Perché le modifiche allo schema causano outage
Il downtime dovuto a una modifica al database non è sempre un'interruzione netta e ovvia. Per gli utenti può sembrare una pagina che si carica all'infinito, un checkout che fallisce o un'app che improvvisamente mostra "qualcosa è andato storto". Per i team si traduce in alert, aumento degli errori e un arretrato di scritture fallite da ripulire.
Le modifiche allo schema sono rischiose perché il database è condiviso da tutte le versioni dell'app in esecuzione. Durante un rilascio spesso coesistono codice vecchio e nuovo (deploy rolling, più istanze, job in background). Una migrazione che sembra corretta può comunque rompere una di quelle versioni.
I modi comuni in cui si fallisce includono:
- Il codice nuovo scrive in una colonna che non esiste ancora, causando errori immediati.
- Il codice vecchio legge una colonna o una tabella che una migrazione ha rinominato o eliminato, causando crash dopo il deploy.
- Un backfill o la creazione di un indice fa impennare la CPU o blocca righe, rallentando le richieste normali o facendo andare in timeout.
- Un cambiamento “rapido” di vincoli (come NOT NULL) blocca le scritture mentre la tabella viene controllata.
Anche quando il codice è a posto, i rilasci si bloccano perché il problema reale è il timing e la compatibilità tra le versioni. Le modifiche senza downtime si riducono a una regola: ogni stato intermedio deve essere sicuro sia per il codice vecchio che per quello nuovo. Si cambia il database senza rompere letture e scritture esistenti, si pubblica codice che può gestire entrambe le forme e si rimuove il percorso vecchio solo quando nulla dipende più da esso.
Lo sforzo extra vale la pena quando hai traffico reale, SLA stringenti o molte istanze e worker. Per uno strumento interno minuscolo con un DB tranquillo, una finestra di manutenzione pianificata può essere più semplice.
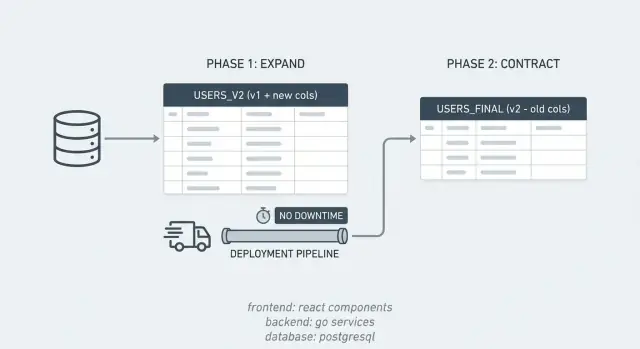
Expand/contract in parole semplici
La maggior parte degli incidenti dovuti al lavoro sul database succede perché l'app si aspetta che il database cambi all'istante, mentre la modifica al database richiede tempo. Il pattern expand/contract evita questo spezzando una modifica rischiosa in passi più piccoli e sicuri.
Per un breve periodo il sistema supporta due “dialetti” contemporaneamente. Introduci prima la nuova struttura, mantieni attiva quella vecchia, sposti i dati gradualmente e poi pulisci.
Il pattern è semplice:
- Expand: aggiungi ciò che ti serve (colonne, tabelle, indici) senza rompere l'app corrente.
- Esegui entrambe le strade: distribuisci codice che funziona con la struttura vecchia e con quella nuova così le versioni miste si comportano correttamente.
- Contract: una volta che tutto usa la nuova struttura, rimuovi lo schema vecchio e il codice legacy.
Questo si integra bene con i deploy rolling. Se aggiorni 10 server uno alla volta, per un attimo eseguirai vecchie e nuove versioni insieme. Expand/contract mantiene entrambe compatibili con lo stesso database durante quella sovrapposizione.
Rende anche i rollback meno spaventosi. Se una release ha un bug, puoi tornare indietro con l'app senza rollare anche il database, perché le strutture vecchie esistono ancora durante la finestra di expand.
Esempio: vuoi dividere una colonna PostgreSQL full_name in first_name e last_name. Aggiungi le nuove colonne (expand), pubblichi codice che può leggere e scrivere entrambe le forme, backfilli le righe vecchie, poi elimini full_name quando sei certo che nessuno lo usi più (contract).
Cosa include di solito l'"expand"
La fase di expand serve ad aggiungere nuove opzioni, non a rimuovere quelle vecchie.
