18 ott 2025·8 min
Come creare un'app web per importare, esportare e validare i dati
Scopri come progettare un'app web che importa/esporta CSV/Excel/JSON, valida i dati con errori chiari, supporta ruoli, log di audit e processi affidabili.
Scopri come progettare un'app web che importa/esporta CSV/Excel/JSON, valida i dati con errori chiari, supporta ruoli, log di audit e processi affidabili.
Prima di progettare schermate o scegliere un parser di file, sii specifico su chi sposta i dati dentro e fuori dal tuo prodotto e perché. Un'app web per import dati pensata per operatori interni sarà molto diversa da uno strumento self-serve per importare Excel usato dai clienti.
Inizia elencando i ruoli che interagiranno con import/export:
Per ogni ruolo definisci il livello di competenza atteso e la tolleranza alla complessità. I clienti solitamente hanno bisogno di meno opzioni e di spiegazioni molto più chiare in prodotto.
Annota i tuoi scenari principali e mettili in ordine di priorità. I più comuni includono:
Poi definisci metriche di successo misurabili. Esempi: meno import falliti, tempo di risoluzione degli errori più breve, meno ticket di supporto su “il mio file non si carica”. Queste metriche ti aiutano a fare trade-off (es. investire in errori più chiari vs. più formati file).
Sii esplicito su cosa supporterai dal giorno uno:
Infine, identifica presto i bisogni di compliance: i file contengono PII? quali sono i requisiti di retention (per quanto conservi gli upload)? quali sono i requisiti di audit (chi ha importato cosa, quando e cosa è cambiato)? Queste decisioni influenzano storage, logging e permessi in tutto il sistema.
Prima di pensare a una UI elaborata per il mapping delle colonne o alle regole di validazione CSV, scegli un'architettura che il tuo team possa rilasciare e gestire con fiducia. Import/export sono infrastrutture “noiose”: velocità di iterazione e facilità di debug battono la novità.
Qualunque stack web mainstream può sostenere un'app per import dati. Scegli in base alle competenze esistenti e alla facilità di assumere persone:
La chiave è la coerenza: lo stack dovrebbe rendere semplice aggiungere nuovi tipi di import, nuove regole di validazione e nuovi formati di esportazione senza riscritture.
Se vuoi accelerare lo scaffolding senza impegnarti su un prototipo one-off, una piattaforma di vibe-coding come Koder.ai può essere utile: descrivi il flusso di import (upload → anteprima → mapping → validazione → elaborazione in background → cronologia) in chat, genera una UI React con backend Go + PostgreSQL e iteri velocemente usando planning mode e snapshot/rollback.
Usa un database relazionale (Postgres/MySQL) per i record strutturati, gli upsert e i log di audit delle modifiche.
Conserva gli upload originali (CSV/Excel) in object storage (S3/GCS/Azure Blob). Tenere i file raw è prezioso per il supporto: puoi riprodurre problemi di parsing, rieseguire job e spiegare le decisioni di gestione errori.
I file piccoli possono essere processati sincronamente (upload → valida → applica) per una UX reattiva. Per file più grandi, sposta il lavoro in job in background:
Questo ti mette anche nelle condizioni di gestire retry e scritture rate-limited.
Se costruisci SaaS, decidi presto come separare i dati dei tenant (scoping a livello di riga, schemi separati o DB separati). Questa scelta influenza API di export, permessi e prestazioni.
Annota obiettivi per uptime, dimensione massima file, righe attese per import, tempo di completamento e limiti di costo. Questi numeri guidano la scelta della coda di job, la strategia di batching e gli indici—molto prima di perfezionare la UI.
Il flusso di intake definisce l'esperienza di ogni import. Se sembra prevedibile e permissivo, gli utenti riproveranno quando qualcosa va storto—e i ticket di supporto diminuiranno.
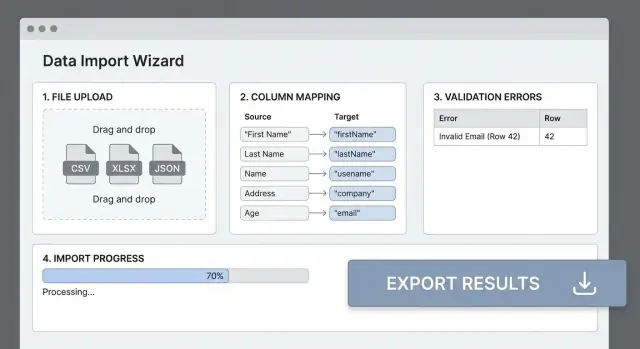
Offri un'area drag-and-drop oltre al classico file picker per la UI web. Il drag-and-drop è più veloce per utenti esperti, mentre il file picker è più accessibile e familiare.
