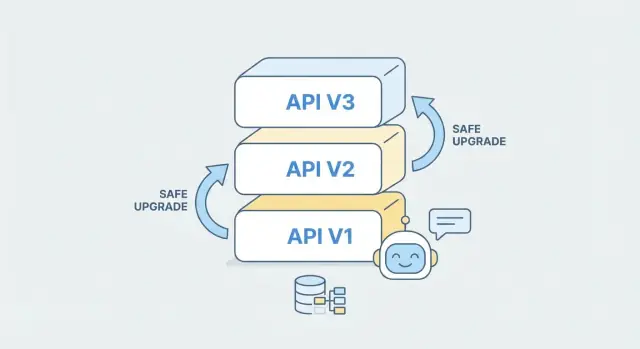
Cosa significa evoluzione delle API per i backend generati da AI
L'evoluzione di un'API è il processo continuo di modificare un'API dopo che è già utilizzata da client reali. Può significare aggiungere campi, modificare regole di validazione, migliorare le prestazioni o introdurre nuovi endpoint. Diventa critico quando i client sono in produzione, perché anche una piccola modifica può rompere una release mobile, uno script di integrazione o il flusso di lavoro di un partner.
Retrocompatibilità, spiegata semplicemente
Una modifica è retrocompatibile se i client esistenti continuano a funzionare senza aggiornamenti.
Per esempio, supponi che la tua API ritorni:
{ "id": "123", "status": "processing" }
Aggiungere un nuovo campo opzionale è tipicamente retrocompatibile:
{ "id": "123", "status": "processing", "estimatedSeconds": 12 }
I client più vecchi che ignorano campi sconosciuti continueranno a funzionare. Invece, rinominare status in state, cambiare il tipo di un campo (stringa → numero) o rendere obbligatorio un campo prima opzionale sono cambiamenti che spesso rompono.
Cosa si intende per “backend generato da AI” qui
Un backend generato da AI non è solo uno snippet di codice. In pratica include:
- Codice API generato (handler, controller, serializer)
- Configurazione (routing, regole di auth, rate limit)
- Colla infrastrutturale (migrazioni, template di deploy, impostazioni d'ambiente)
Poiché l'AI può rigenerare parti del sistema rapidamente, l'API può “deragliare” a meno che non gestisci intenzionalmente le modifiche.
Questo è particolarmente vero quando generi intere app da un workflow guidato via chat. Per esempio, Koder.ai (una piattaforma vibe-coding) può creare applicazioni web, server e mobile da una semplice chat—spesso con React sul web, Go + PostgreSQL nel backend e Flutter per il mobile. Questa velocità è ottima, ma rende la disciplina del contratto (e diff/test automatici) ancora più importante, così una release rigenerata non cambia accidentalmente ciò su cui i client fanno affidamento.
Cosa può essere automatizzato vs. cosa richiede revisione umana
L'AI può automatizzare molto: produrre specifiche OpenAPI, aggiornare codice boilerplate, suggerire default sicuri e persino redigere i passi di migrazione. Ma la revisione umana resta essenziale per decisioni che impattano i contratti dei client—quali cambi sono ammessi, quali campi sono stabili e come gestire edge case e regole di business. L'obiettivo è velocità con comportamento prevedibile, non velocità a costo di sorprese.
Perché la retrocompatibilità è una priorità
Le API raramente hanno un solo “client”. Anche un prodotto piccolo può avere più consumatori che dipendono dagli stessi endpoint:
- Un'app web rilasciata continuamente
- Un'app mobile che aggiorna tramite store più lentamente
- Integrazioni con partner (spesso gestite da team o aziende diverse)
- Servizi interni e automazioni (fatturazione, analytics, strumenti di supporto)
Quando un'API si rompe, il costo non è solo tempo degli sviluppatori. Gli utenti mobile possono restare su vecchie versioni per settimane, quindi una breaking change può trasformarsi in una lunga coda di errori e ticket di supporto. I partner possono subire downtime, perdere dati o bloccare workflow critici—spesso con conseguenze contrattuali o reputazionali. I servizi interni possono fallire silenziosamente e creare arretrati confusi (per esempio, eventi mancanti o record incompleti).
