27 ago 2025·8 min
Pool di worker in Go per lavori in background: ritentativi, cancellazione e spegnimento pulito
I pool di worker in Go aiutano i team piccoli a eseguire lavori in background con ritentativi, cancellazione e spegnimento pulito usando pattern semplici prima di aggiungere infrastrutture pesanti.
Perché i lavori in background diventano rapidamente complicati
In un piccolo servizio Go, il lavoro in background di solito inizia con un obiettivo semplice: restituire la risposta HTTP in fretta e poi fare le operazioni lente dopo. Potrebbe trattarsi di inviare email, ridimensionare immagini, sincronizzare con un'altra API, ricostruire indici di ricerca o generare report notturni.
Il problema è che questi job sono lavoro di produzione reale, ma privi dei dispositivi di protezione che ottieni naturalmente nella gestione delle richieste. Una goroutine avviata da un handler HTTP sembra andare bene finché non arriva un deploy a metà attività, una API upstream rallenta o la stessa richiesta viene ritentata e innesca il job due volte.
I primi punti dolenti sono prevedibili:
- Job bloccati: una chiamata si impalla e i worker smettono di fare progressi.
- Lavoro duplicato: i retry a livello HTTP rilanciano lo stesso job.
- Nessun piano di shutdown: il processo esce e il lavoro va perso o resta a metà.
- Fallimenti silenziosi: gli errori vengono loggati una volta (o per niente) e spariscono.
- Tempeste di retry: i job che falliscono vengono ritentati istantaneamente e sovraccaricano le dipendenze.
Qui entra in gioco un pattern piccolo e esplicito come un pool di worker in Go. Ti permette di scegliere la concorrenza (N worker), trasformare “fa questo dopo” in un tipo di job chiaro e avere un unico posto per gestire retry, timeout e cancellazione.
Esempio: un'app SaaS deve inviare fatture. Non vuoi 500 invii simultanei dopo un import di massa, e non vuoi rinviare la stessa fattura perché una richiesta è stata ritentata. Un pool di worker ti permette di limitare il throughput e trattare “invia la fattura #123” come un'unità di lavoro tracciata.
Un pool di worker non è lo strumento giusto quando hai bisogno di garanzie durature e cross-process. Se i job devono sopravvivere ai crash, essere schedulati per il futuro o essere processati da più servizi, probabilmente avrai bisogno di una coda reale più uno storage persistente per lo stato dei job.
Il modello del worker pool in parole semplici
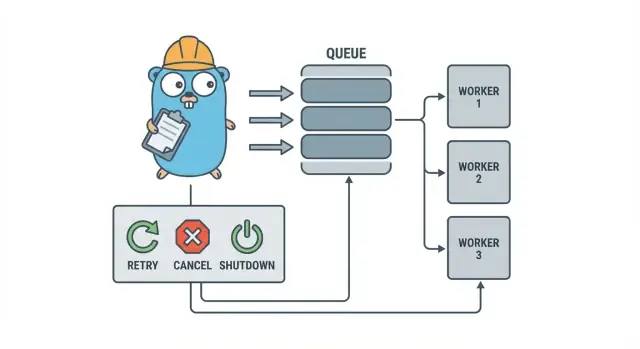
Un pool di worker in Go è deliberatamente noioso: metti il lavoro in una coda, hai un set fisso di worker che la consumano e ti assicuri che tutto possa fermarsi in modo pulito.
I termini di base:
- Job: una unità di lavoro, come “ridimensiona questa immagine” o “invia questa email di fattura”.
- Coda: dove i job aspettano.
- Worker: una goroutine che prende ripetutamente un job ed esegue il lavoro.
- Dispatcher: la parte che accetta i job e li inserisce nella coda.
In molti design in-process, un canale Go è la coda. Un canale buffered può contenere un numero limitato di job prima che i producer si blocchino. Quel blocco è backpressure ed è spesso ciò che impedisce al servizio di accettare lavoro illimitato e consumare tutta la memoria quando il traffico schizza.
La dimensione del buffer cambia la sensazione del sistema. Un buffer piccolo rende la pressione visibile rapidamente (i chiamanti aspettano prima). Un buffer più grande smussa i picchi brevi ma può nascondere il sovraccarico finché non è troppo tardi. Non esiste un numero perfetto, solo un numero che corrisponde a quanto attesa puoi tollerare.
