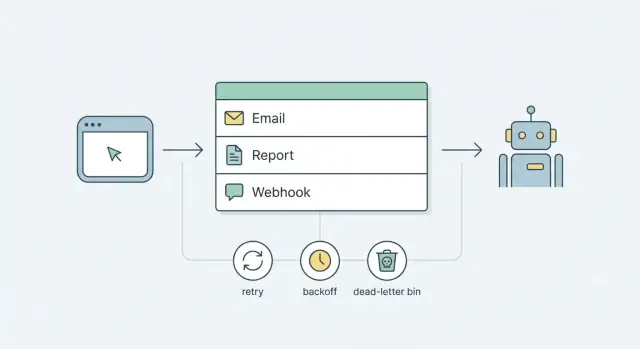
Perché servono i lavori in background (e perché si complicano in fretta)
Qualsiasi lavoro che può richiedere più di uno o due secondi non dovrebbe essere eseguito all'interno di una richiesta utente. Inviare email, generare report e consegnare webhook dipendono da reti, servizi di terze parti o query lente. A volte si bloccano, falliscono o impiegano più tempo del previsto.
Se fai quel lavoro mentre l'utente aspetta, la gente se ne accorge subito. Le pagine si bloccano, i pulsanti "Salva" girano e le richieste scadono. Anche i retry possono avvenire nel posto sbagliato. L'utente aggiorna, il load balancer ritenta, o il frontend invia di nuovo, e ti ritrovi con email duplicate, chiamate webhook duplicate o due esecuzioni di report in competizione.
I lavori in background risolvono questo mantenendo le richieste piccole e prevedibili: accetta l'azione, registra un job da eseguire più tardi, rispondi rapidamente. Il job viene eseguito fuori dalla richiesta, con regole che controlli tu.
La parte difficile è l'affidabilità. Quando il lavoro si sposta fuori dal percorso della richiesta, devi comunque rispondere a domande come:
- E se il provider email è giù per 3 minuti?
- E se un endpoint webhook restituisce 500 o va in timeout?
- E se il job viene eseguito due volte?
- Come noti i job bloccati prima che gli utenti si lamentino?
Molti team rispondono aggiungendo “infrastruttura pesante”: un message broker, flotte di worker separate, dashboard, alert e playbook. Quegli strumenti sono utili quando servono davvero, ma aggiungono anche nuove parti che si muovono e nuovi modi in cui qualcosa può fallire.
Un obiettivo migliore da cui partire è più semplice: job affidabili usando parti che già possiedi. Per la maggior parte dei prodotti significa una coda basata su database più un piccolo processo worker. Aggiungi una strategia chiara di retry e backoff e un pattern dead-letter per i job che continuano a fallire. Ottieni un comportamento prevedibile senza impegnarti fin da subito in una piattaforma complessa.
Anche se stai costruendo rapidamente con uno strumento chat-driven come Koder.ai, questa separazione è comunque importante. Gli utenti dovrebbero ricevere una risposta veloce ora, e il sistema dovrebbe completare il lavoro lento e soggetto a errori in sicurezza in background.
Che cos'è una coda, in termini semplici
Una coda è una fila d'attesa per il lavoro. Invece di fare compiti lenti o inaffidabili durante una richiesta utente (inviare un'email, costruire un report, chiamare un webhook), metti un piccolo record in una coda e rispondi rapidamente. Più tardi, un processo separato prende quel record e svolge il lavoro.
Alcune parole che vedrai spesso:
- Job: un'unità di lavoro, come "invia email di benvenuto all'utente 123".
- Worker: il codice che prende i job e li esegue.
- Attempt: un tentativo di eseguire un job.
- Schedule: quando il job dovrebbe essere eseguito (ora o più tardi).
- Queue: dove i job aspettano finché un worker non li prende.
Il flusso più semplice è così:
-
Enqueue: la tua app salva una riga job (tipo, payload, orario di esecuzione).
-
Claim: un worker trova il prossimo job disponibile e lo "blocca" così solo un worker lo esegue.
-
Run: il worker svolge il compito (invia, genera, consegna).
-
Finish: lo marca come completato, o registra un fallimento e imposta il prossimo orario di esecuzione.
Se il volume di job è contenuto e hai già un database, una coda basata su database spesso è sufficiente. È facile da capire, facile da fare debug e copre esigenze comuni come l'elaborazione di email e la consegna affidabile di webhook.