Se i clienti importano da altri sistemi, aggiungi anche un endpoint API. Può accettare multipart (file + metadata) o un flusso con URL pre-firmati per file di grandi dimensioni.
Al momento dell'upload, esegui un parsing leggero per creare una “anteprima” senza impegnare i dati ancora:
Questa anteprima alimenta i successivi passi come il mapping delle colonne e la validazione.
Salva sempre il file originale in modo sicuro (object storage è tipico). Lascialo immutabile così puoi:
Tratta ogni upload come un record di prima classe. Salva metadata come uploader, timestamp, sistema sorgente, nome file e checksum (per rilevare duplicati e garantire integrità). Questo diventa fondamentale per auditabilità e debugging.
Esegui pre-check veloci subito e fallisci presto quando necessario:
Se un pre-check fallisce, ritorna un messaggio chiaro e indica cosa correggere. L'obiettivo è bloccare i file davvero invalidi—senza impedire dati validi ma imperfetti che possono essere mappati e puliti dopo.
La maggior parte dei fallimenti di import avviene perché gli header del file non corrispondono ai campi della tua app. Uno step chiaro di mapping trasforma un “CSV disordinato” in input prevedibile e risparmia agli utenti tentativi ed errori.
Mostra una tabella semplice: Colonna sorgente → Campo di destinazione. Rileva automaticamente i match probabili (match case-insensitive, sinonimi come “E-mail” → email), ma lascia sempre la possibilità all'utente di sovrascrivere.
Includi qualche tocco che migliora l'usabilità:
Se i clienti importano lo stesso formato ogni settimana, rendilo con un clic. Permetti di salvare template con ambiti:
Quando viene caricato un nuovo file, suggerisci un template basato sulla sovrapposizione delle colonne. Supporta anche versioning così gli utenti possono aggiornare un template senza rompere run precedenti.
Aggiungi trasformazioni leggere che gli utenti possono applicare per ogni campo mappato:
Mantieni le trasformazioni esplicite nell'UI (“Applicato: Trim → Parse Date”) così l'output è spiegabile.
Prima di processare l'intero file, mostra una anteprima dei risultati mappati per (ad esempio) 20 righe. Visualizza il valore originale, il valore trasformato e gli avvisi (tipo “Impossibile parsare la data”). Qui gli utenti intercettano i problemi presto.
Chiedi agli utenti di scegliere un campo chiave (email, external_id, SKU) e spiega cosa succede sui duplicati. Anche se gestirai upsert più avanti, questo passo imposta le aspettative: puoi avvisare sui duplicati nel file e suggerire quale record “vince” (first, last o error).
La validazione è la differenza tra un semplice “uploader di file” e una funzionalità di import di cui le persone si fidano. Lo scopo non è essere severi per forza—è impedire che dati cattivi si propaghino, fornendo feedback chiaro e azionabile.
Tratta la validazione come tre controlli distinti, ognuno con uno scopo diverso:
email è una stringa?”, “amount è un numero?”, “customer_id è presente?” Questo è veloce e può essere eseguito subito dopo il parsing.country=US, state è obbligatorio”, “end_date deve essere dopo start_date”, “Il nome del piano deve esistere in questo workspace.” Queste spesso richiedono contesto (altre colonne o lookup su DB).Tenere separati questi livelli rende il sistema più estensibile e più facile da spiegare nell'UI.
Decidi presto se un import dovrebbe:
Puoi anche supportare entrambi: strict come default e un'opzione “Allow partial import” per gli admin.
Ogni errore dovrebbe rispondere: cosa è successo, dove, e come risolverlo.
Esempio: “Riga 42, Colonna ‘Start Date’: deve essere una data valida nel formato YYYY-MM-DD.”
Differenzia:
Gli utenti raramente sistemano tutto in un solo tentativo. Rendi i re-upload indolori mantenendo i risultati di validazione legati a un tentativo di import e permettendo all'utente di ricaricare un file corretto. Abbina questo a report di errori scaricabili così risolvono in blocco.
Un approccio pratico è ibrido:
Questo mantiene la validazione flessibile senza trasformarla in un labirinto di impostazioni difficile da debugare.
