03 ott 2025·8 min
Dati fuori vs dentro — Lezioni di Pat Helland per le app
Impara l'idea di Pat Helland sui dati esterno vs interno per tracciare confini chiari, progettare chiamate idempotenti e riconciliare lo stato quando la rete fallisce.
Impara l'idea di Pat Helland sui dati esterno vs interno per tracciare confini chiari, progettare chiamate idempotenti e riconciliare lo stato quando la rete fallisce.
Quando costruisci un'app, è facile immaginare richieste che arrivano in ordine, una dopo l'altra. Le reti reali non si comportano così. Un utente preme “Paga” due volte perché lo schermo si è bloccato. La connessione mobile cade subito dopo il tap. Un webhook arriva in ritardo, o arriva due volte. A volte non arriva proprio.
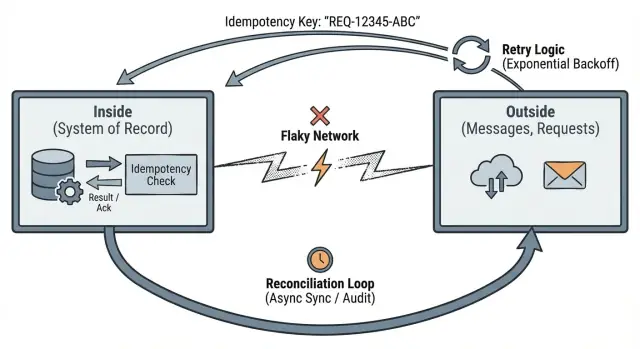
L'idea di Pat Helland di dati fuori vs dentro è un modo chiaro per pensare a questo caos.
“Fuori” è tutto ciò che il tuo sistema non controlla. È dove parli con altre persone e sistemi, e dove la consegna è incerta: richieste HTTP da browser e app mobile, messaggi da code, webhook di terze parti (pagamenti, email, spedizioni) e retry avviati da client, proxy o job di background.
Sul lato esterno, considera che i messaggi possono essere ritardati, duplicati o arrivare fuori ordine. Anche se qualcosa è “di solito affidabile”, progetta pensando al giorno in cui non lo è.
“Dentro” è ciò che il tuo sistema può rendere affidabile. È lo stato duraturo che memorizzi, le regole che applichi e i fatti che puoi dimostrare più tardi:
Dentro è dove proteggi gli invarianti. Se prometti “un pagamento per ordine”, quella promessa deve essere applicata dentro, perché il fuori non è attendibile.
Lo spostamento mentale è semplice: non dare per scontata la consegna perfetta o la tempistica perfetta. Tratta ogni interazione esterna come un suggerimento inaffidabile che potrebbe essere ripetuto, e fai in modo che l'interno reagisca in sicurezza.
Questo vale anche per team piccoli e app semplici. La prima volta che un problema di rete crea un addebito duplicato o un ordine bloccato, smette di essere teoria e diventa un rimborso, un ticket di supporto e una perdita di fiducia.
Un esempio concreto: un utente preme “Conferma ordine”, l'app invia una richiesta e la connessione cade. L'utente riprova. Se il tuo interno non sa riconoscere “è lo stesso tentativo”, potresti creare due ordini, riservare inventario due volte o inviare due conferme via email.
Il punto di Helland è semplice: il mondo esterno è incerto, ma l'interno del tuo sistema deve rimanere consistente. Le reti perdono pacchetti, i telefoni perdono segnale, gli orologi sfasano e gli utenti premono refresh. La tua app non può controllare tutto questo. Può però controllare cosa considera “vero” una volta che i dati passano un confine chiaro.
Immagina qualcuno che ordina un caffè dal telefono mentre cammina in un edificio con Wi‑Fi scarso. Preme “Paga”. La spinner gira. La rete cade. Preme di nuovo.
Forse la prima richiesta è arrivata al server, ma la risposta non è tornata. Oppure nessuna delle due richieste è arrivata. Dalla vista dell'utente, le possibilità sembrano identiche.
Questo è tempo e incertezza: non sai ancora cosa è successo, e potresti scoprirlo più tardi. Il tuo sistema deve comportarsi in modo sensato mentre aspetta.
Una volta accettato che il fuori è inaffidabile, alcuni comportamenti “strani” diventano normali:
I dati esterni sono una rivendicazione, non un fatto. “Ho pagato” è solo un'affermazione inviata su un canale inaffidabile. Diventa un fatto solo dopo che lo registri dentro il tuo sistema in modo durevole e coerente.
