06 nov 2025·8 min
Come costruire un'app web per il tracciamento degli incidenti e i postmortem
Un piano pratico per progettare, costruire e lanciare un’app web per il tracciamento degli incidenti e i postmortem: workflow, modello dati e UX.
Un piano pratico per progettare, costruire e lanciare un’app web per il tracciamento degli incidenti e i postmortem: workflow, modello dati e UX.
Prima di disegnare schermate o scegliere un database, allineatevi su cosa intende il vostro team per incident tracking web app — e cosa deve ottenere la “gestione dei postmortem”. I team spesso usano le stesse parole in modo diverso: per un gruppo un incidente è qualunque problema segnalato dal cliente; per un altro è solo un outage Sev-1 con escalation on-call.
Scrivete una definizione breve che risponda a:
Questa definizione guida il vostro incident response workflow e impedisce che l’app diventi troppo rigida (nessuno la usa) o troppo lasca (dati incoerenti).
Decidete cosa sia un postmortem nella vostra organizzazione: un riassunto leggero per ogni incidente, o una RCA completa solo per eventi ad alta severità. Rendete esplicito se l’obiettivo è apprendimento, compliance, ridurre incidenti ripetuti, o tutti e tre.
Una regola utile: se vi aspettate che un postmortem generi cambiamenti, lo strumento deve supportare il tracciamento degli action item, non solo l’archiviazione dei documenti.
La maggior parte dei team costruisce questo tipo di app per risolvere alcuni dolori ricorrenti:
Tenete la lista stretta. Ogni funzionalità che aggiungete dovrebbe mappare ad almeno uno di questi problemi.
Scegliete poche metriche che potete misurare automaticamente dal modello dati dell’app:
Queste diventano le metriche operative e la vostra “definition of done” per la prima release.
La stessa app serve ruoli diversi nelle operazioni on-call:
Se progettate per tutti contemporaneamente costruirete un’interfaccia ingombra. Invece, scegliete un utente primario per la v1 — e assicuratevi che gli altri possano comunque ottenere quello di cui hanno bisogno tramite viste su misura, dashboard e permessi più avanti.
Un workflow chiaro evita due modalità di fallimento comuni: incidenti che si bloccano perché nessuno sa “cosa fare dopo”, e incidenti che sembrano “chiusi” ma non producono apprendimento. Iniziate mappando il ciclo di vita end-to-end e poi assegnate ruoli e permessi a ciascun passo.
La maggior parte dei team segue un arco semplice: detect → triage → mitigate → resolve → learn. La vostra app dovrebbe riflettere questo con un piccolo set di passi prevedibili, non un menu infinito di opzioni.
Definite cosa significa “fatto” per ogni fase. Per esempio, la mitigazione potrebbe significare che l’impatto sul cliente è fermato, anche se la causa principale è ancora sconosciuta.
Tenete i ruoli espliciti così le persone possano agire senza aspettare riunioni:
La UI dovrebbe rendere visibile il “current owner” e il workflow dovrebbe supportare la delega (riassegnare, aggiungere responder, ruotare il commander).
Scegliete stati obbligatori e transizioni consentite, come Investigating → Mitigated → Resolved. Aggiungete dei guardrail:
Separate aggiornamenti interni (veloci, tattici, possono essere disordinati) dagli aggiornamenti per stakeholder (chiari, timestamped, curati). Costruite due flussi di aggiornamento con template, visibilità e regole di approvazione differenti — spesso il commander è l’unico publisher per gli aggiornamenti agli stakeholder.
