Cosa dovrebbe risolvere questa web app
La maggior parte dei team non fallisce nell’esperimentazione per mancanza di idee: fallisce perché i risultati sono sparsi. Un prodotto ha grafici in uno strumento di analytics, un altro ha un foglio di calcolo, un terzo ha una slide con screenshot. Pochi mesi dopo, nessuno riesce a rispondere a domande semplici come “Abbiamo già testato questo?” o “Quale versione ha vinto, usando quale definizione di metrica?”.
Il problema centrale: risultati frammentati e verità incoerente
Una web app per il tracciamento degli esperimenti dovrebbe centralizzare cosa è stato testato, perché, come è stato misurato e cosa è successo—attraverso più prodotti e team. Senza questo, i team perdono tempo a ricostruire report, discutere sui numeri e rieseguire vecchi test perché gli apprendimenti non sono ricercabili.
A chi è rivolta (e cosa serve a ciascun gruppo)
Non è solo uno strumento per analisti.
- Product manager hanno bisogno di una vista veloce su esiti, confidenza e stato della decisione.
- Analisti necessitano di un posto affidabile per documentare assunzioni, definizioni metriche e caveat.
- Ingegneri richiedono chiarezza su quali feature flag, varianti e condizioni di rollout erano in scope.
- Leadership vuole una vista coerente dell’impatto across product, senza deck ad hoc.
Risultati da ottimizzare
Un buon tracker genera valore di business abilitando:
- Decisioni più rapide (meno tempo a inseguire link e approvazioni)
- Meno errori di report (una sola fonte di verità per “i numeri finali”)\n- Apprendimenti condivisi (storico ricercabile di successi, fallimenti e test neutri)
Confini dello scope
Sii esplicito: questa app è principalmente per tracciare e riportare i risultati degli esperimenti—non per eseguire esperimenti end-to-end. Può collegarsi a strumenti esistenti (feature flagging, analytics, data warehouse) pur avendo il record strutturato dell’esperimento e la sua interpretazione finale concordata.
Requisiti: il tracker di esperimenti minimo vitale
Un tracker minimo deve rispondere a due domande senza cercare tra documenti o fogli di calcolo: cosa stiamo testando e cosa abbiamo imparato. Parti con un set piccolo di entità e campi che funzionino across product, poi espandi solo quando i team avvertono un vero bisogno.
Entità core da supportare
Mantieni il modello dati abbastanza semplice perché ogni team lo usi nello stesso modo:
- Product: l’area dove la modifica viene rilasciata (app/sito/API).
- Experiment: un’ipotesi e una decisione.
- Variant: controllo e una o più treatment.
- Metric: una misura nominata con un owner e una definizione.
- Segment: slice di audience opzionali (nuovi utenti, utenti paganti, regione) usati per i report.
Tipi di esperimenti (parti piccoli, resta flessibile)
Supporta i pattern più comuni fin dal primo giorno:
- A/B test (control vs treatment)
- Test multivariati (più varianti)
- Rollout con feature flag (esposizione percentuale)
Anche se i rollout non usano statistiche formali all’inizio, tracciarli insieme agli esperimenti aiuta a evitare di ripetere gli stessi “test” senza registro.
Campi minimi che ogni esperimento richiede
Alla creazione, richiedi solo ciò che serve per eseguire e interpretare il test in seguito:
- Hypothesis (cosa cambia, per chi e perché)
- Owner (persona responsabile)
- Date inizio/fine (pianificate e reali)
- Targeting (regole di eleggibilità) e allocation (split del traffico)
- Link a rollout/flag, ticket o spec (URL relativi come /projects/123)
Criteri di successo e stato della decisione
Rendi i risultati confrontabili imponendo struttura:
- Primary metric (la misura principale di successo)
- Guardrails (metriche che non devono peggiorare)
- Decision status: proposed → running → analyzed → shipped/rolled back → archived
Se costruisci solo questo, i team possono trovare esperimenti, capire setup e registrare esiti—anche prima di aggiungere analytics avanzati o automazioni.
Modello dati che funziona across prodotti
Un tracker di esperimenti cross-product nasce o cade sul modello dati. Se gli ID collidono, le metriche si spostano o i segmenti sono incoerenti, la dashboard può sembrare “giusta” mentre racconta la storia sbagliata.
