Perché i team sbattono il muso con le integrazioni tradizionali
La maggior parte dei prodotti parte con integrazioni punto-a-punto semplici: il Sistema A chiama il Sistema B, oppure uno script copia dati da un posto all'altro. Funziona finché il prodotto cresce, i team si separano e il numero di connessioni si moltiplica. Presto ogni cambiamento richiede coordinamento tra più servizi, perché un piccolo campo o aggiornamento di stato può propagarsi attraverso una catena di dipendenze.
La velocità è di solito la prima cosa che si rompe. Aggiungere una nuova funzionalità significa aggiornare più integrazioni, ridistribuire diversi servizi e sperare che nessun altro dipendesse dal vecchio comportamento.
Poi il debugging diventa doloroso. Quando qualcosa sembra sbagliato nell'interfaccia, è difficile rispondere a domande di base: cosa è successo, in che ordine e quale sistema ha scritto il valore che vedi?
La parte mancante è spesso una traccia di audit. Se i dati vengono spinti direttamente da un database a un altro (o trasformati lungo il tragitto), perdi la storia. Puoi vedere lo stato finale, ma non la sequenza di eventi che ha portato lì. Le revisioni degli incidenti e il supporto clienti ne soffrono perché non puoi riprodurre il passato per confermare cosa è cambiato e perché.
Qui nasce anche la discussione su "chi possiede la verità". Un team dice "il servizio fatturazione è la fonte di verità". Un altro dice "il servizio ordini lo è". In realtà ogni sistema ha una vista parziale, e le integrazioni punto-a-punto trasformano quel disaccordo in attrito quotidiano.
Un esempio semplice: un ordine viene creato, poi pagato, poi rimborsato. Se tre sistemi si aggiornano a vicenda direttamente, ognuno può finire con una storia diversa quando ci sono retry, timeout o correzioni manuali.
Questo porta alla domanda centrale del design dietro l'event streaming con Kafka: devi solo spostare lavoro da un posto a un altro (una coda), o hai bisogno di un registro condiviso e durevole di ciò che è successo che molti sistemi possano leggere, riavvolgere e cui possano affidarsi (un log)? La risposta cambia il modo in cui costruisci, debugghi ed evochi il sistema.
Jay Kreps, Kafka e l'idea del log
Jay Kreps ha contribuito a plasmare Kafka e, più importante, il modo in cui molti team pensano al movimento dei dati. Lo spostamento utile è mentale: smettere di trattare i messaggi come consegne una tantum e iniziare a considerare l'attività del sistema come un registro.
L'idea centrale è semplice. Modella i cambiamenti importanti come un flusso di fatti immutabili:
- Un ordine è stato creato.
- Un pagamento è stato autorizzato.
- Un utente ha cambiato la propria email.
Ogni evento è un fatto che non dovrebbe essere modificato a posteriori. Se qualcosa cambia dopo, aggiungi un nuovo evento che dichiari la nuova verità. Col tempo, quei fatti formano un log: una cronologia append-only del tuo sistema.
Qui l'event streaming con Kafka si differenzia da molte configurazioni di messaggistica di base. Molte code sono costruite attorno al modello "invia, elabora, elimina". Va bene quando il lavoro è solo un passaggio. La visione del log dice: "conserva la storia così molti consumer possono usarla, adesso e in futuro".
Il replay della storia è il superpotere pratico.
Se un report è sbagliato, puoi rieseguire la stessa storia di eventi attraverso un job di analytics corretto e vedere dove i numeri sono cambiati. Se un bug ha causato email errate, puoi riprodurre gli eventi in un ambiente di test e ricreare la timeline esatta. Se una nuova funzionalità ha bisogno di dati passati, puoi costruire un nuovo consumer che parte dall'inizio e si sincronizza al proprio ritmo.
Ecco un esempio concreto. Immagina di aggiungere controlli antifrode dopo aver già processato mesi di pagamenti. Con un log di eventi di pagamento e account, puoi riprodurre il passato per addestrare o calibrare regole su sequenze reali, calcolare punteggi di rischio per transazioni vecchie e backfillare eventi come fraud_review_requested senza riscrivere il database.
Nota cosa questo ti costringe a fare. Un approccio basato su log ti spinge a nominare gli eventi chiaramente, mantenerli stabili e accettare che più team e servizi dipenderanno da essi. Ti costringe anche a farti domande utili: qual è la fonte della verità? Cosa significa questo evento a lungo termine? Cosa facciamo quando abbiamo sbagliato?