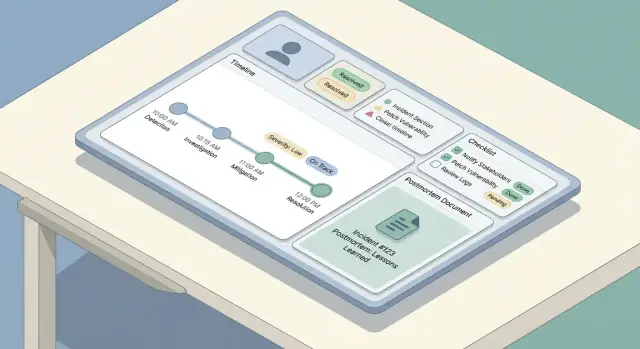
Un buon strumento per incidenti sembra “semplice” nell’UI perché il modello dati sottostante è consistente. Prima di costruire schermate, decidete quali oggetti esistono, come si relazionano e cosa deve restare storicizzato.
Iniziate con un piccolo insieme di oggetti di prima classe:
La maggior parte delle relazioni è uno-a-molti:
Usate identificatori stabili (UUID) per incidenti ed eventi. Gli umani hanno ancora bisogno di una chiave amichevole come INC-2025-0042, che potete generare da una sequenza.
Modellateli presto così potete filtrare, cercare e creare report:
I dati sugli incidenti sono sensibili e spesso vengono riesaminati. Trattate le modifiche come dati — non sovrascritture:
Questa struttura rende più facili in seguito funzionalità come ricerca, metriche e permessi senza rifare il lavoro.
Quando qualcosa si rompe, il compito dell’app è ridurre la digitazione e aumentare la chiarezza. Questa sezione copre il “percorso di scrittura”: come le persone creano un incidente, lo aggiornano e ricostruiscono cosa è successo dopo.
Mantenete il form di creazione abbastanza corto da poter essere completato mentre si troubleshoot. Un buon set di campi obbligatori è:
Tutto il resto dovrebbe essere opzionale alla creazione (impatto, link a ticket clienti, causa sospettata). Usate smart default: impostate start time su “adesso”, pre-selezionate il team on-call dell’utente e offrite un’azione one-tap “Create & open incident room”.
L’UI per gli aggiornamenti deve essere ottimizzata per modifiche ripetute e piccole. Fornite un pannello compatto con:
Fate in modo che gli aggiornamenti siano append-only: ogni update diventa una voce timestamped, non una sovrascrittura del testo precedente.
Costruite una timeline che mescoli:
Questo crea una narrazione affidabile senza costringere le persone a ricordarsi di registrare ogni clic.
Durante un outage molti aggiornamenti avvengono da telefono. Prioritizzate una schermata veloce e a basso attrito: grandi target touch, una singola pagina scrollabile, bozze offline-friendly e azioni one-tap come “Post update” e “Copy incident link”.
La severity è il “speed dial” della risposta agli incidenti: dice alle persone quanto urgentemente agire, quanto comunicare e quali compromessi sono accettabili.
Evitate etichette vaghe come “alto/medio/basso.” Fate in modo che ogni livello di severity mappi a aspettative operative chiare — soprattutto tempi di risposta e cadenza comunicativa.
Per esempio:
Rendete queste regole visibili nell’UI dove si sceglie la severity, così i responder non devono cercare la documentazione.
Le checklist riducono il carico cognitivo quando le persone sono sotto stress. Tenetele brevi, azionabili e legate ai ruoli.
Un pattern utile è dividere in sezioni:
Fate sì che gli item della checklist siano timestamped e attribuiti, così diventano parte del record dell’incidente.
Gli incidenti raramente vivono in un solo strumento. L’app dovrebbe permettere di allegare link a:
Preferite link “tipizzati” (es. Runbook, Ticket) così possono essere filtrati dopo.
Se la vostra organizzazione traccia target di affidabilità, aggiungete campi leggeri come SLO affected (yes/no), estimated error budget burn, e customer SLA risk. Rendeteli opzionali — ma facili da compilare durante o subito dopo l’incidente, quando i dettagli sono freschi.
Un buon postmortem è facile da iniziare, difficile da dimenticare e coerente tra i team. Il modo più semplice per arrivarci è fornire un template predefinito (con campi minimi obbligatori) e precompilarlo dall’incidente in modo che le persone pensino, non riscrivano.
