17 dic 2025·7 min
Pooling connessioni PostgreSQL: pooling in-app vs PgBouncer
Pooling delle connessioni in PostgreSQL: confronta pool in-app e PgBouncer per backend Go, metriche da monitorare e configurazioni errate che scatenano picchi di latenza.
Pooling delle connessioni in PostgreSQL: confronta pool in-app e PgBouncer per backend Go, metriche da monitorare e configurazioni errate che scatenano picchi di latenza.
Una connessione al database è come una linea telefonica tra la tua app e Postgres. Aprirne una costa tempo e risorse su entrambi i lati: setup TCP/TLS, autenticazione, memoria e un processo backend sul lato Postgres. Un connection pool mantiene aperto un piccolo insieme di queste “linee telefoniche” così la tua app può riutilizzarle invece di ristabilire la connessione per ogni richiesta.
Quando il pooling è disattivato o dimensionato male, raramente vedi un errore netto per primo. Vedi lentezza casuale. Richieste che normalmente impiegano 20–50 ms all'improvviso ne impiegano 500 ms o 5 secondi, e il p95 schizza. Poi compaiono timeout, seguiti da “too many connections”, o una coda dentro l'app mentre aspetta una connessione libera.
I limiti di connessione contano anche per app piccole perché il traffico è a raffiche. Una mail di marketing, un cron job o qualche endpoint lento possono far sì che decine di richieste colpiscano il DB nello stesso istante. Se ogni richiesta apre una nuova connessione, Postgres può spendere molta capacità solo ad accettare e gestire connessioni invece di eseguire query. Se hai già un pool ma è troppo grande, puoi sovraccaricare Postgres con troppi backend attivi e generare context switching e pressione sulla memoria.
Fai attenzione ai sintomi precoci come:
Il pooling riduce il churn delle connessioni e aiuta Postgres a gestire i burst. Non risolverà SQL lenti. Se una query sta facendo una scansione completa della tabella o aspetta lock, il pooling cambia per lo più il modo in cui il sistema fallisce (queueing prima, timeout dopo), non se è veloce.
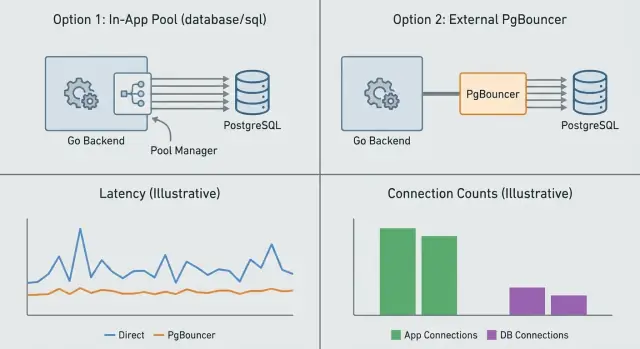
Il connection pooling serve a controllare quante connessioni al database esistono contemporaneamente e come vengono riutilizzate. Puoi farlo dentro l'app (app-level pooling) o con un servizio separato davanti a Postgres (PgBouncer). Risolvono problemi correlati ma diversi.
Il pooling a livello di app (in Go, di solito il pool built-in di database/sql) gestisce le connessioni per processo. Decide quando aprire una nuova connessione, quando riutilizzarne una e quando chiudere quelle inattive. Questo evita di pagare il costo di setup per ogni richiesta. Quello che non può fare è coordinarsi fra più istanze dell'app. Se esegui 10 repliche, hai effettivamente 10 pool separati.
PgBouncer si mette fra la tua app e Postgres e fa pooling per conto di molti client. È più utile quando hai molte richieste di breve durata, molte istanze dell'app o traffico a raffiche. Limita le connessioni server verso Postgres anche se arrivano centinaia di client contemporaneamente.
Una divisione semplice delle responsabilità:
Possono lavorare insieme senza problemi di “double pooling” purché ogni livello abbia uno scopo chiaro: un sensato database/sql pool per processo Go, più PgBouncer per far rispettare un budget globale di connessioni.
Una confusione comune è pensare “più pool significa più capacità.” Di solito vuol dire il contrario. Se ogni servizio, worker e replica ha un pool grande, il conteggio totale delle connessioni può esplodere e causare queueing, context switching e picchi improvvisi di latenza.
database/sql di GoIn Go, sql.DB è un gestore di pool di connessioni, non una singola connessione. Quando chiami db.Query o db.Exec, database/sql cerca di riutilizzare una connessione idle. Se non ci riesce, può aprirne una nuova (fino al tuo limite) o mettere la richiesta in attesa.
