20 set 2025·8 min
Miglior LLM per ogni task di sviluppo: una mappa pratica dei modelli
Il miglior LLM per ogni task di sviluppo: confronta UI copy, componenti React, SQL, refactor e fix dei bug per punti di forza, latenza e costo.
Perché usare un solo LLM per tutto crea problemi
Usare un unico modello per ogni attività sembra semplice. In pratica, spesso rallenta le build, aumenta i costi e riduce l'affidabilità. Lo stesso modello che eccelle nel ragionamento profondo può risultare dolorosamente lento per una microcopy UI. E il modello veloce ed economico può introdurre errori rischiosi quando scrive SQL o modifica la logica centrale.
I team di solito notano il problema attraverso alcuni sintomi ricorrenti:
- Le risposte richiedono troppo tempo per compiti piccoli, così le persone iniziano a fare multi-task e perdono concentrazione.
- Le bollette aumentano perché richieste “semplici” vengono gestite da un modello costoso.
- La qualità del codice oscilla tra eccellente e discutibile, anche quando i prompt sono simili.
- Gli sviluppatori revisionano tutto eccessivamente perché non sanno quando il modello può sbagliare.
L'obiettivo non è inseguire il modello più blasonato. L'obiettivo è scegliere il miglior LLM per ogni task di sviluppo in base a ciò che serve ora: velocità, accuratezza, consistenza o ragionamento attento.
Un esempio rapido: immagini di costruire una piccola dashboard React. Chiedi allo stesso modello top-tier di (1) scrivere le etichette dei bottoni, (2) generare un componente React, (3) creare una migration SQL e (4) risolvere un bug ostico. Pagherai prezzi premium per le etichette, aspetterai più del necessario per il componente e avrai comunque bisogno di controlli extra su SQL e bug fix.
Piattaforme come Koder.ai facilitano questo perché puoi trattare la scelta del modello come qualsiasi altra scelta di strumento: abbina lo strumento al lavoro. Nessun modello vince su qualità, latenza e costo allo stesso tempo, ed è normale. Il vantaggio è avere un “default per task” semplice, così la maggior parte del lavoro procede più veloce con meno sorprese.
I tre compromessi: qualità, latenza e costo
La maggior parte dei builder vuole un modello che sia veloce, economico e sempre corretto. In pratica puoi sceglierne due, e anche questo dipende dal task. Se miri al miglior LLM per ogni task, aiuta mettere i compromessi in parole semplici.
Qualità significa ottenere un risultato corretto e utilizzabile con meno retry. Per il codice, significa logica corretta, sintassi valida e meno effetti collaterali nascosti. Per la scrittura, significa una formulazione chiara che rispecchi il prodotto ed eviti affermazioni imbarazzanti. Alta qualità significa anche che il modello segue i tuoi vincoli, come “modifica solo questo file” o “non toccare lo schema del database”.
Latenza è il tempo per il primo output utile, non il tempo totale per finire una risposta perfetta. Un modello che risponde in 3 secondi con qualcosa che puoi modificare può battere un modello più lento che impiega 25 secondi per produrre una risposta più lunga che devi comunque riscrivere.
Costo non è solo il prezzo per richiesta. Il costo nascosto è quello che paghi quando la prima risposta è sbagliata o vaga.
- Retry extra e chat più lunghe
- Tempo di debugging e fix in produzione
- Rilanciare test o ricostruire deployment
- Contesto che devi incollare di nuovo
Immagina un triangolo: qualità, latenza, costo. Spingere un angolo di solito tira gli altri. Per esempio, se scegli l'opzione più economica e veloce per generare SQL, un piccolo errore di join può consumare più tempo di quello che hai risparmiato.
Un modo semplice per decidere: per la UI copy tollera un po' meno qualità e ottimizza la velocità. Per SQL, refactor e bug fix, paga per qualità più alta anche se latenza e costo aumentano. Piattaforme come Koder.ai rendono più semplice cambiare modello per chat e abbinare il modello al task invece di costringere un solo modello a fare tutto.
Cosa significano davvero i punti di forza nel lavoro quotidiano
Quando si dice che un modello è “bravo a X”, di solito si intende che fa risparmiare tempo su quel tipo di lavoro con meno retry. In pratica, la maggior parte dei punti di forza rientra in poche categorie.
