Quando il database è sotto stress, cosa si rompe per primo
Quando il tuo database è sovraccarico, gli utenti raramente vedono un messaggio pulito di "down". Vedono timeout, pagine che si caricano a metà, pulsanti che girano all'infinito e azioni che a volte funzionano e a volte falliscono. Un salvataggio può riuscire una volta e poi dare errore la volta successiva con "Qualcosa è andato storto." Questa incertezza è ciò che rende gli incidenti caotici.
Le prime cose che si rompono sono di solito i percorsi ad alta scrittura: modifica dei record, flussi di checkout, invio di moduli, aggiornamenti in background e qualsiasi cosa che richieda una transazione e lock. Sotto stress, le scritture rallentano, si bloccano a vicenda e possono anche rallentare le letture trattenendo lock e richiedendo più lavoro.
Gli errori casuali sembrano peggiori di una limitazione controllata perché gli utenti non sanno cosa fare dopo. Ritentano, aggiornano la pagina, cliccano di nuovo e generano ancora più carico. I ticket di supporto aumentano perché il sistema sembra "in parte funzionante", ma nessuno si fida.
Lo scopo della modalità sola lettura durante gli incidenti non è la perfezione. È mantenere le parti più importanti utilizzabili: vedere record chiave, cercare, controllare lo stato e scaricare ciò di cui le persone hanno bisogno per continuare a lavorare. Blocchi intenzionalmente o rimandi le azioni rischiose (scritture) così il database si riprende e le letture rimanenti restano reattive.
Stabilisci le aspettative chiaramente. È un limite temporaneo e non significa che i dati vengano cancellati. Nella maggior parte dei casi, i dati esistenti dell'utente sono ancora lì e al sicuro: il sistema semplicemente mette in pausa le modifiche finché il database non torna sano.
Cosa significa davvero la modalità sola lettura
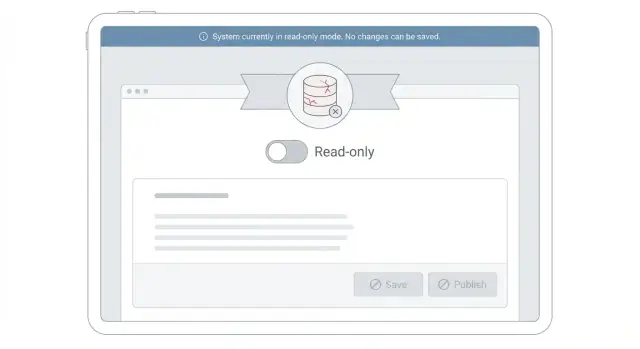
La modalità sola lettura durante gli incidenti è uno stato temporaneo in cui il prodotto resta usabile per la consultazione, ma rifiuta qualsiasi cosa comporti una modifica dei dati. L'obiettivo è semplice: mantenere il servizio utile proteggendo il database da lavoro extra.
In termini pratici, le persone possono ancora cercare informazioni, ma non possono effettuare modifiche che innescherebbero scritture. Di solito ciò significa che la navigazione tra le pagine, la ricerca, i filtri e l'apertura dei record funzionano ancora. Salvare moduli, modificare impostazioni, postare commenti, caricare file o creare account sono bloccati.
Un modo pratico di pensarci: se un'azione aggiorna una riga, crea una riga, elimina una riga o scrive in una coda, non è permessa. Molti team bloccano anche le "scritture nascoste" come eventi di analytics memorizzati nel database primario, log di audit scritti in modo sincrono e timestamp di "last seen".
La modalità sola lettura è la scelta giusta quando le letture funzionano ancora per la maggior parte, ma la latenza delle scritture sale, la contesa per i lock cresce o un arretrato di lavoro pesante sulle scritture rallenta tutto.
Vai completamente offline quando anche le letture di base vanno in timeout, la cache non riesce a servire l'essenziale o il sistema non può dire agli utenti cosa è sicuro fare.
Perché aiuta: una scrittura spesso costa molto più di una semplice lettura. Una scrittura può attivare indici, vincoli, lock e query successive. Bloccare le scritture previene anche le tempeste di retry, dove i client continuano a ripresentare salvataggi falliti moltiplicando il danno.
Esempio: durante un incidente su un CRM, gli utenti possono ancora cercare account, aprire dettagli di contatto e vedere le offerte recenti, ma le azioni Modifica, Crea e Importa sono disabilitate e qualsiasi richiesta di salvataggio viene rifiutata immediatamente con un messaggio chiaro.