Una mossa comune è aggiungere una nuova colonna. In PostgreSQL, di solito è più sicuro aggiungerla come nullable e senza default. Aggiungere una colonna non-null con default può causare un rewrite della tabella o lock più pesanti, a seconda della versione di Postgres e della modifica esatta. Una sequenza più sicura è: aggiungi nullable, distribuisci codice tollerante, backfill, poi applica NOT NULL più tardi.
Anche gli indici richiedono attenzione. Creare un indice normale può bloccare le scritture più a lungo del previsto. Quando possibile, usa la creazione concorrente (CONCURRENTLY) così letture e scritture continuano a fluire. Ci vuole più tempo, ma evita lock che fermano i rilasci.
Expand può anche significare aggiungere nuove tabelle. Se stai passando da una singola colonna a una relazione molti-a-molti, potresti aggiungere una tabella di join mantenendo la colonna vecchia al suo posto. Il percorso vecchio continua a funzionare mentre la nuova struttura inizia a raccogliere dati.
In pratica, expand include spesso:
- Aggiungere nuove colonne nullable o nuove tabelle affiancate a quelle esistenti
- Aggiungere indici in modo non bloccante quando possibile
- Usare feature flag per controllare quando attivare nuove letture/scritture
- Scrivere sia nei campi vecchi che in quelli nuovi (dual-write) quando necessario
- Mantenere le letture retrocompatibili (vecchio, nuovo o fallback)
Dopo l'expand, versioni vecchie e nuove dell'app dovrebbero poter girare contemporaneamente senza sorprese.
Distribuire codice che rimane compatibile
La maggior parte dei problemi di rilascio succede a metà strada: alcuni server eseguono codice nuovo, altri ancora il vecchio, mentre il database sta già cambiando. L'obiettivo è semplice: ogni versione durante il rollout deve funzionare con lo schema vecchio e con quello espanso.
Un approccio comune è il dual-write. Se aggiungi una nuova colonna, la nuova app scrive sia nella colonna vecchia sia in quella nuova. Le versioni vecchie continuano a scrivere solo sulla vecchia, che esiste ancora. Mantieni la nuova colonna opzionale all'inizio e rimanda i vincoli stringenti finché tutti i writer non sono stati aggiornati.
Le letture di solito si cambiano con più cautela rispetto alle scritture. Per un po', mantieni le letture sulla colonna vecchia (quella che sai essere popolata). Dopo il backfill e la verifica, passa a preferire la nuova colonna con un fallback sulla vecchia se la nuova è assente.
Mantieni stabile anche l'output delle API mentre il database cambia sotto il cofano. Anche se introduci un campo interno nuovo, evita di cambiare la forma delle risposte finché tutti i consumer (web, mobile, integrazioni) non sono pronti.
Un rollout favorevole al rollback spesso appare così:
- Release 1: aggiungi la nuova colonna e distribuisci codice che legge i dati vecchi e scrive in entrambe le colonne.
- Release 2: backfill delle righe esistenti, poi distribuisci codice che preferisce leggere la nuova colonna ma può ricadere sulla vecchia.
- Release 3: smetti di scrivere nella colonna vecchia (ma mantienila presente).
- Release 4: rimuovi le letture vecchie, poi elimina la colonna vecchia.
L'idea chiave è che il primo passo irreversibile è eliminare la struttura vecchia, quindi lo si posticipa fino alla fine.
Backfill dei dati in sicurezza (senza sovraccaricare il DB)
Il backfill è dove molte “migrazioni senza downtime” falliscono. Vuoi popolare la nuova colonna per le righe esistenti senza lock lunghi, query lente o picchi imprevisti di carico.
Il batching è importante. Punta a batch che si completano in fretta (secondi, non minuti). Se ogni batch è piccolo, puoi mettere in pausa, riprendere e regolare il job senza bloccare i rilasci.
Per tracciare il progresso, usa un cursore stabile. In PostgreSQL spesso è la primary key. Processa le righe in ordine e memorizza l'ultimo id completato, o lavora per range di id. Questo evita scansioni costose della tabella completa quando il job viene riavviato.
Ecco un pattern semplice:
UPDATE my_table
SET new_col = ...
WHERE new_col IS NULL
AND id > $last_id
ORDER BY id
LIMIT 1000;
Rendi l'update condizionale (per esempio WHERE new_col IS NULL) così il job è idempotente. Le riesecuzioni toccano solo le righe che ancora necessitano lavoro, riducendo scritture inutili.
Prevedi i nuovi dati che arrivano durante il backfill. L'ordine usuale è:
- Aggiorna prima il codice applicativo così le nuove scritture popolano anche il nuovo campo.
