14 ott 2025·8 min
PostgreSQL row-level security per SaaS: policy che funzionano
La row-level security di PostgreSQL per SaaS aiuta a far rispettare l'isolamento dei tenant nel database. Scopri quando usarla, come scrivere le policy e cosa evitare.
La row-level security di PostgreSQL per SaaS aiuta a far rispettare l'isolamento dei tenant nel database. Scopri quando usarla, come scrivere le policy e cosa evitare.
In un'app SaaS, il bug di sicurezza più pericoloso è quello che emerge dopo aver scalato. Si parte con una regola semplice come “gli utenti possono vedere solo i dati del loro tenant”, poi si pubblica rapidamente un nuovo endpoint, si aggiunge una query di report o si introduce una join che inavvertitamente salta il controllo.
L'autorizzazione gestita solo dall'app cede sotto pressione perché le regole finiscono disperse. Un controller controlla tenant_id, un altro verifica l'appartenenza, un job in background si dimentica e un percorso “admin export” resta “temporaneo” per mesi. Anche i team attenti perdono qualche punto.
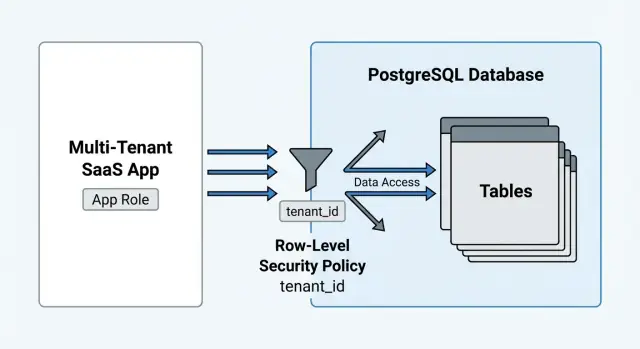
La row-level security (RLS) di PostgreSQL risolve un problema preciso: fa sì che sia il database ad applicare quali righe sono visibili per una determinata richiesta. Il modello mentale è semplice: ogni SELECT, UPDATE e DELETE viene filtrato automaticamente dalle policy, come ogni richiesta viene filtrata dal middleware di autenticazione.
La parte “righe” è importante. RLS non protegge tutto:
Un esempio concreto: aggiungi un endpoint che elenca i progetti con una join alle fatture per una dashboard. Con l'autorizzazione solo nell'app è facile filtrare projects per tenant e dimenticare di filtrare invoices, o fare la join su una chiave che attraversa tenant differenti. Con RLS, entrambe le tabelle possono far rispettare l'isolamento dei tenant, quindi la query fallisce in modo sicuro invece di divulgare dati.
Il compromesso è reale. Scrivi meno codice di autorizzazione ripetuto e riduci il numero di punti che possono perdere dati. Ma assumi anche nuovo lavoro: devi progettare le policy con cura, testararle presto e accettare che una policy possa bloccare una query che ti aspettavi funzionasse.
RLS può sembrare lavoro extra fino a quando la tua app non supera una manciata di endpoint. Se hai confini di tenant netti e molte vie di interrogazione (schermate di elenco, ricerca, esportazioni, strumenti admin), mettere la regola nel database significa che non devi ricordarti di aggiungere lo stesso filtro ovunque.
RLS è particolarmente adatto quando la regola è noiosa e universale: “un utente può vedere solo le righe del proprio tenant” o “un utente può vedere solo i progetti di cui è membro”. In questi casi le policy riducono gli errori perché ogni SELECT, UPDATE e DELETE passa dallo stesso filtro, anche quando una query viene aggiunta dopo.
Aiuta anche nelle app con carico di lettura elevato dove la logica di filtraggio rimane coerente. Se la tua API ha 15 modi diversi per caricare le fatture (per stato, per data, per cliente, per ricerca), RLS ti permette di smettere di reimplementare il filtraggio per tenant in ogni query e concentrarti sulla funzionalità.
RLS aggiunge problemi quando le regole non sono basate sulle righe. Regole per campo come “puoi vedere lo stipendio ma non il bonus” o “maschera questa colonna a meno che non sia HR” spesso si trasformano in SQL goffo e eccezioni difficili da mantenere.
