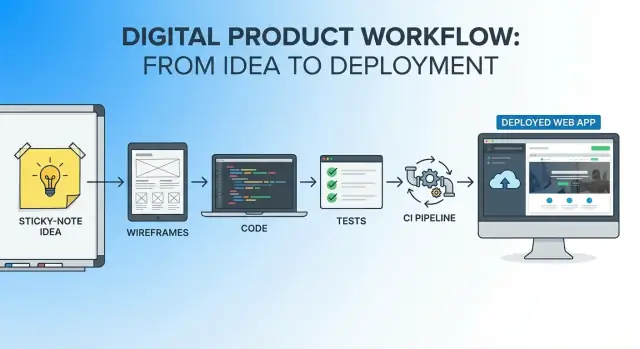
L'obiettivo: un percorso continuo dall'idea all'app live
Immagina una piccola idea utile: un “Queue Buddy” che permette al personale di un caffè di toccare un pulsante per aggiungere un cliente alla lista d'attesa e inviargli automaticamente un SMS quando il tavolo è pronto. La metrica di successo è semplice e misurabile: ridurre del 50% le chiamate confuse sul tempo di attesa medio in due settimane, mantenendo l'onboarding del personale sotto i 10 minuti.
Questo è lo spirito dell'articolo: scegli un'idea chiara e delimitata, definisci cosa significa “bene”, e poi procedi dal concetto a una distribuzione live senza cambiare continuamente strumenti, documenti e modelli mentali.
Cosa significa “flusso unico”
Un flusso unico è un filo continuo dalla prima frase dell'idea al primo rilascio in produzione:
- Un posto dove sono registrate le decisioni (cosa stiamo costruendo e perché)
- Un insieme di artefatti che evolve (requisiti → schermate → task → codice → test → note di deploy)
- Un loop di feedback (ogni cambiamento può essere ricondotto all'obiettivo e alla metrica)
Userai ancora più strumenti (editor, repo, CI, hosting), ma non “riallancerai” il progetto a ogni fase. La stessa narrazione e gli stessi vincoli si portano avanti.
Il ruolo dell'AI: assistente, non pilota automatico
L'AI è più utile quando:\n
- redige opzioni rapidamente (formulazione dei requisiti, user flow, shape delle API)\n- genera codice iniziale e test che puoi rivedere in piccoli pezzi\n- segnala i casi limite che potresti perdere (validazione, permessi, logging)\n
Ma non prende le decisioni di prodotto. Le prendi tu. Il flusso è pensato in modo che tu verifichi sempre: Questo cambiamento muove la metrica? È sicuro da rilasciare?
Il percorso end-to-end che seguiremo
Nelle sezioni successive seguirai passo passo:
- Chiarire il problema, gli utenti e una “piccola vittoria” da consegnare.
- Trasformare l'idea in un documento leggero di requisiti.
- Abbozzare il percorso utente e le schermate chiave.
- Scegliere un'architettura sensata per la v1.
- Bootstrapare lo scheletro del repo funzionante.
- Costruire le funzionalità core in fette sottili e verificabili.
- Aggiungere le basi per la sicurezza: validazione, permessi, logging.
- Aggiungere test che proteggono il percorso felice e le parti rischiose.
- Impostare build, CI e quality gate.
- Distribuire con un processo chiaro e reversibile.
- Monitorare, imparare e iterare—senza spezzare il filo.
Alla fine dovresti avere un modo ripetibile per passare da “idea” ad “app live” mantenendo strettamente connessi scope, qualità e apprendimento.
Parti dalla chiarezza: problema, utenti e una piccola vittoria
Prima di chiedere all'AI di disegnare schermate, API o tabelle del database, ti serve un obiettivo netto. Un po' di chiarezza qui ti salva ore di output “quasi giusti” più avanti.
Una frase che descrive il problema
Stai costruendo un'app perché un gruppo specifico di persone incontra ripetutamente la stessa frizione: non riescono a completare un'attività importante in modo rapido, affidabile o con fiducia usando gli strumenti che hanno. L'obiettivo della versione 1 è rimuovere un passaggio doloroso di quel workflow—senza cercare di automatizzare tutto—così gli utenti possono passare da “devo fare X” a “X è fatto” in pochi minuti, con un registro chiaro di ciò che è successo.