Il template integrato dovrebbe bilanciare struttura e flessibilità:
Rendete “Root cause” opzionale nelle fasi iniziali se volete pubblicare più velocemente, ma richiedetela prima dell’approvazione finale.
Il postmortem non dovrebbe essere un documento separato che galleggia. Quando si crea un postmortem, collegate automaticamente:
Usate questi elementi per precompilare sezioni del postmortem. Per esempio, il blocco “Impact” può partire dagli start/end time e dalla severity dell’incidente, mentre “Cosa abbiamo fatto” può attingere dalle voci della timeline.
Aggiungete un workflow leggero così i postmortem non si bloccano:
A ogni step catturate decision notes: cosa è cambiato, perché, e chi l’ha approvato. Questo evita “modifiche silenziose” e facilita audit e review future.
Se volete mantenere l’UI semplice, trattate le review come commenti con esiti espliciti (Approve / Request changes) e memorizzate l’approvazione finale come record immutabile.
Per i team che ne hanno bisogno, collegate “Published” al workflow di status update (vedi /blog/integrations-status-updates) senza copiare contenuti a mano.
I postmortem riducono gli incidenti futuri solo se il lavoro di follow-up viene effettivamente fatto. Trattate gli action item come oggetti di prima classe nell’app — non come un paragrafo in fondo a un documento.
Ogni action item dovrebbe avere campi coerenti così può essere tracciato e misurato:
Aggiungete metadati utili: tag (es. “monitoring”, “docs”), componente/servizio, e “created from” (incident ID e postmortem ID).
Non intrappolate gli action item dentro una singola pagina di postmortem. Fornite:
Questo trasforma i follow-up in una coda operativa anziché in note sparse.
Alcuni task si ripetono (game day trimestrali, review dei runbook). Supportate un template ricorrente che genera nuovi item su uno schedule, mantenendo ogni occorrenza tracciabile singolarmente.
Se i team già usano un altro tracker, permettete che un action item includa un riferimento esterno e un ID esterno, mantenendo comunque la vostra app come fonte per il linkage e la verifica.
Costruite nudges leggeri: notifiche ai owner man mano che la due date si avvicina, flag sugli overdue al team lead, e segnalazione di pattern cronici nei report. Tenete le regole configurabili così i team possono adattarle alle loro operazioni on-call e alla realtà del carico lavoro.
Incidenti e postmortem spesso contengono dettagli sensibili — identificativi clienti, IP interni, scoperte di sicurezza o problemi con fornitori. Regole di accesso chiare mantengono lo strumento utile per la collaborazione senza trasformarlo in una perdita di dati.
Iniziate con ruoli piccoli e comprensibili:
Se avete più team, considerate di scoped roles by service/team (es. “Payments Editors”) invece di permessi globali.
Classificate i contenuti presto, prima che si creino abitudini:
Un pattern pratico è marcare sezioni come Internal o Shareable ed applicarlo in esportazioni e status page. Gli incidenti di sicurezza potrebbero richiedere un tipo separato con default più restrittivi.
Per ogni cambiamento a incidenti e postmortem registrate: chi l’ha cambiato, cosa è cambiato e quando. Incluse modifiche a severity, timestamp, impatto e approvazioni finali. Rendete gli audit log ricercabili e non editabili.
Supportate autenticazione robusta out of the box: email + MFA o magic link, e aggiungete SSO (SAML/OIDC) se gli utenti lo richiedono. Usate sessioni a breve durata, cookie sicuri, protezione CSRF e revoca automatica delle sessioni su cambi di ruolo. Per considerazioni sul rollout vedi /blog/testing-rollout-continuous-improvement.
Quando un incidente è attivo, le persone scansionano — non leggono. La UX dovrebbe rendere lo stato corrente ovvio in pochi secondi, permettendo comunque ai responder di approfondire senza perdersi.
