Il problema reale: perdite, rallentamenti e risultati incoerenti
Filtrare in una UI è più di una singola casella di ricerca. Di solito include alcune azioni correlate che cambiano ciò che l'utente vede: ricerca testuale (nome, email, ID ordine), facet (stato, proprietario, intervallo di date, tag) e ordinamento (più recenti, valore più alto, ultima attività).
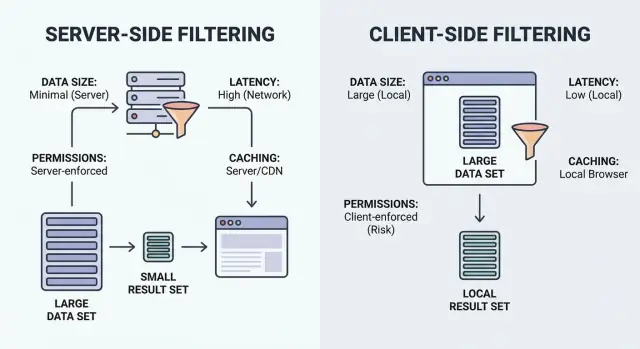
La domanda chiave non è quale tecnica sia “migliore”. È dove risiede il dataset completo e chi è autorizzato ad accederci. Se il browser riceve record che l'utente non dovrebbe vedere, un'interfaccia può esporre dati sensibili anche se li nascondi visivamente.
La maggior parte dei dibattiti su server-side vs client-side filtering sono in realtà reazioni a due fallimenti che gli utenti notano subito:
- Perdite: i dati compaiono nei payload di rete, nelle risposte in cache o attraverso filtri inattesi che rivelano righe nascoste.
- Rallentamenti: lo schermo sembra lento perché mandi troppi dati e poi fai eseguire al dispositivo lavori pesanti ad ogni battitura.
C'è un terzo problema che genera segnalazioni infinite di bug: risultati incoerenti. Se alcuni filtri vengono eseguiti sul client e altri sul server, gli utenti vedono conteggi, pagine e totali che non corrispondono. Questo rompe la fiducia rapidamente, specialmente nelle liste paginate.
Una regola pratica semplice: se l'utente non è autorizzato ad accedere all'intero dataset, filtra sul server. Se lo è e il dataset è abbastanza piccolo da caricare velocemente, il filtraggio client-side può andar bene.
Definizioni rapide in parole semplici
Filtrare è solo “mostrami gli elementi che corrispondono”. La domanda chiave è dove avviene il matching: nel browser dell'utente (client) o nel tuo backend (server).
Filtraggio lato client viene eseguito nel browser. L'app scarica un insieme di record (spesso JSON), poi applica i filtri localmente. Può sembrare immediato dopo il caricamento dei dati, ma funziona solo quando il dataset è abbastanza piccolo da inviare e sicuro da esporre.
Filtraggio lato server viene eseguito nel tuo backend. Il browser invia i criteri di filtro (come status=open, owner=me, createdAfter=Jan 1) e il server restituisce solo i risultati corrispondenti. In pratica è solitamente un endpoint API che accetta filtri, costruisce una query al database e restituisce una lista paginata più i totali.
Un modello mentale semplice:
- Client-side: scarica molti, filtra qui.
- Server-side: chiedi esattamente ciò di cui hai bisogno.
Gli setup ibridi sono comuni. Un buon pattern è far rispettare i filtri “pesanti” sul server (permessi, proprietà, intervallo di date, ricerca), poi usare piccoli toggle solo UI localmente (nascondi elementi archiviati, chip rapidi dei tag, visibilità colonne) senza fare un'altra richiesta.
Ordinamento, paginazione e ricerca di solito appartengono alla stessa decisione. Influenzano la dimensione del payload, la sensazione dell'utente e quali dati stai esponendo.
Fattore decisionale 1: dimensione dei dati e costo del payload
Inizia con la domanda più pratica: quanta informazione invieresti al browser se filtrassi sul client? Se la risposta sincera è “più di qualche schermata”, lo pagherai in tempo di download, uso di memoria e interazioni più lente.