Questo ti spinge verso tre abitudini pratiche: definire confini chiari, rendere sicuri i retry con idempotenza e pianificare la riconciliazione quando la realtà non coincide.
L'idea “fuori vs dentro” parte da una domanda pratica: dove inizia e finisce la verità del tuo sistema?
Dentro il confine puoi fare garanzie forti perché controlli i dati e le regole. Fuori dal confine fai tentativi al meglio e assumi che i messaggi possano essere persi, duplicati, ritardati o arrivare fuori ordine.
Nelle app reali il confine appare spesso in posti come:
Una volta tracciata la linea, decidi quali invarianti sono non negoziabili all'interno. Esempi:
Il confine ha anche bisogno di linguaggio chiaro per “dove siamo”. Molti guasti vivono nel gap tra “ti abbiamo ricevuto” e “abbiamo finito”. Un pattern utile è separare tre significati:
Quando i team saltano questo, finiscono con bug che emergono solo sotto carico o durante outage parziali. Un sistema usa “pagato” per intendere denaro catturato; un altro lo usa per indicare che il tentativo di pagamento è iniziato. Quel disallineamento crea duplicati, ordini bloccati e ticket di supporto impossibili da riprodurre.
Idempotenza significa: se la stessa richiesta è inviata due volte, il sistema la tratta come una sola richiesta e restituisce lo stesso risultato.
I retry sono normali. I timeout accadono. I client si ripetono. Se il fuori può ripetere, il tuo dentro deve trasformare quello in cambiamenti di stato stabili.
Un esempio semplice: un'app mobile invia “paga 20€” e la connessione cade. L'app ritenta. Senza idempotenza, il cliente potrebbe essere addebitato due volte. Con idempotenza, la seconda richiesta restituisce il risultato del primo addebito.
La maggior parte dei team usa uno di questi pattern (a volte una combinazione):
Idempotency-Key: ...). Il server registra la chiave e la risposta finale.Quando arriva un duplicato, il comportamento migliore di solito non è “409 conflict” o un errore generico. È restituire lo stesso risultato che hai restituito la prima volta, compreso lo stesso ID di risorsa e stato. Questo rende i retry sicuri per client e job di background.
Il record di idempotenza deve vivere dentro il tuo confine in uno storage durevole, non in memoria. Se la tua API si riavvia e dimentica, la garanzia di sicurezza scompare.
Conserva i record abbastanza a lungo da coprire retry realistici e consegne ritardate. La finestra dipende dal rischio di business: minuti-ore per create a basso rischio, giorni per pagamenti/email/spedizioni dove i duplicati costano, e più a lungo se i partner possono ritentare per periodi estesi.
Le transazioni distribuite sembrano rassicuranti: un unico grande commit attraverso servizi, code e database. In pratica spesso non sono disponibili, sono lente o troppo fragili. Una volta che entra in gioco un hop di rete, non puoi assumere che tutto commetta insieme.
Una trappola comune è costruire un workflow che funziona solo se ogni passo riesce ora: salva ordine, addebita carta, riserva inventario, invia conferma. Se il passo 3 va in timeout, è fallito o è riuscito? Se ritenti, addebiterai due volte o riserverai due volte?
Due approcci pratici evitano questo:
Scegli uno stile per workflow e mantienilo. Mescolare “a volte facciamo outbox” con “a volte assumiamo successo sincrono” crea edge case difficili da testare.
Una regola semplice aiuta: se non puoi commettere in modo atomico oltre il confine, progetta per retry, duplicati e ritardi.
La riconciliazione ammette una verità fondamentale: quando la tua app parla con altri sistemi via rete, a volte non sarai d'accordo su cosa è successo. Le richieste timeout, i callback arrivano in ritardo e le persone ritentano azioni. La riconciliazione è come rilevi le discrepanze e le sistemi nel tempo.
Tratta i sistemi esterni come fonti di verità indipendenti. La tua app mantiene il proprio record interno, ma ha bisogno di un modo per confrontarlo con ciò che partner, provider e utenti hanno effettivamente fatto.
La maggior parte dei team usa un piccolo set di strumenti noiosi (e il noioso è buono): un worker che ritenta azioni pendenti e ricontrolla lo stato esterno, una scansione programmata per incongruenze e una piccola azione di riparazione per il supporto per ritentare, annullare o segnare come revisionato.
La riconciliazione funziona solo se sai cosa confrontare: ledger interno vs ledger del provider (pagamenti), stato ordine vs stato spedizione (fulfillment), stato abbonamento vs stato fatturazione.
Rendi gli stati riparabili. Invece di saltare direttamente da “created” a “completed”, usa stati intermedi come pending, on hold o needs review. Questo consente di dire in sicurezza “non siamo sicuri” e dà alla riconciliazione un posto chiaro dove atterrare.