Iniziate con tre schermate che coprono la maggior parte dei workflow:
Una regola semplice: la pagina dettaglio deve rispondere “Cosa sta succedendo adesso?” in alto, e “Come siamo arrivati qui?” sotto.
Gli incidenti si accumulano rapidamente, quindi rendete la scoperta veloce e permissiva:
Offrite viste salvate come My open incidents o Sev-1 this week così gli on-call non ricostruiscono i filtri a ogni turno.
Usate badge consistenti e con contrasti accessibili in tutta l’app. Mantenete lo stesso vocabolario di stato ovunque: lista, header dettaglio e eventi timeline.
A colpo d’occhio il responder dovrebbe vedere:
Prioritizzate la scansionabilità:
Progettate per il momento peggiore: se qualcuno è svegliato di notte e consulta l’app da telefono, l’interfaccia deve comunque guidarlo all’azione corretta velocemente.
Le integrazioni trasformano un tracker di incidenti da “luogo dove scrivere note” al sistema con cui il team gestisce davvero gli incidenti. Iniziate elencando i sistemi da connettere: monitoring/observability (PagerDuty/Opsgenie, Datadog, CloudWatch), chat (Slack/Teams), email, ticketing (Jira/ServiceNow) e una status page.
La maggior parte dei team finisce con un mix:
Gli alert sono rumorosi, ritentano e spesso arrivano fuori ordine. Definite una chiave di idempotenza stabile per evento provider (per esempio: provider + alert_id + occurrence_id) e salvatela con vincolo di unicità. Per la deduplica, decidete regole come “stesso servizio + stessa signature entro 15 minuti” devono appendersi a un incidente esistente anziché crearne uno nuovo.
Siate espliciti su cosa possiede l’app rispetto a cosa rimane nello strumento sorgente:
Quando un’integrazione fallisce, degradate con grazia: mettere in coda i retry, mostrare un avviso sull’incidente (“Pubblicazione su Slack ritardata”) e permettere sempre agli operatori di continuare manualmente.
Trattate gli aggiornamenti di stato come output di prima classe: un’azione “Update” strutturata nell’UI dovrebbe poter pubblicare in chat, appenderla alla timeline dell’incidente e opzionalmente sincronizzarsi con la status page — senza chiedere al responder di scrivere lo stesso messaggio tre volte.
Il vostro strumento per incidenti è un sistema “during-an-outage”, quindi preferite semplicità e affidabilità alla novità. Lo stack migliore è spesso quello che il vostro team sa già costruire, debuggare e operare alle 2 del mattino con fiducia.
Partite da ciò che gli ingegneri già deployano in produzione. Un framework web mainstream (Rails, Django, Laravel, Spring, Express/Nest, ASP.NET) è di solito più sicuro rispetto a un framework nuovo che solo una persona conosce.
Per lo storage, un database relazionale (PostgreSQL/MySQL) si adatta bene ai record di incidente: incidents, updates, participants, action items e postmortem beneficiano di transazioni e relazioni chiare. Aggiungete Redis solo se serve davvero per caching, code o lock effimeri.
L’hosting può essere semplice come una piattaforma managed (Render/Fly/Heroku-like) o il vostro cloud esistente (AWS/GCP/Azure). Preferite database gestiti e backup gestiti quando possibile.
Gli incidenti attivi sembrano migliori con aggiornamenti real-time, ma non sempre servono websockets dal day one.
Un approccio pratico: progettate API/eventi così potete partire con polling e passare a websockets più avanti senza riscrivere l’UI.
Se questa app fallisce durante un incidente, diventa parte dell’incidente. Aggiungete:
Trattatelo come un sistema di produzione:
Se volete validare workflow e schermate prima di investire in un build completo, un approccio vibe-coding può funzionare: usate uno strumento come Koder.ai per generare un prototipo funzionante da una spec dettagliata in chat, poi iterate con i responder durante tabletop exercises. Perché Koder.ai può produrre front-end React reali con backend Go + PostgreSQL (e supporta l’export del codice), potete trattare le prime versioni come prototipi “usa e getta” o come punto di partenza da hardenare — senza perdere gli apprendimenti raccolti dalle simulazioni reali.
