22 set 2025·7 min
Mantieni il codice generato manutenibile: la regola dell'architettura noiosa
Scopri come mantenere il codice generato manutenibile con la regola dell'architettura noiosa: confini di cartelle chiari, naming coerente e default semplici che riducono il lavoro futuro.
Perché la manutenibilità è più difficile con il codice generato
Il codice generato cambia il lavoro quotidiano. Non stai solo costruendo funzionalità, ma guidando un sistema che può creare molti file rapidamente. La velocità è reale, ma piccole incoerenze si moltiplicano in fretta.
L'output generato spesso sembra corretto isolatamente. I costi emergono al secondo e terzo cambiamento: non capisci dove una parte debba stare, correggi lo stesso comportamento in due posti, o eviti di toccare un file perché non sai cos'altro può influenzare.
La struttura “astuta” diventa costosa perché è difficile da prevedere. Pattern personalizzati, magie nascoste e astrazioni pesanti hanno senso il primo giorno. Alla sesta settimana, la modifica successiva rallenta perché devi riapprendere il trucco prima di poter aggiornare in sicurezza. Con la generazione assistita da AI, quell’astuzia può anche confondere futuri generatori e portare a logiche duplicate o nuovi strati sovrapposti.
L'architettura noiosa è l'opposto: confini semplici, nomi chiari e default ovvi. Non si tratta di perfezione. Si tratta di scegliere una disposizione che un collega stanco (o il tuo futuro io) possa capire in 30 secondi.
Un obiettivo semplice: rendere la modifica successiva facile, non impressionante. Questo di solito significa un unico posto chiaro per ogni tipo di codice (UI, API, dati, utilità condivise), nomi prevedibili che corrispondono a ciò che un file fa, e il minimo di “magia” come wiring automatico, globali nascosti o metaprogrammazione.
Esempio: se chiedi a Koder.ai di aggiungere le “invitazioni team”, vuoi che metta l'interfaccia nell'area UI, aggiunga una route API nell'area API e salvi i dati degli inviti nel layer dati, senza inventare una nuova cartella o pattern solo per quella feature. Quella coerenza noiosa è ciò che mantiene economiche le modifiche future.
La regola dell'architettura noiosa
Il codice generato diventa costoso quando offre molti modi per fare la stessa cosa. La regola dell'architettura noiosa è semplice: rendi la prossima modifica prevedibile, anche se la prima versione sembra meno elegante.
Dovresti poter rispondere a queste domande rapidamente:
- Dove vive questa feature?
- Dove devo mettere un nuovo file?
- Come dovrei chiamarlo?
- Qual è il percorso più semplice da UI a dati?
La regola
Scegli una struttura semplice e usala ovunque. Quando uno strumento (o un collega) suggerisce un pattern sofisticato, la risposta predefinita è “no” a meno che non risolva un dolore reale.
Default pratici che reggono nel tempo:
- Una responsabilità per cartella e per file. Se un file ha due motivi per cambiare, separalo.
- Prevedibilità > flessibilità. Lo stesso tipo di cosa va nello stesso posto, ogni volta.
- Preferisci l'approccio standard del tuo stack rispetto a mini-framework personalizzati.
- Rendi il percorso felice ovvio. I nuovi contributori dovrebbero indovinare la posizione giusta senza chiedere.
- Rifiuta la “magia.” Evita comportamenti nascosti, trucchi basati su reflection e astrazioni troppo intelligenti.
Un rapido test mentale
Immagina che un nuovo sviluppatore apra il tuo repository e debba aggiungere un pulsante “Annulla abbonamento”. Non dovrebbe dover imparare prima un'architettura personalizzata. Dovrebbe trovare una chiara area della feature, un componente UI chiaro, un singolo luogo per il client API e un unico percorso di accesso ai dati.