Le piattaforme di streaming diventano sensate quando hai bisogno di altissimo throughput, molti consumer indipendenti o la capacità di riprodurre grandi storie di eventi su molti sistemi. Se gestisci dozzine di servizi con milioni di eventi all'ora, strumenti come Kafka possono aiutare. Fino ad allora, una tabella di database più un loop worker copre molti casi reali.
I dati minimi che dovresti tracciare per ogni job
Una coda su database rimane gestibile solo se ogni record job risponde rapidamente a tre domande: cosa fare, quando riprovare e cosa è successo l'ultima volta. Se lo fai bene, le operazioni diventano noiose (che è l'obiettivo).
Cosa mettere nel payload (e cosa no)
Memorizza l'input minimo necessario per eseguire il lavoro, non l'output completamente renderizzato. Buoni payload sono ID e pochi parametri, come { "user_id": 42, "template": "welcome" }.
Evita di memorizzare grandi blob (email HTML complete, grandi dati di report, grandi corpi webhook). Fanno crescere il database più velocemente e complicano il debug. Se il job ha bisogno di un documento grande, memorizza invece un riferimento: report_id, export_id o una chiave file. Il worker potrà recuperare i dati completi quando esegue il job.
I campi che si ripagano da soli
Al minimo, lascia spazio per:
- job_type + payload:
job_type seleziona l'handler (send_email, generate_report, deliver_webhook). payload contiene input piccoli come ID e opzioni.
- status: tienilo esplicito (per esempio:
queued, running, succeeded, failed, dead).
- tracciamento tentativi:
attempt_count e max_attempts così puoi smettere di riprovare quando chiaramente non funzionerà.
- campi temporali:
created_at e next_run_at (quando diventa eleggibile). Aggiungi started_at e finished_at se vuoi una migliore visibilità sui job lenti.
- idempotency + last error: una
idempotency_key per prevenire doppi effetti, e last_error così puoi vedere perché ha fallito senza scavare tra i log.
L'idempotenza sembra elegante, ma l'idea è semplice: se lo stesso job viene eseguito due volte, la seconda esecuzione dovrebbe rilevarlo e non fare nulla di pericoloso. Per esempio, un job di consegna webhook può usare una chiave di idempotenza come webhook:order:123:event:paid così non consegni lo stesso evento due volte se un retry si sovrappone a un timeout.
Cattura anche pochi numeri di base fin da subito. Non ti serve una grande dashboard per iniziare, solo query che ti dicono: quanti job sono in coda, quanti stanno fallendo e l'età del job più vecchio in coda.
Passo dopo passo: una semplice coda su database che puoi costruire oggi
Se hai già un database, puoi iniziare una coda in background senza aggiungere nuova infrastruttura. I job sono righe, e un worker è un processo che continua a prendere le righe dovute e fare il lavoro.
1) Crea una tabella jobs
Mantieni la tabella piccola e semplice. Vuoi abbastanza campi per eseguire, riprovare e fare debug dei job più tardi.
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued',
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
Se stai costruendo su Postgres (comune nei backend Go), jsonb è un modo pratico per memorizzare i dati del job come { "user_id":123,"template":"welcome" }.
2) Enqueue in modo sicuro (soprattutto per azioni utente)
Quando un'azione utente deve scatenare un job (inviare un'email, scatenare un webhook), scrivi la riga job nella stessa transazione di database della modifica principale quando possibile. Questo evita il caso "utente creato ma job mancante" se il sistema va in crash subito dopo la scrittura principale.
Esempio: quando un utente si registra, inserisci la riga utente e un job send_welcome_email in un'unica transazione.
3) Esegui un loop worker che può scalare
Un worker ripete lo stesso ciclo: trova un job dovuto, lo reclama così nessun altro lo prende, lo processa, poi lo marca come fatto o programma un retry.
Nella pratica, questo significa:
- Prendi un job dove
status='queued' e next_run_at <= now().
- Reclama il job in modo atomico (in Postgres,
SELECT ... FOR UPDATE SKIP LOCKED è un approccio comune).
- Imposta
status='running', locked_at=now(), locked_by='worker-1'.
- Processa il job.
- Marchialo come completato (per esempio
done/succeeded), o registra last_error e programma il tentativo successivo.
Più worker possono girare contemporaneamente. Il passo di claim è ciò che previene la doppia esecuzione.
4) Gestisci lo shutdown senza rompere i job
Al termine, smetti di prendere nuovi job, finisci quello corrente, poi esci. Se un processo muore a metà job, usa una regola semplice: tratta i job bloccati su running oltre un timeout come eleggibili per essere rimesi in coda da un task periodico "reaper".