Utenti target e le loro top 3 job-to-be-done
Scegli un utente primario. Gli utenti secondari possono aspettare.
- Utente primario: operatori/proprietari occupati che gestiscono il processo end-to-end (non specialisti).
- Top job-to-be-done:
- Catturare la richiesta (o l'input) rapidamente, senza perdere dettagli chiave.
- Tracciare lo stato a colpo d'occhio e sapere cosa fare dopo.
- Condividere un risultato (conferma, riepilogo o esportazione) che altri possano fidarsi.
Assunzioni (ciò che deve essere vero)
Le assunzioni sono dove le buone idee falliscono silenziosamente—rendile visibili.
- Gli utenti accetteranno un piccolo setup per avere un workflow ripetibile.
- I dati necessari esistono (o possono essere inseriti) con precisione ragionevole.
- Una traccia di controllo leggera è sufficiente; funzionalità di compliance complete non servono per la v1.
- L'“aiuto AI” migliora la velocità, ma gli utenti vogliono comunque il controllo finale.
Definizione di fatto per il primo rilascio
La versione 1 dovrebbe essere una piccola vittoria che puoi spedire.
- Un utente può completare il flusso core in meno di 3 minuti.
- I dati sono validati e salvati, con permessi di base e un log di attività.
- Esiste un output condivisibile (email, PDF o link) e risulta coerente.
- Puoi distribuire, rollbackare e rispondere: “Sta funzionando?”
Un documento di requisiti leggero (pensa: una pagina) è il ponte tra “idea interessante” e “piano costruibile.” Ti mantiene concentrato, dà all'assistente AI il contesto giusto e impedisce alla prima versione di gonfiarsi in un progetto di mesi.
Bozza di un PRD di una pagina (le parti che contano)
Tieni tutto stringato e scansionabile. Un template semplice:
- Problema: quale dolore risolvi, in una frase?
- Utenti target: chi incontra questo problema più spesso?
- Scope (Versione 1): cosa costruirai ora.
- Non-goal: cosa esplicitamente non costruirai ancora (qui muore lo scope creep).
- Vincoli: budget, timeline, vincoli tecnologici, compliance, dispositivi, sorgenti dati.
- Metrica di successo: come si capisce che “ha funzionato” (anche una proxy semplice va bene).
Definisci e classifica 5–10 feature core
Scrivi 5–10 feature al massimo, formulate come risultati. Poi ordinalele:
- Must-have (l'app fallisce senza di esso)
- Should-have (alto valore, ma può aspettare)
- Nice-to-have (mettilo in stand-by)
Questa classificazione guida anche i piani e il codice generati dall'AI: “Implementa solo i must-have prima.”
Aggiungi criteri di accettazione per le feature top
Per le prime 3–5 feature, aggiungi 2–4 criteri di accettazione ciascuna. Usa linguaggio semplice e affermazioni testabili.
Esempio:
- Feature: Creare un account
- L'utente può registrarsi con email e password
- La password deve essere almeno di 12 caratteri
- Dopo la registrazione, l'utente atterra sulla dashboard
- Email duplicate mostrano un errore chiaro
Cattura le domande aperte per una rapida validazione
Termina con una breve lista “Domande Aperte”—cose che puoi rispondere con una chat, una chiamata a un cliente o una ricerca veloce.
Esempi: “Gli utenti hanno bisogno del login Google?” “Qual è il dato minimo che dobbiamo memorizzare?” “Serve approvazione admin?”
Questo documento non è burocrazia; è una fonte di verità condivisa che aggiornerai mentre il build procede.
Schizza il percorso utente e le schermate chiave
Prima di chiedere all'AI di generare schermate o codice, metti a fuoco la storia del prodotto. Un rapido schizzo del percorso mantiene tutti allineati: cosa l'utente vuole fare, cosa significa successo e dove si può sbagliare.
Mappa i flussi principali (happy path + casi limite chiave)
Inizia con l'happy path: la sequenza più semplice che consegna il valore principale.
Esempio di flusso (generico):
- L'utente si registra / effettua il login
- L'utente crea un nuovo Progetto
- L'utente aggiunge Task
- L'utente marca un Task come completato
- L'utente vede progresso / conferma
Poi aggiungi alcuni casi limite probabili e costosi se gestiti male:
- L'utente abbandona la registrazione a metà (cosa succede ai dati parziali?)