Gli import falliscono spesso per motivi banali: DB lento, picchi di file, o una singola riga “cattiva” che blocca tutto. L'affidabilità è soprattutto spostare il lavoro pesante fuori dal path request/response e rendere ogni passaggio sicuro da rieseguire.
Esegui parsing, validazione e scritture in job in background (code/workers) così gli upload non incappano in timeout web. Questo permette anche di scalare i worker quando i clienti iniziano a importare fogli di grandi dimensioni.
Un pattern pratico è suddividere il lavoro in chunk (per esempio 1.000 righe per job). Un job “parent” pianifica job per chunk, aggrega i risultati e aggiorna il progresso.
Modella l'import come una macchina a stati così UI e team ops sanno sempre cosa sta succedendo:
Salva timestamp e conteggio tentativi per ogni transizione così puoi rispondere a “quando è iniziato?” e “quanti retry?” senza scavare nei log.
Mostra progresso misurabile: righe processate, righe rimanenti e errori finora. Se puoi stimare la throughput, aggiungi una ETA approssimativa—ma preferisci “~3 min” a un conto alla rovescia preciso.
I retry non devono creare duplicati o doppie applicazioni. Tecniche comuni:
import_id + row_number (o hash della riga) come chiave di idempotenza stabile.external_id) invece di “insert always”.Rate-limita gli import concorrenti per workspace e throttla le operazioni scrittura-intensive (es. max N righe/sec) per evitare di sovraccaricare il DB e degradare l'esperienza degli altri utenti.
Se le persone non capiscono cosa è andato storto, rilanceranno lo stesso file fino a quando si arrendono. Tratta ogni import come una “run” di prima classe con un chiaro tracciamento e errori azionabili.
Inizia creando un'entità import run nel momento in cui viene inviato un file. Questo record dovrebbe catturare l'essenziale:
Questo diventa la tua schermata cronologia import: una lista semplice di run con stato, conteggi e una pagina “view details”.
I log applicativi sono ottimi per gli ingegneri, ma gli utenti hanno bisogno di errori interrogabili. Memorizza errori come record strutturati legati alla import run, idealmente a due livelli:
Con questa struttura puoi abilitare filtri veloci e insight aggregati come “Top 3 tipi di errore della settimana”.
Nella pagina dei dettagli della run, fornisci filtri per tipo, colonna e severità, più una casella di ricerca (es. “email”). Poi offri un report errori scaricabile in CSV che include la riga originale più colonne aggiuntive come error_columns e error_message, con indicazioni chiare tipo “Correggi formato data in YYYY-MM-DD.”
Una “dry run” valida tutto usando lo stesso mapping e regole, ma non scrive dati. È ideale per importazioni iniziali e permette agli utenti di iterare in sicurezza prima di commettere le modifiche.
Gli import sembrano “completi” quando le righe arrivano nel DB—ma il costo a lungo termine è spesso in aggiornamenti disordinati, duplicati e cronologia di modifica poco chiara. Questa sezione riguarda il design del modello dati così che gli import siano prevedibili, reversibili e spiegabili.
Definisci come una riga importata mappa al modello di dominio. Per ogni entità, decidi se l'import può:
Questa decisione dovrebbe essere esplicita nell'UI di setup dell'import e memorizzata con il job in modo che il comportamento sia ripetibile.
Se supporti “create or update”, ti servono chiavi di upsert stabili—campi che identificano lo stesso record nel tempo. Scelte comuni:
external_id (ideale quando proviene da un altro sistema)account_id + sku)Definisci regole di collisione: cosa succede se due righe condividono la stessa chiave, o se una chiave corrisponde a più record? I default utili sono “fallisci la riga con errore chiaro” o “ultima riga vince”, ma scegli deliberatamente.
Usa transazioni dove proteggono la consistenza (es. creare un parent e i suoi figli). Evita una transazione gigantesca per un file da 200k righe; può lockare tabelle e rendere i retry difficili. Preferisci scritture chunked (es. 500–2.000 righe per batch) con upsert idempotenti.
Gli import devono rispettare le relazioni: se una riga fa riferimento a un record parent (es. Company), o lo richiedi che esista o lo crei in uno step controllato. Fallire presto con “parent mancante” previene dati mezzi collegati.
Aggiungi log di audit per i cambi fatti dagli import: chi ha triggerato l'import, quando, file sorgente e un sommario per record di cosa è cambiato (old vs new). Questo semplifica il supporto, aumenta la fiducia degli utenti e facilita rollback.