Scegli identificatori stabili (e mantienili)
Inizia con una strategia chiara di identificatori:
- product_id: stabile anche in caso di rename (non usare display name come chiavi)
- experiment_key: slug leggibile (es.
checkout_free_shipping_banner) più un experiment_id immutabile
- variant_key: etichette stabili come
control, treatment_a
Questo permette di confrontare risultati tra prodotti senza indovinare se “Web Checkout” e “Checkout Web” siano la stessa cosa.
Collezioni/tabelle core
Tieni le entità core piccole ed esplicite:
- experiments: product_id, hypothesis, primary_metric_def_id, start/end, status
- variants: experiment_id, variant_key, traffic_split
- assignments: experiment_id, user_id (o anonymous_id), variant_key, assigned_at
- metric_defs: nome metrica, logica numeratore/denominatore, unità (user/session/order), owner
- results: experiment_id, metric_def_id, time_window_id, segment_id, computed_at, effect, uncertainty
Anche se il calcolo avviene altrove, memorizzare gli output (results) abilita dashboard veloci e una storia affidabile.
Finestre temporali e versioning
Metriche e esperimenti non sono statici. Modella:
- time windows (es. “primi 7 giorni dopo l’assegnazione”, “settimane di calendario”)
- definizioni metriche versionate: quando cambia il calcolo di una metrica, crea una nuova versione invece di editare la vecchia
Questo evita che esperimenti passati cambino quando qualcuno aggiorna la logica del KPI.
Segmenti e audit trail
Prevedi segmenti coerenti across prodotti: paese, device, tier del piano, nuovi vs returning.
Infine, aggiungi un audit trail che catturi chi ha cambiato cosa e quando (cambi di stato, split del traffico, aggiornamenti di definizioni metriche). È essenziale per fiducia, review e governance.
Definizioni metriche e calcoli coerenti
Se il tracker sbaglia i calcoli delle metriche (o li rende incoerenti across prodotti), il “risultato” è solo un’opinione con un grafico. Il modo più veloce per evitare questo è trattare le metriche come asset condivisi del prodotto—non snippet di query ad-hoc.
Costruisci un catalogo metrico canonico
Crea un catalogo metriche che sia la fonte unica di verità per definizioni, logica di calcolo e ownership. Ogni voce deve includere:
- una definizione in linguaggio semplice (che decisione supporta)
- un owner (persona/team responsabile dei cambi)
- la formula esatta e gli eventi/campi richiesti
- regole di inclusione/esclusione (es. utenti interni, bot, ordini rimborsati)
- livelli di aggregazione validi e prodotti supportati
Tieni il catalogo vicino a dove le persone lavorano (es. link dalla creazione dell’esperimento) e versionalo così puoi spiegare risultati storici.
Standardizza i livelli di aggregazione
Decidi in anticipo quale sia l’“unità di analisi” di ciascuna metrica: per user, per sessione, per account o per ordine. Un tasso di conversione “per user” può discordare con “per session” pur essendo entrambi corretti.
Per ridurre confusione, memorizza la scelta di aggregazione con la definizione della metrica e richiedila al setup dell’esperimento. Non lasciare che ogni team scelga l’unità ad hoc.
Gestisci conversioni ritardate e attribuzione
Molti prodotti hanno finestre di conversione (es. iscrizione oggi, acquisto entro 14 giorni). Definisci regole di attribuzione coerenti:
- Quando parte il conteggio (tempo di esposizione, prima visita, tempo di assegnazione)?
- Cosa conta come conversione se un utente è esposto più volte?
- Come gestisci percorsi cross-device o cross-product?
Rendi queste regole visibili nella dashboard così i lettori sanno cosa stanno guardando.
Memorizza conteggi grezzi e statistiche calcolate
Per dashboard rapide e auditabilità, conserva entrambi:
- conteggi grezzi (esposizioni, converter, somme di revenue, input per la varianza)
- statistiche calcolate (lift, intervalli di confidenza, p-value)
Questo permette rendering veloce pur lasciando la possibilità di ricalcolare quando le definizioni cambiano.
Convenzioni di naming per evitare proliferazione di metriche
Adotta uno standard di naming che codifichi il significato (es. activation_rate_user_7d, revenue_per_account_30d). Richiedi ID unici, applica alias ed evidenzia quasi-duplicati durante la creazione per mantenere il catalogo pulito.