Puoi anche scegliere se la dimensione del pool è fissa o può cambiare. I pool fissi sono più facili da capire e mantengono l'uso delle risorse prevedibile. I worker auto-scalanti possono aiutare con carichi irregolari, ma aggiungono decisioni da mantenere (quando scalare, di quanto, e quando scalare giù).
Infine, in un pool in-process "ack" di solito significa semplicemente “il worker ha finito il job e non ha restituito errore”. Non c'è un broker esterno che confermi la consegna, quindi il tuo codice definisce cosa significa “fatto” e cosa succede quando un job fallisce o viene cancellato.
Obiettivi di progetto: retry, cancellazione e shutdown pulito
Un pool di worker è semplice meccanicamente: esegui un numero fisso di worker, nutrili con job e processali. Il valore è il controllo: concorrenza prevedibile, gestione degli errori chiara e una strada di shutdown che non lascia lavoro a metà.
Tre obiettivi tengono i team piccoli ragionevoli:
- Limitare la concorrenza così un picco non brucia il database o un'API esterna.
- Evitare di perdere lavoro (o almeno sapere esattamente cosa è stato scartato e perché).
- Rimanere debuggabili: ogni job dovrebbe essere tracciabile tramite log e qualche contatore.
La maggior parte dei fallimenti è noiosa, ma vuoi comunque trattarli diversamente:
- Errori transitori (problemi di rete, limiti di rate) che dovrebbero essere ritentati.
- Errori permanenti (input non valido, record mancante) che non dovrebbero essere ritentati.
- Timeout (una dipendenza si impalla) che devono essere interrotti per non intasare i worker.
La cancellazione non è la stessa cosa dell’“errore”. È una decisione: un utente ha annullato, un deploy ha sostituito il processo o il servizio sta per spegnersi. In Go, tratta la cancellazione come un segnale di prima classe usando context cancellation e assicurati che ogni job lo controlli prima di iniziare lavoro costoso e in alcuni punti sicuri durante l'esecuzione.
Lo shutdown pulito è dove molti pool falliscono. Decidi presto cosa significa “sicuro” per i tuoi job: termini il lavoro in corso o ti fermi rapidamente e lo riesegui dopo? Un flusso pratico è:
- Smettere di accettare nuovi job.
- Dire ai worker di fermarsi dopo il job in corso (o fermarsi subito).
- Aspettare fino a una scadenza, poi forzare l'uscita.
Se definisci queste regole in anticipo, retry, cancellazione e shutdown restano piccoli e prevedibili anziché trasformarsi in un framework casalingo.
Passo dopo passo: costruire un worker pool di base
Un worker pool è solo un gruppo di goroutine che prendono job da un canale ed eseguono lavoro. La parte importante è rendere le basi prevedibili: come è fatto un job, come i worker si fermano e come sai quando tutto il lavoro è terminato.
Inizia con un tipo Job semplice. Dagli un ID (per i log), un payload (cosa processare), un contatore di tentativi (utile poi per i retry), timestamp e un posto per memorizzare dati di contesto per job.
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := \u00026Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i \u0003c size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case \u0003c-p.ctx.Done():
return
case job, ok := \u0003c-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case \u0003c-p.ctx.Done():
return context.Canceled
case p.jobs \u0003c- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
Alcune scelte pratiche che farai subito:
- Scegli una dimensione della coda in base a quanto attesa puoi tollerare.
- Decidi cosa significa backpressure per i caller: bloccare, restituire un errore o scartare.
- Mantieni
Stop()eWait()separati così puoi fermare prima l'ingresso, poi aspettare che il lavoro in corso finisca.
Aggiungere i retry senza trasformarlo in un framework
I retry sono utili, ma sono anche il punto dove i pool si complicano. Mantieni l'obiettivo ristretto: ritenta solo quando un altro tentativo ha una reale possibilità di successo e fermati rapidamente quando non è così.
Inizia decidendo cosa è retryable. I problemi temporanei (hickup di rete, timeout, risposte “riprovare più tardi”) valgono generalmente un retry. Quelli permanenti (input errato, record mancante, permessi negati) no.
Una policy di retry piccola è solitamente sufficiente:
- Marca gli errori come retryable o non retryable (per esempio, wrapparli con un helper
Retryable(err)). - Imposta un numero massimo di tentativi (spesso 3–5). Oltre quello, di solito stai solo sprecando tempo.