Non servono stime perfette. Prendi solo l'ordine di grandezza: quante righe potrebbe vedere l'utente e qual è la dimensione media di una riga? Una lista di 500 elementi con pochi campi corti è molto diversa da 50.000 elementi dove ogni riga include note lunghe, testo ricco o oggetti annidati.
I record larghi sono il killer silenzioso del payload. Una tabella può sembrare piccola per numero di righe ma essere pesante se ogni riga contiene molti campi, stringhe lunghe o dati joinati (contatto + azienda + ultima attività + indirizzo completo + tag). Anche se mostri solo tre colonne, le squadre spesso inviano “tutto, nel caso” e il payload esplode.
Pensa anche alla crescita. Un dataset che oggi va bene può diventare problematico dopo pochi mesi. Se i dati crescono rapidamente, considera il filtraggio client-side come una scorciatoia a breve termine, non come default.
Regole pratiche:
- Se non puoi inviare comodamente l'intero dataset su una connessione mobile tipica, filtra sul server.
- Se gli utenti toccano solo una piccola fetta alla volta, recupera quella fetta e filtra lato server.
- Se il dataset è piccolo, stabile e davvero sicuro da esporre, il filtraggio client-side può risultare molto reattivo.
Quest'ultimo punto conta per più della sola performance. “Possiamo inviare l'intero dataset al browser?” è anche una domanda di sicurezza. Se la risposta non è un sì sicuro, non inviarlo.
Fattore decisionale 2: latenza e percezione dell'utente
Le scelte di filtraggio falliscono spesso sulla percezione, non sulla correttezza. Gli utenti non misurano i millisecondi. Notano pause, sfarfallii e risultati che saltano mentre digitano.
Il tempo può sparire in posti diversi:
- Rete: tempo di richiesta/risposta e dimensione del payload
- Server: query al database, join, ordinamenti, controlli di permessi
- Browser: parsing JSON, rendering delle righe, filtrare grandi array
Definisci cosa significa “abbastanza veloce” per questa schermata. Una vista lista potrebbe richiedere digitazione reattiva e scrolling fluido, mentre una pagina report può tollerare una breve attesa purché il primo risultato appaia rapidamente.
Non giudicare solo sulla Wi‑Fi ufficio. Su connessioni lente, il filtraggio client-side può sembrare ottimo dopo il primo caricamento, ma quel primo caricamento potrebbe essere la parte lenta. Il filtraggio server-side mantiene i payload piccoli, ma può sembrare lento se mandi una richiesta ad ogni battitura.
Progetta attorno all'input umano. Usa debounce durante la digitazione. Per grandi set di risultati, usa caricamento progressivo in modo che la pagina mostri qualcosa rapidamente e resti fluida mentre l'utente scorre.
Fattore decisionale 3: permessi ed esposizione dei dati
I permessi dovrebbero decidere l'approccio più della velocità. Se il browser riceve mai dati che un utente non può vedere, hai già un problema, anche se li nascondi dietro un bottone disabilitato o una colonna collassata.
Inizia nominando cosa è sensibile in questa schermata. Alcuni campi sono ovvi (email, numeri di telefono, indirizzi). Altri sono facili da trascurare: note interne, costi o margini, regole di prezzo speciali, punteggi di rischio, flag di moderazione.
La grande trappola è “filtriamo sul client, ma mostriamo solo le righe consentite”. Questo significa comunque che l'intero dataset è stato scaricato. Chiunque può ispezionare la risposta di rete, aprire dev tools o salvare il payload. Nascondere colonne nella UI non è controllo di accesso.
Quando il filtraggio lato server è il default sicuro
Il filtraggio lato server è il default più sicuro quando l'autorizzazione varia per utente, specialmente quando utenti diversi possono vedere righe diverse o campi diversi.
Controllo rapido:
- Ruoli diversi vedono righe diverse (solo team, solo regione, assegnato a me)?
- Ruoli diversi vedono campi diversi (note, prezzi, PII)?
- Esistono regole a livello di riga (proprietario account, stage dell'affare, flag “privato”)?
- Esportare, ordinare o i totali potrebbero rivelare informazioni protette?