Scegli le letture da mantenere e le scritture da fermare
Quando passi in modalità sola lettura durante gli incidenti, l'obiettivo non è "tutto funziona". L'obiettivo è che le schermate più importanti si carichino, mentre tutto ciò che crea ulteriore pressione sul database si fermi rapidamente e in sicurezza.
Inizia nominando poche azioni utente che devono funzionare anche in un giorno difficile. Sono di solito piccole letture che sbloccano decisioni: visualizzare l'ultimo record, controllare uno stato, cercare una lista breve o scaricare un report già memorizzato.
Poi decidi cosa puoi mettere in pausa senza causare danni importanti. La maggior parte dei percorsi di scrittura rientra in "bello avere" durante un incidente: modifiche, aggiornamenti in blocco, importazioni, commenti, allegati, eventi di analytics e qualsiasi cosa inneschi query extra.
Un modo semplice per decidere è dividere le azioni in tre categorie:
- Must keep: piccole letture veloci che sbloccano gli utenti immediatamente
- Can pause: scritture e letture pesanti che aggiungono carico o bloccano righe
- Can degrade: funzionalità che possono mostrare dati in cache o una vista parziale
Imposta anche un orizzonte temporale. Se prevedi minuti, puoi essere severo e bloccare quasi tutte le scritture. Se prevedi ore, considera di consentire un set molto limitato di scritture sicure (per esempio reset password o aggiornamenti di stato critici) e mettere in coda tutto il resto.
Concorda la priorità in anticipo: sicurezza prima della completezza. È meglio mostrare un chiaro messaggio "le modifiche sono in pausa" che permettere una scrittura che va a metà e lascia i dati incoerenti.
Come decidere quando attivarla
Passare in sola lettura è un compromesso: meno funzionalità ora, ma un prodotto utilizzabile e un database più sano. L'obiettivo è agire prima che gli utenti inneschino una spirale di retry, timeout e connessioni bloccate.
Osserva un piccolo insieme di segnali che puoi spiegare in una frase. Se due o più appaiono contemporaneamente, consideralo un avvertimento precoce:
- Richieste in timeout o che superano una soglia di latenza chiara (per esempio p95 da 300 ms a 3 s)
- CPU del database costantemente al massimo per diversi minuti, non solo un breve picco
- Esaurimento del pool di connessioni (richieste in coda perché non ci sono connessioni disponibili)
- Log di query lente che si riempie improvvisamente con le stesse poche query
- Aumento del tasso di errori dovuto ad attese per lock, deadlock o transazioni fallite
Le metriche da sole non devono essere l'unico trigger. Aggiungi una decisione umana: la persona on-call dichiara lo stato di incidente e attiva la modalità sola lettura. Questo evita discussioni sotto pressione e rende l'azione tracciabile.
Rendi le soglie facili da ricordare e comunicare. "Le scritture sono in pausa perché il database è sovraccarico" è più chiaro di "abbiamo raggiunto la saturazione". Definisci anche chi può azionare l'interruttore e dove è controllato.
Evita il flapping tra le modalità. Aggiungi un'isteresi semplice: una volta che entri in sola lettura, resta lì per una finestra minima (ad esempio 10-15 minuti) e riattiva solo dopo che i segnali sono normali da un po'. Questo evita che gli utenti vedano moduli che funzionano un minuto e falliscono il successivo.
Passo dopo passo: attivare la modalità sola lettura in sicurezza
Tratta la modalità sola lettura come un cambiamento controllato, non come una corsa improvvisata. L'obiettivo è proteggere il database fermando le scritture, mantenendo le letture più preziose.
Una sequenza di rollout sicura
Se possibile, distribuisci prima il percorso di codice. Così attivare la sola lettura è solo un toggle, non una modifica live.
- Crea un singolo toggle per l'incidente (feature flag o impostazione di configurazione) che tutto il sistema legge. Mantienilo globale e noioso:
READ_ONLY=true. Evita più flag che possono sfasarsi.
- Aggiorna l'UI per prevenire tentativi di scrittura. Disabilita i pulsanti Salva, nascondi i form di modifica e trasforma gli input in testo semplice. Mostra comunque i dati in modo che le persone possano continuare a lavorare (visualizzazione, ricerca, esportazione).
- Fallo rispettare dal server, non solo dall'UI. Blocca le scritture in un unico punto (middleware, guardia nel controller o layer di servizio) così ogni client è coperto, incluse app mobili, utenti API e automazioni.
- Restituisci un errore chiaro e coerente per le scritture bloccate. Usa un codice di stato dedicato e un messaggio come: "La modifica è temporaneamente disabilitata mentre stabilizziamo il sistema. I tuoi dati sono al sicuro. Riprova più tardi." Non restituire un generico 500 che sembra perdita di dati.