- L'utente perde l'accesso (sessione scaduta, permesso revocato)
- Stato vuoto (ancora nessun progetto)
- Salvataggio fallito (errore di rete) e comportamento di retry
Non serve un grande diagramma. Una lista numerata con note è sufficiente per guidare prototipazione e generazione di codice.
Elenca schermate/pagine chiave e cosa devono ottenere
Scrivi un breve “job to be done” per ogni schermata. Mantienilo focalizzato sul risultato più che sull'interfaccia.
- Login / Signup: far entrare l'utente; spiegare chiaramente gli errori; abilitare il reset della password
- Dashboard: mostrare elementi correnti e la prossima azione; gestire lo stato vuoto con cura
- Dettaglio Progetto: mostrare info progetto; permettere aggiunta/modifica task; visualizzare lo stato
- Editor Task (modal/pagina): creare o aggiornare un task; validare i campi richiesti
- Impostazioni / Account: gestire profilo; fare logout; gestire la cancellazione account se serve
Se lavori con l'AI, questa lista diventa materiale eccellente da usare nel prompt: “Genera una Dashboard che supporta X, Y, Z e include stati vuoto/caricamento/errore.”
Definisci entità dati ad alto livello
Tieni questo a livello “schema da tovagliolo”—sufficiente per supportare schermate e flussi.
- User: id, email, name, role
- Project: id, ownerId, title, createdAt
- Task: id, projectId, title, status, dueDate
Nota le relazioni (User → Projects → Tasks) e tutto ciò che influisce sui permessi.
Identifica dove fiducia e sicurezza sono importanti
Segna i punti dove gli errori rompono la fiducia:
- Autenticazione e gestione delle sessioni
- Permessi (chi può vedere/modificare un progetto?)
- Azioni distruttive (elimina progetto/task) e conferme
- Auditabilità (logging base per modifiche ed eliminazioni)
Non si tratta di sovra-ingegnerizzare—si tratta di prevenire sorprese che trasformano una “demo funzionante” in un problema di supporto dopo il lancio.
Scegli un'architettura sensata per la v1
L'architettura della versione 1 deve fare una cosa bene: permetterti di spedire il prodotto utile più piccolo senza intrappolarti. Una buona regola è “un repo, un backend distribuibile, un frontend distribuibile, un database”—e aggiungi pezzi solo quando un requisito chiaro lo impone.
Scegli lo stack più semplice che funzioni
Se costruisci una web app tipica, un default sensato è:
- Frontend: React (o Next.js se vuoi routing + rendering server di base)
- Backend: Node.js + un framework minimal (Express/Fastify) o API routes di Next.js se l'API è piccola
- Database: Postgres (affidabile, flessibile e supportato ovunque)
Mantieni basso il numero di servizi. Per la v1, un “monolite modulare” (codebase ben organizzata ma un solo servizio backend) è di solito più semplice dei microservizi.
Se preferisci un ambiente AI-first dove architettura, task e codice generato restano strettamente connessi, piattaforme come Koder.ai possono essere adatte: descrivi lo scope v1 in chat, iteri in “planning mode” e poi generi un frontend React con backend Go + PostgreSQL—tenendo comunque il controllo e la revisione nelle tue mani.
Definisci la tua API come un contratto
Prima di generare codice, scrivi una piccola tabella API così tu e l'AI avrete lo stesso obiettivo. Esempio di forma:
GET /api/projects → { items: Project[] }POST /api/projects → { project: Project }GET /api/projects/:id → { project: Project, tasks: Task[] }POST /api/projects/:id/tasks → { task: Task }
Aggiungi note su codici di stato, formato degli errori (es. { error: { code, message } }) e qualsiasi paginazione.
Decidi sull'autenticazione (o evitala)
Se la v1 può essere pubblica o single-user, salta l'autenticazione e manda in produzione più velocemente. Se servono account, usa un provider gestito (magic link email o OAuth) e mantieni permessi semplici: “l'utente possiede i propri record.” Evita ruoli complessi finché l'uso reale non li richiede.