Questa regola funziona particolarmente bene con strumenti di generazione veloce come Koder.ai: puoi generare rapidamente, ma devi comunque guidare l'output negli stessi confini noiosi ogni volta.
Confini di cartelle semplici che scalano
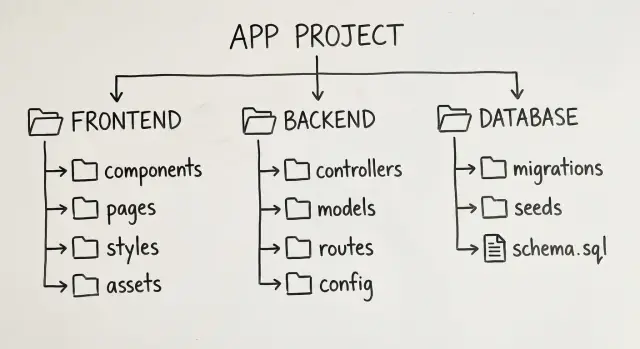
Il codice generato tende a crescere velocemente. Il modo più sicuro per mantenerlo manutenibile è una mappa di cartelle noiosa dove chiunque può indovinare dove appartiene una modifica.
Una piccola struttura top-level che si adatta a molte web app:
app/schermate, routing e stato a livello di paginacomponents/pezzi riusabili di UIfeatures/una cartella per feature (billing, projects, settings)api/codice client API e helper per le richiesteserver/handler backend, servizi e regole di business
Questo rende i confini ovvi: la UI sta in app/ e components/, le chiamate API stanno in api/, e la logica backend sta in server/.
L'accesso ai dati dovrebbe essere noioso anche lui. Tieni query SQL e codice repository vicino al backend, non sparse nei file UI. In una configurazione Go + PostgreSQL, una regola semplice è: gli HTTP handler chiamano i servizi, i servizi chiamano i repository, i repository parlano al database.
Tipi condivisi e utilità meritano una casa chiara, ma mantienila piccola. Metti i tipi cross-cutting in types/ (DTO, enum, interfacce condivise) e piccoli helper in utils/ (formattazione date, validatori semplici). Se utils/ inizia a sembrare una seconda app, probabilmente il codice appartiene a una cartella feature.
Generato vs scritto a mano
Tratta le cartelle generate come sostituibili.
- Metti l'output generato in
generated/(ogen/) ed evita di modificarlo direttamente. - Tieni la logica personalizzata in
features/oserver/così la rigenerazione non la sovrascrive. - Se devi patchare un comportamento generato, wrapparlo (file adapter) invece di modificare la sorgente.
Esempio: se Koder.ai genera un client API, mettilo sotto generated/api/, poi scrivi sottili wrapper in api/ dove aggiungere retry, logging o messaggi d'errore più chiari senza toccare i file generati.
Convenzioni di naming che prevengono confusione
Il codice generato è facile da creare e da accumulare. Il naming è ciò che lo mantiene leggibile un mese dopo.
Scegli uno stile di naming e non mescolarlo:
- Cartelle e file:
kebab-case(user-profile-card.tsx,billing-settings) - Componenti React:
PascalCase(UserProfileCard) - Funzioni e variabili:
camelCase(getUserProfile) - Costanti:
SCREAMING_SNAKE_CASE(MAX_RETRY_COUNT)
Nome per ruolo, non per come funziona oggi. user-repository.ts è un ruolo. postgres-user-repository.ts è un dettaglio di implementazione che potrebbe cambiare. Usa suffissi di implementazione solo quando hai davvero più implementazioni.
Evita cassetti tipo misc, helpers o un enorme utils. Se una funzione è usata solo da una feature, tienila vicino a quella feature. Se è condivisa, fai in modo che il nome descriva la capacità (date-format.ts, money-format.ts, id-generator.ts) e mantieni il modulo piccolo.