I backend generati da AI aggiungono una complicazione: il codice può cambiare rapidamente e frequentemente, talvolta con diff ampi, perché la generazione è ottimizzata per produrre codice funzionante—non per preservare il comportamento nel tempo. Questa velocità è preziosa, ma aumenta il rischio di cambi accidentali che rompono (campi rinominati, default diversi, validazione più severa, nuovi requisiti di auth).
Per questo la retrocompatibilità deve essere una decisione di prodotto deliberata, non una pratica al risparmio. L'approccio pratico è definire un processo di cambiamento prevedibile dove l'API è trattata come un'interfaccia di prodotto: puoi aggiungere capacità, ma non sorprendere i client esistenti.
Un modello mentale utile è trattare il contratto API (per esempio, una specifica OpenAPI) come la “fonte di verità” per ciò su cui i client possono contare. La generazione diventa allora un dettaglio di implementazione: puoi rigenerare il backend, ma il contratto—e le promesse che fa—rimane stabile a meno che tu non versi intenzionalmente in una nuova versione e lo comunichi.
Il contratto API come fonte di verità
Quando un sistema AI può generare o modificare codice backend rapidamente, l'ancora affidabile è il contratto API: la descrizione scritta di cosa i client possono chiamare, cosa devono inviare e cosa possono aspettarsi indietro.
Cosa significa “contratto” nella pratica
Un contratto è una specifica leggibile dalla macchina come:
- OpenAPI per endpoint REST (paths, parametri, auth, forme di risposta)
- JSON Schema per validare payload di richiesta/risposta (spesso embeddato in OpenAPI)
- Schema GraphQL per tipi, query, mutation e deprecazioni
Questo contratto è ciò che prometti ai consumatori esterni—anche se l'implementazione dietro cambia.
Contract-first vs. code-first (e dove si collocano i generatori)
In un workflow contract-first progetti o aggiorni lo schema OpenAPI/GraphQL prima, poi generi gli stub server e implementi la logica. Questo è generalmente più sicuro per la compatibilità perché le modifiche sono intenzionali e revisionabili.
In un workflow code-first il contratto è prodotto da annotazioni nel codice o introspezione a runtime. I backend generati da AI spesso tendono al code-first di default, il che va bene—a patto che lo spec generato sia trattato come un artefatto da revisionare, non come un ripensamento.
Un ibrido pratico: lascia che l'AI proponga cambiamenti al codice, ma richiedi che aggiorni (o rigeneri) anche il contratto, e considera le diff del contratto come il segnale principale di modifica.
Metti il contratto sotto controllo versione
Conserva le tue specifiche API nello stesso repo del backend e revisionale via pull request. Una regola semplice: niente merge se la modifica del contratto non è compresa e approvata. Questo rende visibili le modifiche retroincompatibili prima che raggiungano la produzione.
Genera server e client dallo stesso sorgente
Per ridurre il drift, genera stub server e SDK client dallo stesso contratto. Quando lo spec si aggiorna, entrambi i lati si aggiornano insieme—rendendo molto più difficile che un'implementazione generata inventi comportamenti che i client non sono stati costruiti per gestire.
Strategie di versioning che funzionano nella pratica
Il versionamento API non serve a prevedere ogni cambiamento futuro—serve a dare ai client un modo chiaro e stabile per continuare a funzionare mentre migliori il backend. In pratica, la strategia “migliore” è quella che i tuoi consumatori capiscono subito e che il tuo team applica con coerenza.
Strategie comuni (e cosa significano per i client)
Versioning in URL mette la versione nel path, come /v1/orders e /v2/orders. È visibile in ogni richiesta, facile da debug e funziona bene con caching e routing.
Versioning via header tiene pulite le URL e sposta la versione in un header (per esempio, Accept: application/vnd.myapi.v2+json). Può essere elegante, ma è meno ovvio durante il troubleshooting e può essere perso in esempi copiati.
Versioning via query param usa qualcosa come /orders?version=2. È semplice, ma può diventare disordinato quando client o proxy alterano le query string, ed è più facile che le persone mescolino versioni accidentalmente.
Raccomandazione di default
Per la maggior parte dei team—specialmente se vuoi che i client capiscano facilmente—usa per default il versioning in URL. È l'approccio meno sorprendente, facile da documentare e rende ovvio quale versione sta chiamando un SDK, un'app mobile o un'integrazione partner.
