenti degli strumenti, violazioni di schema e drift. In concreto, traccia:
- Tasso di successo delle chiamate a strumenti e timeout (il modello ha scelto lo strumento giusto ed è stato eseguito?)
- Conformità al formato/schema dell'output (i validatori l'hanno rifiutato?)
- Uso dei fallback (quanto spesso devi passare a percorsi più sicuri o semplici)
- Blocchi di sicurezza dei contenuti (quanto spesso rifiuti o sani)
Per il drift, confronta il traffico corrente con il baseline: cambiamenti nella combinazione di argomenti, lingua, lunghezza media del prompt e intenti “sconosciuti”. Il drift non è sempre negativo—ma è sempre un campanello per riesaminare.
Alert, runbook e risposta agli incidenti
Imposta soglie di allerta e runbook on-call. Le allerte dovrebbero mappare ad azioni: rollback di una versione di prompt, disabilitare uno strumento instabile, restringere la validazione o passare a un fallback.
Pianifica la risposta agli incidenti per comportamenti non sicuri o scorretti. Definisci chi può attivare gli interruttori di sicurezza, come notificare gli utenti e come documentare e imparare dall'evento.
Chiudi il ciclo con il feedback degli utenti
Usa loop di feedback: pollici su/giu, codici di motivo, report di bug. Chiedi un “perché?” leggero (fatti sbagliati, non ha seguito istruzioni, non sicuro, troppo lento) così puoi instradare i problemi alla correzione giusta—prompt, strumenti, dati o policy.
UX per la logica guidata dal modello: trasparenza e controllo
Le funzionalità guidate dal modello sembrano magiche quando funzionano—e fragili quando non funzionano. L'UX deve presumere incertezza e comunque aiutare gli utenti a completare il compito.
Mostra il “perché” senza sovraccaricare le persone
Gli utenti si fidano di più degli output AI quando vedono da dove vengono—non perché vogliano una lezione, ma perché questo li aiuta a decidere se agire.
Usa disclosure progressiva:
- Mostra prima l'outcome (risposta, bozza, raccomandazione).
- Offri un toggle “Perché?” o “Mostra lavoro” che riveli input chiave: la richiesta dell'utente, gli strumenti usati e le fonti o record consultati.
- Se usi il retrieval, mostra citazioni che rimandano allo snippet esatto (per esempio, “Basato su: Policy §3.2”). Mantienolo scansionabile.
Se hai un explainer più profondo, collegalo internamente (ad esempio, un articolo interno sul grounding RAG) invece di appesantire l'interfaccia.
Progetta per l'incertezza (senza avvisi spaventosi)
Un modello non è una calcolatrice. L'interfaccia dovrebbe comunicare la confidenza e invitare la verifica.
Pattern pratici:
- Indicazioni di confidenza in linguaggio semplice (“Probabilmente corretto”, “Da verificare”) invece di precisione fittizia.
- Opzioni piuttosto che risposte singole: “Ecco 3 modi per rispondere.” Questo riduce il costo di una prima scelta sbagliata.
- Conferme per azioni ad alto impatto (invio email, cancellazione dati, pagamenti). Fai una domanda chiara: “Inviare questo messaggio a 12 destinatari?”
Rendi la correzione e il recupero facili
Gli utenti dovrebbero poter correggere l'output senza ricominciare da capo:
- Modifica inline con “Applica modifiche” così il modello continua dalle correzioni dell'utente.
- “Rigenera” con controlli (tono, lunghezza, vincoli) invece di un reroll cieco.
- “Annulla” e una cronologia visibile così gli errori sono reversibili.
Fornisci una via di fuga
Quando il modello fallisce—o l'utente è incerto—offri un flusso deterministico o aiuto umano.
Esempi: “Passa al modulo manuale”, “Usa un template” o “Contatta il supporto”. Questo non è un fallback vergognoso; è il modo per proteggere il completamento del task e la fiducia.
Dal prototipo alla produzione (senza ricostruire tutto)
La maggior parte dei team non fallisce perché gli LLM sono incapaci; fallisce perché il percorso dal prototipo a una feature affidabile, testabile e monitorabile è più lungo del previsto.
Un modo pratico per abbreviare quel percorso è standardizzare lo “scheletro di prodotto” presto: state machine, schemi strumenti, validazione, tracce e una storia di deploy/rollback. Piattaforme come Koder.ai possono essere utili quando vuoi creare rapidamente un workflow AI-first—costruendo UI, backend e database insieme—e poi iterare in sicurezza con snapshot/rollback, domini personalizzati e hosting. Quando sei pronto per operazionalizzare, puoi esportare il codice sorgente e continuare con il tuo CI/CD e stack di osservabilità preferiti.