Cattura una piccola traccia di audit sui cambi importanti:
Esempio: se la tua app richiede un'etichetta di spedizione e la rete cade, potresti ritrovarti con “nessuna etichetta” internamente mentre il corriere ne ha creata una. Un worker di recon può cercare per correlation ID, scoprire che l'etichetta esiste e avanzare l'ordine (o segnalarlo per revisione se i dettagli non combaciano).
Una volta che assumi che la rete fallirà, l'obiettivo cambia. Non tenti di far funzionare ogni passo in un solo tentativo. Cerchi di rendere ogni passo sicuro da ripetere e facile da riparare.
Scrivi una frase che descriva il confine. Sii esplicito su cosa possiede il tuo sistema (la source of truth), cosa rispecchia e cosa richiede solo ad altri.
Elenca i modi in cui può fallire prima del flusso felice. Al minimo: timeout (non sai se ha funzionato), richieste duplicate, successo parziale (un passo è riuscito, il successivo no) ed eventi fuori ordine.
Scegli una strategia di idempotenza per ogni input. Per API sincrone spesso è una idempotency key più risultato memorizzato. Per messaggi/eventi è un ID messaggio unico e un record "ho già processato questo?".
Persisti l'intento, poi agisci. Prima salva qualcosa di durevole come “PaymentAttempt: pending” o “ShipmentRequest: queued”, poi fai la chiamata esterna, poi registra l'esito. Restituisci un ID di riferimento stabile così i retry puntano allo stesso intento invece di crearne uno nuovo.
Costruisci riconciliazione e una via di riparazione, e rendile visibili. La riconciliazione può essere un job che scansiona record “pendenti troppo a lungo” e ricontrolla lo stato. La via di riparazione può essere un'azione admin sicura come “retry”, “cancel” o “mark resolved”, con una nota di audit. Aggiungi osservabilità di base: correlation ID, campi di stato chiari e qualche conteggio (pending, retries, failures).
Esempio: se il checkout va in timeout subito dopo aver chiamato un provider di pagamento, non indovinare. Memorizza il tentativo, restituisci l'ID del tentativo e lascia che l'utente ritenti con la stessa idempotency key. Più tardi la riconciliazione può confermare se il provider ha addebitato o no e aggiornare il tentativo senza duplicare l'addebito.
Un cliente preme “Conferma ordine”. Il tuo servizio invia una richiesta di pagamento a un provider, ma la rete è instabile. Il provider ha la sua verità e il tuo database ha la sua. Deriveranno se non progetti per questo.
Dal tuo punto di vista, il fuori è uno stream di messaggi che possono essere in ritardo, ripetuti o mancanti:
Nessuno di questi passaggi garantisce “esattamente una volta”. Garantisc ono solo “forse”.
Dentro il tuo confine, memorizza fatti duraturi e il minimo necessario per collegare eventi esterni a quei fatti.
Quando il cliente crea l'ordine, crea un record order in uno stato chiaro come pending_payment. Crea anche un record payment_attempt con un riferimento provider unico e una idempotency_key legata all'azione del cliente.
Se il client fa timeout e ritenta, la tua API non dovrebbe creare un secondo ordine. Dovrebbe cercare la idempotency_key e restituire lo stesso order_id e lo stato corrente. Questa scelta impedisce duplicati quando la rete fallisce.
Ora il webhook arriva due volte. Il primo callback aggiorna payment_attempt in authorized e muove l'ordine a paid. Il secondo callback entra nello stesso handler, ma tu rilevi che hai già processato quell'evento provider (memorizzando l'ID evento del provider, o controllando lo stato attuale) e non fai nulla. Puoi comunque rispondere 200 OK, perché il risultato è già vero.
Infine, la riconciliazione gestisce i casi sporchi. Se l'ordine è ancora pending_payment dopo un po', un job di background interroga il provider usando il riferimento memorizzato. Se il provider dice “authorized” ma ti sei perso il webhook, aggiorni i record. Se il provider dice “failed” ma tu l'hai marcato paid, lo segnali per revisione o avvii una compensazione come un rimborso.
La maggior parte dei record duplicati e dei workflow “bloccati” nasce dal confondere ciò che è successo fuori (una richiesta è arrivata, un messaggio è stato ricevuto) con ciò che hai impegnato in modo sicuro dentro il tuo sistema.
Un fallimento classico: un client invia “crea ordine”, il server inizia il lavoro, la rete cade e il client ritenta. Se tratti ogni retry come nuova verità, ottieni addebiti doppi, ordini duplicati o email multiple.