- Logga ogni tentativo di scrittura bloccato. Registra utente, endpoint e tipo di azione. Mantieni il payload minimo per evitare dati sensibili nei log. Questi log ti aiutano a correggere gap di UX e a riprodurre azioni critiche più avanti se necessario.
Un piccolo dettaglio che previene incidenti ripetuti
Quando la modalità sola lettura è attiva, falla fallire velocemente prima di toccare il database. Non eseguire query di validazione e poi bloccare la scrittura. La richiesta bloccata più veloce è quella che non raggiunge mai il database sotto stress.
Messaggi UI che riducono confusione e ticket di supporto
Ship Calm Incident Messaging
Create clear banners and blocked-write messages that match your backend behavior.
Quando abiliti la modalità sola lettura durante un incidente, l'interfaccia è parte della soluzione. Se le persone continuano a cliccare Salva e ricevono errori vaghi, ritenteranno, aggiorneranno e apriranno ticket. Un messaggio chiaro riduce il carico e la frustrazione.
Un buon schema è un banner visibile e persistente in cima all'app. Mantienilo breve e fattuale: cosa sta succedendo, cosa aspettarsi e cosa si può fare adesso. Non nasconderlo in un toast che scompare.
Di' cosa funziona, cosa è in pausa e cosa succederà dopo
Gli utenti vogliono principalmente sapere se possono continuare a lavorare. Scrivilo chiaramente. Per la maggior parte dei prodotti significa:
- Ancora funzionante: visualizzazione record, ricerca, download, consultazione dashboard
- In pausa: creazione, modifica, cancellazione, upload, pagamenti, invio messaggi
- Cosa fare invece: copiare informazioni chiave, esportare una vista, riprovare più tardi
- Aggiornamenti: "Pubblicheremo un aggiornamento qui tra 15 minuti."
Un'etichetta di stato semplice aiuta le persone a capire i progressi senza indovinare. "Investigando" significa che stai ancora cercando la causa. "Stabilizzando" significa che stai riducendo il carico e proteggendo i dati. "Recuperando" significa che le scritture torneranno presto, ma potrebbero essere lente.
Mantieni il tono calmo e specifico
Evita testi colpevolizzanti o vaghi come "Qualcosa è andato storto" o "Non hai il permesso." Se un pulsante è disabilitato, etichettalo: "La modifica è temporaneamente sospesa mentre stabilizziamo il sistema."
Un piccolo esempio: in un CRM, mantieni leggibili le pagine contatto e deal, ma disabilita Modifica, Aggiungi nota e Nuova opportunità. Se qualcuno prova comunque, mostra un breve dialogo: "Le modifiche sono in pausa in questo momento. Puoi copiare questo record o esportare la lista, poi riprovare più tardi."
Conservare le letture chiave senza aumentare il carico
Quando passi in sola lettura durante gli incidenti, l'obiettivo non è "mantenere tutto visibile". È "mantenere poche pagine su cui le persone contano", senza aggiungere pressione a un database stressato.
Inizia riducendo le schermate più pesanti. Tabelle lunghe con molti filtri, ricerche full-text su più campi e ordinamenti complessi spesso generano query lente. In sola lettura rendi quelle schermate più semplici: meno opzioni di filtro, un ordinamento predefinito sicuro e un intervallo di date limitato.
Preferisci viste in cache o precompute per le pagine più importanti. Un semplice "overview account" che legge da una cache o da una tabella di riepilogo è di solito più sicuro che caricare log grezzi o fare join su molte tabelle.
Modi pratici per mantenere vive le letture senza peggiorare il carico:
- Usa pagine più piccole e rimuovi il pulsante "mostra tutto"
- Sostituisci ordinamenti complessi con un ordine predefinito (per esempio "più recenti prima")
- Rimanda letture non essenziali come analytics, raccomandazioni e grafici di attività
- Preferisci sommari in cache invece di storici grezzi
- Consenti dati leggermente obsoleti se mantiene le pagine core reattive
Un esempio concreto: in un incidente CRM, mantieni funzionanti Visualizza contatto, Visualizza stato opportunità e Visualizza ultima nota. Nascondi temporaneamente Ricerca avanzata, Grafico dei ricavi e Timeline completa delle email, e mostra una nota che indica che i dati potrebbero avere qualche minuto di ritardo.
Cosa fare con job, webhook e integrazioni
Test the CRM Scenario
Prototype a CRM style workflow and test what stays usable when writes are paused.
