14 ott 2025·8 min
Che cos'è GraphQL? Guida chiara per API e recupero dati
Scopri cos'è GraphQL, come funzionano query, mutation e schema, e quando usarlo invece di REST—più vantaggi, svantaggi e esempi pratici.
Scopri cos'è GraphQL, come funzionano query, mutation e schema, e quando usarlo invece di REST—più vantaggi, svantaggi e esempi pratici.
GraphQL è un linguaggio di query e un runtime per API. In poche parole: è un modo per un'app (web, mobile o un altro servizio) di chiedere a un'API dei dati con una richiesta chiara e strutturata — e per il server di restituire una risposta che corrisponde a quella richiesta.
Molte API costringono i client ad accettare tutto ciò che un endpoint fisso restituisce. Questo porta spesso a due problemi:
Con GraphQL, il client può richiedere esattamente i campi di cui ha bisogno, né più né meno. Questo è particolarmente utile quando schermate diverse (o app diverse) necessitano di "fette" diverse dello stesso dato sottostante.
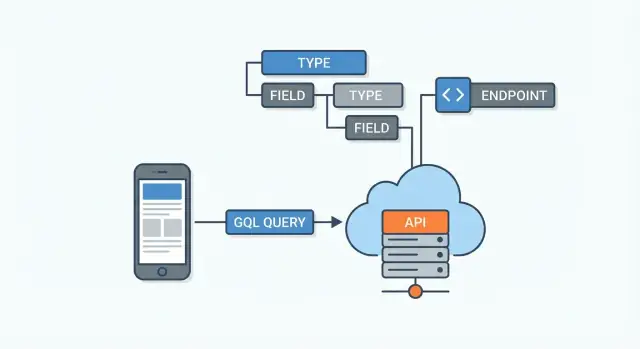
GraphQL di solito sta tra le app client e le tue sorgenti di dati. Quelle sorgenti possono essere:
Il server GraphQL riceve una query, decide come recuperare ogni campo richiesto dal posto giusto e poi compone la risposta JSON finale.
Pensa a GraphQL come ordinare una risposta su misura:
GraphQL viene spesso frainteso, quindi ecco alcune chiarificazioni:
Se mantieni questa definizione centrale — linguaggio di query + runtime per API — avrai la base giusta per tutto il resto.
GraphQL è nato per risolvere un problema pratico di prodotto: i team passavano troppo tempo ad adattare le API alle schermate reali.
Le API tradizionali basate su endpoint spesso costringono a scegliere tra spedire più dati del necessario o effettuare chiamate extra per ottenere ciò che serve. Con la crescita del prodotto, questa frizione si traduce in pagine più lente, codice client più complesso e coordinazione difficile tra frontend e backend.
Over-fetching accade quando un endpoint restituisce un oggetto “completo” anche se una schermata ha bisogno solo di pochi campi. Una vista profilo mobile potrebbe aver bisogno solo di nome e avatar, ma l'API restituisce indirizzi, preferenze, campi di audit e altro ancora. Questo spreca banda e può penalizzare l'esperienza utente.
Under-fetching è l'opposto: nessun endpoint singolo ha tutto ciò che serve, quindi il client deve fare più richieste e unire i risultati. Questo aumenta la latenza e il rischio di errori parziali.
Molte API in stile REST rispondono al cambiamento aggiungendo nuovi endpoint o versionando (v1, v2, v3). Il versioning può essere necessario, ma crea lavoro di manutenzione a lungo termine: i client vecchi continuano a usare vecchie versioni mentre nuove funzionalità si accumulano altrove.
L'approccio di GraphQL è far evolvere lo schema aggiungendo campi e tipi nel tempo, mantenendo stabili i campi esistenti. Questo spesso riduce la pressione di creare “nuove versioni” solo per supportare nuove necessità dell'interfaccia.
I prodotti moderni raramente hanno un solo consumatore. Web, iOS, Android e integrazioni partner richiedono tutte forme di dati diverse.