Non è nemmeno adatto per reportistica pesante che ha davvero bisogno di accesso ampio. I team spesso creano ruoli di bypass per “solo questo job” e lì gli errori si accumulano.
Prima di impegnarti, decidi se vuoi che il database sia il guardiano finale. Se sì, pianifica la disciplina: testa il comportamento del database (non solo le risposte dell'API), tratta le migrazioni come cambiamenti di sicurezza, evita bypass rapidi, decidi come si autenticano i job in background e mantieni le policy piccole e ripetibili.
Se usi tool che generano backend, possono accelerare la consegna, ma non eliminano la necessità di ruoli chiari, test e un modello di tenant semplice. (Ad esempio, Koder.ai usa Go e PostgreSQL per backend generati, e vuoi comunque progettare RLS deliberatamente invece di “spruzzarlo” dopo.)
RLS è più semplice quando il tuo schema dice già con chiarezza chi possiede cosa. Se inizi con un modello sfocato e cerchi di “aggiustare tutto con le policy”, di solito ottieni query lente e bug confusi.
Scegli una chiave tenant unica (come org_id) e usala in modo coerente. La maggior parte delle tabelle possedute dal tenant dovrebbe averla, anche se fanno riferimento a un'altra tabella che ce l'ha. Questo evita join dentro le policy e mantiene i controlli USING semplici.
Una regola pratica: se una riga dovrebbe scomparire quando un cliente annulla, probabilmente ha bisogno di org_id.
Le policy RLS solitamente rispondono a una domanda: “Questo utente è membro di questa org, e cosa può fare?” È difficile dedurlo da colonne ad hoc.
Mantieni le tabelle core piccole e semplici:
users (una riga per persona)orgs (una riga per tenant)org_memberships (user_id, org_id, role, status)project_memberships per accesso per-progettoCon questo in posto, le tue policy possono verificare l'appartenenza con una singola lookup indicizzata.
Non tutto necessita di org_id. Tabelle di riferimento come paesi, categorie di prodotto o tipi di piano sono spesso condivise tra tutti i tenant. Rendile in lettura per la maggior parte dei ruoli e non legarle a un singolo org.
I dati posseduti dal tenant (progetti, fatture, ticket) dovrebbero evitare di tirare dettagli specifici del tenant tramite tabelle condivise. Mantieni le tabelle condivise minime e stabili.
Le foreign key funzionano ancora con RLS, ma le delete possono sorprenderti se il ruolo che elimina non può “vedere” le righe dipendenti. Pianifica i cascade con attenzione e testa i flussi di delete reali.
Indicizza le colonne su cui le tue policy filtrano, specialmente org_id e le chiavi di membership. Una policy che pare WHERE org_id = ... non dovrebbe diventare una scansione completa della tabella quando questa raggiunge milioni di righe.
RLS è un interruttore per tabella. Una volta abilitata, PostgreSQL smette di fidarsi del codice dell'app per ricordare il filtro per il tenant. Ogni SELECT, UPDATE e DELETE viene filtrato dalle policy, e ogni INSERT e UPDATE è validato dalle policy.
Il cambiamento mentale più grande: con RLS attiva, le query che prima restituivano dati possono cominciare a restituire zero righe senza errori. È PostgreSQL che applica il controllo accessi.
Le policy sono piccole regole attaccate a una tabella. Usano due controlli:
USING è il filtro di lettura. Se una riga non corrisponde a USING, è invisibile per SELECT e non può essere target di UPDATE o DELETE.WITH CHECK è il cancello di scrittura. Decide quali righe nuove o modificate sono ammesse per INSERT o UPDATE.Un pattern SaaS comune: USING assicura che vedi solo righe del tuo tenant, e WITH CHECK assicura che non puoi inserire una riga nel tenant di qualcun altro indovinando un tenant ID.
Quando aggiungi più policy in seguito, questo conta:
PERMISSIVE (default): una riga è permessa se una qualsiasi policy la permette.RESTRICTIVE: una riga è permessa solo se tutte le policy restrictive la permettono (in aggiunta al comportamento permissive).Se prevedi di stratificare regole come corrispondenza del tenant più controlli di ruolo più appartenenza al progetto, le policy restrictive possono rendere l'intento più chiaro, ma rendono anche più facile bloccarsi fuori se dimentichi una condizione.