Raccolta dati: eventi, pipeline e controlli di qualità
Il tracker è credibile quanto i dati che riceve. L’obiettivo è rispondere in modo affidabile a due domande per ogni prodotto: chi è stato esposto a quale variante e cosa ha fatto dopo? Tutto il resto—metriche, statistiche, dashboard—dipende da questa base.
Scegli un approccio di ingest
La maggior parte dei team sceglie uno di questi pattern:
- Event stream (near real-time): ottimo per letture veloci e debugging rapido. Richiede più maturità ingegneristica per rimanere stabile.
- Batch giornaliero: più semplice da gestire e meno costoso. Ideale quando le decisioni non devono essere orarie.
- Ibrido: stream per esposizioni e eventi critici (validare rapidamente gli assignment), batch per il resto per completezza e controllo costi.
Qualunque scelta, standardizza il set minimo di eventi across prodotti: exposure/assignment, eventi di conversione chiave, e abbastanza contesto per unirli (user ID/device ID, timestamp, experiment ID, variant).
Mappa eventi prodotto a metriche (e valida la completezza)
Definisci una mappatura chiara da eventi grezzi a metriche che il tracker riporta (es. purchase_completed → Revenue, signup_completed → Activation). Mantieni questa mappatura per prodotto, ma usa nomi coerenti across prodotti così la dashboard confronta “like with like”.
Valida la completezza presto:
- conferma che ogni exposure abbia experiment ID e variant
- assicurati che gli eventi di conversione includano gli stessi campi identità usati per le join di exposure
- controlla eventuali perdite di eventi tra client, server e warehouse (SDK mobile sono spesso colpevoli)
Controlli di qualità dati da automatizzare
Crea check che girano ad ogni caricamento e falliscono in modo rumoroso:
- Exposure mancanti: conversioni senza exposure precedente (spesso gap di instrumentation o mismatch di identità)
- Allocazioni sbilanciate: varianti con 70/30 quando aspettavi 50/50 (può indicare bug di targeting)
- Sanity timestamp: esposizioni dopo conversioni, o grandi ritardi che suggeriscono problemi con gli orologi
Mostra questi warning nell’app attaccati all’esperimento, non nascosti nei log.
Backfill e reprocessing
Le pipeline cambiano. Quando risolvi un bug di instrumentation o logica di dedup, dovrai reprocessare dati storici per mantenere coerenza di metriche e KPI.
Pianifica per:
- trasformazioni versionate (così sai quale logica ha prodotto quale risultato)
- backfill sicuri (limita l’ambito per data/prodotto/esperimento)
- audit trail di ricalcolo
Documenta le integrazioni
Tratta le integrazioni come feature di prodotto: documenta SDK supportati, schemi eventi e procedure di troubleshooting. Se hai un’area docs, rimandala come testo semplice come /docs/integrations.
Statistiche e calcolo dei risultati affidabili
Mantieni piena proprietà del codice
Esporta il codice sorgente in qualsiasi momento e continua a sviluppare nel tuo repository.
Se le persone non si fidano dei numeri, non useranno il tracker. L’obiettivo non è impressionare con la matematica—è rendere le decisioni ripetibili e difendibili across prodotti.
Scegli un “dialetto” statistico e mantienilo
Decidi in anticipo se l’app riporterà risultati frequentisti (p-value, intervalli di confidenza) o bayesiani (probabilità di miglioramento, intervalli credibili). Entrambi funzionano, ma mescolarli across prodotti crea confusione (“Perché questo test mostra 97% di probabilità di vincere, mentre quell’altro mostra p=0.08?”).
Una regola pratica: scegli l’approccio che l’organizzazione già capisce, poi standardizza terminologia, default e soglie.
Definisci esattamente cosa mostra l’UI
Al minimo, la vista risultati dovrebbe rendere inequivocabili:
- Lift (assoluto e/o relativo) rispetto al controllo
- Intervallo (confidence interval o credible interval) mostrato come range, non solo una stima puntuale
- Forza dell’evidenza (p-value per frequentista, o probabilità di battere il controllo per bayesiano)
Mostra anche la finestra di analisi, le unità conteggiate (users, sessions, orders) e la versione della definizione metrica usata. Questi dettagli fanno la differenza tra report coerenti e discussioni.