GraphQL è progettato in modo che ogni client possa richiedere esattamente i campi di cui ha bisogno — senza che il backend debba creare un endpoint separato per ogni schermata o dispositivo.
Un'API GraphQL è definita dal suo schema. Pensalo come l'accordo tra server e client: elenca quali dati esistono, come sono connessi e cosa può essere richiesto o modificato. I client non indovinano endpoint: leggono lo schema e chiedono campi specifici.
Lo schema è composto da tipi (come User o Post) e campi (come name o title). I campi possono puntare ad altri tipi, ed è così che GraphQL modella le relazioni.
Ecco un esempio semplice in Schema Definition Language (SDL):
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
Poiché lo schema è fortemente tipizzato, GraphQL può validare una richiesta prima di eseguirla. Se un client chiede un campo che non esiste (per esempio, Post.publishDate quando lo schema non prevede quel campo), il server può rifiutare o soddisfare parzialmente la richiesta con errori chiari — senza comportamenti ambigui.
Gli schemi sono pensati per crescere. Di solito puoi aggiungere nuovi campi (per esempio User.bio) senza rompere i client esistenti, perché i client ricevono solo ciò che chiedono. Rimuovere o cambiare campi è più delicato, perciò i team spesso deprecano i campi prima di eliminarli e migrano i client gradualmente.
Un'API GraphQL è tipicamente esposta tramite un endpoint singolo (per esempio, /graphql). Invece di avere molte URL per risorse diverse (come /users, /users/123, /users/123/posts), mandi una query in un unico posto e descrivi esattamente i dati che vuoi ricevere.
Una query è sostanzialmente una "lista della spesa" di campi. Puoi richiedere campi semplici (come id e name) e anche dati annidati (come i post recenti di un utente) nella stessa richiesta — senza scaricare campi extra che non ti servono.
Ecco un piccolo esempio:
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
Le risposte GraphQL sono prevedibili: il JSON che ricevi rispecchia la struttura della query. Questo rende il lavoro sul frontend più semplice, perché non devi indovinare dove appariranno i dati o parsare formati di risposta diversi.
Un esempio semplificato potrebbe assomigliare a:
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
Se non chiedi un campo, non verrà incluso. Se lo chiedi, puoi aspettarti di trovarlo nel punto corrispondente — questo rende le query GraphQL un modo pulito per prendere esattamente ciò che ogni schermata o funzionalità richiede.
Le query servono per leggere; le mutation sono il modo per modificare i dati in un'API GraphQL — creare, aggiornare o cancellare record.
La maggior parte delle mutation segue lo stesso schema:
input) con i campi da aggiornare.Le mutation GraphQL di solito restituiscono dati intenzionalmente, invece di limitarsi a success: true. Restituire l'oggetto aggiornato (o almeno il suo id e i campi principali) aiuta l'interfaccia a:
Un design comune è un tipo "payload" che include sia l'entità aggiornata sia eventuali errori.
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
Per API orientate all'interfaccia, una buona regola è: restituisci ciò che serve per renderizzare lo stato successivo (per esempio l'user aggiornato più eventuali errors). Questo mantiene il client semplice, evita di indovinare cosa è cambiato e facilita la gestione degli errori.
Uno schema GraphQL descrive cosa si può chiedere. I resolver descrivono come ottenere effettivamente quei dati. Un resolver è una funzione collegata a un campo specifico nello schema. Quando un client richiede quel campo, GraphQL invoca il resolver per recuperare o calcolare il valore.
GraphQL esegue una query percorrendo la forma richiesta. Per ogni campo, trova il resolver corrispondente e lo esegue. Alcuni resolver semplicemente ritornano una proprietà di un oggetto già in memoria; altri interrogano un database, chiamano un servizio o combinano più sorgenti.
Per esempio, se lo schema ha User.posts, il resolver posts potrebbe interrogare la tabella posts filtrando per userId, o chiamare un servizio Posts separato.