Quell'attesa è spesso l'origine della “latenza misteriosa”. Quando il pool è saturato, le richieste fanno coda dentro l'app. Dall'esterno sembra che Postgres sia lento, ma il tempo è in realtà speso aspettando una connessione libera.
La maggior parte della messa a punto si riduce a quattro impostazioni:
MaxOpenConns: limite rigido sulle connessioni aperte (idle + in uso). Quando lo raggiungi, le chiamate bloccano.MaxIdleConns: quante connessioni possono restare pronte per il riuso. Troppo basso causa reconnect frequenti.ConnMaxLifetime: forza il riciclo periodico delle connessioni. Utile per load balancer e timeout NAT, ma troppo basso crea churn.ConnMaxIdleTime: chiude connessioni inutilizzate da troppo tempo.Il riuso delle connessioni di solito abbassa la latenza e la CPU del DB perché eviti setup ripetuti (TCP/TLS, auth, inizializzazione della sessione). Ma un pool sovradimensionato può fare il contrario: permette più query concorrenti di quante Postgres possa gestire bene, aumentando contesa e overhead.
Pensa ai totali, non per processo. Se ogni istanza Go permette 50 connessioni aperte e scala a 20 istanze, hai effettivamente permesso 1.000 connessioni. Confronta quel numero con quanto il tuo server Postgres può effettivamente gestire.
Un punto di partenza pratico è legare MaxOpenConns alla concorrenza attesa per istanza, poi validare con metriche di pool (in-use, idle e wait time) prima di aumentarlo.
PgBouncer è un piccolo proxy tra la tua app e PostgreSQL. Il servizio si connette a PgBouncer, e PgBouncer mantiene un numero limitato di connessioni reali verso Postgres. Durante i picchi, PgBouncer mette in coda il lavoro dei client invece di creare immediatamente più backend Postgres. Quella coda può fare la differenza tra un rallentamento controllato e un database che va in tilt.
PgBouncer ha tre modalità di pooling:
Il session pooling si comporta più come connessioni dirette a Postgres. È il meno sorprendente, ma risparmia meno connessioni server durante carichi bursty.
Per le API HTTP tipiche in Go, la transaction pooling è spesso un buon default. La maggior parte delle richieste esegue una piccola query o una breve transazione, poi termina. La transaction pooling permette a molte connessioni client di condividere un budget di connessioni Postgres più piccolo.
Il compromesso è lo stato di sessione. In transaction mode, tutto ciò che presuppone che una singola connessione server rimanga assegnata può rompersi o comportarsi in modo strano, inclusi:
SET, SET ROLE, search_path)Se la tua app dipende da questo tipo di stato, il session pooling è più sicuro. Lo statement pooling è il più restrittivo e raramente adatto alle web app.
Una regola utile: se ogni richiesta può impostare ciò che serve dentro una singola transazione, la transaction pooling tende a mantenere la latenza più stabile sotto carico. Se hai bisogno di comportamento di sessione a lungo termine, usa session pooling e concentra i limiti più rigidi nell'app.
Se gestisci un servizio Go con database/sql, hai già il pooling lato app. Per molte squadre questo è sufficiente: poche istanze, traffico stabile e query non estremamente spike. In quel contesto, la scelta più semplice e sicura è ottimizzare il pool Go, mantenere realistico il limite delle connessioni al database e fermarti lì.
PgBouncer aiuta soprattutto quando il database viene colpito da troppe connessioni client contemporanee. Questo si manifesta con molte istanze dell'app (o scaling in stile serverless), traffico a raffiche e molte query brevi.
PgBouncer può anche essere dannoso se usato nella modalità sbagliata. Se il tuo codice dipende da stato di sessione (tabelle temporanee, prepared statement riusati tra richieste, advisory lock tenuti tra chiamate o impostazioni di sessione), la transaction pooling può causare fallimenti confusi. Se hai veramente bisogno del comportamento di sessione, usa session pooling o evita PgBouncer e dimensiona con cura i pool delle app.
Usa questa regola empirica:
max open connections potrebbe superare ciò che Postgres può gestire, aggiungi PgBouncer.I limiti di connessione sono un budget. Se lo spendi tutto in una volta, ogni nuova richiesta aspetta e la tail latency salta. L'obiettivo è limitare la concorrenza in modo controllato mantenendo il throughput.
Misura i picchi odierni e la latenza ai tail. Registra le connessioni attive di picco (non le medie), più p50/p95/p99 per le richieste e le query chiave. Nota eventuali errori di connessione o timeout.