Convenzioni che rendono la navigazione veloce
Quando route, handler e componenti seguono un pattern, puoi trovare le cose senza cercare:
- Routes:
routes/users.tscon percorsi come/users/:userId - Handler (HTTP):
handlers/users.get.ts,handlers/users.update.ts - Services (regole di business):
services/user-profile-service.ts - Data access:
repositories/user-repository.ts - Componenti UI:
components/user/UserProfileCard.tsx
Se usi Koder.ai (o qualsiasi generatore), metti queste regole nel prompt e mantienile coerenti durante le modifiche. Il punto è la prevedibilità: se puoi indovinare il nome del file, le modifiche future restano economiche.
Default senza astuzie (regole pratiche)
Dal repo all'app in esecuzione
Pubblica una build manutenibile con il deployment e l'hosting di Koder.ai quando sei pronto.
Il codice generato può sembrare impressionante il primo giorno e doloroso il trentesimo. Scegli default che rendano il codice ovvio, anche quando è un po' ripetitivo.
Inizia riducendo la magia. Salta il caricamento dinamico, i trucchi in stile reflection e l'auto-wiring a meno che non ci sia un bisogno misurato. Queste feature nascondono da dove provengono le cose, rendendo debugging e refactor più lenti.
Preferisci import espliciti e dipendenze chiare. Se un file ha bisogno di qualcosa, importalo direttamente. Se i moduli necessitano wiring, fallo in un unico posto visibile (per esempio, un file di composizione). Un lettore non dovrebbe dover indovinare cosa gira prima.
Tieni la configurazione noiosa e centralizzata. Metti variabili d'ambiente, feature flag e impostazioni globali in un modulo con uno schema di naming unico. Non spargere la config in file casuali perché pareva comodo.
Regole pratiche per mantenere la coerenza nel team:
- Scegli esplicito su implicito (import, routing, DI, effetti collaterali).
- Se risparmi 10 righe ma aggiungi un nuovo concetto, evita.
- Mantieni un modo per fare le cose (uno strumento di logging, un modulo config).
- Preferisci flusso di dati semplice a osservatori nascosti o catene di eventi.
- Quando fai debugging, elimina prima il codice astuto.
La gestione degli errori è dove l'astuzia fa più male. Scegli un pattern e usalo dappertutto: ritorna errori strutturati dal layer dati, mappali in risposte HTTP in un solo posto e traducili in messaggi per l'utente al confine UI. Non lanciare tre tipi di errori diversi a seconda del file.
Se generi un'app con Koder.ai, chiedi questi default fin dall'inizio: wiring esplicito dei moduli, config centralizzata e un unico pattern per gli errori.
Confini tra UI, API e dati
Linee chiare tra UI, API e dati mantengono le modifiche contenute. La maggior parte dei bug misteriosi succede quando un layer comincia a fare il lavoro di un altro layer.
UI: mostrare stato, raccogliere input
Tratta la UI (spesso React) come luogo per renderizzare schermate e gestire stato solo UI: quale tab è aperto, errori di form, spinner di caricamento e gestione base degli input.
Tieni separato lo stato server: liste fetchate, profili in cache e qualsiasi cosa che debba corrispondere al backend. Quando i componenti UI iniziano a calcolare totali, validare regole complesse o decidere permessi, la logica si sparge tra le schermate e diventa costosa da cambiare.
API: forme sottili e stabili
Mantieni il layer API prevedibile. Dovrebbe tradurre richieste HTTP in chiamate a codice di business e poi trasformare i risultati in shape di request/response stabili. Evita di inviare modelli del database direttamente sulla wire. Risposte stabili ti permettono di rifattorizzare l'interno senza rompere la UI.
Un percorso semplice che funziona bene:
- La UI chiama un client API con oggetti request/response tipizzati.
- Gli handler API validano l'input e chiamano un metodo del service.
- I service contengono regole di business e workflow.
- I repository nascondono le query al database dietro piccoli metodi.