Imposta obiettivi di performance e affidabilità per il lancio
Documenta alcuni vincoli pratici:
- Traffico previsto (anche un numero approssimativo)
- Obiettivo di tempo di risposta (es. “la maggior parte delle richieste sotto i 300ms”)
- Logging minimo (richieste, errori e eventi business chiave)
- Backup e piano di rollback
Queste note guidano la generazione di codice assistita dall'AI verso qualcosa di distribuibile, non solo funzionale.
Bootstrap del repo: da cartella vuota a scheletro funzionante
Trasforma l'apprendimento in crediti
Ottieni crediti creando contenuti su Koder.ai o condividendo il tuo referral.
Il modo più veloce per uccidere lo slancio è discutere strumenti per una settimana e non avere codice eseguibile. Il tuo obiettivo qui è semplice: arrivare a una “hello app” che parte localmente, abbia una schermata visibile e possa accettare una richiesta—restando però abbastanza piccolo da rendere ogni cambiamento facile da rivedere.
Chiedi all'AI uno scheletro pratico (non un prodotto finito)
Dai all'AI un prompt stringato: scelta del framework, pagine di base, un'API stub e i file attesi. Cerchi convenzioni prevedibili, non soluzioni brillanti.
Un buon primo passo è una struttura come:
/README.md
/.env.example
/apps/web/
/apps/api/
/package.json
Se usi un repo monorepo, chiedi rotte base (es. / e /settings) e un endpoint API (es. GET /health o GET /api/status). È sufficiente per provare che l'impianto funziona.
Se usi Koder.ai, questo è anche il posto naturale per iniziare: chiedi uno scheletro minimale “web + api + pronto per database”, poi esporta il sorgente quando sei soddisfatto della struttura e delle convenzioni.
Genera una UI minima collegata a un backend stub
Mantieni la UI intenzionalmente noiosa: una pagina, un pulsante, una chiamata.
Comportamento di esempio:
- La homepage rende “App is running.”
- Un pulsante chiama l'endpoint backend.
- La risposta viene mostrata nella pagina.
Questo ti dà un loop di feedback immediato: se la UI carica ma la chiamata fallisce, sai esattamente dove guardare (CORS, porta, routing, errori di rete). Resisti ad aggiungere auth, database o stato complesso qui—farai tutto dopo che lo scheletro è stabile.
Aggiungi variabili d'ambiente e istruzioni per lo sviluppo locale
Crea un .env.example dal giorno uno. Previene i problemi “funziona sulla mia macchina” e rende l'onboarding indolore.
Esempio:
WEB_PORT=3000
API_PORT=4000
API_URL=http://localhost:4000
Poi rendi il README eseguibile in meno di un minuto:
- installa dipendenze
- copia
.env.example in .env
- avvia web + api
- apri l'URL nel browser
Mantieni le modifiche piccole e committa presto
Tratta questa fase come la posa di fondazioni pulite. Committa dopo ogni piccola vittoria: “init repo,” “add web shell,” “add api health endpoint,” “wire web to api.” Piccoli commit rendono l'iterazione assistita dall'AI più sicura: se una modifica generata va male, puoi revertare senza perdere una giornata di lavoro.
Costruisci le funzionalità core in fette sottili verificabili
Una volta che lo scheletro gira end-to-end, resisti alla tentazione di “finire tutto subito.” Costruisci invece una slice verticale che tocchi database, API e UI (se applicabile), poi ripeti. Le slice sottili mantengono le revisioni veloci, i bug piccoli e l'assistenza AI più facile da verificare.
Parti dal modello dati principale (e migrazioni)
Scegli il modello senza il quale l'app non può funzionare—spesso la “cosa” che gli utenti creano o gestiscono. Definiscilo chiaramente (campi, obbligatori vs opzionali, valori di default), poi aggiungi migrazioni se usi un database relazionale. Mantieni la prima versione semplice: evita normalizzazioni ingegnose e flessibilità prematura.
Se usi l'AI per scrivere il modello, chiedile di giustificare ogni campo e default. Se non è in grado di spiegare qualcosa in una frase, probabilmente non serve nella v1.