Le esportazioni sembrano semplici finché i clienti non provano a scaricare “tutto” alla scadenza. Un sistema di export scalabile gestisce dataset grandi senza rallentare l'app o produrre file inconsistenti.
Inizia con tre opzioni:
Gli export incrementali sono particolarmente utili per integrazioni e riducono il carico rispetto a dump completi ripetuti.
Qualunque formato tu scelga, mantieni header consistenti e ordine colonne stabile così i processi downstream non si rompano.
Le esportazioni grandi non devono caricare tutte le righe in memoria. Usa paginazione/streaming per scrivere righe mentre le recuperi. Questo evita timeout e mantiene l'app reattiva.
Per dataset grandi, genera le esportazioni con job in background e notifica l'utente quando sono pronte. Un pattern comune è:
Questo si abbina bene ai job in background per gli import e al medesimo pattern “cronologia run + artifact scaricabile” che usi per i report errori.
Gli export vengono spesso auditati. Includi sempre:
Questi dettagli riducono confusione e aiutano riconciliazioni affidabili.
Import/export sono funzionalità potenti perché spostano molti dati rapidamente. Questo le rende anche punti comuni per bug di sicurezza: un ruolo troppo permissivo, un URL file esposto o una riga di log che include dati personali.
Inizia con la stessa autenticazione usata in tutto il prodotto—non creare un percorso auth “speciale” solo per import/export.
Se gli utenti lavorano in browser, auth basata su sessione (con SSO/SAML opzionale) è spesso la scelta migliore. Se gli import/export sono automatizzati (job notturni, partner di integrazione), considera API key o token OAuth con scoping e rotazione chiari.
Una regola pratica: UI import e API import devono applicare gli stessi permessi, anche se usati da pubblici diversi.
Tratta le capacità di import/export come privilegi espliciti. Ruoli comuni includono:
Rendi “download files” un permesso separato. Molti leak sensibili avvengono quando qualcuno può vedere la run e il sistema presume che possa anche scaricare il foglio originale.
Considera anche confini a livello riga o tenant: un utente deve poter importare/esportare solo per l'account (o workspace) di cui fa parte.
Per i file memorizzati (upload, report errori generati, archivi di export) usa object storage privato e link di download a breve scadenza. Cripta a riposo quando richiesto dalla compliance e sii coerente: upload originale, file di staging elaborato e report generati devono seguire le stesse regole.
Fai attenzione ai log. Redigi campi sensibili (email, numeri di telefono, ID, indirizzi) e non loggare righe raw per default. Quando il debug lo richiede, abilita il “verbose row logging” solo dietro impostazioni admin e assicurati che scada.
Tratta ogni upload come input non attendibile:
Valida anche la struttura presto: rifiuta file evidentemente malformati prima che raggiungano i job in background e fornisci un messaggio chiaro all'utente su cosa non va.
Registra eventi utili in caso di indagine: chi ha caricato un file, chi ha avviato un import, chi ha scaricato un export, cambi permessi e tentativi di accesso falliti.
Le voci di audit dovrebbero includere attore, timestamp, workspace/tenant e l'oggetto interessato (import run ID, export ID), senza memorizzare dati sensibili a livello di riga. Questo si integra con la UI cronologia import e aiuta a rispondere a “chi ha cambiato cosa e quando?” rapidamente.
Se import/export toccano dati clienti, prima o poi incontrerai casi limite: encoding strani, celle unite, righe mezze compilate, duplicati e “ieri funzionava”. L'operabilità è ciò che impedisce a quei problemi di diventare incubi per il supporto.
Inizia con test mirati sulle parti più soggette a errore: parsing, mapping e validazione.
Poi aggiungi almeno un test end-to-end per il flusso completo: upload → elaborazione in background → generazione report. Questi test catturano mismatch di contract tra UI, API e worker.
Traccia segnali che riflettono impatto utente:
Collega alert a sintomi (aumento failure, crescita queue depth) piuttosto che ogni eccezione isolata.
Dai ai team interni una piccola superficie admin per rieseguire job, cancellare import bloccati e ispezionare i fallimenti (metadata file input, mapping usato, sommario errori e link a log/trace).
Per gli utenti, riduci errori prevenibili con suggerimenti inline, template di esempio scaricabili e passi successivi chiari nelle schermate di errore. Mantieni una pagina di help centrale e linkala dall'UI di import (ad esempio: /docs).