Dati: nascondi le query dietro repository
Metti SQL (o logica ORM) dietro un confine repository così il resto dell'app non “sa” come i dati sono memorizzati. In Go + PostgreSQL, questo di solito significa repository come UserRepo o InvoiceRepo con metodi piccoli e chiari (GetByID, ListByAccount, Save).
Esempio concreto: aggiungere codici sconto. La UI mostra un campo e aggiorna il prezzo. L'API accetta code e ritorna {total, discount}. Il service decide se il codice è valido e come si combinano gli sconti. Il repository recupera e persiste le righe necessarie.
Passo dopo passo: impostare codice generato manutenibile
Le app generate possono sembrare “finte” rapidamente, ma è la struttura che mantiene le modifiche economiche nel tempo. Decidi prima regole noiose, poi genera solo il codice necessario per dimostrarle.
Un flusso pratico di setup
Inizia con una breve fase di pianificazione. Se usi Koder.ai, la Planning Mode è un buon posto per scrivere una mappa di cartelle e poche regole di naming prima di generare qualsiasi cosa.
Poi segui questa sequenza:
- Definisci la mappa e le regole per iscritto. Scegli confini (per esempio:
ui/,api/,data/,features/) e un piccolo set di regole di naming. - Genera una thin vertical slice. Scegli una piccola feature che tocchi UI, API e storage, come “crea un contatto.” L'obiettivo è il percorso end-to-end, non la completezza.
- Refattorizza subito per aderire ai confini. Sposta il codice nelle cartelle pianificate, rinomina file poco chiari e cancella duplicati. Separa funzioni che “fanno tutto” in UI, handler e accesso ai dati.
- Aggiungi una seconda feature per testare la forma. Scegli qualcosa di simile, come “elenca contatti.” Se ti senti costretto a infrangere le regole, probabilmente i confini sono sbagliati.
- Blocca le convenzioni presto. Aggiungi un breve
CONVENTIONS.mde trattalo come un contratto. Una volta che il codebase cresce, cambiare nomi e pattern di cartelle diventa costoso.
Reality check: se una nuova persona non riesce a indovinare dove mettere “modifica contatto” senza chiedere, l'architettura non è ancora abbastanza noiosa.
Scenario esemplare: aggiungere una feature senza creare disordine
Segnala e guadagna crediti
Usa il tuo referral per portare altri e guadagnare crediti mentre costruisci.
Immagina un CRM semplice: una pagina lista contatti e un form di modifica contatto. Costruisci la prima versione velocemente, poi una settimana dopo devi aggiungere “tag” ai contatti.
Tratta l'app come tre scatole noiose: UI, API e dati. Ogni scatola ha confini chiari e nomi letterali così la modifica “tag” resta piccola.
Una disposizione pulita potrebbe essere:
web/src/pages/ContactsPage.tsxeweb/src/components/ContactForm.tsxserver/internal/http/contacts_handlers.goserver/internal/service/contacts_service.goserver/internal/repo/contacts_repo.goserver/migrations/
Ora “tag” diventa prevedibile. Aggiorni lo schema (nuova tabella contact_tags o una colonna tags), poi tocchi uno strato alla volta: il repo legge/scrive i tag, il service valida, l'handler espone il campo e la UI lo rende e modifica. Non infilare SQL negli handler né regole di business nei componenti React.
Se il product chiede dopo “filtra per tag”, lavorerai principalmente in ContactsPage.tsx (stato UI e query params) e nell'HTTP handler (parsing della richiesta), mentre il repo gestirà la query.
Per test e fixture, mantieni le cose piccole e vicine al codice:
server/internal/service/contacts_service_test.goper regole come “i nomi tag devono essere unici per contatto”server/internal/repo/testdata/per fixture minimeweb/src/components/__tests__/ContactForm.test.tsxper il comportamento del form
Se stai generando questo con Koder.ai, la stessa regola vale dopo l'export: mantieni le cartelle noiose, i nomi letterali e le modifiche smettono di sembrare archeologia.