Comparazioni multiple e policy di “peeking”
Se i team testano molte varianti, molte metriche o controllano i risultati giornalmente, i falsi positivi diventano probabili. L’app dovrebbe codificare una policy invece di lasciarla a ogni team:
- Comparazioni multiple: decidi se aggiustare (es. controllare false discovery rate) o etichettare chiaramente i risultati come “unadjusted exploratory”.
- Peeking ripetuto: o (1) scoraggialo con una data di fine fissa e stato “finalized”, o (2) supporta metodi sequenziali e mostra indicazioni “safe-to-stop”.
Guardrail che intercettano failure comuni
Aggiungi flag automatizzati che appaiono accanto ai risultati, non nascosti nei log:
- Sample Ratio Mismatch (SRM): avvisa quando lo split del traffico devia dall’allocazione attesa.
- Rilevazione anomalie: segnala crolli/aumenti improvvisi nel traffico, conversioni o revenue che possono indicare rotture nel tracciamento, outage o traffico bot.
Spiegazioni in linguaggio semplice
Accanto ai numeri, aggiungi una breve spiegazione comprensibile anche a non tecnici, ad esempio: “La stima migliore è +2.1% di lift, ma l’effetto reale potrebbe essere tra -0.4% e +4.6%. Non abbiamo evidenza sufficiente per dichiarare un vincitore.”
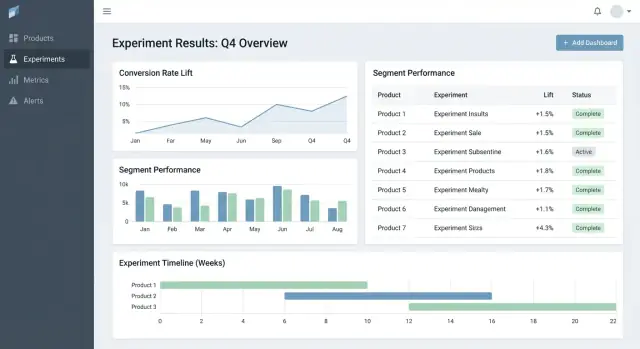
UX e dashboard per decisioni rapide
Un buon tooling per esperimenti aiuta a rispondere a due domande velocemente: Cosa dovrei guardare dopo? e Cosa dovremmo fare? L’UI dovrebbe minimizzare la ricerca di contesto e rendere esplicito lo “stato decisionale”.
Pagine chiave per ancorare il workflow
Inizia con tre pagine che coprono la maggior parte degli usi:
- Experiments list: una coda ordinabile per tutta l’organizzazione (o per prodotto).
- Experiment detail: la singola fonte di verità per setup, risultati e decisione.
- Product overview: un rollup di test attivi, decisioni recenti e stato delle metriche per un prodotto.
Su list e product pages, rendi i filtri veloci e persistenti: product, owner, range di date, status, primary metric e segment. Le persone dovrebbero poter restringere a “esperimenti di Checkout, owned da Maya, in esecuzione questo mese, primary metric = conversion, segmento = new users” in pochi secondi.
Stati di decisione affidabili
Tratta lo status come un vocabolario controllato, non testo libero:
Draft → Running → Stopped → Shipped / Rolled back
Mostra lo stato ovunque (righe della lista, header del dettaglio e link di condivisione) e registra chi l’ha cambiato e perché. Questo evita “launch silenziosi” e outcome poco chiari.
Una tabella di risultati che rende la decisione ovvia
Nella vista dettaglio, guida con una tabella compatta dei risultati per metrica:
- Baseline
- Variant
- Lift
- Incertezza (intervallo)
- Note (es. caveat di instrumentation, particolarità del segmento)
Tieni i grafici avanzati nella sezione “More details” così i decisori non vengono sovraccaricati.
Condivisione ed export senza perdere il controllo
Aggiungi export CSV per gli analisti e link condivisibili per gli stakeholder, ma applica permessi: i link devono rispettare ruoli e permessi per prodotto. Un semplice bottone “Copy link” più “Export CSV” copre la maggior parte delle esigenze di collaborazione.
Permessi, privacy e governance
Configura un catalogo metriche
Crea definizioni metriche versionate così i risultati restano comparabili nel tempo.