Rilasciare un sistema di import/export non è solo “push in produzione”. Trattalo come una funzionalità di prodotto con default sicuri, chiare vie di recupero e spazio per evolvere.
Configura ambienti separati dev/staging/prod con database isolati e bucket di object storage separati (o prefissi) per upload e export generati. Usa chiavi di crittografia e credenziali diverse per ambiente e assicurati che i worker puntino alle code giuste.
Lo staging dovrebbe rispecchiare la produzione: stessa concorrenza job, timeout e limiti dimensione file. È il posto dove validare prestazioni e permessi senza rischiare dati reali.
Gli import tendono a “vivere per sempre” perché i clienti conservano CSV vecchi. Usa migrazioni DB come al solito, ma versiona i template di import (e i preset di mapping) così una modifica dello schema non rompe i CSV del trimestre scorso.
Un approccio pratico è memorizzare template_version con ogni import run e mantenere codice di compatibilità per le versioni vecchie finché non puoi deprecarle.
Usa feature flag per rilasciare cambiamenti in sicurezza:
Le flag ti permettono di testare con utenti interni o una piccola coorte cliente prima di attivare tutto.
Documenta come il support indaga i fallimenti usando cronologia import, job ID e log. Una checklist semplice aiuta: conferma versione template, controlla la prima riga fallita, verifica accesso allo storage, poi ispeziona i log worker. Collega questo dal runbook interno e, quando opportuno, dalla UI admin (es. /admin/imports).
Una volta stabile il workflow core, estendilo oltre l'upload:
Questi upgrade riducono lavoro manuale e fanno sembrare l'app nativa nei processi esistenti dei clienti.
Se stai costruendo questa funzionalità come prodotto e vuoi accorciare il tempo per avere una “first usable version”, considera di usare Koder.ai per prototipare l'assistente di import, le pagine di stato job e le schermate cronologia end-to-end, poi esportare il codice sorgente per un workflow di engineering convenzionale. Questo approccio è particolarmente pratico quando l'obiettivo è affidabilità e velocità di iterazione (non la perfezione UI su day one).
Inizia chiarendo chi importa/esporta (admin, operatori, clienti) e i principali casi d'uso (caricamento massivo in onboarding, sincronizzazioni periodiche, esportazioni one-off).
Scrivi i vincoli da giorno uno:
Queste decisioni guidano l'architettura, la complessità dell'interfaccia e il carico di supporto.
Usa l'elaborazione sincrona quando i file sono piccoli e la validazione + scrittura finiscono entro i timeout della richiesta web.
Usa i job in background quando:
Un pattern comune: upload → enqueue → mostra stato/progresso della run → notifica al completamento.
Conserva entrambi, per motivi diversi:
Mantieni l'upload raw immutabile e collegalo a un import run.
Costruisci uno step di anteprima che rileva header e analizza un piccolo campione (es. 20–100 righe) prima di commettere qualsiasi dato.
Gestisci la variabilità comune:
Blocca subito i veri ostacoli (file illeggibile, colonne richieste mancanti), ma non rifiutare dati che possono essere mappati o trasformati in seguito.
Usa una tabella semplice: Colonna sorgente → Campo di destinazione.
Best practice:
Mostra sempre un'anteprima mappata così l'utente può intercettare errori prima di processare l'intero file.
Supporta trasformazioni leggere e sempre esplicite in modo che l'utente possa prevederne l'effetto:
ACTIVE)Mostra “originale → trasformato” nell'anteprima e segnala avvisi quando una trasformazione non è applicabile.
Separa la validazione in livelli:
Nell'interfaccia mostra messaggi azionabili con riferimento a riga/colonna (es. “Riga 42, Start Date: deve essere YYYY-MM-DD”).
Decidi se gli import sono (fallisce tutto il file) o (accetta righe valide); considera di offrire entrambe le opzioni per gli admin.
Rendi il processamento sicuro per i retry:
import_id + row_number o hash della riga)external_id) invece di “insert sempre”Crea un record di import run non appena viene inviato un file e memorizza errori strutturati, non solo log.
Funzionalità utili per i report errori:
Tratta import/export come azioni privilegiate:
Se gestisci PII, definisci fin da subito policy di retention e cancellazione per non accumulare file sensibili indefinitamente.
Limita anche gli import concorrenti per workspace per proteggere il DB e gli altri utenti.
error_columns e error_messageQuesto riduce il comportamento “rilancio finché non funziona” e i ticket di supporto.