Costruisci gli endpoint primari con regole di validazione
Crea solo gli endpoint necessari per il primo percorso utente: tipicamente create, read e un update minimale. Metti la validazione vicino al confine (request DTO/schema) e rendi esplicite le regole:
- Campi richiesti, formati e range consentiti
- Controlli di proprietà/permessi (“questo utente può accedere a questo record?”)
- Forme di risposta coerenti (successo e fallimento)
La validazione è parte della feature, non rifinitura—previene dati sporchi che ti rallentano dopo.
Gestione degli errori che aiuta le persone
Tratta i messaggi d'errore come UX per debug e supporto. Restituisci messaggi chiari e azionabili (cosa è fallito e come sistemarlo) mantenendo fuori dalla risposta client dettagli sensibili. Logga il contesto tecnico server-side con un request ID così puoi tracciare gli incidenti senza indovinare.
Usa suggerimenti AI—poi rivedi ogni cambiamento
Chiedi all'AI di proporre cambiamenti incrementali di dimensione PR: una migrazione + un endpoint + un test alla volta. Rivedi le diff come faresti con un collega: controlla nomi, casi limite, ipotesi di sicurezza e se la modifica supporta davvero la “piccola vittoria” dell'utente. Se aggiunge feature extra, accorcia e vai avanti.
Rendilo sufficientemente sicuro: validazione, permessi e logging
Rilascia con un piano di rollback
Usa snapshot e rollback così le release restano reversibili e a basso stress.
La versione 1 non necessita di sicurezza enterprise, ma deve evitare i fallimenti prevedibili che trasformano un'app promettente in un incubo di supporto. L'obiettivo qui è “sufficientemente sicuro”: prevenire input dannosi, restringere l'accesso di default e lasciare tracce utili quando qualcosa va storto.
Tratta ogni confine come non attendibile: campi dei form, payload API, query params e anche webhook interni. Valida tipo, lunghezza e valori consentiti, e normalizza i dati (trim di stringhe, conversione di casing) prima di salvare.
Alcuni default pratici:
- Validazione server-side (sempre), anche se validi anche in UI.
- Rate limit per login, password reset e endpoint costosi.
- Controlli upload file: limiti di dimensione, MIME consentiti e scansione antivirus se accetti upload pubblici.
- Messaggi d'errore sicuri: spiega cosa correggere, ma non esporre stack trace o identificatori interni.
Se usi l'AI per generare handler, chiedile di includere regole di validazione esplicite (es. “max 140 chars” o “deve essere uno di: …”) invece di dire genericamente “valida input.”
Permessi: comincia in piccolo, deny by default
Un modello di permessi semplice è spesso sufficiente per la V1:
- Anonymous: può accedere solo a pagine pubbliche.
- Signed-in user: può creare e vedere i propri dati.
- Owner/editor (opzionale): può modificare record condivisi.
Rendi i controlli di proprietà centrali e riutilizzabili (middleware/funzioni policy), così non spargi if userId == … nel codice.
Logging che aiuta a debug rapidi
Buoni log rispondono: cosa è successo, a chi, e dove? Includi:
- Request ID (propagalo tra i servizi)
- User ID (quando autenticato)
- Azione + risorsa (es.
update_project, project_id)
- Tempi (durata per richieste lente)
Logga eventi, non segreti: mai scrivere password, token o dettagli completi di pagamento.
Una checklist rapida degli errori comuni
Prima di dichiarare l'app “sufficientemente sicura”, controlla:
- Auth richiesta su tutte le route non pubbliche
- Controlli di autorizzazione (non solo autenticazione)
- Rate limit su auth e endpoint con scritture intensive
- Validazione server per tutti gli input
- Segreti in env/secret manager (non nel repo)
- Logging coerente e non sensibile con request ID
Aggiungi test che proteggano l'happy path e i rischi
Il testing non è inseguire un punteggio perfetto—serve a prevenire i tipi di guasti che feriscono gli utenti, rompono la fiducia o generano incidenti costosi. In un workflow assistito dall'AI, i test fungono anche da “contratto” che mantiene il codice generato allineato con quello che intendevi.