Come i backend generati da AI possono aiutare
Quando usi l'AI per generare o estendere un backend, tratta ogni versione come un'unità separata “contratto + implementazione”. Puoi scaffoldare una nuova /v2 da uno spec OpenAPI aggiornato mantenendo intatta /v1, poi condividere la logica di business sottostante dove possibile. Questo riduce il rischio: i client esistenti continuano a funzionare, mentre i nuovi client adottano v2 intenzionalmente.
Documentazione e comunicazione dei cambiamenti
Il versioning funziona solo se la documentazione tiene il passo. Mantieni doc API versionate, tieni esempi coerenti per versione e pubblica un changelog che dichiari chiaramente cosa è cambiato, cosa è deprecato e note di migrazione (idealmente con esempi request/response affiancati).
Cambi compatibili vs. breaking: una checklist pratica
Quando un backend generato da AI si aggiorna, il modo più sicuro di pensare alla compatibilità è: “Un client esistente continuerà a funzionare senza cambi?” Usa la checklist qui sotto per classificare le modifiche prima di spedirle.
Di solito compatibili (additivi)
Queste modifiche generalmente non rompono i client esistenti perché non invalidano ciò che i client già inviano o si aspettano:
- Nuovi campi opzionali nelle risposte (es.
middleName o metadata). I client esistenti dovrebbero continuare a funzionare a patto che non richiedano un set esatto di campi.
- Nuovi endpoint (o nuovi metodi su path diversi). Non cambia nulla per chi è già in produzione.
- Nuovi campi opzionali nelle richieste che il server può ignorare o trattare con default.
- Espansione degli enum nelle risposte (i client dovrebbero gestire valori sconosciuti in modo difensivo).
Di solito breaking (rischiosi)
Considera questi breaking a meno che tu non abbia forti evidenze del contrario:
- Rimozione di campi o endpoint, o cessare il supporto per un campo di richiesta che i client inviano.
- Rinominare campi (anche se il significato resta) — molti client mappano per nome.
- Cambi di tipo (stringa → numero, oggetto → array,
nullable → non-nullable).
- Cambi di comportamento: default diversi, ordinamento differente, semantica di paginazione mutata, regole di validazione alterate.
- Stringere vincoli: rendere obbligatorio un campo prima opzionale, ridurre la lunghezza massima, cambiare i formati accettati.
“Lettori tolleranti” come baseline di compatibilità
Incoraggia i client a essere lettori tolleranti: ignorare campi sconosciuti e gestire enum inaspettati con grazia. Questo permette al backend di evolvere aggiungendo campi senza forzare aggiornamenti immediati ai client.
Come i generatori AI dovrebbero applicare le regole
Un generatore può prevenire cambi accidentali con politiche come:
- Bloccare i merge se le diff OpenAPI includono rimozioni, rinomi o cambi di tipo senza un bump di versione.
- Richiedere che ogni breaking change sia introdotto prima come nuovi campi/endpoint con avvisi di deprecazione su quelli vecchi.
- Emettere warning quando si aggiungono enum di risposta o si cambiano default, richiedendo una review di compatibilità.
Migrazioni di database senza rompere i client
Aggiorna i client insieme al backend
Genera app web, server e mobile insieme così client e backend evolvono in sincronia.
I cambi API sono ciò che i client vedono: forme di request/response, nomi dei campi, regole di validazione e comportamento degli errori. I cambi del database sono ciò che il backend memorizza: tabelle, colonne, indici, vincoli e formati dei dati. Sono correlati, ma non identici.
Un errore comune è trattare una migrazione DB come “solo interna”. Nei backend generati da AI, il layer API è spesso generato dallo schema (o strettamente accoppiato ad esso), quindi un cambiamento di schema può diventare silenziosamente un cambiamento API. Così i client più vecchi si rompono anche se non intendevi toccare l'API.
Un pattern di migrazione sicuro (expand → migrate → contract)
Usa un approccio in più fasi che mantiene sia i vecchi sia i nuovi percorsi funzionanti durante i rolling upgrade:
- Aggiungi: introduce nuove colonne/tabelle senza rimuovere o rinominare quelle esistenti.
- Backfill: popola i nuovi campi per le righe esistenti (in batch se necessario).
- Dual-write: il backend scrive sia nella locazione vecchia sia in quella nuova.
- Switch reads: inizia a leggere dalla nuova fonte mantenendo il dual-write.