Imposta un budget sicuro di connessioni Postgres per l'app. Parti da max_connections e sottrai spazio per accesso admin, migrazioni, job in background e spike. Se più servizi condividono il DB, dividi il budget intenzionalmente.
Mappa il budget ai limiti Go per istanza. Dividi il budget dell'app per il numero di istanze e imposta MaxOpenConns su quel valore (o leggermente più basso). Imposta MaxIdleConns abbastanza alto da evitare reconnect costanti e imposta lifetimes così le connessioni si riciclano occasionalmente senza churn.
Aggiungi PgBouncer solo se serve e scegli una modalità. Usa session pooling se ti serve stato di sessione. Usa transaction pooling quando vuoi la maggiore riduzione delle connessioni server e la tua app è compatibile.
Distribuisci gradualmente e confronta prima e dopo. Cambia una cosa alla volta, fai canary, poi confronta latenza ai tail, tempo di attesa del pool e CPU del DB.
Esempio: se Postgres può concedere in sicurezza 200 connessioni al tuo servizio e hai 10 istanze Go, parti con MaxOpenConns=15-18 per istanza. Questo lascia spazio per i burst e riduce la probabilità che ogni istanza colpisca il tetto simultaneamente.
I problemi di pooling raramente si mostrano prima come “too many connections.” Più spesso vedi una lenta crescita del tempo di attesa e poi un salto improvviso di p95 e p99.
Parti da ciò che l'app Go riporta. Con database/sql monitora open connections, in-use, idle, wait count e wait time. Se il wait count cresce mentre il traffico è stabile, il pool è sottodimensionato o le connessioni vengono trattenute troppo a lungo.
Dal lato database, traccia connessioni attive vs max, CPU e attività di lock. Se la CPU è bassa ma la latenza è alta, spesso è queueing o lock, non capacità di calcolo.
Se usi PgBouncer, aggiungi una terza visuale: client connections, server connections verso Postgres e profondità della coda. Una coda crescente con server connections stabili è un segno chiaro che il budget è saturo.
Buoni segnali di alert:
I problemi di pooling spesso si manifestano durante i burst: le richieste si accumulano in attesa di una connessione, poi tutto torna normale. La causa radice è spesso un'impostazione ragionevole su una singola istanza ma pericolosa quando si eseguono molte copie del servizio.
Cause comuni:
MaxOpenConns impostato per istanza senza un budget globale. 100 connessioni per istanza su 20 istanze sono 2.000 connessioni potenziali.ConnMaxLifetime / ConnMaxIdleTime impostati troppo bassi. Questo può scatenare reconnect storms quando molte connessioni si riciclano contemporaneamente.Un modo semplice per ridurre i picchi è trattare il pooling come un limite condiviso, non un default locale all'app: limita le connessioni totali tra tutte le istanze, mantieni un pool idle modesto e usa lifetimes abbastanza lunghi da evitare reconnect sincronizzati.
Quando il traffico esplode, di solito vedi uno di tre esiti: le richieste fanno coda aspettando una connessione libera, le richieste fanno timeout, oppure tutto rallenta così tanto che i retry si accumulano.
Il queueing è il più subdolo. Il tuo handler è ancora in esecuzione, ma è parcheggiato in attesa di una connessione. Quell'attesa diventa parte del tempo di risposta, quindi un pool piccolo può trasformare una query da 50 ms in un endpoint di più secondi sotto carico.
Un modello mentale utile: se il tuo pool ha 30 connessioni utilizzabili e improvvisamente hai 300 richieste concorrenti che necessitano del DB, 270 di esse devono aspettare. Se ogni richiesta tiene la connessione per 100 ms, la latenza ai tail sale rapidamente a secondi.
Imposta un chiaro budget di timeout e rispettalo. Il timeout dell'app dovrebbe essere leggermente più corto del timeout del database così fallisci velocemente e riduci la pressione invece di lasciare il lavoro appeso.
statement_timeout così una query cattiva non può occupare le connessioni per semprePoi aggiungi backpressure per non sovraccaricare il pool in primo luogo. Scegli uno o due meccanismi prevedibili, come limitare la concorrenza per endpoint, scartare traffico con errori chiari (es. 429) o separare job in background dal traffico utente.
Infine, risolvi prima le query lente. Sotto pressione di pooling, le query lente tengono le connessioni più a lungo, il che aumenta le attese, i timeout e i retry. Quello è il loop che trasforma “un po' lente” in “tutto è lento”.
Tratta i load test come un modo per validare il tuo budget di connessioni, non solo throughput. L'obiettivo è confermare che il pooling si comporta sotto pressione come in staging.