RLS ha bisogno di un valore affidabile di “chi sta chiamando”. Opzioni comuni:
app.user_id e app.tenant_id).SET ROLE ...) per richiesta, che può funzionare ma aggiunge overhead operativo.Scegline una e applicala ovunque. Mischiare fonti d'identità tra servizi è una strada veloce per bug confusi.
Usa una convenzione prevedibile così dump dello schema e log restano leggibili. Per esempio: {table}__{action}__{rule}, come projects__select__tenant_match.
Se sei nuovo alla RLS, inizia con una tabella e una piccola prova. L'obiettivo non è la copertura perfetta. L'obiettivo è far sì che il database rifiuti l'accesso cross-tenant anche se un bug dell'app lo causa.
Supponi una semplice tabella projects. Prima, aggiungi tenant_id in modo che non rompa le scritture.
ALTER TABLE projects ADD COLUMN tenant_id uuid;
-- Backfill existing rows (example: everyone belongs to a default tenant)
UPDATE projects SET tenant_id = '11111111-1111-1111-1111-111111111111'::uuid
WHERE tenant_id IS NULL;
ALTER TABLE projects ALTER COLUMN tenant_id SET NOT NULL;
Poi separa la proprietà dall'accesso. Un pattern comune è: un ruolo possiede le tabelle (app_owner), un altro ruolo è usato dall'API (app_user). Il ruolo API non dovrebbe essere il proprietario della tabella, altrimenti può bypassare le policy.
ALTER TABLE projects OWNER TO app_owner;
REVOKE ALL ON projects FROM PUBLIC;
GRANT SELECT, INSERT, UPDATE, DELETE ON projects TO app_user;
Ora decidi come la richiesta dica a Postgres quale tenant sta servendo. Un approccio semplice è un'impostazione scoped alla richiesta. La tua app la imposta subito dopo aver aperto una transazione.
-- inside the same transaction as the request
SELECT set_config('app.current_tenant', '22222222-2222-2222-2222-222222222222', true);
Abilita RLS e inizia con l'accesso in lettura.
ALTER TABLE projects ENABLE ROW LEVEL SECURITY;
CREATE POLICY projects_tenant_select
ON projects
FOR SELECT
TO app_user
USING (tenant_id = current_setting('app.current_tenant')::uuid);
Dimostra che funziona provando due tenant diversi e controllando che il conteggio delle righe cambi.
Le policy di lettura non proteggono le scritture. Aggiungi WITH CHECK così insert e update non possono contrabbandare righe nel tenant sbagliato.
CREATE POLICY projects_tenant_write
ON projects
FOR INSERT, UPDATE
TO app_user
WITH CHECK (tenant_id = current_setting('app.current_tenant')::uuid);
Un modo veloce per verificare il comportamento (inclusi i fallimenti) è tenere uno script SQL piccolo che puoi rieseguire dopo ogni migrazione:
BEGIN; SET LOCAL ROLE app_user;SELECT set_config('app.current_tenant', '\u003ctenant A\u003e', true); SELECT count(*) FROM projects;INSERT INTO projects(id, tenant_id, name) VALUES (gen_random_uuid(), '\u003ctenant B\u003e', 'bad'); (dovrebbe fallire)UPDATE projects SET tenant_id = '\u003ctenant B\u003e' WHERE ...; (dovrebbe fallire)ROLLBACK;Se puoi eseguire quello script e ottenere sempre gli stessi risultati, hai una baseline affidabile prima di espandere RLS ad altre tabelle.
La maggior parte dei team adotta RLS dopo essersi stancata di ripetere gli stessi controlli di autorizzazione in ogni query. La buona notizia è che gli schemi di policy di cui hai bisogno sono solitamente coerenti.
Alcune tabelle sono naturalmente possedute da un singolo utente (note, token API). Altre appartengono a un tenant dove l'accesso dipende dalla membership. Trattale come pattern diversi.
Per dati solo del proprietario, le policy spesso verificano created_by = app_user_id(). Per dati di tenant, le policy spesso controllano se l'utente ha una riga di membership per l'org.