- Writing: formulazione chiara e naturale, buon tono, frasi meno goffe
- Coding: sintassi corretta, buoni pattern, meno import mancanti o edge case non gestiti
- Reasoning: tiene in mente molti vincoli ed è capace di spiegare i compromessi senza indovinare
- Tool use: segue un formato, chiama funzioni in modo pulito e rispetta istruzioni rigorose
La lunghezza del contesto conta più di quanto molti builder si aspettino. Se il tuo prompt è corto e mirato (un componente, una query, un bug), i modelli veloci spesso vanno bene. Se hai bisogno che il modello usi molto codice esistente, requisiti o decisioni precedenti, un contesto lungo aiuta perché riduce i dettagli “dimenticati”. Il rovescio della medaglia è che il contesto lungo può aumentare costo e latenza, quindi usalo solo quando davvero previene errori.
L'affidabilità è una forza nascosta. Alcuni modelli seguono le istruzioni (formato, stile, vincoli) in modo più coerente. Suona noioso, ma riduce il rifacimento: meno “per favore riscrivilo in TypeScript”, meno file mancanti, meno sorprese in SQL.
Una regola semplice che funziona: paga per la qualità quando gli errori costano caro. Se un errore può rompere la produzione, esporre dati o sprecare ore di debugging, scegli il modello più attento anche se è più lento.
Per esempio, la microcopy dei bottoni può tollerare qualche iterazione. Ma cambiare un flusso di pagamento, una migration o un controllo di autenticazione è dove vuoi il modello cauto e consistente, anche se costa di più per esecuzione. Se usi una piattaforma come Koder.ai che supporta più famiglie di modelli, è qui che cambiare modello paga velocemente.
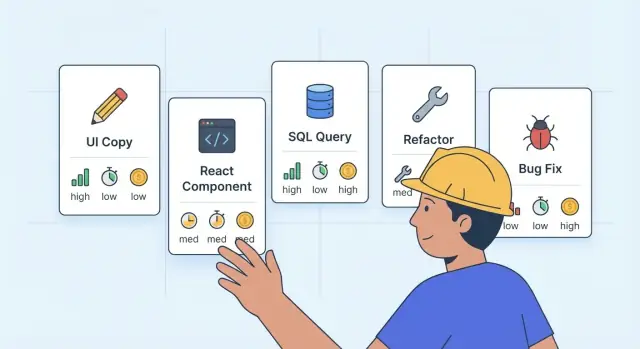
Una mappa pratica dei task (cosa usare quando)
Se vuoi il miglior LLM per ogni task di sviluppo, smetti di pensare ai nomi dei modelli e inizia a pensare in “tier”: fast-cheap, balanced e reasoning-first. Puoi mescolare i tier nello stesso progetto, anche all'interno della stessa feature.
Ecco una mappa semplice da tenere accanto al backlog:
| Tipo di task | Punti di forza preferiti | Target costo/latenza | Scelta tipica |
|---|---|---|---|
| UI copy, microcopy, etichette | Velocità, controllo del tono, varianti rapide | Minimo costo, minima latenza | Fast-cheap |
| Componenti React (nuovi) | Correttezza, struttura pulita, test | Latenza media, costo medio | Balanced o reasoning-first per UI complesse |
| Generazione SQL e migration | Accuratezza, sicurezza, output prevedibile | Costi più alti OK, latenza OK | Reasoning-first |
| Refactor (multi-file) | Coerenza, cautela, rispetto delle regole | Latenza da media ad alta | Reasoning-first |
| Bug fix | Ragionamento sulla causa radice, cambi minimi | Costi più alti OK | Reasoning-first (poi fast-cheap per rifinire) |
Una regola utile: esegui i modelli “cheap” quando gli errori sono facili da individuare, e i modelli “forti” quando gli errori sono costosi.
Sicuri sui modelli più veloci: editing di copy, piccole modifiche UI, rinominare, funzioni helper semplici e formattazione. Rischiosi sui modelli più veloci: qualsiasi cosa tocchi dati (SQL), auth, pagamenti o refactor cross-file.