Quando passi in sola lettura durante un incidente, la sorpresa più grande spesso non è l'UI. Sono gli scrittori invisibili: job in background, sync pianificati, azioni bulk admin e integrazioni di terze parti che continuano a battere sul database.
Inizia fermando il lavoro in background che crea o aggiorna record. I colpevoli comuni sono importazioni, sincronizzazioni notturne, invio di email che registra log di consegna, rollup di analytics e loop di retry che continuano a tentare lo stesso aggiornamento fallito. Mettere in pausa questi processi riduce rapidamente la pressione ed evita una seconda ondata di carico.
Una buona impostazione di default è mettere in pausa o limitare i job pesanti in scrittura e qualsiasi consumer di code che persiste risultati, disabilitare azioni bulk admin (aggiornamenti massivi, cancellazioni in blocco, grandi reindicizzazioni) e far fallire velocemente gli endpoint di scrittura con una risposta temporanea chiara anziché farli andare in timeout.
Per webhook e integrazioni, la chiarezza batte l'ottimismo. Se accetti un webhook ma non puoi processarlo, creerai discrepanze e carico di supporto. Quando le scritture sono in pausa, restituisci un errore temporaneo che dica al mittente di riprovare più tardi e assicurati che i messaggi nell'UI corrispondano a quello che stai facendo dietro le quinte.
Fai attenzione al buffering tipo "mettilo in coda per dopo". Suona amichevole, ma può creare un arretrato che inonda il sistema nel momento in cui riattivi le scritture. Metti in coda le scritture degli utenti solo se puoi garantire idempotenza, limita la dimensione della coda e mostra all'utente lo stato reale (in sospeso vs salvato).
Infine, audita gli scrittori bulk nascosti nel tuo prodotto. Se un'automazione può aggiornare migliaia di righe, deve essere forzata off in modalità sola lettura anche se il resto dell'app continua a caricare.
Errori comuni che peggiorano gli incidenti
Il modo più veloce per peggiorare un incidente è trattare la modalità sola lettura come una modifica cosmetica. Se disabiliti solo i pulsanti nella UI, le persone continueranno a scrivere tramite API, vecchie schede, app mobili e job in background. Il database resta sotto pressione e perdi fiducia perché gli utenti vedono "salvato" in un posto e cambiamenti mancanti in un altro.
Una vera modalità sola lettura durante gli incidenti richiede una regola chiara: il server rifiuta le scritture, ogni volta, per ogni client.
Errori da tenere d'occhio
Questi pattern ricorrono spesso durante il sovraccarico del database:
- Bloccare le modifiche solo nell'UI mentre il backend continua ad accettare POST, PUT, PATCH e DELETE
- Dimenticare percorsi nascosti: pannelli admin, strumenti interni, endpoint di import e API pubbliche usate da integrazioni
- Lasciare che il sistema flappi tra normale e sola lettura ogni minuto
- Mostrare messaggi vaghi come "Qualcosa è andato storto"
- Permettere scritture parziali che lasciano dati incoerenti
Come evitarli
Fai comportare il sistema in modo prevedibile. Applica un unico interruttore server-side che rifiuta le scritture con una risposta chiara. Aggiungi un cooldown in modo che, una volta entrati in sola lettura, si resti per un tempo minimo (es. 10-15 minuti) a meno che un operatore non lo cambi.
Sii rigoroso sull'integrità dei dati. Se una scrittura non può completarsi completamente, fai fallire l'intera operazione e comunica all'utente cosa fare dopo. Un messaggio semplice come "Modalità sola lettura: la visualizzazione funziona, le modifiche sono in pausa. Riprova più tardi." riduce i retry ripetuti.
Controlli rapidi prima e durante un incidente
La modalità sola lettura aiuta solo se è facile da attivare e si comporta allo stesso modo ovunque. Prima che inizi il problema, assicurati che ci sia un unico toggle (feature flag, config, switch admin) che l'on-call può abilitare in pochi secondi, senza deploy.
Quando sospetti sovraccarico del database, fai un controllo rapido che confermi le basi:
- Attiva il toggle in un ambiente sicuro e conferma che ha effetto immediato
- Prova alcune azioni di scrittura (salva, cancella, importa) e conferma che ogni endpoint di scrittura restituisce la stessa risposta bloccata e codice di stato
- Controlla che il testo del banner sia pronto, breve e visibile nelle schermate più usate
- Carica le tue 3 pagine principali (per esempio: login, dashboard, visualizza record) e conferma che si rendono sotto stress
- Assicurati che il support abbia uno script di una frase che spiega cosa funziona, cosa è in pausa e dove guardare gli aggiornamenti
Durante l'incidente, tieni una persona focalizzata sulla verifica dell'esperienza utente, non solo sui dashboard. Un controllo rapido in una finestra di navigazione in incognito cattura problemi come banner nascosti, form rotti o spinner infiniti che creano traffico di aggiornamento extra.