I resolver sono il collante tra lo schema e i tuoi sistemi reali:
Questa mappatura è flessibile: puoi cambiare l'implementazione backend senza modificare la forma della query client — purché lo schema rimanga coerente.
Poiché i resolver possono eseguire per campo e per elemento in una lista, è facile inavvertitamente generare molte chiamate piccole (ad esempio, recuperare post per 100 utenti con 100 query separate). Questo pattern "N+1" può rallentare le risposte.
Le soluzioni comuni includono batching e caching (es. raccogliere gli ID e recuperare in una singola query) e decidere intenzionalmente quali campi annidati incoraggiare i client a richiedere.
L'autorizzazione viene spesso applicata nei resolver (o in middleware condivisi) perché i resolver conoscono chi sta chiedendo (tramite il context) e quali dati si stanno accedendo. La validazione avviene a due livelli: GraphQL gestisce automaticamente la validazione di tipo/forma, mentre i resolver fanno rispettare le regole di business (per esempio, "solo gli admin possono impostare questo campo").
Una cosa che sorprende chi è nuovo a GraphQL è che una richiesta può “riuscire” e comunque includere errori. Questo perché GraphQL è orientato ai campi: se alcuni campi si risolvono e altri no, potresti ottenere dati parziali.
Una tipica risposta GraphQL può contenere sia data sia un array errors:
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
Questo è utile: il client può comunque renderizzare ciò che ha (per esempio il profilo utente) gestendo il campo mancante.
data è spesso null.Scrivi messaggi di errore per l'utente finale, non per il debugging. Evita di esporre stack trace, nomi di database o ID interni. Un buon pattern è:
message breve e sicuroextensions.code leggibile dalla macchina e stabileretryable: true)Logga l'errore dettagliato lato server con un request ID in modo da poter indagare senza esporre gli internals.
Definisci un piccolo "contratto" di errori condiviso tra web e mobile: valori comuni in extensions.code (come UNAUTHENTICATED, FORBIDDEN, BAD_USER_INPUT), quando mostrare una notifica vs un errore inline, e come trattare i dati parziali. La coerenza evita che ogni client inventi regole diverse.
Le subscriptions sono il modo di GraphQL per inviare dati ai client mentre cambiano, invece di farli chiedere continuamente. Di solito sono veicolate su una connessione persistente (più comunemente WebSockets), così il server può inviare eventi non appena accadono.
Una subscription somiglia molto a una query, ma il risultato non è una singola risposta. È un flusso di risultati — ognuno rappresenta un evento.
Sotto il cofano, un client si "iscrive" a un argomento (per esempio messageAdded in una chat). Quando il server pubblica un evento, i subscriber connessi ricevono un payload che rispecchia la selection set della subscription.
Le subscriptions brillano quando si aspettano cambiamenti istantanei:
Con il polling il client chiede “c'è qualcosa di nuovo?” ogni N secondi. È semplice, ma può sprecare richieste (soprattutto quando nulla cambia) e restituire aggiornamenti con ritardo.
Con le subscriptions, il server invia l'aggiornamento immediatamente. Questo può ridurre traffico inutile e migliorare la percezione di velocità — al costo di mantenere connessioni aperte e gestire l'infrastruttura realtime.
Le subscriptions non sono sempre giustificate. Se gli aggiornamenti sono rari, non urgenti o facilmente raggruppabili, il polling (o semplicemente rifetch dopo azioni utente) è spesso sufficiente.
Aggiungono anche overhead operativo: scalare le connessioni, autenticare sessioni di lunga durata, retry e monitoraggio. Una buona regola: usa subscriptions solo quando il realtime è un requisito di prodotto, non semplicemente un "nice-to-have".
GraphQL viene spesso descritto come “potere al client”, ma quel potere ha dei costi. Conoscere i compromessi aiuta a decidere quando GraphQL è la scelta giusta — e quando può essere eccessivo.