Il valore non è la personalità. È rendersi conto che un registro condiviso può diventare la memoria del tuo sistema, e la memoria è ciò che permette ai sistemi di crescere senza rompersi ogni volta che aggiungi un nuovo consumer.
Coda vs log: il modello mentale più semplice
Una coda di messaggi è come una fila di cose da fare per il tuo software. I producer mettono lavoro nella fila, i consumer prendono il prossimo elemento, eseguono il lavoro e l'elemento sparisce. Il sistema riguarda principalmente che ogni task sia gestito una volta, il prima possibile.
Un log è diverso. È un record ordinato di fatti accaduti, conservato in sequenza durevole. I consumer non "prendono" gli eventi. Li leggono al proprio ritmo e possono rileggere più tardi. Nell'event streaming con Kafka, quel log è l'idea centrale.
Un modo pratico per ricordare la differenza:
- Coda = lavoro da fare. Una volta che un worker conferma, scompare.
- Log = storia di ciò che è successo. Gli eventi restano per un periodo di retention.
La retention cambia il design. Con una coda, se in seguito ti serve una nuova funzionalità che dipende da messaggi vecchi (analytics, antifrode, replay dopo un bug), spesso devi aggiungere un database separato o iniziare a catturare copie altrove. Con un log, il replay è normale: puoi ricostruire una vista derivata leggendo dall'inizio (o da un checkpoint noto).
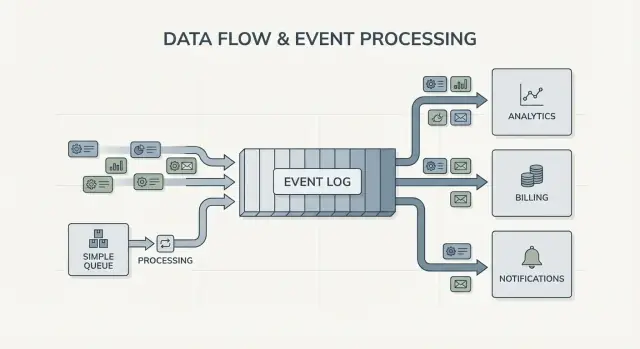
Il fan-out è un'altra grande differenza. Immagina che un servizio checkout emetta OrderPlaced. Con una coda, di solito scegli un gruppo di worker che lo processa, o duplicare il lavoro su code multiple. Con un log, billing, email, inventario, indicizzazione search e analytics possono leggere lo stesso stream in modo indipendente. Ogni team può muoversi al proprio ritmo e aggiungere un nuovo consumer più tardi non richiede di cambiare il produttore.
Quindi il modello mentale è semplice: usa una coda quando stai spostando task; usa un log quando stai registrando eventi che molte parti dell'azienda potrebbero voler leggere, ora o in futuro.
Cosa cambia l'event streaming nel design dei sistemi
L'event streaming inverte la domanda predefinita. Invece di chiedere "a chi devo mandare questo messaggio?", inizi registrando "cosa è appena successo?". Sembra piccolo, ma cambia come modelli il sistema.
Pubblicherai fatti come OrderPlaced o PaymentFailed, e altre parti del sistema decideranno se, quando e come reagire.
Con l'event streaming Kafka-style, i producer non hanno più bisogno di una lista di integrazioni dirette. Un servizio di checkout può pubblicare un evento e non deve sapere se analytics, email, controlli antifrode o un futuro servizio di raccomandazioni lo useranno. Possono apparire nuovi consumer dopo, i vecchi possono essere messi in pausa e il produttore si comporta allo stesso modo.
Questo cambia anche il modo di recuperare dagli errori. In un mondo solo a messaggi, una volta che un consumer perde qualcosa o ha un bug, i dati sono spesso "persi" a meno che non avessi costruito backup ad hoc. Con un log, puoi correggere il codice e riprodurre la storia per ricostruire lo stato corretto. Spesso è meglio rispetto a modifiche manuali al database o script one-off di cui nessuno si fida.
Nella pratica, lo shift si vede in alcuni modi affidabili: tratti gli eventi come record durevoli, aggiungi funzionalità sottoscrivendoti invece di modificare i producer, puoi ricostruire read model (indici di ricerca, dashboard) da zero e ottieni timeline più chiare di cosa è successo tra i servizi.