- Pulizia: solo dopo che tutti i client sono aggiornati e il codice legacy è sparito, rimuovi i campi legacy.
Questo pattern evita rilasci “big bang” e ti dà opzioni di rollback.
Default, null e campi “mancanti”
I client vecchi spesso assumono che un campo sia opzionale o abbia un significato stabile. Quando aggiungi una nuova colonna non null, scegli tra:
- un default lato server che preservi il comportamento, o
- permettere NULL temporaneamente e gestirlo esplicitamente nel layer API.
Fai attenzione: un default DB non sempre aiuta se il serializer dell'API emette ancora null o cambia le regole di validazione.
Migrazioni generate da AI: utili, non automatiche
Gli strumenti AI possono redigere script di migrazione e suggerire backfill, ma serve sempre validazione umana: confermare vincoli, controllare performance (lock, costruzione indici) ed eseguire migrazioni su dati di staging per assicurarsi che i client più vecchi restino funzionanti.
Feature flag e rollout graduali per aggiornamenti più sicuri
I feature flag permettono di cambiare il comportamento senza alterare la forma dell'endpoint. Questo è particolarmente utile nei backend generati da AI, dove la logica interna può essere rigenerata o ottimizzata frequentemente, mentre i client dipendono da richieste e risposte coerenti.
Invece di un grande interruttore, spedisci il nuovo path di codice disabilitato di default e poi attivalo gradualmente. Se qualcosa va storto, lo spegni—senza l'urgenza di un redeploy.
Come funziona il rollout graduale
Un piano pratico di rollout combina tre tecniche:
- Canary release: abilita il nuovo comportamento per una piccola porzione di traffico (o per un tenant) prima.
- Rollout per percentuale: aumenta l'esposizione da 1% → 10% → 50% → 100%, monitorando errori e impatto sui client.
- Piano di rollback rapido: definisci in anticipo quali metriche innescano il rollback (es. tasso di 5xx, fallimenti di validazione, ticket di supporto) e rendi il flag reversibile entro pochi minuti.
Per le API, la chiave è mantenere le risposte stabili mentre sperimenti internamente. Puoi cambiare implementazione (nuovo modello, nuova logica di routing, nuovo piano di query DB) restituendo gli stessi codici di stato, nomi di campo e formati d'errore promessi dal contratto. Se devi aggiungere dati, preferisci campi additivi che i client possono ignorare.
Esempio semplice: rollout di una validazione più severa
Immagina POST /orders che accetta phone in molti formati. Vuoi far rispettare E.164, ma inasprire la validazione può rompere i client.
Un approccio più sicuro:
- Spedisci il validatore più severo dietro un flag (es.
strict_phone_validation).
- Inizia in modalità “report-only”: accetta la richiesta ma logga cosa sarebbe fallito. Le risposte restano invariate.
- Canary enable l'enforcement per utenti interni o 1% del traffico.
- Rampa mentre monitori: picchi di errori di validazione, retry dei client e drop-off.
- Rollback immediato se le soglie vengono superate.
Questo pattern ti permette di migliorare la qualità dei dati senza trasformare un'API retrocompatibile in una breaking change accidentale.
Deprecazione e sunsetting: come ritirare versioni vecchie
Mantieni gli errori coerenti
Definisci forme di errore e codici stabili, poi rigenera senza sorprendere le integrazioni.
La deprecazione è l'“uscita educata” per comportamenti API vecchi: smetti di promuoverli, avvisa i client in anticipo e dai un percorso prevedibile per aggiornarsi. Il sunsetting è il passo finale: una vecchia versione viene disabilitata a una data pubblicata. Per i backend generati da AI—dove endpoint e schemi possono evolvere rapidamente—avere un processo rigido di ritiro è ciò che mantiene gli aggiornamenti sicuri e la fiducia intatta.
Definisci cosa significa “major” (Semantic Versioning)
Usa il versionamento semantico a livello di contratto API, non solo nel repo.
- MAJOR: qualsiasi breaking change (rimozione di campi/endpoint, cambio di significato di un campo, validazione più stringente, cambio dei requisiti di auth, cambio di comportamento predefinito su cui i client fanno affidamento).
- MINOR: aggiunte retrocompatibili (nuovi campi opzionali, nuovi endpoint, valori enum additivi, nuovi parametri di filtro).