Se il tracker copre più prodotti, controllo accessi e audit non sono opzionali. Sono ciò che rende lo strumento sicuro da adottare e credibile nelle review.
Controllo accessi basato sui ruoli (RBAC)
Inizia con un set semplice di ruoli e mantienili coerenti nell’app:
- Viewer: sola lettura su esperimenti, risultati e dashboard.
- Editor: crea/modifica esperimenti, carica documentazione, imposta stato (draft → running → concluded).
- Admin: gestisce utenti, permessi, definizioni metriche, regole di retention e integrazioni.
Centralizza le decisioni RBAC (un unico layer di policy) così UI e API fanno rispettare le stesse regole.
Permessi a livello prodotto e riga
Molte org hanno bisogno di accesso limitato per prodotto: il Team A vede i dati del Product A ma non del Product B. Modellalo esplicitamente (es. membership user ↔ product) e filtra ogni query per product.
Per casi sensibili (partner, segmenti regolamentati), aggiungi restrizioni row-level oltre al product scoping. Un approccio pratico è taggare esperimenti o slice dei risultati con un livello di sensibilità e richiedere un permesso aggiuntivo per visualizzarli.
Audit trail: accessi + cronologia delle modifiche
Registra due cose separatamente:
- Change logs: chi ha editato un esperimento, definizione metrica o decisione—cosa è cambiato e quando.
- Access logs: chi ha visualizzato o esportato risultati (soprattutto per esperimenti sensibili).
Esponi la cronologia delle modifiche nella UI per trasparenza e conserva log più approfonditi per investigazioni.
Regole di retention e cancellazione
Definisci regole di retention per:
- Metadati esperimento (hypothesis, owner, date, note di decisione)
- Risultati calcolati (effect size, intervalli, flag di significatività)
Rendi la retention configurabile per prodotto e sensibilità. Quando i dati devono essere rimossi, conserva un tombstone minimale (ID, orario di cancellazione, motivo) per preservare l’integrità dei report senza mantenere contenuti sensibili.
Workflow: dall’idea alla libreria degli apprendimenti
Un tracker diventa veramente utile quando copre l’intero ciclo di vita dell’esperimento, non solo il p-value finale. Le feature di workflow trasformano documenti sparsi, ticket e grafici in un processo ripetibile che migliora la qualità e rende gli apprendimenti riutilizzabili.
Workflow di lifecycle: idea → review → run → post-mortem
Modella gli esperimenti come una serie di stati (Draft, In Review, Approved, Running, Ended, Readout Published, Archived). Ogni stato dovrebbe avere criteri di uscita chiari così gli esperimenti non vanno in produzione senza essenziali come ipotesi, metrica primaria e guardrail.
Le approvazioni non devono essere pesanti. Un semplice step reviewer (es. product + data) più una traccia audit di chi ha approvato cosa e quando può prevenire errori evitabili. Dopo il completamento, richiedi un breve post-mortem prima di marcare l’esperimento “Published” per assicurare che risultati e contesto siano catturati.
Template che standardizzano il pensiero
Aggiungi template per:
- Brief dell’esperimento (obiettivo, ipotesi, audience target, metriche di successo, guardrail, piano di rollout)
- Note di analisi (fonti dati, esclusioni, sanity check, interpretazione, rischi)
I template riducono l’attrito del “foglio bianco” e velocizzano le review perché tutti sanno dove guardare. Lasciali editabili per prodotto mantenendo un nucleo comune.
Apprendimenti: collega tutto, rendilo ricercabile
Gli esperimenti raramente vivono isolati—gli utenti hanno bisogno del contesto. Permetti di allegare link a ticket/spec e writeup correlati (per esempio: /blog/how-we-define-guardrails, /blog/experiment-analysis-checklist). Memorizza campi strutturati “Learning” come:
- Che cosa è cambiato (decisione)
- Cosa abbiamo imparato (insight)
- Cosa fare dopo (follow-up)
Alert per guardrail e cambiamenti nei risultati
Supporta notifiche quando i guardrail peggiorano (es. error rate, cancellazioni) o quando i risultati cambiano sostanzialmente dopo dati tardivi o ricalcolo di metriche. Rendi gli alert azionabili: mostra metrica, soglia, intervallo e un owner per acknowledge o escalation.