L'osservabilità migliora perché il log degli eventi diventa un riferimento condiviso. Quando qualcosa va storto, puoi seguire una sequenza di business: ordine creato, inventario riservato, pagamento ritentato, spedizione programmata. Quella timeline è spesso più facile da capire rispetto a log applicativi sparsi perché è focalizzata su fatti di business.
Un esempio concreto: se un bug nei prezzi ha sbagliato gli ordini per due ore, puoi spedire una correzione e riprodurre gli eventi interessati per ricalcolare i totali, aggiornare le fatture e rinfrescare gli analytics. Correggi i risultati ricalcolando, non indovinando quali tabelle patchare a mano.
Quando una semplice coda è sufficiente
Una coda semplice è lo strumento giusto quando stai spostando lavoro, non costruendo un registro a lungo termine. L'obiettivo è consegnare un task a un worker, eseguirlo e poi dimenticarlo. Se nessuno ha bisogno di riprodurre il passato, ispezionare eventi vecchi o aggiungere nuovi consumer più tardi, una coda mantiene le cose più semplici.
Le code brillano per i job in background: inviare email di registrazione, ridimensionare immagini dopo l'upload, generare un report notturno o chiamare un'API esterna lenta. In questi casi il messaggio è solo un biglietto di lavoro. Una volta che il worker finisce il job, il biglietto ha fatto il suo dovere.
Una coda si adatta anche al modello di ownership usuale: un gruppo di consumer è responsabile per il lavoro e altri servizi non dovrebbero leggere lo stesso messaggio in modo indipendente.
Una coda è solitamente sufficiente quando la maggior parte di queste condizioni è vera:
- I dati hanno valore a breve termine.
- Un solo team o servizio possiede il job end-to-end.
- Replay e retention lunga non sono requisiti.
- Il debugging non dipende dal rieseguire la storia.
Esempio: un prodotto carica foto utente. L'app scrive un task "resize image" in una coda. Il Worker A lo prende, crea le thumbnail, le memorizza e segna il task come completato. Se il task viene eseguito due volte, l'output è lo stesso (idempotente), quindi la consegna almeno-una-volta va bene. Nessun altro servizio deve leggere quel task in seguito.
Se i bisogni iniziano a spostarsi verso fatti condivisi (molti consumer), replay, audit o "cosa pensava il sistema la settimana scorsa?", è lì che l'event streaming con Kafka e l'approccio basato su log iniziano a ripagare.
Quando conviene un approccio basato su log
Un sistema basato su log conviene quando gli eventi smettono di essere messaggi una-tantum e diventano storia condivisa. Invece di "invia e dimentica", mantieni un record ordinato che molti team possano leggere, ora o più tardi, al proprio ritmo.
Il segnale più chiaro è la presenza di più consumer. Un evento come OrderPlaced può alimentare billing, email, antifrode, indicizzazione search e analytics. Con un log, ogni consumer legge lo stesso stream in modo indipendente. Non devi costruire una pipeline di fan-out custom o coordinare chi riceve il messaggio per primo.
Un altro vantaggio è poter rispondere a "cosa sapevamo allora?". Se un cliente contesta un addebito o una raccomandazione era sbagliata, una cronologia append-only rende possibile riprodurre i fatti così come sono arrivati. Quella traccia di audit è difficile da aggiungere a una coda semplice più tardi.
Ottieni anche un modo pratico per aggiungere nuove funzionalità senza riscrivere quelle vecchie. Se aggiungi una nuova pagina di "stato spedizione" mesi dopo, un nuovo servizio può sottoscriversi e backfillare dalla storia esistente per costruire il suo stato, invece di chiedere esportazioni a tutti i sistemi a monte.
Un approccio basato su log vale spesso la pena quando riconosci uno o più di questi bisogni:
- Gli stessi eventi devono alimentare diversi sistemi (analytics, search, billing, strumenti di supporto).
- Hai bisogno di replay, auditing o indagini basate su fatti passati.
- I nuovi servizi devono backfillare dalla storia senza job ad hoc.
- L'ordinamento è importante per entità (per ordine, per utente).
- I formati degli eventi evolveranno e ti serve un modo controllato per gestire il versioning.
Un pattern comune è un prodotto che inizia con ordini e email. Più tardi, finance vuole report sui ricavi, product vuole funnel e ops vuole dashboard live. Se ogni nuovo bisogno ti costringe a copiare dati attraverso una nuova pipeline, i costi aumentano rapidamente. Un log condiviso permette ai team di costruire sulla stessa fonte di verità, anche mentre il sistema cresce e gli eventi cambiano forma.