Se stai costruendo in Koder.ai, questo pattern di coda su database è un default solido per email, report e webhook prima di aggiungere servizi di coda specializzati.
Retry e backoff che non creano caos
Experiment without fear
Capture a snapshot before changes so you can roll back if a release spikes failures.
I retry sono come una coda rimane calma quando il mondo reale è scostante. Senza regole chiare, i retry diventano un loop rumoroso che spamma utenti, martella API e nasconde il bug reale.
Inizia decidendo cosa deve essere riprovato e cosa deve fallire subito.
Riprova problemi temporanei: timeout di rete, errori 502/503, rate limit o un breve problema di connessione al database.
Fallisci subito quando il job non riuscirà: indirizzo email mancante, risposta 400 da un webhook perché il payload è invalido, o una richiesta di report per un account cancellato.
Il backoff è la pausa tra i tentativi. Il backoff lineare (5s, 10s, 15s) è semplice, ma può comunque creare ondate di traffico. Il backoff esponenziale (5s, 10s, 20s, 40s) distribuisce meglio il carico ed è di solito più sicuro per webhook e provider di terze parti. Aggiungi jitter (un piccolo ritardo casuale) così mille job non riprovano esattamente nello stesso secondo dopo un'interruzione.
Regole che tendono a comportarsi bene in produzione:
- Riprova solo su errori chiaramente temporanei (timeout, 429, 5xx).
- Usa backoff esponenziale con jitter.
- Limita i tentativi, poi ferma e marca il job come fallito.
- Imposta un timeout per tentativo così i worker non si bloccano.
- Rendi ogni job idempotente così i retry non creano duplicati.
Il numero massimo di tentativi serve a limitare i danni. Per molti team, 5–8 tentativi sono sufficienti. Dopo di che, smetti di riprovare e parcheggia il job per revisione (flow dead-letter) invece di lasciare un loop infinito.
I timeout prevengono job "zombie". Le email possono avere timeout di 10–20 secondi per tentativo. I webhook spesso richiedono limiti più brevi, come 5–10 secondi, perché il ricevitore potrebbe essere giù e vuoi andare avanti. La generazione di report può permettersi minuti, ma dovrebbe comunque avere un cutoff fisso.
Se stai costruendo questo in Koder.ai, tratta should_retry, next_run_at e una chiave di idempotenza come campi di prima classe. Questi piccoli dettagli mantengono il sistema silenzioso quando qualcosa va storto.
Dead-letter handling e operazioni semplici
Lo stato dead-letter è dove vanno i job quando i retry non sono più sicuri o utili. Trasforma il fallimento silenzioso in qualcosa che puoi vedere, cercare e su cui agire.
Cosa salvare su un job dead-letter
Salva abbastanza per capire cosa è successo e per riprodurre il job senza indovinare, ma fai attenzione ai segreti.
Tieni:
- Gli input del job (payload) esattamente come usati, più il tipo di job e la versione
- L'ultimo messaggio di errore e una breve traccia dello stack (o un codice errore se non hai stack)
- Conteggio tentativi, ora del primo run, ora dell'ultimo run e next_run_at (se era schedulato)
- L'identità del worker (nome del servizio, host) e un correlation ID per i log
- Una ragione dead-letter (timeout, validation error, 4xx dal vendor, ecc.)
Se il payload include token o dati personali, redattali o cifrali prima di salvare.
Un workflow di triage semplice
Quando un job arriva in dead-letter, prendi una decisione rapida: retry, fix o ignore.
Retry è per outage esterni e timeout. Fix è per dati errati (email mancante, URL webhook sbagliato) o un bug nel codice. Ignore dovrebbe essere raro, ma può essere valido quando il job non è più rilevante (per esempio il cliente ha cancellato l'account). Se ignori, registra una ragione così non sembra che il job sia svanito.
Il requeue manuale è più sicuro quando crea un nuovo job e mantiene quello vecchio immutabile. Marca il job dead-letter con chi lo ha rimeso in coda, quando e perché, poi enqueurane una copia nuova con un nuovo ID.
Per gli alert, guarda segnali che solitamente indicano dolore reale: conteggio dead-letter in crescita rapida, lo stesso errore che si ripete su molti job, e job vecchi in coda che non vengono reclamati.
Se usi Koder.ai, snapshot e rollback possono aiutare quando una release sbagliata fa impennare i fallimenti, perché puoi tornare indietro rapidamente mentre indaghi.
Infine, aggiungi valvole di sicurezza per outage dei vendor. Limita gli invii per provider e usa un circuit breaker: se un endpoint webhook fallisce pesantemente, sospendi i nuovi tentativi per una finestra breve così non inondi i loro server (e i tuoi).