Una vista library per riutilizzare lavori passati
Fornisci una libreria filtrabile per prodotto, area funzionale, audience, metrica, outcome e tag (es. “pricing”, “onboarding”, “mobile”). Aggiungi suggerimenti di “esperimenti simili” basati su tag/metriche condivise così i team evitano di ri-testare e possono invece costruire sugli apprendimenti precedenti.
Architettura e opzioni tech stack
Non serve uno stack “perfetto” per costruire un tracker di esperimenti—ma servono confini chiari: dove vivono i dati, dove girano i calcoli e come i team accedono ai risultati in modo coerente.
Uno stack baseline pratico
Per molti team, una configurazione semplice e scalabile è:
- Frontend: React (o Vue) per dashboard e workflow
- Backend API: Node.js/Express, Python/FastAPI o Java/Spring—scegli ciò che il tuo team può mantenere
- Database: Postgres per i dati applicativi (experiments, definizioni metriche, permessi)
- Analytics warehouse: BigQuery/Snowflake/Redshift per dati eventi e aggregazioni pesanti
Questa separazione mantiene le workflow transazionali veloci lasciando al warehouse i calcoli su larga scala.
Se vuoi prototipare l’UI rapidamente (experiments list → detail → readout) prima di impegnarti in un ciclo di engineering completo, una piattaforma di vibe-coding come Koder.ai può aiutare a generare una base funzionante React + backend da uno spec in chat. È utile per mettere in piedi entià, form, scaffolding RBAC e CRUD audit-friendly, poi iterare sui contratti dati con il team analytics.
Dove dovrebbero vivere i calcoli metrici?
Tipicamente hai tre opzioni:
- Warehouse-first: modelli SQL calcolano metriche e tabelle risultati. L’app legge principalmente.
- Backend jobs: un worker calcola i risultati su schedule o quando gli esperimenti cambiano.
- Ibrido: aggregazioni canoniche in warehouse, con post-processing backend (formatting, guardrail, caching).
Warehouse-first è spesso il più semplice se il data team già possiede SQL affidabile. Backend-heavy aiuta quando servono aggiornamenti a bassa latenza o logica custom, ma aumenta la complessità applicativa.
I dashboard ripetono spesso le stesse query (KPI top-line, serie temporali, slice per segmento). Pianifica di:
- Precomputare rollup (aggregati giornalieri per experiment/variant/segment)
- Cacheare letture costose a livello API (es. Redis) con regole di invalidazione chiare
- Usare materialized views o tabelle programmate nel warehouse per dashboard comuni
Multi-tenant vs single-tenant
Se supporti molti prodotti o business unit, decidi presto:
- Single-tenant (schema condiviso): più semplice da gestire, ma richiede filtering di permessi rigoroso.
- Multi-tenant: schemi/progetti separati per prodotto/team per maggior isolamento, più overhead.
Un compromesso comune è infrastruttura condivisa con forte modello tenant_id e accesso row-level forzato.
Definisci le API core
Mantieni l’API surface piccola ed esplicita. La maggior parte dei sistemi ha endpoint per experiments, metrics, results, segments e permissions (più letture audit-friendly). Questo rende più semplice aggiungere nuovi prodotti senza riscrivere la plumbing.
Testing, monitoraggio e operazioni affidabili
Pianifica la build a step
Definisci il modello dati, le API e il workflow di stato prima di generare l'app.
Un tracker è utile solo se le persone si fidano. Quella fiducia viene da testing disciplinato, monitoraggio chiaro e operazioni prevedibili—soprattutto quando più prodotti e pipeline alimentano le stesse dashboard.
Observability coerente con l’uso dell’app
Inizia con logging strutturato per ogni passo critico: ingest evento, assignment, rollup metriche, computazione risultati. Includi identificatori come product, experiment_id, metric_id e pipeline run_id così il supporto può tracciare un singolo risultato fino agli input.
Aggiungi metriche di sistema (latency API, runtime job, depth code) e metriche dati (eventi processati, % eventi tardivi, % scartati da validazione). Completa con tracing tra servizi per rispondere a “Perché questo esperimento manca i dati di ieri?”.