- Usa un backoff esponenziale con jitter così i job non ritentano all'unisono.
- Limita il delay (per esempio, non dormire mai più di 30 secondi).
- Logga i retry con numero di tentativo, prossimo ritardo e job ID.
Il backoff non deve essere complicato. Una forma comune è: delay = min(base * 2^(attempt-1), max), poi aggiungi jitter (randomizza di +/- 20%). Il jitter è importante perché altrimenti molti worker falliscono e ritentano insieme.
Dove vive il delay? Per sistemi piccoli, dormire all'interno del worker va bene, ma occupa uno slot worker. Se i retry sono rari, è accettabile. Se sono comuni o i ritardi sono lunghi, considera di reinserire il job con un timestamp “run after” così i worker restano occupati con altro lavoro.
Alla fine, sul fallimento definitivo, sii esplicito. Conserva il job fallito (e l'ultimo errore) per la revisione, logga abbastanza contesto per rieseguirlo, o mettilo in una dead list che controlli regolarmente. Evita scarti silenziosi. Un pool che nasconde i fallimenti è peggiore di non avere retry.
Cancellazione e timeout che fermano veramente il lavoro
Prototipa una pipeline per job di fatturazione
Genera la pipeline da paid a invoice e il loop worker da una singola specifica.
I pool di worker sono sicuri solo quando puoi fermarli. La regola più semplice è: passa un context.Context attraverso ogni layer che possa bloccarsi. Questo vale per submission, esecuzione e cleanup.
Una configurazione pratica usa due limiti temporali:
- Un timeout per job così un singolo task non può occupare un worker per sempre.
- Un timeout di shutdown così il processo può uscire anche se alcuni job non collaborano.
Usa il context end-to-end
Dai a ogni job un proprio context derivato dal context del worker. Poi ogni chiamata lenta (DB, HTTP, code, I/O su file) deve usare quel context così può ritornare prima.
func worker(ctx context.Context, jobs \u0003c-chan Job) {
for {
select {
case \u0003c-ctx.Done():
return
case job, ok := \u0003c-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
Se Run chiama il DB o un'API, passa il context a quelle chiamate (per esempio, QueryContext, NewRequestWithContext o metodi client che accettano context). Se lo ignori in un punto, la cancellazione diventa “best effort” e di solito fallisce quando ne hai più bisogno.
Lavoro parziale e passi "sicuri da ritentare"
La cancellazione può avvenire a metà job, quindi considera il lavoro parziale come normale. Punta a passi idempotenti così le riesecuzioni non creano duplicati. Approcci comuni includono usare chiavi uniche per gli insert (o upsert), scrivere marker di progresso (started/done), salvare i risultati prima di continuare e controllare ctx.Err() tra i passi.
Tratta lo shutdown come una scadenza: smetti di accettare nuovi job, cancella i context dei worker e aspetta solo fino al timeout di shutdown per far uscire i job in corso.
Shutdown pulito: cosa fare quando il processo deve uscire
Uno shutdown pulito ha un compito: smettere di prendere nuovo lavoro, dire al lavoro in corso di fermarsi e uscire senza lasciare il sistema in uno stato strano.
Inizia con i segnali. Nella maggior parte dei deploy vedrai SIGINT in locale e SIGTERM dal process manager o runtime di container. Usa un shutdown context che viene cancellato quando arriva un segnale e passalo al pool e agli handler dei job.
Poi, smetti di accettare nuovi job. Non lasciare i caller bloccati per sempre cercando di inviare su un canale che nessuno legge più. Tieni le submission dietro una singola funzione che controlla un flag di chiusura o seleziona sul shutdown context prima di inviare.
Quindi decidi cosa succede alla coda:
- Svuotare (Drain): finire quello che è già in coda, ma rifiutare nuove submission.
- Scartare (Drop): scartare tutto quello che non è ancora iniziato.
Il draining è più sicuro per cose come pagamenti ed email. Lo scarto va bene per task “belli da avere” come ricomputare una cache.
Una sequenza pratica di shutdown:
- Cattura SIGINT/SIGTERM e cancella un context condiviso.
- Ferma le submission (chiudi il percorso di submit, non necessariamente il canale di lavoro).
- Lascia che i worker finiscano o abortiscano in base al context.