Pianifica l'uscita prima di attivarla. Decidi cosa significa "sano" (latenza, tasso di errori, lag di replica) e fai una breve verifica dopo la riattivazione: crea un record di test, modificalo e conferma che conteggi e attività recenti siano corretti.
Esempio di incidente: mantenere un CRM utilizzabile bloccando le modifiche
Own the Implementation
Keep full control by exporting source code after you generate your incident controls.
Sono le 10:20. Il tuo CRM è lento e la CPU del database è satura. I ticket di supporto arrivano: gli utenti non riescono a salvare modifiche a contatti e opportunità. Ma il team ha ancora bisogno di cercare numeri di telefono, vedere gli stati delle opportunità e leggere le ultime note prima delle chiamate.
Scegli una regola semplice: congelare tutto ciò che scrive, mantenere le letture più utili. In pratica, ricerca contatti, pagine dettaglio contatto e vista pipeline rimangono attive. Modificare un contatto, creare una nuova opportunità, aggiungere note e importazioni bulk sono bloccati.
Nell'UI, il cambiamento deve essere ovvio e calmo. Nelle schermate di modifica il pulsante Salva è disabilitato e il form resta visibile così le persone possono copiare ciò che hanno scritto. Un banner in cima dice: "La modalità sola lettura è attiva per alto carico. La visualizzazione è disponibile. Le modifiche sono in pausa. Riprova più tardi." Se un utente prova comunque a scrivere (per esempio tramite API), restituisci un messaggio chiaro ed evita retry automatici che colpiscono il database.
Operativamente, mantieni il flusso corto e ripetibile. Abilita la sola lettura e verifica che tutti gli endpoint di scrittura la rispettino. Metti in pausa job di background che scrivono (sync, import, logging email, backfill analytics). Limita o metti in pausa webhook e integrazioni che generano aggiornamenti. Monitora carico del database, tasso di errori e query lente. Pubblica un aggiornamento di stato con cosa è interessato (modifiche) e cosa funziona ancora (ricerca e viste).
Il recupero non è solo riabbassare l'interruttore. Riattiva le scritture gradualmente, verifica i log di errore per i salvataggi falliti e presta attenzione a una possibile ondata di scritture da job in coda. Poi comunica chiaramente: "La modalità sola lettura è disattivata. Il salvataggio è stato ripristinato. Se hai provato a salvare tra le 10:20 e le 10:55, controlla le ultime modifiche."
Prossimi passi: rendere la sola lettura parte del tuo playbook
La modalità sola lettura funziona meglio quando è noiosa e ripetibile. L'obiettivo è seguire uno script breve con proprietari e controlli chiari.
Crea un playbook piccolo e utilizzabile
Tienilo su una pagina. Includi i trigger (i pochi segnali che giustificano il passaggio a sola lettura), l'esatto interruttore da attivare e come confermare che le scritture sono bloccate, una lista breve delle letture chiave che devono funzionare, ruoli chiari (chi attiva lo switch, chi guarda le metriche, chi gestisce il support) e i criteri di uscita (cosa deve essere vero prima di riabilitare le scritture e come svuotare gli arretrati).
Prepara i testi UI prima di averne bisogno
Scrivi e approva i testi ora così non discuterai le parole durante un outage. Un set semplice copre la maggior parte dei casi:
- Banner: "Siamo in modalità sola lettura mentre ripristiniamo le prestazioni. Puoi visualizzare i dati, ma le modifiche sono temporaneamente disabilitate."
- Azioni bloccate: "Il salvataggio è in pausa in questo momento. Le tue modifiche non sono state applicate. Riprova tra qualche minuto."
- Dettaglio stato: "Ultimo aggiornamento alle HH:MM. Prossimo aggiornamento tra 10 minuti."
Esercita lo switch in staging e cronometralo. Assicurati che support e on-call trovino il toggle rapidamente e che i log mostrino chiaramente le scritture bloccate. Dopo ogni incidente, rivedi quali letture erano davvero critiche, quali erano utili e quali hanno creato carico accidentalmente, poi aggiorna la checklist.
Se costruisci prodotti su Koder.ai (koder.ai), può essere utile trattare la sola lettura come un toggle di prima classe nella tua app generata così l'UI e le protezioni server-side rimangono coerenti quando ne hai più bisogno.