Rilasciare uno strumento per incidenti senza prove è un rischio. I migliori team trattano lo strumento come qualsiasi altro sistema operativo: testate i percorsi critici, fate esercitazioni realistiche, rilasciate gradualmente e continuate a tarare basandovi sull’uso reale.
Mettete il focus sui flussi su cui le persone si baseranno sotto forte stress:
Aggiungete test di regressione che validino ciò che non deve rompersi: timestamp, fusi orari e ordinamento eventi. Gli incidenti sono narrazioni — se la timeline è sbagliata, la fiducia svanisce.
I bug di permessi sono rischi operativi e di sicurezza. Scrivete test che comprovino:
Testate anche casi limite come un utente che perde accesso a metà incidente o una riorganizzazione che cambia membership dei gruppi.
Prima del rollout più ampio fate simulazioni tabletop usando la vostra app come fonte di verità. Scegliete scenari riconoscibili dall’organizzazione (es. outage parziale, ritardo dati, failure di terze parti). Osservate gli attriti: campi confusi, contesto mancante, troppi click, ownership poco chiara.
Catturate il feedback subito e trasformate i problemi in piccoli miglioramenti rapidi.
Iniziate con un team pilota e pochi template preconfezionati (tipi incidente, checklist, formati postmortem). Fornite training brevi e una one-page “how we run incidents” linkata dall’app (es. /docs/incident-process).
Tracciate metriche di adozione e iterate sui punti di attrito: time-to-create, % incidenti con aggiornamenti, tasso di completamento postmortem e tempo di chiusura degli action item. Trattatele come metriche di prodotto — non di compliance — e migliorate a ogni release.
Iniziate scrivendo una definizione concreta su cui l’organizzazione sia d’accordo:
Questa definizione deve mappare direttamente agli stati del flusso di lavoro e ai campi obbligatori, così i dati restano coerenti senza diventare pesanti.
Trattate i postmortem come un workflow, non come un semplice documento:
Se vi aspettate cambiamento, servono tracciamento degli action item e promemoria — non solo archiviazione.
Un set pratico per la v1:
Sospendete automazioni avanzate fino a che questi flussi non funzionano bene sotto stress.
Usate un numero piccolo di stati prevedibili allineati al modo di lavorare dei team:
Definite cosa significa “done” per ogni fase, poi aggiungete dei guardrail:
Questo evita incidenti bloccati e migliora la qualità delle analisi successive.
Modellate pochi ruoli chiari e collegate i permessi:
Rendete evidente chi è l’owner/commander corrente nell’interfaccia e permettete la delega (reassign, rotate commander).
Mantenete il modello di dati piccolo ma strutturato:
Usate identificatori stabili (UUID) più una chiave leggibile dall’umano (es. INC-2025-0042). Trattate le modifiche come storia con created_at/created_by e un audit log per le variazioni.
Separate i flussi e applicate regole diverse:
Implementate template/visibilità differenti e memorizzate entrambi nello stesso record d’incidente così da poter ricostruire le decisioni senza perdere dettagli sensibili.
Definite livelli di severity con aspettative esplicite (urgenza di risposta e cadenza comunicativa). Per esempio:
Mostrate le regole nell’UI ogni volta che si sceglie la severity, così i responder non devono cercare documentazione esterna durante un outage.
Trattate gli action item come record strutturati, non come testo libero:
Poi fornite viste globali (overdue, due soon, per owner/service) e promemoria/escalation leggeri così i follow-up non spariscono dopo la review.
Usate chiavi di idempotenza specifiche per provider e regole di dedup:
provider + alert_id + occurrence_idConsentite sempre il linking manuale come fallback quando le API o le integrazioni falliscono.