Errori comuni che rendono le modifiche future costose
Il codice generato può sembrare pulito il primo giorno e comunque essere costoso dopo. Il colpevole usuale non è il “codice cattivo”, ma l'incoerenza.
Un'abitudine costosa è lasciare che il generatore inventi una struttura ogni volta. Una feature arriva con cartelle proprie, stile di naming e helper, e ti ritrovi con tre modi diversi per fare la stessa cosa. Scegli un pattern, scrivilo e tratta ogni nuovo pattern come una modifica consapevole, non come predefinito.
Un'altra trappola è mescolare i layer. Quando un componente UI parla al database, o un handler API costruisce SQL, le piccole modifiche diventano edit rischiosi attraverso tutta l'app. Mantieni il confine: la UI chiama un'API, l'API chiama un service, il service chiama l'accesso ai dati.
Abusare di astrazioni generiche troppo presto aggiunge anche costo. Un “BaseService” universale o un framework di repository sembra elegante, ma le astrazioni iniziali sono ipotesi. Quando la realtà cambia, combatti il tuo stesso framework invece di consegnare.
Rinomine e riorganizzazioni costanti sono una forma più silenziosa di debito. Se i file si spostano ogni settimana, le persone smettono di fidarsi della disposizione e le soluzioni rapide finiscono in posti casuali. Stabilizza la mappa delle cartelle prima, poi rifattorizza a blocchi pianificati.
Infine, fai attenzione al “codice di piattaforma” che non ha utenti reali. Librerie condivise e tool fatti in casa ripagano solo quando hai bisogni ripetuti e provati. Fino ad allora, mantieni i default diretti.
Una checklist rapida prima della spedizione
Ricevi ricompense per l'insegnamento
Guadagna crediti condividendo ciò che hai costruito con Koder.ai e le convenzioni che hai usato.
Se qualcuno nuovo apre il repo, dovrebbe poter rispondere a una domanda velocemente: “Dove aggiungo questo?”
Test di navigazione in 2 minuti
Affida il progetto a un collega (o al tuo futuro io) e chiedigli di aggiungere una piccola feature, tipo “aggiungi un campo al form di signup.” Se non trova il posto giusto rapidamente, la struttura non sta facendo il suo lavoro.
Controlla tre case chiare:
- Le modifiche UI vivono in un posto ovvio.
- Le route/handler API sono facili da trovare a partire dalla UI.
- Il modello dati e le modifiche al database hanno una posizione chiara.
Regole da far rispettare in review
- UI, API e dati hanno ognuno una casa, e le eccezioni sono rare.
- I nomi si leggono come etichette, non come puzzle.
- I fori tra i layer vengono segnalati (per esempio UI che accede al database).
- Le scorciatoie astute vengono rifiutate di default.
Se la tua piattaforma lo supporta, mantieni una strada di rollback. Snapshot e rollback sono particolarmente utili quando sperimenti con la struttura e vuoi tornare indietro in sicurezza.
Passi successivi: mantieni noioso, mantieni economico
La manutenibilità migliora più in fretta quando smetti di discutere di stile e cominci a prendere poche decisioni che restano.
Scrivi un piccolo set di convenzioni che rimuova l'esitazione quotidiana: dove vanno i file, come si chiamano e come gestire errori e config. Mantienilo abbastanza breve da leggerlo in un minuto.
Poi fai una passata di pulizia per aderire a quelle regole e smetti di riorganizzare ogni settimana. Riorganizzare frequentemente rallenta la modifica successiva, anche se il codice sembra più bello.
Se costruisci con Koder.ai (koder.ai), aiuta salvare queste convenzioni come prompt iniziale così ogni nuova generazione atterri nella stessa struttura. Lo strumento può muoversi velocemente, ma sono i confini noiosi che mantengono il codice facile da cambiare.