- PATCH: bugfix e miglioramenti non funzionali (performance, refactor interni) che non cambiano il contratto o il comportamento osservabile.
Metti questa definizione nella documentazione e applicala con coerenza. Evita “major silenziosi” dove una modifica assistita dall'AI sembra piccola ma rompe un client reale.
Timeline pratica di deprecazione
Scegli una politica di default e mantienila così gli utenti possono pianificare. Un approccio comune:
- Annuncia la deprecazione: immediatamente al rilascio della nuova versione.
- Finestra di deprecazione: tieni la versione vecchia attiva per 90–180 giorni (più a lungo per clienti enterprise).
- Data di sunset: pubblica una data definitiva sin dal primo giorno.
Se sei incerto, scegli una finestra leggermente più lunga; il costo di tenere una versione viva qualche tempo è spesso inferiore al costo di migrazioni d'emergenza dei client.
Segnali di deprecazione (rendili difficile da ignorare)
Usa canali multipli perché non tutti leggono le release notes.
- Header di risposta: es.
Deprecation: true e Sunset: Wed, 31 Jul 2026 00:00:00 GMT, più un Link alla documentazione di migrazione.
- Note nella doc: un banner chiaro nella doc della vecchia versione con data di sunset e checklist di migrazione.
- Warning negli SDK: avvisi negli SDK ufficiali (log a runtime + annotazioni di deprecazione a compile-time quando possibile).
Includi anche avvisi nei changelog e negli aggiornamenti di stato così procurement e ops li vedono.
Rimozione: sunset con data ferma (e uno stato finale sicuro)
Mantieni le vecchie versioni attive fino alla data di sunset, poi disabilitale deliberatamente—non gradualmente tramite rotture accidentali.
Al momento del sunset:
- Ritorna un errore chiaro per la versione ritirata (es.
410 Gone) con un messaggio che indica la versione più recente e la pagina di migrazione.
- Mantieni una spiegazione leggibile e stabile per un po' (es. /docs/deprecations/v1).
Soprattutto, tratta il sunsetting come una modifica pianificata con owner, monitoraggio e piano di rollback. Questa disciplina rende possibile un'evoluzione frequente senza sorprendere i client.
Test che prevengono cambi breaking accidentali
Il codice generato dall'AI può cambiare rapidamente—e a volte in modi sorprendenti. Il modo più sicuro per mantenere i client funzionanti è testare il contratto (ciò che prometti esternamente), non solo l'implementazione.
Test di contratto: confronti spec-to-spec
Una baseline pratica è un test di contratto che confronta la OpenAPI precedente con quella appena generata. Trattalo come un controllo “prima vs dopo”:
- Rileva endpoint rimossi, campi rinominati, regole di validazione più stringenti o cambi di requisiti di auth
- Segnala cambi di codici di risposta (es. 200 → 204, o comportamento 404 che cambia)
- Cattura shift sottili come un campo opzionale reso obbligatorio
Molti team automatizzano una diff OpenAPI in CI così nessuna modifica generata può essere deployata senza revisione. Questo è particolarmente utile quando prompt, template o versioni del modello cambiano.
Consumer-driven contract testing (in termini semplici)
I test guidati dal consumer capovolgono la prospettiva: invece di far indovinare al team backend come i client usano l'API, ogni client condivide un piccolo insieme di aspettative (le richieste che invia e le risposte su cui fa affidamento). Il backend deve provare di soddisfare ancora quelle aspettative prima del rilascio.
Funziona bene quando hai più consumatori (web, mobile, partner) e vuoi aggiornamenti senza coordinare ogni singolo deploy.
Test di regressione per forme di risposta ed errori
Aggiungi test di regressione che fissano:
- Forma JSON della risposta (nomi dei campi, tipi, nesting)
- Default e nullabilità (mancante vs null)
- Semantica di paginazione e ordinamento
- Formato degli errori: codici errore stabili, struttura del messaggio e campi di errore di validazione
Se pubblichi uno schema di errore, testalo esplicitamente—i client spesso parsano gli errori più di quanto vorremmo.
Gate CI prima del rollout
Combina controlli di diff OpenAPI, contratti consumer e test di forma/errore in un gate CI. Se una modifica generata fallisce, la correzione è solitamente adattare il prompt, le regole di generazione o inserire un layer di compatibilità—prima che gli utenti se ne accorgano.