- Aspetta i worker con una WaitGroup.
- Applica una scadenza, poi esci.
La scadenza è importante. Per esempio, dai ai job in corso 10 secondi per fermarsi. Dopo ciò, logga cosa è ancora in esecuzione ed esci. Questo rende i deploy prevedibili ed evita processi bloccati.
Logging e metriche semplici per i worker pool
Pianifica la tua strategia di retry
Mappa prima le regole di retry e backoff, poi fai costruire a Koder.ai il job runner.
Quando un worker pool si rompe, raramente fallisce rumorosamente. I job rallentano, i retry si accumulano e qualcuno segnala che “non succede nulla”. Logging e qualche contatore di base trasformano questo in una storia chiara.
Dai a ogni job un ID stabile (o generane uno al submit) e includilo in ogni riga di log. Mantieni i log coerenti: una riga quando un job inizia, una quando finisce e una quando fallisce. Se ritenti, logga il numero di tentativo e il prossimo delay.
Una forma di log semplice:
- start: job_id, worker_id, attempt, kind
- finish: job_id, worker_id, attempt, duration_ms
- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
Le metriche possono rimanere minime e comunque pagare. Traccia lunghezza della coda, job in-flight, successi totali e fallimenti, e latenza dei job (almeno media e max). Se la lunghezza della coda continua a salire e gli in-flight restano al numero di worker, sei saturo. Se i submitter si bloccano inviando nel canale jobs, il backpressure sta raggiungendo il chiamante. Non è sempre male, ma deve essere una scelta deliberata.
Quando “i job sono bloccati”, controlla se il processo sta ancora ricevendo job, se la lunghezza della coda cresce, se i worker sono vivi e quali job stanno girando da più tempo. I runtime lunghi di solito indicano timeout mancanti, dipendenze lente o un loop di retry che non si ferma.
Un esempio realistico: una piccola coda background per una SaaS
Immagina una piccola SaaS dove un ordine diventa PAID. Subito dopo il pagamento devi inviare un PDF della fattura, mandare un'email al cliente e notificare il team interno. Non vuoi che questo lavoro blocchi la richiesta web. Questo è un buon caso per un worker pool perché il lavoro è reale ma il sistema è ancora piccolo.
Il payload del job può essere minimale: quanto basta per recuperare il resto dal database. L'handler API scrive una riga come jobs(status='queued', type='send_invoice', payload, attempts=0) nella stessa transazione dell'aggiornamento dell'ordine, poi un loop in background pollerà i job in coda e li spingerà nel canale dei worker.
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
Quando un worker lo prende, il percorso felice è semplice: carica l'ordine, genera la fattura, chiama il provider email e poi marca il job come completato.
I retry sono dove la cosa diventa seria. Se il provider email ha un outage temporaneo, non vuoi che 1.000 job falliscano per sempre o martellino il provider ogni secondo. Un approccio pratico è:
- Tratta errori di rete e risposte 5xx come retryable.
- Usa backoff esponenziale con un delay massimo (per esempio: 5s, 15s, 45s, 2m).
- Limita i tentativi (per esempio, 10) e poi marca il job come failed.
- Registra l'ultimo errore così il supporto può vedere cosa è successo.
Durante l'outage, i job passano da queued a in_progress e poi tornano a queued con un tempo di esecuzione futuro. Quando il provider si riprende, i worker drenano naturalmente il backlog.
Ora immagina un deploy. Invi un SIGTERM. Il processo dovrebbe smettere di prendere nuovo lavoro ma finire quello già in corso. Smetti di fare polling, smetti di inserire nel canale dei worker e aspetta i worker con una scadenza. I job che finiscono vengono marcati come done. I job ancora in esecuzione quando la scadenza scade dovrebbero essere rimessi in queued (o lasciati in progress con un watchdog) così possono essere ripresi quando la nuova versione parte.
Errori comuni e trappole
La maggior parte dei bug nel background processing non sono nella logica del job. Vengono da errori di coordinamento che emergono solo sotto carico o durante lo shutdown.
Una trappola classica è chiudere un canale da più posti. Il risultato è un panic difficile da riprodurre. Scegli un solo owner per ogni canale (di solito il producer) e fallo essere l'unico a chiamare close(jobs).