Un modo pratico per mantenere le policy leggibili è centralizzare l'identità in piccole helper SQL e riutilizzarle:
-- Example helpers
create function app_user_id() returns uuid
language sql stable as $$
select current_setting('app.user_id', true)::uuid
$$;
create function app_is_admin() returns boolean
language sql stable as $$
select current_setting('app.is_admin', true) = 'true'
$$;
Le letture sono spesso più ampie delle scritture. Ad esempio, qualsiasi membro dell'org può SELECT i progetti, ma solo gli editor possono UPDATE, e solo i proprietari possono DELETE.
Mantieni esplicito: una policy per SELECT (membership), una policy per INSERT/UPDATE con WITH CHECK (ruolo), e una per DELETE (spesso più severa dell'update).
Evita di “disabilitare RLS per gli admin”. Invece, aggiungi un'uscita all'interno delle policy, tipo app_is_admin(), così non concedi inavvertitamente accesso totale a un ruolo di servizio condiviso.
Se usi deleted_at o status, inseriscili nella policy SELECT (deleted_at is null). Altrimenti, qualcuno può “resuscitare” righe cambiando flag che l'app assumevano definitivi.
WITH CHECK amichevoleINSERT ... ON CONFLICT DO UPDATE deve soddisfare WITH CHECK per la riga dopo la scrittura. Se la tua policy richiede created_by = app_user_id(), assicurati che l'upsert imposti created_by all'inserimento e non lo sovrascriva in update.
Se generi codice backend, questi pattern valgono la pena di essere trasformati in template interni così le nuove tabelle partono con default sicuri invece di uno schema vuoto.
RLS è ottima finché un piccolo dettaglio non la fa sembrare come se PostgreSQL stesse “nascondendo” o mostrando dati a caso. Gli errori sotto consumano la maggior parte del tempo.
La prima trappola è dimenticare WITH CHECK su insert e update. USING controlla cosa puoi vedere, non cosa sei autorizzato a creare o modificare. Senza WITH CHECK, un bug dell'app può scrivere una riga nel tenant sbagliato e potresti non notarlo perché lo stesso utente non può rileggere quella riga.
Un altro leak comune è la “join che perde dati”. Filtri corretti su projects, poi join a invoices, notes o files che non sono protette allo stesso modo. La correzione è severa ma lineare: ogni tabella che può rivelare dati di tenant ha bisogno della propria policy, e le viste non dovrebbero dipendere dal fatto che solo una tabella sia sicura.
Pattern di fallimento comuni emergono presto:
WITH CHECK per la scrittura.Policy che referenziano la stessa tabella (direttamente o tramite una vista) possono creare sorprese di ricorsione. Una policy potrebbe controllare la membership interrogando una vista che legge di nuovo la tabella protetta, portando a errori, query lente o a una policy che non corrisponde mai.
La configurazione dei ruoli è un'altra fonte di confusione. I proprietari di tabella e ruoli con privilegi elevati possono bypassare RLS, quindi i tuoi test passano mentre gli utenti reali falliscono (o il contrario). Testa sempre con lo stesso ruolo a basso privilegio che la tua app usa.
Fai attenzione con le funzioni SECURITY DEFINER. Esse eseguono con i privilegi del proprietario della funzione, quindi un helper come current_tenant_id() può andare bene, ma una funzione “di comodo” che legge dati può accidentalmente leggere tra tenant a meno che non sia progettata per rispettare RLS.
Imposta anche un search_path sicuro dentro le funzioni security definer. Altrimenti la funzione può trovare un oggetto con lo stesso nome in uno schema diverso e la logica della policy può puntare di nascosto alla cosa sbagliata a seconda dello stato della sessione.
I bug RLS solitamente derivano da contesto mancante, non da “SQL sbagliato”. Una policy può essere corretta sulla carta e comunque fallire perché il ruolo di sessione è diverso da quanto pensi, o perché la richiesta non ha impostato i valori tenant e user che la policy si aspetta.