Pattern per email, report e webhook
Ship the request-job split
Generate a React and Go app that keeps requests fast and moves slow work to workers.
Una coda funziona meglio quando ogni tipo di job ha regole chiare: cosa conta come successo, cosa va riprovato e cosa non deve mai succedere due volte.
Email. La maggior parte dei fallimenti email è temporanea: timeout del provider, rate limit o brevi interruzioni. Trattali come ri-tryabili, con backoff. Il rischio maggiore sono gli invii duplicati, quindi rendi i job email idempotenti. Memorizza una chiave di dedup stabile come user_id + template + event_id e rifiuta l'invio se quella chiave è già segnata come inviata.
Vale anche la pena di memorizzare il nome del template e la versione (o un hash del subject/body renderizzato). Se devi rieseguire job, puoi scegliere se rinviare lo stesso contenuto o rigenerarlo dall'ultimo template. Se il provider restituisce un message ID, salvalo così il supporto può tracciare cosa è successo.
Report. I report falliscono in modo diverso. Possono impiegare minuti, incontrare limiti di paginazione o esaurire la memoria se fai tutto in un colpo. Dividi il lavoro in pezzi più piccoli. Un pattern comune è: un job "report request" crea molti job "page" (o "chunk"), ciascuno che elabora una fetta di dati.
Memorizza i risultati per il download successivo invece di tenere l'utente in attesa. Questo può essere una tabella DB indicizzata da report_run_id, o un riferimento file più metadata (status, row count, created_at). Aggiungi campi di progresso così l'UI può mostrare "processing" vs "ready" senza indovinare.
Webhooks. I webhook riguardano l'affidabilità della consegna, non la velocità. Firma ogni richiesta (per esempio HMAC con un segreto condiviso) e includi un timestamp per prevenire replay. Riprova solo quando il ricevente potrebbe avere successo più tardi.
Un semplice insieme di regole:
- Riprova su timeout e risposte 5xx, usando backoff e un limite di tentativi.
- Tratta la maggior parte dei 4xx come fallimenti permanenti e smetti di riprovare.
- Registra l'ultimo codice di stato e un breve corpo di risposta per il debug.
- Usa una chiave di idempotenza così i riceventi possono ignorare i duplicati in sicurezza.
- Limita la dimensione del payload e registra cosa hai effettivamente inviato.
Ordinamento e priorità. La maggior parte dei job non richiede un ordinamento rigoroso. Quando l'ordine conta, di solito è per chiave (per utente, per fattura, per endpoint webhook). Aggiungi un group_key ed esegui un solo job in volo per chiave.
Per la priorità, separa il lavoro urgente da quello lento. Un backlog di report grandi non dovrebbe ritardare le email di reset password.
Esempio: dopo un acquisto, enqueuerai (1) un'email di conferma ordine, (2) un webhook al partner, e (3) un job di aggiornamento report. L'email può riprovare rapidamente, il webhook riprova più a lungo con backoff, e il report viene eseguito più tardi a bassa priorità.
Un esempio realistico: flusso di signup più webhook più report notturno
Un utente si registra alla tua app. Tre cose dovrebbero succedere, ma nessuna di esse dovrebbe rallentare la pagina di registrazione: inviare un'email di benvenuto, notificare il CRM con un webhook e includere l'utente nel report notturno di attività.
Cosa viene messo in coda al momento della registrazione
Subito dopo aver creato il record utente, scrivi tre righe job nella tua coda database. Ogni riga ha un tipo, un payload (come user_id), uno status, un conteggio tentativi e un timestamp next_run_at.
Un ciclo di vita tipico è:
queued: creato e in attesa di un workerrunning: un worker lo ha reclamatosucceeded: fatto, nessun altro lavorofailed: fallito, schedulato per più tardi o esauriti i retrydead: fallito troppe volte e necessita attenzione umana
Il job email di benvenuto include una chiave di idempotenza come welcome_email:user:123. Prima di inviare, il worker controlla una tabella di chiavi idempotenti completate (o applica una constraint unica). Se il job viene eseguito due volte a causa di un crash, la seconda esecuzione vede la chiave e salta l'invio. Niente doppie email di benvenuto.
Un fallimento e come si riprende
Ora l'endpoint CRM webhook è giù. Il job webhook fallisce con un timeout. Il tuo worker programma un retry usando backoff (per esempio: 1 minuto, 5 minuti, 30 minuti, 2 ore) più un po' di jitter così molti job non riprovano nello stesso secondo.