- Backfilla le righe storiche a batch.
- Esegui un breve ciclo di catch-up che ricontrolla le righe recenti.
- Se necessario, aggiungi una guardia (come un trigger o un default) per prevenire nuovi NULL.
Un buon backfill è noioso: costante, misurabile e facile da mettere in pausa se il database si riscalda.
Verificare che la migrazione sia davvero completata
Il momento più rischioso non è aggiungere la nuova colonna. È decidere di potersi fidare di essa.
Prima di passare al contract, dimostra due cose: i nuovi dati sono completi e la produzione li sta leggendo in sicurezza.
Inizia con controlli di completezza veloci e ripetibili:
- Conferma che la nuova colonna non abbia NULL inattesi.
- Confronta quante righe erano eleggibili vs quante sono state riempite.
- Controlla a campione alcuni ID e confronta i valori vecchi e nuovi.
- Testa i casi limite (stringhe vuote, zero, record molto vecchi).
- Riesegui gli stessi controlli più tardi per assicurarti che nulla derivi.
Se fai dual-write, aggiungi un controllo di consistenza per cogliere bug silenziosi. Per esempio, esegui ogni ora una query che trova righe dove old_value <> new_value e manda alert se il numero non è zero. Questo spesso è il modo più rapido per scoprire che qualche writer aggiorna solo il campo vecchio.
Monitora i segnali di produzione mentre la migrazione è in corso. Se i tempi delle query o le attese di lock schizzano, anche le tue query di verifica “sicure” possono aggiungere carico. Controlla i tassi di errore per i percorsi che leggono la nuova colonna, specialmente subito dopo i deploy.
Per quanto tempo mantenere entrambe le strade? Abbastanza a lungo da superare almeno un ciclo completo di rilascio e una riesecuzione del backfill. Molti team usano 1–2 settimane, o finché sono sicuri che non giri più nessuna vecchia versione dell'app.
Fase di contract: rimuovere il percorso vecchio
Il contract è dove i team si spaventano perché sembra il punto di non ritorno. Se l'expand è stato fatto bene, il contract è per lo più pulizia e può essere eseguito in passi piccoli e a basso rischio.
Scegli il momento con cura. Non eliminare nulla subito dopo aver finito il backfill. Aspetta almeno un ciclo completo di rilascio così job ritardati e casi estremi hanno il tempo di emergere.
Una sequenza di contract sicura di solito sembra così:
- Smetti il dual-write e conferma che le nuove scritture vanno solo nelle nuove colonne.
- Rimuovi le letture vecchie nell'applicazione così il fallback scompare.
- Elimina i percorsi di codice morti, i feature flag e i job di background che fanno riferimento allo schema vecchio.
- Rimuovi trigger temporanei, job di sincronizzazione o viste di compatibilità.
- Elimina indici e vincoli non più necessari, poi cancella la colonna vecchia.
Se puoi, dividi il contract in due release: una che rimuove i riferimenti nel codice (con logging extra) e una successiva che rimuove gli oggetti database. Questa separazione semplifica rollback e troubleshooting.
I dettagli PostgreSQL contano qui. Droppare una colonna è per lo più un cambiamento metadata, ma richiede comunque un breve lock ACCESS EXCLUSIVE. Pianifica una finestra tranquilla e mantieni la migrazione veloce. Se hai creato indici aggiuntivi, preferisci rimuoverli con DROP INDEX CONCURRENTLY per evitare di bloccare le scritture (non può essere eseguito dentro un blocco di transazione, quindi il tuo tooling di migrazione deve supportarlo).
Errori comuni e trappole
Le migrazioni senza downtime falliscono quando il database e l'app smettono di concordare su cosa sia permesso. Il pattern funziona solo se ogni stato intermedio è sicuro per entrambe le versioni del codice.
Trappole che rompono la produzione
Questi errori capitano spesso:
- Aggiungere NOT NULL troppo presto, mentre una versione più vecchia dell'app può ancora scrivere righe senza il nuovo campo.
- Backfillare una tabella enorme in una singola transazione, che può mantenere lock, causare bloat e timeouts.
- Assumere che un default sia gratuito. In PostgreSQL, alcuni default provocano rewrite della tabella.
- Passare le letture alla nuova colonna prima che le scritture la popolino in modo affidabile.
- Dimenticare altri writer/reader (cron job, worker, esportazioni, query di reporting).
Uno scenario realistico: inizi a scrivere full_name dall'API, ma un job di background che crea utenti continua a impostare solo first_name e last_name. Gira di notte, inserisce righe con full_name = NULL, e il codice successivo assume sempre la presenza di full_name.