Un modo affidabile per riprodurre un report di produzione è replicare lo stesso setup di sessione localmente ed eseguire la stessa query. Questo di solito significa:
SET ROLE app_user; (o il ruolo API reale)SELECT set_config('app.tenant_id', 't_123', true); e SELECT set_config('app.user_id', 'u_456', true);SELECT current_user, current_setting('app.tenant_id', true), current_setting('app.user_id', true);Quando non sei sicuro di quale policy venga applicata, controlla il catalogo invece di indovinare. pg_policies mostra ogni policy, il comando e le espressioni USING e WITH CHECK. Accoppialo con pg_class per confermare che RLS è abilitata sulla tabella e non viene bypassata.
I problemi di performance possono sembrare problemi di autorizzazione. Una policy che fa join a una tabella di membership o chiama una funzione può essere corretta ma lenta quando la tabella cresce. Usa EXPLAIN (ANALYZE, BUFFERS) sulla query riprodotta e cerca scansioni sequenziali, nested loop inattesi o filtri applicati tardi. Indici mancanti su (tenant_id, user_id) e sulle tabelle di membership sono cause comuni.
Aiuta anche loggare tre valori per richiesta nel layer app: tenant ID, user ID e ruolo database usato per la richiesta. Quando questi non corrispondono a quanto pensi di aver impostato, RLS si comporterà “male” perché gli input sono sbagliati.
Per i test, mantieni pochi tenant seedati e rendi i fallimenti espliciti. Una piccola suite di test tipicamente include: “Tenant A non può leggere Tenant B”, “utente senza membership non vede il progetto”, “owner può aggiornare, viewer no”, “insert bloccato a meno che tenant_id corrisponda al contesto” e “override admin solo dove previsto”.
Tratta RLS come una cintura di sicurezza, non come un interruttore. Piccoli errori si trasformano in “tutti vedono i dati di tutti” o “tutto restituisce zero righe”.
Assicurati che il progetto delle tabelle e le regole delle policy corrispondano al tuo modello di tenant.
tenant_id). Se non ce l'ha, scrivi perché (per esempio tabelle di riferimento globali).FORCE ROW LEVEL SECURITY su quelle tabelle.USING. Le scritture devono avere WITH CHECK così insert e update non possono spostare una riga in un altro tenant.tenant_id o fanno join tramite tabelle di membership, aggiungi gli indici corrispondenti.Uno scenario di sanità semplice: un utente del tenant A può leggere le proprie fatture, può inserire una fattura solo per il tenant A e non può aggiornare una fattura per cambiare tenant_id.
RLS è forte quanto i ruoli che la tua app usa.
bypassrls.Immagina un'app B2B dove aziende (orgs) hanno progetti e i progetti hanno task. Gli utenti possono appartenere a più org e un utente può essere membro di alcuni progetti ma non di altri. Questo è un buon caso per RLS perché il database può applicare l'isolamento dei tenant anche se un endpoint API dimentica un filtro.
Un modello semplice è: orgs, users, org_memberships (org_id, user_id, role), projects (id, org_id), project_memberships (project_id, user_id), tasks (id, project_id, org_id, ...). Quel org_id su tasks è intenzionale. Mantiene le policy semplici e riduce sorprese durante le join.
Un leak classico succede quando tasks ha solo project_id e la tua policy verifica l'accesso tramite una join a projects. Un singolo errore (una policy permissiva su projects, una join che rimuove una condizione, o una vista che cambia il contesto) può esporre task di un'altra org.
Un percorso di migrazione più sicuro evita di interrompere il traffico di produzione:
org_id a tasks, aggiungi tabelle di membership).tasks.org_id da projects.org_id, poi aggiungi NOT NULL.L'accesso di supporto è solitamente gestito meglio con un ruolo break-glass ristretto, non disabilitando RLS. Tienilo separato dagli account di supporto normali e rendi esplicito quando viene usato.
Documenta le regole così le policy non deraglino: quali variabili di sessione devono essere impostate (user_id, org_id), quali tabelle devono portare org_id, cosa significa essere “member” e qualche esempio SQL che dovrebbe restituire 0 righe se eseguito con l'org sbagliata.
RLS è più facile da gestire quando la tratti come una modifica di prodotto. Distribuiscila a piccoli blocchi, dimostra il comportamento con test e tieni un registro chiaro del perché ogni policy esiste.