Dopo i tentativi massimi, il job diventa dead. L'utente si è comunque registrato, ha ricevuto l'email di benvenuto e il job report notturno può eseguire normalmente. Solo la notifica al CRM resta bloccata ed è visibile.
La mattina dopo, il supporto (o chi è on call) può gestirla senza scavare tra i log per ore:
- Filtra i job dead per tipo (per esempio
webhook.crm).
- Legge l'ultimo messaggio di errore e conferma che il payload sembra corretto.
- Verifica che il CRM sia tornato su.
- Requeuea il job (dead -> queued, reset attempts) o disabilita temporaneamente quella destinazione.
Se costruisci app su una piattaforma come Koder.ai, lo stesso pattern si applica: mantieni il flusso utente veloce, sposta gli effetti collaterali nei job e rendi i fallimenti facili da ispezionare e rieseguire.
Errori comuni che rendono le code inaffidabili
Generate a Go worker loop
Ask Koder.ai to generate a Go worker with safe job claiming and timeouts.
Il modo più veloce per rompere una coda è trattarla come opzionale. I team spesso iniziano con "invio l'email nella richiesta questa volta" perché sembra più semplice. Poi si diffonde: reset password, ricevute, webhook, export report. Presto l'app sembra lenta, i timeout aumentano e qualsiasi problema di terze parti diventa il tuo outage.
Un'altra trappola comune è saltare l'idempotenza. Se un job può essere eseguito due volte, non deve creare due risultati. Senza idempotenza, i retry si trasformano in email duplicate, eventi webhook ripetuti o peggio.
Un terzo problema è la visibilità. Se impari dei fallimenti solo dai ticket di supporto, la coda sta già danneggiando gli utenti. Anche una vista interna di base che mostra i conteggi dei job per stato più last_error ricercabile risparmia tempo.
Killer di affidabilità da tenere d'occhio
Alcuni problemi emergono presto, anche in code semplici:
- Riprovare immediatamente dopo un fallimento. Se un provider è giù, retry rapidi creano un picco di traffico tuo.
- Mescolare job lenti con job urgenti. Un report da 10 minuti può bloccare un messaggio di verifica email.
- Trattare gli errori come temporanei per sempre. I job che non riusciranno mai continuano a ciclicare e nascondono problemi veri.
- Nessuna ownership delle versioni del payload. Se cambi la forma del job, i job vecchi possono iniziare a fallire.
- Ignorare i rate limit. Le code possono inondare provider che ti throttleranno.
Il backoff previene outage auto-inflitti. Anche una semplice schedule come 1 minuto, 5 minuti, 30 minuti, 2 ore rende il fallimento più sicuro. Imposta anche un limite massimo di tentativi così un job rotto si ferma e diventa visibile.
Se costruisci su una piattaforma come Koder.ai, è utile spedire queste basi insieme alla feature stessa, non settimane dopo come progetto di pulizia.
Checklist rapida e prossimi passi
Prima di aggiungere altri strumenti, assicurati che le basi siano solide. Una coda su database funziona bene quando ogni job è facile da reclamare, da riprovare e da ispezionare.
Una checklist rapida di affidabilità:
- Ogni job ha: id, tipo, payload, status, attempts, max_attempts, run_at/next_run_at e last_error.
- I worker reclamano i job in modo sicuro (un worker prende un job) e recuperano dopo i crash (lock timeout + reaper).
- Ogni job ha un timeout chiaro così il lavoro bloccato diventa retryable invece di rimanere appeso per sempre.
- I retry sono limitati e il ritardo cresce (backoff) per evitare il fenomeno del thundering herd.
- C'è uno stato dead-letter (o una tabella) più un modo chiaro per rieseguire o scartare i job.
Poi, scegli i tuoi primi tre tipi di job e scrivi le loro regole. Per esempio: email reset password (retry rapidi, max brevi), report notturno (pochi retry, timeout più lunghi), consegna webhook (più retry, backoff più lungo, stop sui 4xx permanenti).
Se non sei sicuro quando una coda su database smette di essere sufficiente, guarda segnali come contesa a livello di riga dovuta a molti worker, esigenze rigide di ordinamento tra molti tipi di job, grande fan-out (un evento che genera migliaia di job) o consumo cross-service dove team diversi gestiscono worker diversi.
Se vuoi un prototipo veloce, puoi disegnare il flusso in Koder.ai (koder.ai) usando la planning mode, generare la tabella jobs e il loop worker, e iterare con snapshot e rollback prima del deploy.