- Un payload trapelato creerebbe problemi di conformità?
Se una qualsiasi risposta è sì, tieni il filtraggio e la selezione campi sul server. Invia solo ciò che l'utente può vedere ed applica le stesse regole a ricerca, ordinamento, paginazione ed export.
Esempio: in una lista contatti CRM, i venditori possono vedere solo i propri account mentre i manager vedono tutto. Se il browser scarica tutti i contatti e filtra localmente, un venditore può comunque recuperare account nascosti dalla risposta. Il filtraggio server-side previene questo non inviando mai quelle righe.
Fattore decisionale 4: caching e freschezza
Il caching può far sembrare una schermata istantanea. Può anche mostrare la verità sbagliata. La chiave è decidere cosa puoi riutilizzare, per quanto tempo e quali eventi devono invalidarlo.
Inizia scegliendo l'unità di cache. Caching dell'intera lista è semplice ma di solito spreca banda e diventa obsoleto in fretta. Caching per pagine funziona bene per lo scroll infinito. Caching di risultati di query (filtro + ordinamento + ricerca) è accurato, ma può crescere velocemente se gli utenti provano molte combinazioni.
La freschezza conta di più in alcuni domini. Se i dati cambiano rapidamente (livelli di stock, saldi, stato consegne), anche una cache di 30 secondi può confondere gli utenti. Se i dati cambiano lentamente (record archiviati, dati di riferimento), caching più lungo va bene.
Pianifica l'invalidamento prima di scrivere codice. Oltre al tempo, decidi cosa deve forzare un refresh: creazioni/modifiche/cancellazioni, cambi permessi, import/bulk merge, transizioni di stato, azioni di undo/rollback e job in background che aggiornano campi usati per filtrare.
Decidi anche dove risiede il caching. La memoria del browser rende rapido il back/forward, ma può perdere dati tra account se non la chiavi per utente e org. Il caching backend è più sicuro per permessi e consistenza, ma deve includere la firma completa dei filtri e l'identità del chiamante così i risultati non si mescolano.
Passo dopo passo: come scegliere per una nuova schermata
Tratta l'obiettivo come non negoziabile: la schermata deve sembrare veloce senza perdere dati.
Un flusso decisionale pratico
- Inizia dal vincolo più forte. Se l'accesso varia per ruolo, team, regione, org o sottoscrizione, vincono i permessi. Se il dataset è grande o può crescere rapidamente, vince la dimensione.
- Di default usa il lato server quando i dati sono grandi o sensibili. Se non saresti a tuo agio a loggare l'intero dataset nella console del browser, non spedirlo.
- Usa il filtraggio client-side solo per liste piccole, sicure e riutilizzate. Dropdown di stato, piccoli elenchi di tag, una singola pagina di risultati già approvati.
- Definisci l'API prima della UI. Scrivi i filtri, l'ordinamento, la paginazione e i valori predefiniti in modo che server e UI non possano essere in disaccordo.
- Aggiungi guardrail. Applica un max page size, imposta timeout e decidi come si comporta la UI quando il filtraggio è lento (mostra spinner, conserva i risultati vecchi, offre retry).
Errori comuni che causano perdite o rallentamenti
La maggior parte dei team viene colpita dagli stessi pattern: una UI che in demo sembra ottima, poi con dati reali, permessi reali e reti reali mostra le crepe.
Errori che perdono dati
Il fallimento più grave è trattare il filtraggio come presentazione. Se il browser riceve record che non dovrebbe avere, hai già perso.
Due cause comuni:
- Inviare l'intero dataset al browser e filtrare localmente “per velocità”. Chiunque può ispezionare la risposta o interrogare i dati in memoria.
- Caching di risposte filtrate senza legare la chiave di cache a identità utente, org, ruolo o versione della policy. Un cambio di permessi può esporre dati vecchi in modo silenzioso.
Esempio: gli stagisti dovrebbero vedere solo lead della loro regione. Se l'API restituisce tutte le regioni e il dropdown filtra in React, gli stagisti possono comunque estrarre l'elenco completo.