I check di freschezza dati sono il modo più rapido per prevenire failure silenziose. Se uno SLA è “giornaliero entro le 9am”, monitora freschezza per prodotto e per fonte, e allerta quando:
- manca la partizione più recente
- il volume eventi devia nettamente dal baseline
- i job di rollup finiscono ma producono zero righe
Test automatici: proteggi dati e matematica
Crea test a tre livelli:
- Schema e constraints: campi richiesti, unicità (es. un assignment per user per esperimento), foreign key, range date validi.
- Permessi: test RBAC (viewer/editor/admin) e scoping per prodotto così i team vedono solo ciò che devono.
- Matematica dei risultati: unit test per lift, intervalli, flag di significatività e casi limite (campioni piccoli, zero denominatori, più varianti).
Mantieni un piccolo “golden dataset” con output noti così intercetti regressioni prima di rilasciare.
Deploy, migration e sicurezza storica
Tratta le migrazioni come parte delle operations: versiona le definizioni metriche e la logica di computazione risultati, e evita di riscrivere esperimenti storici a meno che non sia richiesto esplicitamente. Quando servono cambi, fornisci un percorso di backfill controllato e documenta le modifiche in un audit trail.
Fornisci una vista admin per rieseguire una pipeline per uno specifico experiment/range di date, ispezionare errori di validazione e marcare incidenti con aggiornamenti di stato. Collega note di incidente direttamente dagli esperimenti impattati così gli utenti comprendono i ritardi e non prendono decisioni su dati incompleti.
Piano di rollout e insidie comuni da evitare
Rilasciare un tracker across prodotti non è una “giornata di lancio” ma un percorso per ridurre l’ambiguità: cosa viene tracciato, chi ne è owner e se i numeri rispecchiano la realtà.
Sequenza di rollout pratica
Inizia con un prodotto e un set di metriche ad alta confidenza (per esempio: conversion, activation, revenue). L’obiettivo è validare l’end-to-end—creazione esperimento, cattura exposure e outcome, calcolo risultati e registrazione decisione—prima di aggiungere complessità.
Una volta stabile il primo prodotto, espandi prodotto per prodotto con un onboarding prevedibile. Ogni nuovo prodotto dovrebbe sembrare una configurazione ripetibile, non un progetto custom.
Se l’organizzazione tende a incagliarsi in lunghi cicli di “costruzione piattaforma”, considera un approccio a due tracce: costruisci i contratti dati duraturi (eventi, ID, definizioni metriche) in parallelo con un layer applicativo sottile. Alcuni team usano Koder.ai per mettere su quel layer sottile rapidamente—form, dashboard, permessi ed export—poi lo consolidano mentre cresce l’adozione (incluso export del codice sorgente e rollback iterativi con snapshot quando i requisiti cambiano).
Checklist di rollout per ogni nuovo prodotto
Usa una checklist leggera per onboardare prodotti e schemi eventi in modo coerente:
- Conferma tassonomia eventi e convenzioni di naming (e chi può cambiarle)
- Verifica che esistano eventi di exposure univocamente attribuibili
- Mappa metriche allo schema eventi del prodotto (inclusi edge case come rimborsi)
- Esegui un backfill o un periodo di run parallelo per confrontare con l’analytics esistente
- Assegna ownership per setup esperimento, validazione dati e note di decisione finali
Dove aiuta l’adozione, collega “next steps” dai risultati dell’esperimento alle aree prodotto rilevanti (per esempio, esperimenti su pricing possono rimandare a /pricing). Mantieni i rimandi informativi e neutrali—senza implicare outcome.
Misura l’adozione per correggere frizioni presto
Valuta se lo strumento sta diventando il luogo di default per le decisioni:
- utenti attivi settimanali per ruolo (PM, analyst, engineer)
- esperimenti creati e completati
- percentuale con note di decisione compilate (non solo risultati visualizzati)
- tempo da fine esperimento → decisione registrata
Insidie comuni
Nella pratica, la maggior parte dei rollout inciampa su alcuni problemi ricorrenti:
- Definizioni metriche incoerenti across prodotti (stesso nome, matematica diversa)
- Tracciamento exposure mancante o difettoso, che porta a risultati distorti
- Ownership poco chiara per validazione e sign-off, causando esperimenti “zombie”
- Cambiamenti silenziosi di schema che spezzano trend senza avvisi
- Scalare a troppe metriche troppo presto, prima che il workflow core sia affidabile