Un piano di rollout che funziona spesso:
projects) e bloccala.Dopo che la prima tabella è stabile, rendi deliberati i cambi di policy. Aggiungi un passo di revisione delle policy alle migrazioni e includi una breve nota di intento (chi deve accedere a cosa e perché) più l'aggiornamento dei test corrispondente. Questo evita di “aggiungere solo un OR” che lentamente apre una falla.
Se ti muovi velocemente, strumenti come Koder.ai possono aiutarti a generare un punto di partenza Go + PostgreSQL tramite chat, e poi puoi stratificare policy RLS e test con la stessa disciplina di un backend costruito a mano.
Infine, mantieni salvaguardie durante il rollout. Prendi snapshot prima delle migrazioni di policy, esercita il rollback finché non diventa routine e tieni una piccola via break-glass per il supporto che non disabiliti RLS su tutto il sistema.
RLS fa sì che PostgreSQL applichi quali righe sono visibili o scrivibili per una richiesta, così l'isolamento dei tenant non dipende dal fatto che ogni endpoint ricordi la corretta clausola WHERE tenant_id = .... Il vantaggio principale è ridurre i bug dovuti a “un controllo dimenticato” quando l'app cresce e le query si moltiplicano.
Vale la pena quando le regole di accesso sono coerenti e basate sulle righe, ad esempio l'isolamento per tenant o l'accesso basato sull'appartenenza, e quando ci sono molte vie di interrogazione (ricerche, esportazioni, pannelli admin, job in background). Di solito non conviene se le regole sono per campo, ricche di eccezioni, o quando prevalgono reportistica ampia che richiede letture cross-tenant.
Usa RLS per la visibilità delle righe e il controllo base sulle scritture, poi usa altri strumenti per il resto. La privacy delle colonne tipicamente richiede viste e privilegi sulle colonne, e regole aziendali complesse (per esempio proprietà di fatturazione o flussi di approvazione) restano nella logica dell'app o in vincoli di database progettati con cura.
Crea un ruolo a basso privilegio per l'API (non il proprietario della tabella), abilita RLS, poi aggiungi una policy SELECT e una policy INSERT/UPDATE con WITH CHECK. Imposta un valore di sessione per richiesta (per esempio app.current_tenant) e verifica che cambiare quel valore modifichi quali righe puoi vedere e scrivere.
Una pratica comune è una variabile di sessione per richiesta, impostata all'inizio della transazione, come app.tenant_id e app.user_id. L'importante è la coerenza: ogni percorso di codice (richieste web, job, script) deve impostare gli stessi valori che le policy si aspettano, altrimenti otterrai il confuso comportamento di “zero righe”.
USING controlla quali righe esistenti sono visibili e targetabili per SELECT, UPDATE e DELETE. WITH CHECK controlla quali righe nuove o modificate sono permesse durante INSERT e , così si impedisce di "scrivere in un altro tenant" anche se l'app passa un sbagliato.
Se aggiungi solo USING, un endpoint difettoso può comunque inserire o aggiornare righe nel tenant sbagliato, e potresti non accorgertene perché lo stesso utente non può leggere la riga errata. Abbina sempre le regole di lettura del tenant a una corrispondente regola WITH CHECK per le scritture in modo che non si possano creare dati sbagliati.
Evita join dentro le policy mettendo la chiave tenant (per esempio org_id) direttamente sulle tabelle possedute dal tenant, anche se fanno riferimento ad un'altra tabella che la contiene. Aggiungi tabelle esplicite di membership (org_memberships, opzionalmente project_memberships) così le policy possono fare una sola lookup indicizzata invece di inferenze complicate.
Riproduci prima il contesto di sessione che la tua app usa impostando lo stesso ruolo e le stesse impostazioni di sessione, poi esegui la stessa query SQL. Conferma anche che RLS è abilitato e ispeziona pg_policies per vedere quali espressioni USING e WITH CHECK sono applicate, perché spesso i fallimenti di RLS dipendono da un contesto d'identità mancante e non da SQL sbagliato.
Sì, ma tratta il codice generato come punto di partenza, non come un sistema di sicurezza completo. Se usi Koder.ai per generare un backend Go + PostgreSQL, devi comunque definire il tuo modello di tenant, impostare l'identità di sessione in modo coerente e aggiungere policy e test deliberatamente così che nuove tabelle non vengano rilasciate senza le protezioni corrette.
UPDATEtenant_id