Un flusso realistico: chiedi una nuova pagina Settings. Usa un modello balanced per abbozzare il componente React. Passa a un modello reasoning-first per rivedere la gestione dello stato e gli edge case. Poi usa un modello veloce per affinare i testi UI. In Koder.ai, i team spesso fanno questo nella stessa chat assegnando passi diversi a modelli diversi così non sprechi crediti dove non servono.
Regole rapide per mescolare i modelli
- Bozza veloce, verifica lenta.
- Usa reasoning-first per qualsiasi cosa non facilmente “testabile a occhio”.
- Mantieni un solo modello per tutto un passaggio di refactor per evitare deriva di stile.
- Dopo le correzioni, chiedi a un secondo modello di revisionare per effetti collaterali mancati.
UI copy e testi di prodotto: prima la velocità, poi una QA rapida
Per la UI copy l'obiettivo è di solito chiarezza, non genialità. I modelli veloci e a basso costo sono un buon default per microcopy come etichette dei bottoni, stati vuoti, testi d'aiuto, messaggi di errore e brevi passaggi di onboarding. Ottieni iterazioni rapide, che contano più di una frase perfetta.
Usa un modello più forte quando le poste in gioco sono alte o i vincoli sono stringenti. Questo include l'allineamento del tono su molte schermate, riscritture che devono mantenere significato esatto, testi sensibili (fatturazione, privacy, sicurezza) o qualsiasi cosa possa essere letta come una promessa. Se stai cercando il miglior LLM per ogni task, questo è uno dei modi più facili per risparmiare tempo e crediti iniziando veloce e aggiornando solo se necessario.
Suggerimenti di prompt che migliorano più dei cambi modello:
- Incolla 3-5 esempi della voce del tuo brand (anche brevi vanno bene).
- Elenca frasi proibite e parole che il prodotto non usa mai.
- Specifica livello di lettura e limiti di lunghezza (es. sotto 60 caratteri).
- Fornisci il contesto UI esatto (schermata, obiettivo utente, cosa succede dopo).
Una QA rapida richiede un minuto e previene settimane di piccole confusioni. Prima di spedire, controlla:
- Ambiguità: l'utente può interpretarlo in due modi?
- Affermazioni: promette risultati che non puoi garantire?
- Terminologia: usi le stesse parole ovunque (es. “snapshot” vs “backup”)?
- Tono: è calmo negli errori e diretto nei bottoni?
- Localizzazione: avrà senso una volta tradotto?
Esempio: in Koder.ai, un modello veloce può abbozzare il tooltip di un pulsante “Deploy”, poi un modello più forte può riscrivere il testo della schermata prezzi per rimanere coerente tra Free, Pro, Business ed Enterprise senza aggiungere nuove promesse.
Componenti React: scegli la correttezza sulla creatività
Pianifica prima, poi costruisci
Use Planning Mode to map risks and constraints before you let the agent change code.
Per i componenti React, il modello più veloce è spesso “sufficientemente buono” solo quando la superficie è piccola. Pensa a una variante di bottone, a una correzione di spacing, a un form semplice con due campi o a cambiare layout da flex a grid. Se puoi revisionare il risultato in meno di un minuto, la velocità vince.
Non appena compaiono stato, side effect o interazioni reali, scegli un modello di coding più forte anche se costa di più. Il tempo extra è spesso più economico del debugging di un componente instabile in seguito. Questo conta soprattutto per gestione dello stato, interazioni complesse (drag and drop, ricerca debounced, flussi multi-step) e accessibilità, dove una risposta sicura ma sbagliata fa sprecare ore.
Prima che il modello scriva codice, dagli dei vincoli. Una breve specifica previene componenti “creativi” che non corrispondono alla tua app.
- Usa TypeScript e indica la versione target di React
- Definisci l'API del componente (props, eventi, valori di default)
- Elenca gli stati UI (loading, empty, error, disabled)
- Indica esigenze di accessibilità (tastiera, ARIA, ordine del focus)
- Segnala edge case (testo lungo, rete lenta, doppi click)
Un esempio pratico: costruire una “UserInviteModal”. Un modello veloce può abbozzare layout e CSS del modal. Un modello più forte dovrebbe gestire validazione del form, richieste async d'invito e prevenire submit duplicati.