Parti dalla logica ad alto rischio
Prima di aggiungere tanta copertura, identifica dove gli errori sarebbero costosi. Aree tipiche ad alto rischio includono soldi/crediti, permessi, trasformazioni dati e validazione di edge-case. Scrivi test unitari per questi pezzi per primi. Mantienili piccoli e specifici: dato l'input X, aspetti l'output Y (o un errore). Se una funzione ha troppe diramazioni da testare agevolmente, è un segnale che va semplificata.
Aggiungi uno o due test di integrazione per il flusso principale
I unit test prendono errori di logica; i test di integrazione prendono i bug di wiring—rotte, chiamate al DB, controlli auth e il flusso UI che funziona insieme.
Scegli il journey core (l'happy path) e automatizzalo end-to-end:
- Crea un account / effettua login
- Completa l'azione principale per cui l'app è nata
- Conferma che il risultato appare dove l'utente si aspetta (schermata, email, dashboard)
Un paio di solidi test di integrazione spesso prevengono più incidenti di decine di test piccoli.
Usa l'AI per bozzare i test—poi rendili significativi
L'AI è brava a generare scaffolding per test ed elencare casi limite che potresti perdere. Chiedile:
- casi limite (valori vuoti, lunghezze massime, fusi orari)
- casi negativi (accesso non autorizzato, stati invalidi)
- esempi di dati realistici (non solo “foo/bar”)
Poi rivedi ogni asserzione generata. I test devono verificare comportamento, non dettagli di implementazione. Se un test passerebbe comunque dopo un bug, non sta facendo il suo lavoro.
Stabilisci un piccolo obiettivo di coverage e punta alla affidabilità
Scegli un target modesto (es. 60–70% sui moduli core) e usalo come guida, non come trofeo. Concentrati su test stabili e veloci che girano in CI e falliscono per i motivi giusti. I test flaky erodono la fiducia—e una volta che le persone smettono di fidarsi della suite, smette di proteggerti.
Preparati per l'automazione: build, CI e quality gate
L'automazione è dove un workflow assistito dall'AI smette di essere “un progetto che funziona sulla mia macchina” e diventa qualcosa che puoi rilasciare con fiducia. L'obiettivo non è lo strumento più sofisticato—è la ripetibilità.
Parti da un comando di build ripetibile
Scegli un comando unico che produca lo stesso risultato localmente e in CI. Se usi Node, potrebbe essere npm run build; per Python, make build; per mobile, uno step Gradle/Xcode specifico.
Separa anche presto la configurazione di sviluppo da quella di produzione. Una regola semplice: le impostazioni di dev sono comode; quelle di produzione sono sicure.
{
"scripts": {
"lint": "eslint .",
"format": "prettier -w .",
"test": "vitest run",
"build": "vite build"
}
}
Un linter cattura pattern rischiosi (variabili inutilizzate, async non sicuri). Un formatter evita “dibattiti di stile” che inquinano le diff nelle review. Mantieni le regole modeste per la v1, ma applicale in modo coerente.
Un ordine pratico di gate:
- format → 2) lint → 3) tests → 4) build
Imposta una CI di base: esegui i test ad ogni push
Il tuo primo workflow CI può essere piccolo: installa le dipendenze, esegui i gate e fallisci velocemente. Questo da solo impedisce che codice rotto finisca silenziosamente nel main.
name: ci
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npm run format -- --check
- run: npm run lint
- run: npm test
- run: npm run build
Definisci la gestione dei segreti (e rendila difficile da sbagliare)
Decidi dove vivono i segreti: store segreti del CI, un password manager, o le impostazioni ambiente della piattaforma di deployment. Non committarli mai su git—aggiungi .env a .gitignore e includi .env.example con placeholder sicuri.
Se vuoi un passo successivo pulito, collega questi gate al processo di deployment nella sezione successiva, così “CI verde” è l'unica strada verso la produzione.
Distribuisci in produzione con un processo chiaro e reversibile
Vai live sul tuo dominio
Aggiungi un dominio personalizzato così la tua v1 sembra reale appena pubblicata.
Il deploy non è un click singolo—è una routine ripetibile. L'obiettivo per la v1 è semplice: scegli un target di deployment che combaci con il tuo stack, distribuisci in piccoli incrementi e assicurati sempre di avere una via di ritorno.