I retry sono un'altra area dove le buone intenzioni causano outage. Se ritenti tutto, ritenterai anche i fallimenti permanenti. Questo spreca tempo, aumenta il carico e può trasformare un piccolo problema in un incidente. Classifica gli errori e limita i retry con una policy chiara.
I duplicati accadono anche con un design attento. I worker possono crashare a metà job, un timeout può scattare dopo che il lavoro è finito o puoi reinserire durante il deploy. Se il job non è idempotente, i duplicati causano danni reali: due fatture, due email di benvenuto, due rimborsi.
Gli errori che emergono più spesso:
- Chiudere lo stesso canale da più goroutine.
- Ritentare fallimenti permanenti invece di segnalarli.
- Nessuna chiave di idempotenza, quindi i duplicati provocano effetti collaterali doppi.
- Code in memoria non limitate che crescono fino a un picco di memoria.
- Ignorare
context.Context, così il lavoro continua dopo che lo shutdown è iniziato.
Le code non limitate sono particolarmente subdole. Un picco di lavoro può accumularsi in RAM. Preferisci un buffer del canale limitato e decidi cosa succede quando si riempie: bloccare, scartare o restituire un errore.
Checklist rapida prima del rilascio
Costruisci lo spegnimento pulito in Go
Crea gestione dei segnali e timeout con context in pochi minuti da un prompt di chat.
Prima di mandare un worker pool in produzione, dovresti essere in grado di descrivere a voce il lifecycle del job. Se qualcuno chiede “dove si trova adesso questo job?”, la risposta non dovrebbe essere un'ipotesi.
Una checklist pratica pre-lancio:
- Sai nominare ogni stato e transizione: queued, picked up, running, finished, failed (e cosa li muove).
- La concorrenza è un'unica manopola (come
workerCount) e cambiarla non richiede riscrivere il codice. - I retry sono limitati: max attempts sono chiari, il backoff cresce e il fallimento permanente va in un posto intenzionale.
- Il comportamento di shutdown è provato: smetti di prendere lavoro, lasci finire i job in corso e hai comunque un timeout hard.
- I log rispondono alle basi: job ID, numero di tentativo, durata e motivo dell'errore.
Esegui una prova realistica prima del rilascio: metti in coda 100 job “invia email ricevuta”, forza 20 a fallire, poi riavvia il servizio a metà esecuzione. Dovresti vedere i retry comportarsi come previsto, nessun effetto collaterale duplicato e la cancellazione interrompere davvero il lavoro quando scade il tempo.
Se qualche punto è vago, raffinalo ora. Piccole correzioni qui salvano giorni dopo.
Passi successivi: quando aggiungere infrastrutture più pesanti (e quando no)
Un pool in-process semplice è spesso sufficiente mentre il prodotto è giovane. Se i tuoi job sono "belli da avere" (inviare email, aggiornare cache, generare report) e puoi rieseguirli, un worker pool mantiene il sistema semplice da capire.
Segnali che hai superato un pool in-process
Osserva questi punti di pressione:
- Esegui più istanze dell'app e vuoi che solo una di esse prenda un job.
- Hai bisogno di durabilità (i job devono sopravvivere a crash e deploy).
- Hai bisogno di una traccia di audit: chi ha messo in coda cosa, quando è stato eseguito e il risultato esatto.
- Hai bisogno di controlli di backpressure tra servizi, non solo dentro un processo.
- Hai bisogno di scheduling rigoroso o lunghi ritardi (ore o giorni) con risveglio affidabile.
Se nessuno di questi è vero, strumenti più pesanti possono aggiungere più parti mobili che valore.
Migrare gradualmente senza riscrivere tutto
La migliore copertura è un'interfaccia di job stabile: un payload piccolo, un ID e un handler che ritorna un risultato chiaro. Così puoi cambiare il backend della coda più tardi (da un canale in memoria a una tabella DB e poi a una coda dedicata) senza toccare la logica di business.
Un passo intermedio pratico è un piccolo servizio Go che legge job da PostgreSQL, li claimma con un lock e aggiorna lo stato. Ottieni durabilità e audit di base mantenendo la stessa logica dei worker.
Se vuoi prototipare velocemente, Koder.ai (koder.ai) può generare uno starter Go + PostgreSQL da un prompt di chat, includendo una tabella di background jobs e un loop worker, e i suoi snapshot e rollback possono aiutare mentre sistemi retry e comportamento di shutdown.