Gestione degli errori e stabilità del comportamento tra versioni
Quando i client si integrano con la tua API, di solito non “leggono” i messaggi di errore—reagiscono alle forme e ai codici degli errori. Un refuso nel messaggio umano è fastidioso ma sopportabile; un codice di stato cambiato, un campo mancante o un identificatore di errore rinominato può trasformare una situazione recuperabile in una checkout fallita, una sincronizzazione saltata o un loop di retry infinito.
Errori stabili: priorizza la machine-readability
Punta a mantenere un involucro di errore coerente (la struttura JSON) e un set stabile di identificatori su cui i client possano fare affidamento. Per esempio, se ritorni { code, message, details, request_id }, non rimuovere o rinominare quei campi in una nuova versione. Puoi migliorare la parola in message liberamente, ma mantieni la semantica di code documentata e stabile.
Se hai già più formati in produzione, resisti alla tentazione di “ripulire” tutto in place. Invece, aggiungi un nuovo formato dietro un confine di versione o un meccanismo di negoziazione (es. header Accept), continuando a supportare quello vecchio.
Aggiungere nuovi codici di errore senza rompere i client
Nuovi codici di errore sono talvolta necessari (nuove regole di validazione, nuovi controlli di autorizzazione), ma vanno introdotti in modo da non sorprendere le integrazioni esistenti.
Un approccio sicuro:
- Mantieni validi i codici vecchi: se i client già gestiscono
VALIDATION_ERROR, non sostituirlo con INVALID_FIELD da un giorno all'altro.
- Introduci nuovi codici come varianti più specifiche: ritorna il nuovo
code, ma includi anche indizi retrocompatibili in details (o mantieni una mappatura al codice generalizzato per le versioni più vecchie).
- Documenta una regola di fallback: indica ai client di trattare codici sconosciuti come una classe generica basata sullo status HTTP (400/401/403/404/409/429/500) e continuare a mostrare
message.
Soprattutto, non cambiare il significato di un codice esistente. Se NOT_FOUND indicava “la risorsa non esiste”, non usarlo per “accesso negato” (quello è 403).
Stabilità del comportamento: i default non devono cambiare silenziosamente
La retrocompatibilità è anche “stessa richiesta, stesso risultato”. Cambi di default apparenti possono rompere client che non impostano esplicitamente parametri.
Paginazione: non cambiare limit, page_size o comportamento del cursore di default senza versionare. Passare da paginazione per pagina a cursore è breaking a meno di mantenere entrambi i percorsi.
Ordinamento: l'ordine predefinito deve restare stabile. Cambiare da created_at desc a relevance desc può riordinare liste e rompere assunzioni UI o sincronizzazioni incrementali.
Filtri: evita di alterare filtri impliciti (es. escludere improvvisamente elementi “inattivi” di default). Se ti serve un nuovo comportamento, aggiungi un flag esplicito come include_inactive=true o status=all.
Alcuni problemi di compatibilità non riguardano endpoint ma interpretazione.
- Fusi orari: specifica sempre se i timestamp sono UTC, includi offset e mantienilo consistente. Passare da locale a UTC senza avviso può causare eventi duplicati o mancanti.
- Formati numerici: i numeri JSON sono inequivocabili, ma stringhe che sembrano numeri (valute, decimali) possono variare. Non cambiare
"9.99" in 9.99 (o viceversa) in place.
- Booleani di default: default come
include_deleted=false o send_email=true non dovrebbero flipparsi. Se devi cambiare un default, richiedi che il client opt-in via un nuovo parametro.
Per i backend generati da AI in particolare, blocca questi comportamenti con contratti espliciti e test: il modello potrebbe “migliorare” risposte a meno che tu non imponga la stabilità come requisito primario.
Osservabilità: monitorare la compatibilità nel mondo reale
Applica modifiche intenzionali
Usa la Planning Mode per definire versioni, campi e deprecazioni prima di generare codice.
La retrocompatibilità non è qualcosa che verifichi una volta sola. Con i backend generati da AI il comportamento può cambiare più velocemente che nei sistemi fatti a mano, quindi hai bisogno di feedback che mostrino chi sta usando cosa e se un aggiornamento sta danneggiando i client.