Le cause usuali sono:
Un problema che peggiora tutto: nessuna traccia di audit. Se sovrascrivi campi e tieni solo l'ultimo stato, perdi le prove necessarie per riconciliare dopo.
Un buon controllo di sanità è: “Se eseguo questo handler due volte, ottengo lo stesso risultato?” Se la risposta è no, i duplicati non sono un edge case raro. Sono garantiti.
Se ti ricordi una cosa: la tua app deve rimanere corretta anche quando i messaggi arrivano in ritardo, arrivano due volte o non arrivano affatto.
Usa questa checklist per individuare punti deboli prima che diventino record duplicati, aggiornamenti mancanti o workflow bloccati:
Se non sai rispondere rapidamente a uno di questi punti, è utile: di solito significa che un confine è sfocato o che manca una transizione di stato.
Passi pratici successivi:
Disegna prima i confini e gli stati. Definisci un piccolo set di stati per ogni workflow (per esempio: Created, PaymentPending, Paid, FulfillmentPending, Completed, Failed).
Aggiungi idempotenza dove conta di più. Parti dalle scritture a rischio più alto: create order, cattura pagamento, emetti rimborso. Memorizza le idempotency key in PostgreSQL con un vincolo UNIQUE così i duplicati sono rifiutati in sicurezza.
Tratta la riconciliazione come una funzionalità normale. Pianifica un job che cerca record “pendenti troppo a lungo”, controlla i sistemi esterni e ripara lo stato locale.
Itera in sicurezza. Aggiusta transizioni e regole di retry, poi testa rimandando intenzionalmente la stessa richiesta e rielaborando lo stesso evento.
Se stai costruendo rapidamente su una piattaforma guidata dalla chat come Koder.ai (koder.ai), vale comunque la pena incorporare queste regole nei servizi generati fin dall'inizio: la velocità arriva dall'automazione, ma l'affidabilità arriva da confini chiari, handler idempotenti e riconciliazione.
“Esterno” è tutto ciò che il tuo sistema non controlla: browser, reti mobile, code, webhook di terze parti, retry e timeout.
“Interno” è ciò che tu controlli: lo stato memorizzato, le regole e i fatti che puoi dimostrare in seguito (di solito nel database).
Perché la rete non è sincera.
Un client che timeout non significa che il server non abbia processato la richiesta. Un webhook che arriva due volte non implica che il provider abbia eseguito l'azione due volte. Se tratti ogni messaggio come “nuova verità”, otterrai ordini duplicati, addebiti doppi e workflow bloccati.
Il confine chiaro è il punto in cui un messaggio inaffidabile diventa un fatto duraturo.
Esempi comuni:
Una volta che i dati attraversano il confine, applichi invarianti all'interno (per esempio: “un ordine può essere pagato una sola volta”).
Usa l'idempotenza. La regola: lo stesso intento deve produrre lo stesso risultato anche se inviato più volte.
Pattern pratici:
Non tenerla solo in memoria. Memorizzala dentro il tuo confine (per esempio PostgreSQL) così i riavvii non eliminano la protezione.
Regola pratica per la conservazione:
Conservala abbastanza a lungo da coprire retry realistici e callback ritardati.
Usa stati che ammettono incertezza.
Un set semplice e pratico:
pending_* (abbiamo accettato l'intento ma non conosciamo ancora l'esito)succeeded / failed (abbiamo registrato un esito finale)needs_review (abbiamo rilevato una discrepanza che richiede intervento umano)Perché non puoi commettere in modo atomico attraverso più sistemi in rete.
Se fai “salva ordine → addebita carta → riserva inventario” in modo sincrono e il passo 2 va in timeout, non sai se ripetere. Ritentare può creare duplicati; non ritentare può lasciare lavoro incompleto.
Progetta per il successo parziale: persisti prima l'intento, poi esegui le azioni esterne, poi registra gli esiti.
Il pattern outbox/inbox rende l'invio di messaggi cross-system affidabile senza fingere che la rete sia perfetta.
La riconciliazione è come recuperi quando i tuoi record e un sistema esterno non sono d'accordo.
Default consigliati:
needs_reviewNon è opzionale per pagamenti, fulfillment, abbonamenti o qualsiasi cosa con webhook.
Sì. Costruire velocemente non elimina i guasti di rete: semplicemente li scopri prima.
Se generi servizi con Koder.ai, incorpora questi default fin da subito:
Così i retry e i callback duplicati diventano banali invece che costosi.
Questo evita congetture durante i timeout e facilita la riconciliazione.