Testa con traffico realistico: stesso mix di richieste, pattern di burst e lo stesso numero di istanze dell'app che usi in produzione. I benchmark su “un solo endpoint” spesso nascondono i problemi di pool fino al giorno del lancio.
Includi un warm-up così non misuri cache fredde ed effetti di ramp-up. Lascia che i pool raggiungano la loro dimensione normale, poi inizia a registrare i numeri.
Se confronti strategie, mantieni il carico identico e esegui:
database/sql, senza PgBouncer)Dopo ogni run, registra una piccola scheda di valutazione che puoi riusare dopo ogni rilascio:
Col tempo questo trasforma la capacity planning in qualcosa di ripetibile invece che in un azzardo.
Prima di toccare le dimensioni dei pool, scrivi un numero: il tuo connection budget. È il numero massimo sicuro di connessioni Postgres attive per questo ambiente (dev, staging, prod), inclusi job in background e accesso admin. Se non sai dirlo, stai facendo supposizioni.
Una checklist rapida:
MaxOpenConns) rientri nel budget (o nel cap di PgBouncer).max_connections e eventuali connessioni riservate siano allineate col tuo piano.Piano di rollout che rende il rollback facile:
Se stai costruendo e ospitando un'app Go + PostgreSQL su Koder.ai (koder.ai), Planning Mode può aiutarti a mappare la modifica e cosa misurerai, e snapshot più rollback rendono più semplice revertare se la tail latency peggiora.
Passo successivo: aggiungi una misura prima del prossimo salto di traffico. “Tempo trascorso in attesa di una connessione” nell'app è spesso la più utile, perché mostra pressione del pooling prima che gli utenti la percepiscano.
Un pool mantiene un piccolo insieme di connessioni PostgreSQL aperte e le riutilizza tra le richieste. Questo evita di pagare ripetutamente il costo di setup (TCP/TLS, autenticazione, creazione del backend), aiutando a mantenere la latenza ai tail sotto controllo durante i picchi.
Quando il pool è saturato, le richieste aspettano dentro la tua app che si liberi una connessione e quel tempo di attesa si manifesta come risposte lente. Spesso sembra una “lentezza casuale” perché le medie possono restare buone mentre p95/p99 schizzano durante i burst di traffico.
No. Il pooling cambia soprattutto il comportamento sotto carico riducendo il churn delle connessioni e controllando la concorrenza. Se una query è lenta per scansioni, lock o indicizzazione scarsa, il pooling non la renderà veloce; può solo limitare quante query lente possono girare contemporaneamente.
Il pooling a livello di app gestisce connessioni per processo, quindi ogni istanza dell'app ha il proprio pool e i propri limiti. PgBouncer si pone davanti a Postgres ed applica un budget di connessioni globale tra molti client, utile specialmente con molte repliche o traffico a raffiche.
Se hai poche istanze e le connessioni totali restano ben entro il limite del database, sintonizzare il pool di database/sql in Go di solito basta. Aggiungi PgBouncer quando molte istanze, autoscaling o traffico bursty potrebbero far superare il numero di connessioni che Postgres può gestire.
Imposta prima un budget totale di connessioni per il servizio, dividilo per il numero di istanze e imposta MaxOpenConns leggermente al di sotto di quel valore per istanza. Parti basso, osserva il tempo di attesa del pool e p95/p99, e aumenta solo se sei sicuro che il database abbia margine.
Per le API HTTP tipiche, la transaction pooling è spesso una buona scelta perché permette a molte connessioni client di condividere meno connessioni server e rimane stabile durante i picchi. Usa session pooling se il tuo codice dipende dallo stato di sessione che deve persistere tra le query.
Prepared statement, tabelle temporanee, advisory lock e impostazioni di sessione possono comportarsi diversamente perché il client potrebbe non riavere sempre la stessa connessione server. Se serve questo comportamento, tieni tutto dentro una singola transazione per richiesta o passa a session pooling.
Monitora p95/p99 insieme al tempo di attesa del pool nell'app, perché il tempo di attesa spesso cresce prima che gli utenti si accorgano del problema. Su Postgres controlla connessioni attive, CPU e lock; su PgBouncer controlla client connections, server connections e profondità della coda per vedere se stai saturando il budget.
Imposta limiti di timeout chiari: deadline per le richieste e statement_timeout in DB così una query lenta non blocca le connessioni per sempre. Aggiungi backpressure limitando la concorrenza o restituendo errori di carico (es. 429) e riduci il churn evitando lifetimes di connessione troppo corti che causano storm di reconnect.