Come decidere, passo dopo passo
Scegliere tra una coda semplice e un approccio basato su log è più facile se lo tratti come una decisione di prodotto. Parti da cosa deve essere vero tra un anno, non solo da cosa funziona questa settimana.
Una pratica decisione in 5 passi
-
Mappa publisher e reader. Annota chi crea eventi e chi li legge oggi, poi aggiungi i probabili consumer futuri (analytics, indicizzazione, antifrode, notifiche). Se prevedi molti team che leggono gli stessi eventi in modo indipendente, un log comincia ad avere senso.
-
Chiediti se avrai bisogno di rileggere la storia. Sii specifico sul perché: replay dopo un bug, backfill o consumer che leggono a velocità diverse. Le code vanno bene per consegnare lavoro una volta. I log sono migliori quando vuoi un registro che puoi riprodurre.
-
Definisci cosa significa "fatto". Per alcuni workflow, fatto significa "il job è eseguito" (inviare una email, ridimensionare un'immagine). Per altri, fatto significa "l'evento è un fatto durevole" (un ordine è stato piazzato, un pagamento è stato autorizzato). I fatti durevoli ti spingono verso un log.
-
Scegli le aspettative di delivery e decidi come gestire i duplicati. La consegna almeno-una-volta è comune, il che significa che i duplicati possono succedere. Se un duplicato può fare danno (addebito doppio), pianifica idempotency: memorizza un ID evento processato, usa vincoli unici o rendi gli aggiornamenti sicuri da ripetere.
-
Parti con una fetta sottile. Scegli un topic/event stream facile da ragionare e cresci da lì. Se usi Kafka, mantieni il primo topic focalizzato, nomina gli eventi chiaramente ed evita di mescolare tipi di eventi non correlati.
Un esempio concreto: se OrderPlaced in seguito alimenterà spedizioni, fatturazione, supporto e analytics, un log permette a ogni team di leggere al proprio ritmo e di riprodurre dopo errori. Se hai solo bisogno di un worker in background per inviare una ricevuta, una coda semplice di solito basta.
Esempio: eventi d'ordine in un prodotto che cresce
Immagina un piccolo negozio online. All'inizio deve solo prendere ordini, addebitare una carta e creare una richiesta di spedizione. La versione più semplice è un job in background che gira dopo il checkout: "process order". Parla con le API di pagamento, aggiorna la riga dell'ordine nel DB e poi chiama la spedizione.
Quello stile a coda funziona bene quando c'è un workflow chiaro, serve un solo consumer (il worker) e retry e dead letter coprono i casi di fallimento.
Inizia a far male man mano che il negozio cresce. Il supporto vuole aggiornamenti automatici "dov'è il mio ordine?". Finance vuole numeri giornalieri di fatturato. Product vuole email ai clienti. L'antifrode dovrebbe controllare prima della spedizione. Con un singolo job "process order" finisci per modificare lo stesso worker continuamente, aggiungendo rami e rischiando nuovi bug nel flusso core.
Con un approccio basato su log, il checkout produce piccoli fatti come eventi e ogni team può costruirci sopra. Eventi tipici potrebbero essere:
OrderPlacedPaymentConfirmedItemShippedRefundIssued
Il cambiamento chiave è la proprietà. Il servizio checkout possiede OrderPlaced. Il servizio pagamenti possiede PaymentConfirmed. La spedizione possiede ItemShipped. Più tardi, nuovi consumer possono apparire senza cambiare il produttore: un servizio antifrode legge OrderPlaced e PaymentConfirmed per calcolare il rischio, un servizio email invia ricevute, analytics costruisce funnel e gli strumenti di supporto tengono una timeline di cosa è successo.
Qui l'event streaming con Kafka ripaga: il log conserva la storia, così i nuovi consumer possono riavvolgere e sincronizzarsi dall'inizio (o da un punto noto) invece di chiedere a tutti i team upstream di aggiungere un altro webhook.
Il log non sostituisce il database. Hai ancora bisogno di un DB per lo stato corrente: l'ultimo stato dell'ordine, il record cliente, i conteggi di inventario e le regole transazionali (tipo "non spedire se il pagamento non è confermato"). Pensa al log come al registro delle modifiche e al database come al posto dove interrogare "cos'è vero adesso".