Richiedi il formato di output in modo da ottenere qualcosa di pronto da spedire, non solo frammenti di codice.
- Solo codice del componente (niente placeholder non compilabili)
- Breve spiegazione delle parti delicate (stato, effetti, memoization)
- Un piccolo piano di test (cosa cliccare e cosa dovrebbe succedere)
- Note sui controlli di accessibilità (ordine del tab, focus trap, label)
Se usi Koder.ai, chiedi di generare il componente e poi fai uno snapshot prima dell'integrazione. Così, se il modello “corretto” introduce una regressione sottile, il rollback è un passo invece che un progetto di pulizia. Questo approccio rientra nella mentalità del miglior LLM per ogni task: paga per profondità solo dove gli errori costano.
Task SQL: dai priorità ad accuratezza e sicurezza
SQL è il punto in cui un piccolo errore può diventare un grande problema. Una query che “sembra giusta” può comunque restituire righe sbagliate, essere lenta o modificare dati non intenzionati. Per il lavoro SQL, prediligi accuratezza e sicurezza prima della velocità.
Usa un modello più forte quando la query ha join complicati, funzioni finestra, catene di CTE o qualsiasi cosa sensibile alle performance. Lo stesso vale per cambi di schema (migration), dove ordine e vincoli contano. Un modello più economico e veloce va bene per SELECT semplici, filtri base e CRUD scaffold quando puoi rapidamente controllare il risultato.
Prompting che previene SQL sbagliati
Il modo più veloce per ottenere SQL corretto è eliminare le supposizioni. Includi lo schema (tabelle, chiavi, tipi), la forma dell'output che ti serve (colonne e significato) e un paio di righe di esempio. Se stai costruendo su PostgreSQL (comune nei progetti Koder.ai), dillo, perché sintassi e funzioni cambiano tra DB.
Un piccolo prompt di esempio che funziona bene:
"PostgreSQL. Tables: orders(id, user_id, total_cents, created_at), users(id, email). Return: email, total_spend_cents, last_order_at for users with at least 3 orders in the last 90 days. Sort by total_spend_cents desc. Include indexes if needed."
Prima di eseguire, aggiungi controlli di sicurezza rapidi:
- Chiedi un preview SELECT prima di qualsiasi UPDATE/DELETE.
- Richiedi una clausola WHERE per le scritture (o consenti esplicitamente un cambiamento su tutta la tabella).
- Richiedi una transaction e un piano di rollback per le migration.
- Chiedi gli edge case (NULL, duplicati, fusi orari).
- Fai spiegare al modello perché le chiavi di join sono corrette.
Questo approccio fa risparmiare più tempo e crediti che inseguire risposte “veloci” che poi devi annullare.
Refactor: scegli modelli cauti e coerenti
Debug con meno retry
Paste the error and repro steps to get a focused diagnosis and minimal fix.
I refactor sembrano facili perché non si costruisce “nuovo”. Ma sono rischiosi perché l'obiettivo è l'opposto di una feature: cambiare codice mantenendo esattamente lo stesso comportamento. Un modello che diventa creativo, riscrive troppo o “migliora” la logica può rompere edge case silenziosamente.
Per i refactor, favorisci modelli che rispettano i vincoli, mantengono le modifiche minimali e spiegano perché ogni cambiamento è sicuro. La latenza conta meno della fiducia. Pagare un po' di più per un modello attento spesso salva ore di debugging, ed è per questo che questa categoria è importante in qualsiasi mappa del miglior LLM per ogni task.
Come promptare per refactor sicuri
Sii esplicito su cosa non deve cambiare. Non dare per scontato che il modello lo inferisca dal contesto.
- Elenca vincoli rigidi: API pubbliche, shape dei props, route, schema DB, output ed error message
- Dichiara cosa intendi per “stesso comportamento”: test esistenti che passano, stessi stati UI, stessi risultati di query
- Chiedi un diff minimo: “niente rename a meno che non sia necessario” e “nessuna modifica solo di formattazione”
- Richiedi un quick self-check: “evidenzia qualsiasi rischio di cambiamento comportamentale prima di codare”
Chiedi prima un piano (poi codice)
Un piano breve ti aiuta a individuare i pericoli in anticipo. Chiedi: passi, rischi, quali file cambieranno e approccio di rollback.