Errori che rendono la schermata lenta
Il rallentamento spesso nasce da assunzioni:
- Assumere che il filtraggio client-side sia sempre più veloce. Con 50.000 righe, scaricare e parsare può richiedere più tempo di una query mirata.
- Dimenticare paginazione e stati di caricamento. Una schermata che blocca mentre renderizza una lista enorme sembra rotta anche se la query è corretta.
Un problema sottile ma doloroso sono regole non corrispondenti. Se il server tratta “starts with” diversamente dalla UI, gli utenti vedono conteggi che non corrispondono o elementi che scompaiono dopo il refresh.
Checklist rapida prima di rilasciare
Fai un controllo finale con due mentalità: un utente curioso e una giornata con rete pessima.
- Sanità del payload: conferma che le risposte non includano mai righe o campi che l'utente non dovrebbe vedere, anche se la UI li nasconde. Fai attenzione a totali, conteggi di gruppo o ID che permettono di dedurre dati protetti.
- Log sicuri: i filtri spesso includono email, nomi o ID. Non registrare valori sensibili dei filtri, SQL completo o corpi di richiesta completi in posti accessibili a molti.
- Coerenza tra dispositivi: applica gli stessi filtri su desktop e mobile. Le differenze spesso derivano da ordinamenti client-side, regole locali (case, accenti) o valori predefiniti differenti.
- Stati chiari: loading, empty e error devono essere evidenti. Testa cambi rapidi (digitare, cancellare, toggle) in modo che la UI non sfarfalli o mostri risultati obsoleti.
- Guardrail worst-case: max page size, max intervallo di date e timeout. Proteggi contro query costose (wildcard, troppe condizioni OR, campi non indicizzati).
Un test semplice: crea un record ristretto e conferma che non appaia mai nel payload, nei conteggi o nella cache, anche quando filtri in modo ampio o cancelli i filtri.
Scenario d'esempio: una lista contatti CRM
Immagina un CRM con 200.000 contatti. I venditori vedono solo i propri account, i manager vedono il team e gli admin vedono tutto. La schermata ha ricerca, filtri (stato, proprietario, ultima attività) e ordinamento.
Il filtraggio client-side fallisce rapidamente qui. Il payload è pesante, il primo caricamento diventa lento e il rischio di perdita dati è alto. Anche se la UI nasconde righe, il browser ha comunque ricevuto i dati. Metti anche pressione sul dispositivo: grandi array, ordinamenti pesanti, esecuzioni ripetute di filtri, alto uso di memoria e crash su telefoni più vecchi.
Un approccio più sicuro è il filtraggio lato server con paginazione. Il client invia le scelte di filtro e il server restituisce solo righe che l'utente può vedere, già filtrate e ordinate.
Un pattern pratico:
- Applica prima i permessi, poi filtri e ordinamento.
- Restituisci una pagina alla volta (per esempio 50 righe) più un conteggio totale.
- Cache con attenzione (per utente o per ruolo) così non mescoli risultati tra permessi diversi.
Una piccola eccezione in cui il filtraggio client-side va bene: dati minuscoli e statici. Un dropdown “Stato contatto” con 8 valori può essere caricato una volta e filtrato localmente con poco rischio o costo.
Prossimi passi: documenta le decisioni e costruisci evitando riscritture
I team di solito non vengono bruciati da aver scelto l'opzione “sbagliata” una volta. Vengono bruciati dal fare scelte diverse su ogni schermata, poi cercare di correggere perdite e pagine lente sotto pressione.
Scrivi una nota decisionale breve per ogni schermata con i filtri: dimensione del dataset, costo per inviarlo, cosa significa “abbastanza veloce”, quali campi sono sensibili e come i risultati dovrebbero essere cached (o no). Mantieni server e UI allineati così non finisci con “due verità” per il filtraggio.
Se stai costruendo schermate velocemente in Koder.ai (koder.ai), vale la pena decidere in anticipo quali filtri devono essere applicati nel backend (permessi e accesso a livello di riga) e quali piccoli toggle solo UI possono rimanere nel layer React. Quella singola scelta tende a prevenire le riscritture più costose in seguito.