Scegli il target di deployment giusto (non sovradimensionare)
Scegli una piattaforma che si adatti a come gira la tua app:
- Static site + API serverless: Vercel / Netlify
- Web app docker-based: Render / Fly.io
- Bisogni VM tradizionali: un piccolo VPS (solo se veramente necessario)
Ottimizzare per “facile da ridistribuire” spesso batte ottimizzare per “massimo controllo” in questa fase.
Se vuoi minimizzare il cambio di strumenti, considera piattaforme che uniscono build + hosting + rollback. Per esempio, Koder.ai supporta deployment e hosting insieme a snapshot e rollback, così puoi trattare i rilasci come passi reversibili anziché porte senza ritorno.
Usa una checklist di deploy ogni volta
Scrivila una volta e riutilizzala per ogni release. Rendila breve così la gente la segue davvero:
- Conferma che variabili d'ambiente e segreti sono impostati
- Esegui le migrazioni database (o conferma che non ce ne sono)
- Build e avvia l'app in configurazione production
- Esegui uno smoke test del flusso utente principale
- Verifica che i log scorrono e che gli errori siano visibili
Se la salvi nel repo (per esempio in /docs/deploy.md), resta naturalmente vicina al codice.
Aggiungi
Aggiungi health check e endpoint di status
Crea un endpoint leggero che risponda: “L'app è up e riesce a raggiungere le dipendenze?” Pattern comuni:
GET /health per load balancer e uptime monitorGET /status che ritorna versione app + check di dipendenze
Mantieni le risposte veloci, senza cache e sicure (niente segreti o dettagli interni).
Pianifica il rollback prima di averne bisogno
Un piano di rollback dovrebbe essere esplicito:
- Come ridistribuire la versione precedente (tag, release o immagine)
- Cosa fare sulle migrazioni (prima compatibili all'indietro; reversibili solo se necessario)
- Chi decide il rollback e quali segnali lo innescano (tasso di errore, health check falliti)
Quando il deployment è reversibile, rilasciare diventa di routine—e puoi spedire più spesso con meno stress.
Chiudi il cerchio: monitora, impara e iterare nello stesso flusso
Lanciare è l'inizio della fase più utile: imparare cosa fanno gli utenti reali, dove l'app si rompe e quali piccoli cambiamenti muovono la metrica di successo. L'obiettivo è mantenere lo stesso workflow assistito dall'AI che hai usato per costruire—ora puntato sulle evidenze anziché sulle assunzioni.
Imposta un monitoraggio base (uptime, errori, performance)
Inizia con uno stack minimo che risponda a tre domande: È up? Sta fallendo? È lento?
Gli uptime check possono essere semplici (una hit periodica all'endpoint health). Il tracking errori deve catturare stack trace e contesto della richiesta (senza raccogliere dati sensibili). Il monitoraggio performance può partire da tempi di risposta per endpoint chiave e metriche di caricamento lato front-end.
Fai aiutare l'AI a generare:
- un formato di logging e correlation ID così un'azione utente è tracciabile end-to-end
- soglie di alert (inizialmente conservative) e una checklist “on-call” per cosa fare subito
Aggiungi analytics prodotto collegati alla metrica di successo
Non tracciare tutto—traccia ciò che dimostra che l'app funziona. Definisci una metrica di successo primaria (es. “checkout completato,” “primo progetto creato,” “invitato un collega”). Poi strumenta un piccolo funnel: ingresso → azione chiave → successo.
Chiedi all'AI di proporre nomi di eventi e proprietà, poi rivedili per privacy e chiarezza. Mantieni gli eventi stabili; cambiarli ogni settimana rende le tendenze inutili.
Crea un intake semplice: un pulsante di feedback in-app, un alias email breve e un template bug leggero. Triaggialo settimanalmente: raggruppa feedback per temi, collega i temi alle analytics e decidi le prossime 1–2 migliorie.
Mantieni il flusso continuo dopo il lancio
Tratta alert di monitoraggio, cali nelle analytics e temi ricorrenti del feedback come nuovi “requisiti.” Alimentali nello stesso processo: aggiorna il doc, genera una piccola proposta di modifica, implementala in slice sottili, aggiungi un test mirato e distribuisci con lo stesso processo reversibile. Per i team, una pagina “Learning Log” condivisa (linkata dalla /blog o dai documenti interni) mantiene decisioni visibili e ripetibili.