Esempio: vuoi refactorare un form React da logica mista a un unico reducer. Un modello cauto dovrebbe proporre una migrazione passo-passo, segnalare rischi attorno a validazione e stati disabilitati e suggerire di eseguire i test esistenti (o aggiungerne 2-3) prima della sweep finale.
Se lo fai in Koder.ai, fai uno snapshot prima del refactor e un altro dopo che i test passano, così il rollback è un click se qualcosa non va.
Bug fix: il ragionamento batte la velocità
Quando risolvi un bug, il modello più veloce raramente è la strada più rapida verso la soluzione. Fixare bug è per lo più leggere: devi capire il codice esistente, collegarlo all'errore e cambiare il meno possibile.
Un buon workflow è uguale indipendentemente dallo stack: riprodurre il bug, isolare dove accade, proporre la patch più piccola e sicura, verificarla e poi aggiungere una piccola guardia per evitare il ritorno.
Per il miglior LLM per ogni task, qui scegli modelli noti per ragionamento accurato e lettura del codice, anche se costano un po' di più o rispondono più lentamente.
Per ottenere una risposta utile, fornisci al modello gli input giusti. Un prompt vago come “crasha” porta a congetture.
- Testo d'errore e stack trace esatti (completi, non parafrasati)
- Passi per riprodurre (click-by-click o chiamate API)
- Comportamento atteso vs effettivo
- File o funzioni rilevanti (e dettagli di config/env)
- Cosa hai già provato (per evitare ripetizioni)
Chiedi al modello di spiegare la diagnosi prima di modificare il codice. Se non riesce a indicare chiaramente la linea o la condizione fallante, non è pronto per la patch.
Dopo la proposta di fix, richiedi una breve checklist di verifica. Per esempio, se un form React invia due volte dopo un refactor, la checklist dovrebbe includere comportamento UI e API.
- Confermare che il bug è risolto usando gli stessi passi di riproduzione
- Eseguire i test più vicini (o aggiungerne uno piccolo)
- Controllare i flussi correlati che condividono lo stesso path di codice
- Revisionare i log per nuovi warning o errori
- Provare un edge case prima considerato a rischio
Se usi Koder.ai, fai uno snapshot prima di applicare le modifiche, poi verifica e rollback rapidi se la fix causa un nuovo problema.
Passo a passo: come scegliere un modello per un task specifico
Comincia nominando il lavoro in parole semplici. “Scrivi copy di onboarding” è diverso da “risolvi un test intermittente” o “refactor di un form React”. L'etichetta conta perché dice quanto rigoroso deve essere l'output.
Poi scegli l'obiettivo principale per questa esecuzione: ti serve la risposta più veloce, il costo più basso o meno retry possibili? Se stai spedendo codice, spesso “meno retry” vince, perché il rifacimento costa più di un modello leggermente più caro.
Un modo semplice per scegliere il miglior LLM per ogni task è partire dal modello più economico che potrebbe avere successo, poi salire solo quando vedi segnali d'allarme.
- Classifica il task per rischio: basso (copy, etichette), medio (nuovi componenti UI), alto (cambi SQL, auth, pagamenti) o “sconosciuto” (bug).
- Decidi cosa ottimizzare oggi: velocità, costo o correttezza con meno scambi.
- Fai il primo tentativo con un modello economico, ma scala se vedi: edge case mancanti, assunzioni traballanti, formattazione incoerente o errori ripetuti.
- Mantieni un prompt standard per tipo di task più un breve acceptance check (cosa deve essere vero prima di incollarlo nell'app).
- Annota il vincitore: modello usato, prompt e cosa ha fallito prima di funzionare.
Per esempio, puoi iniziare un nuovo componente “Profile Settings” con un modello economico. Se dimentica input controllati, rompe tipi TypeScript o ignora il design system, passa a un modello più forte per il pass successivo.
Se usi Koder.ai, tratta la scelta del modello come una regola di routing nel workflow: prima bozza veloce, poi modalità Planning e un acceptance check più severo per le parti che possono rompere la prod. Quando trovi una buona strada, salvala così la prossima build parte più vicina al risultato.