Come evitare di restare bloccati a metà migrazione
Tratta ogni passo come una release che può durare giorni:
- Mantieni la nuova colonna nullable durante la transizione e applica il requisito di “obbligatorio” prima nel codice.
- Backfilla a piccoli batch con pause e monitora il carico DB.
- Rendi il codice tollerante: leggi entrambe le strade, scrivi entrambe quando serve, gestisci valori mancanti.
- Revisiona ogni punto che tocca la tabella, inclusi worker e processi di reporting.
Checklist rapida prima di ogni release
Una checklist ripetibile evita di spedire codice che funziona solo in uno stato del DB.
Prima di distribuire, conferma che il database abbia già i pezzi expanded (nuove colonne/tabelle, indici creati in modo low-lock). Poi conferma che l'app sia tollerante: deve funzionare contro lo schema vecchio, lo schema expanded e uno stato mezzo backfillato.
Tieni la checklist corta:
- Expansion presente: i nuovi oggetti di schema esistono e sono stati aggiunti in modo a basso impatto.
- Compatibilità reale: l'app funziona con vecchio ed expanded schema, inclusi worker e percorsi admin.
- Backfill controllato: batch piccoli, pausable, con metriche di progresso.
- Switch delle letture pianificato: sai esattamente quando sposti le letture e come rollbackare se i risultati sono sbagliati.
- Contract posticipato: aspetti almeno uno o due cicli di release prima di eliminare gli oggetti vecchi.
Una migrazione si considera fatta quando le letture usano i nuovi dati, le scritture non mantengono più i dati vecchi e hai verificato il backfill con almeno un controllo semplice (conteggi o campionamento).
Un esempio realistico: sostituire una colonna senza downtime
Supponiamo di avere una tabella PostgreSQL customers con una colonna phone che contiene valori disomogenei (formati diversi, a volte vuota). Vuoi sostituirla con phone_e164, ma non puoi bloccare i rilasci o mettere offline l'app.
Una sequenza expand/contract pulita è:
- Expand: aggiungi
phone_e164 come nullable, senza default e senza vincoli pesanti.
- Deploy compatibile: aggiorna il codice per scrivere sia in
phone sia in phone_e164, ma mantieni le letture su phone così gli utenti non notano cambiamenti.
- Backfill: converti le righe esistenti a piccoli batch (per esempio 1.000 alla volta).
- Switch delle letture: distribuisci codice che legge prima
phone_e164 e ricade su phone se è ancora NULL.
- Contract: quando sei sicuro che tutto usa
phone_e164, rimuovi il fallback, elimina phone e poi aggiungi vincoli più stringenti se ancora necessari.
Il rollback rimane semplice quando ogni passo è retrocompatibile. Se lo switch di lettura crea problemi, rollbacki l'app e il database ha ancora entrambe le colonne. Se il backfill causa picchi di carico, metti in pausa il job, riduci la dimensione dei batch e riprendi più tardi.
Per mantenere il team allineato, documenta il piano in un unico posto: l'SQL esatto, quale release cambia le letture, come misuri il completamento (per esempio percentuale di phone_e164 NON NULL) e chi è responsabile di ogni passo.
Prossimi passi: rendilo ripetibile
Expand/contract funziona meglio quando diventa routine. Scrivi un breve runbook che il team può riutilizzare per ogni modifica allo schema, idealmente una pagina e sufficientemente specifico perché un nuovo collega possa seguirlo.
Un template pratico copre:
- Expand (migrazioni esatte)
- Cambiamenti di codice (cosa deve restare backward compatible e dove si usa dual-read o dual-write)
- Backfill (dimensione dei batch, rate limit, pause/reprise)
- Verifica (query e metriche che dimostrano la correttezza)
- Contract (cosa viene rimosso e quando)
Decidi ownership in anticipo. “Tutti pensavano che qualcun altro avrebbe fatto il contract” è il motivo per cui colonne e feature flag vecchie restano mesi.
Anche se il backfill è online, pianificalo quando il traffico è più basso. È più facile mantenere batch piccoli, monitorare il carico DB e fermarsi rapidamente se la latenza aumenta.
Se costruisci e distribuisci con Koder.ai (koder.ai), Planning Mode può essere utile per mappare fasi e checkpoint prima di toccare la produzione. Le stesse regole di compatibilità si applicano, ma avere i passaggi scritti rende più difficile saltare le parti noiose che prevengono outage.