Errori comuni e trappole
L'event streaming può rendere i sistemi più puliti, ma alcuni errori comuni possono annullare i benefici rapidamente. La maggior parte deriva dal trattare il log di eventi come un telecomando invece che come un registro.
Una trappola frequente è scrivere eventi come comandi, tipo "SendWelcomeEmail" o "ChargeCardNow". Questo rende i consumer fortemente accoppiati all'intento. Gli eventi funzionano meglio come fatti: "UserSignedUp" o "PaymentAuthorized". I fatti invecchiano meglio. Nuovi team possono riusarli senza indovinare cosa intendevi.
Duplicati e retry sono la prossima grande fonte di dolore. Nei sistemi reali i producer ritentano e i consumer rielaborano. Se non ti prepari, ottieni addebiti doppi, email duplicate e ticket di supporto arrabbiati. La soluzione non è esotica, ma deve essere deliberata: handler idempotenti, ID evento stabili e regole di business che rilevano "già applicato".
Trappole comuni:
- Usare eventi in stile comando che dicono ai servizi cosa fare invece di registrare cosa è successo.
- Costruire consumer che si rompono se vedono lo stesso evento due volte.
- Spezzare gli stream troppo presto, così un singolo flusso di business è sparso su troppi topic.
- Ignorare le regole di schema finché una piccola modifica rompe consumer più vecchi.
- Trattare lo streaming come sostituto di un buon design del database.
Schema e versioning richiedono attenzione speciale. Anche se inizi con JSON, ti serve un contratto chiaro: campi obbligatori, campi opzionali e come vengono rilasciate le modifiche. Una piccola modifica come rinominare un campo può rompere silenziosamente analytics, fatturazione o app mobile che aggiornano più lentamente.
Un'altra trappola è oversplitting. I team a volte creano un nuovo stream per ogni feature. Un mese dopo, nessuno sa rispondere "qual è lo stato corrente di un ordine?" perché la storia è dispersa in troppi posti.
L'event streaming non elimina la necessità di modelli dati solidi. Serve ancora un database che rappresenti la verità corrente. Il log è la storia, non l'intera applicazione.
Checklist rapida e prossimi passi
Se sei indeciso tra una coda e l'event streaming con Kafka, parti con alcuni controlli veloci. Ti diranno se ti serve solo un passaggio tra worker o un log riutilizzabile per anni.
Controlli rapidi
- Ti serve replay (per backfill, correzioni di bug o nuove feature) e quanto indietro?
- Più di un consumer avrà bisogno degli stessi eventi ora o presto (analytics, search, email, antifrode, billing)?
- Ti serve retention così i team possono rileggere la storia senza chiedere al produttore di rinviare?
- Quanto è importante l'ordinamento e a che livello: per entità (per ordine, per utente) o veramente globale?
- I consumer possono essere idempotenti (sicuri da ritentare senza doppio addebito, doppia email o doppio aggiornamento)?
Se hai risposto "no" a replay, "un solo consumer" e "messaggi a breve durata", una coda di base di solito basta. Se hai risposto "sì" a replay, consumer multipli o retention più lunga, un approccio basato su log tende a ripagare perché trasforma un flusso di fatti in una fonte condivisa su cui altri sistemi possono costruire.
Prossimi passi
Trasforma le risposte in un piano piccolo e testabile.
- Elenca 5-10 eventi principali in linguaggio semplice (esempio: OrderPlaced, PaymentAuthorized, OrderShipped) e annota chi pubblica e chi consuma ciascuno.
- Decidi la chiave d'ordinamento (spesso per entità, come
orderId) e documenta cosa significa "ordine corretto".
- Definisci una regola di idempotency per ogni consumer (per esempio: memorizzare l'ultimo ID evento processato per ordine).
- Scegli un target di retention che corrisponde ai tuoi bisogni (giorni per workflow simile a coda, settimane/mesi quando il replay è importante).
- Esegui una fetta end-to-end in una sandbox prima di impegnare l'intero sistema.
Se stai prototipando velocemente, puoi abbozzare il flusso degli eventi in Koder.ai planning mode e iterare sul design prima di fissare nomi e regole di retry. Poiché Koder.ai supporta l'export del codice sorgente, snapshot e rollback, è anche un modo pratico per testare un singolo slice producer-consumer e aggiustare la forma degli eventi senza trasformare esperimenti iniziali in debito tecnico di produzione.