Traccia metriche per versione API (e per endpoint)
Inizia taggando ogni richiesta con una versione API esplicita (path come /v1/..., header come X-Api-Version o il numero di schema negoziato). Poi raccogli metriche segmentate per versione:
- Uso: richieste al minuto per versione e route
- Latency: p50/p95 per versione (un cambiamento compatibile può comunque essere troppo lento)
- Tassi di errore: 4xx vs 5xx per versione (i picchi spesso rivelano rotture nascoste)
Questo ti permette di notare, per esempio, che /v1/orders è solo il 5% del traffico ma il 70% degli errori dopo un rollout.
Rileva i client che usano ancora campi o endpoint vecchi
Strumenta il gateway API o l'app per loggare cosa i client inviano e quali route chiamano:
- Request verso endpoint deprecati (es.
/v1/legacy-search)
- Payload contenenti campi deprecati
- Request che non includono nuovi campi opzionali che del codice generato potrebbe assumere presenti
Se controlli gli SDK, aggiungi un identificatore client leggero + header versione SDK per individuare integrazioni datate.
Usa log e tracing per individuare la modifica
Quando gli errori aumentano, devi rispondere: “Quale deploy ha cambiato il comportamento?” Correlare i picchi con:
- identificatori di release (commit hash/build id)
- log strutturati che includono versione, route e fallimenti di validazione
- trace distribuiti che mostrano dove sono apparse latenza o eccezioni (gateway → handler → DB)
Rollback adatto ai deploy generati
Mantieni i rollback semplici: sii sempre in grado di ridistribuire l'artifact generato precedente (container/image) e rimandare il traffico indietro via router. Evita rollback che richiedono inversioni di dati; se sono coinvolti cambi di schema, preferisci migrazioni DB additive così le versioni più vecchie continuano a funzionare mentre reverti il layer API.
Se la tua piattaforma supporta snapshot di ambiente e rollback veloci, usali. Per esempio, Koder.ai include snapshot e rollback nel suo workflow, che si accoppia bene con i cambi DB expand → migrate → contract e i rollout API graduali.
Un workflow ripetibile per far evolvere API generate dall'AI
I backend generati da AI possono cambiare rapidamente—nuovi endpoint appaiono, i modelli cambiano e le validazioni si stringono. Il modo più sicuro per mantenere i client stabili è trattare le modifiche API come un piccolo processo di rilascio ripetibile piuttosto che come “editing occasionale”.
Il workflow (proposta → ritiro)
- Proponi la modifica
Documenta il “perché”, il comportamento inteso e l'impatto esatto sul contratto (campi, tipi, required/optional, codici di errore).
- Classificala
Segnala come compatibile (sicura) o breaking (richiede modifiche ai client). Se incerto, assumi breaking e progetta un percorso di compatibilità.
- Progetta il piano di compatibilità
Decidi come supporterai i client vecchi: alias, dual-write/dual-read, valori di default, parsing tollerante o una nuova versione.
- Implementa dietro garanzie
Aggiungi la modifica con feature flag o configurazione così puoi rolloutare gradualmente e rollbackare rapidamente.
- Testa il contratto
Esegui controlli automatici sul contratto (es. regole di diff OpenAPI) oltre a test “golden” con richieste/risposte di client conosciuti per catturare drift del comportamento.
- Rilascia con documentazione
Ogni rilascio dovrebbe includere: doc di riferimento aggiornata in /docs, una breve nota di migrazione quando rilevante e una voce nel changelog che dichiari cosa è cambiato e se è compatibile.
- Depreca e rimuovi secondo il calendario
Annuncia deprecazioni con date, aggiungi header/avvisi, misura l'uso residuo e poi rimuovi dopo la finestra di sunset.
Mini esempio: rinominare un campo senza rompere i client
Se vuoi rinominare last_name in family_name:
- Request handling: accetta entrambi i campi; se sono entrambi forniti, preferisci
family_name.
- Response handling: ritorna entrambi per un periodo di transizione (o ritorna
family_name e conserva last_name come alias).
- Storage: mappa entrambi alla stessa colonna interna.
- Doc + changelog: documenta il nuovo nome, marca
last_name come deprecato e pubblica una data di rimozione.
Se la tua offerta include supporto per piani o supporto di versioni a lungo termine, specifica chiaramente quei dettagli su /pricing.