Errori comuni che sprecano tempo e crediti
Trasforma una specifica in un'app
Describe your feature in chat and get a React app plus a Go and PostgreSQL backend.
Il modo più veloce per bruciare budget è trattare ogni richiesta come se avesse bisogno del modello più costoso. Per piccole modifiche UI, rinominare un bottone o scrivere un breve messaggio di errore, un modello premium spesso aggiunge costo senza valore. Dà l'impressione di “sicurezza” perché l'output è rifinito, ma paghi potenza che non ti serve.
Un'altra trappola comune sono i prompt vaghi. Se non dici cosa significa “fatto”, il modello deve indovinare. Quell'indovinare si trasforma in scambi extra, più token e riscritture. Il modello non è “cattivo” qui, semplicemente non gli hai dato un obiettivo.
Ecco gli errori che compaiono più spesso nel lavoro reale:
- Pagare prezzi top-tier per lavori facili come editing copy, markup React semplice o formattazione JSON
- Chiedere “fix this bug” senza passi di riproduzione, comportamento atteso e messaggio d'errore esatto
- Saltare la verifica (nessun run dei test, nessun click-through UI, nessun EXPLAIN o spot-check SQL)
- Lasciare che il modello refactorizzi più file insieme, rendendo la review lenta e il rollback rischioso
- Mischiare obiettivi in un solo prompt (nuova copy + nuova architettura + nuovo codice) e ottenere output confuso
Un esempio pratico: chiedi una “checkout page migliore” e incolli un componente. Il modello aggiorna UI, cambia gestione dello stato, modifica la copy e aggiusta le chiamate API. Ora non capisci cosa ha causato il nuovo bug. Un percorso più economico e veloce è dividerlo: prima varianti di copy, poi una piccola modifica React, poi una correzione separata.
Se usi Koder.ai, usa snapshot prima di grandi modifiche così puoi rollback rapidamente, e tieni la modalità Planning per decisioni architetturali importanti. Quella sola abitudine ti aiuta a seguire il miglior LLM per ogni task invece di usare un unico modello per tutto.
Checklist rapida, esempio realistico e prossimi passi
Se vuoi il miglior LLM per ogni task, una routine semplice batte l'indovinare. Inizia dividendo il lavoro in parti piccole, poi abbina ogni parte al comportamento del modello che ti serve (bozza veloce, coding attento o ragionamento profondo).
Checklist rapida prima di premere “run”
Usala come guardrail finale per non bruciare tempo e crediti:
- Definisci l'output: copy, UI, SQL o fix (un solo obiettivo per prompt).
- Scegli il modello per rischio: bozza a basso rischio può essere veloce; dati e logica devono essere attenti.
- Chiedi modifiche in stile diff e casi limite (empty state, errori, loading).
- Aggiungi un controllo di sicurezza per lavori sui dati (parametri, vincoli, migration reversibili).
- Rilancia lo stesso prompt su un modello più forte se il risultato deve essere spedito oggi.
Esempio realistico: aggiungere una pagina Settings
Supponi di aver bisogno di una nuova Settings page con: (1) copy UI aggiornato, (2) una pagina React con stati di form e (3) un nuovo campo DB come marketing_opt_in.
Inizia con un modello veloce e a basso costo per redigere microcopy e etichette. Poi passa a un modello “correttezza-first” per il componente React: routing, validazione del form, stati di loading ed error, pulsanti disabilitati durante il salvataggio.
Per il cambiamento al database, usa un modello attento per la migration e gli aggiornamenti delle query. Chiedi di includere un piano di rollback, valori di default e un passaggio di backfill sicuro se le righe esistenti ne hanno bisogno.
Controlli di accettazione per mantenerlo sicuro: conferma focus da tastiera e label, testa stati vuoti ed error, verifica che le query siano parametrizzate e fai una piccola regressione su tutte le schermate che leggono le impostazioni utente.
Prossimi passi: in Koder.ai prova modelli OpenAI, Anthropic e Gemini per task diversi invece di forzare un modello unico. Usa Planning Mode per cambi ad alto rischio e fatti aiutare da snapshot e rollback quando sperimenti.