Il guadagno più grande è il recupero dati flessibile: i client possono richiedere esattamente i campi necessari, riducendo l'over-fetching e rendendo più rapide le modifiche UI.
Un altro vantaggio importante è il contratto forte fornito dallo schema GraphQL. Lo schema diventa una single source of truth per tipi e operazioni disponibili, migliorando collaborazione e tooling.
I team spesso vedono miglior produttività lato client perché gli sviluppatori frontend possono iterare senza aspettare nuove varianti di endpoint, e strumenti come Apollo Client possono generare tipi e semplificare il recupero dati.
GraphQL può rendere il caching più complesso. Con REST il caching spesso si basa sull'URL. Con GraphQL molte query condividono lo stesso endpoint, quindi il caching dipende dalla forma della query, cache normalizzate e una configurazione attenta server/client.
Sul lato server ci sono trappole di prestazioni. Una query apparentemente piccola può scatenare molte chiamate backend a meno che non progetti i resolver con attenzione (batching, evitare pattern N+1 e controllare campi costosi).
C'è anche una curva di apprendimento: schemi, resolver e pattern client possono essere nuovi per i team abituati alle API basate su endpoint.
Poiché i client possono chiedere molto, le API GraphQL dovrebbero imporre limiti di profondità e complessità delle query per prevenire richieste abusive o accidentali troppo grandi.
Autenticazione e autorizzazione vanno applicate per campo, non solo a livello di rotta, dato che campi diversi possono avere regole di accesso diverse.
A livello operativo, investi in logging, tracing e monitoring che comprendano GraphQL: traccia nomi delle operazioni, variabili (con attenzione), tempi dei resolver e tassi di errore in modo da rilevare query lente e regressioni precocemente.
GraphQL e REST aiutano entrambe le app a parlare con i server, ma strutturano quella conversazione in modi molto diversi.
REST è basato sulle risorse. Recuperi dati chiamando endpoint diversi (URL) che rappresentano "cose" come /users/123 o /orders?userId=123. Ogni endpoint restituisce una forma di dati fissa decisa dal server.
REST si appoggia anche alle semantiche HTTP: metodi come GET/POST/PUT/DELETE, codici di stato e regole di caching. Questo rende REST naturale quando fai CRUD semplici o lavori strettamente con cache del browser/proxy.
GraphQL è basato sullo schema. Invece di molti endpoint, di solito hai un endpoint, e il client invia una query descrivendo i campi esatti che vuole. Il server valida la richiesta rispetto allo schema GraphQL e restituisce una risposta che corrisponde alla forma della query.
Questa "selezione guidata dal client" è il motivo per cui GraphQL può ridurre l'over-fetching e l'under-fetching, specialmente per schermate UI che necessitano dati da più modelli correlati.
REST è spesso la scelta migliore quando:
Molti team mescolano entrambi:
La domanda pratica non è “Qual è meglio?” ma “Qual è più adatto a questo caso d'uso con la minor complessità?”.
Progettare un'API GraphQL è più semplice se la tratti come un prodotto per chi costruisce schermate, non come uno specchio del tuo database. Parti in piccolo, convalida con casi d'uso reali ed espandi man mano che servono.
Elenca le schermate chiave (es. “Lista prodotti”, “Dettaglio prodotto”, “Checkout”). Per ogni schermata, annota i campi esatti di cui ha bisogno e le interazioni supportate.
Questo aiuta a evitare "query onnivore", riduce l'over-fetching e chiarisce dove servono filtraggio, ordinamento e paginazione.
Definisci prima i tipi core (es. User, Product, Order) e le loro relazioni. Poi aggiungi:
Preferisci nomi in linguaggio di business piuttosto che nomi legati al database. “placeOrder” comunica meglio l'intento rispetto a “createOrderRecord”.
Mantieni naming coerente: singolare per singoli elementi (product), plurale per collezioni (products). Per la paginazione, di solito scegli una delle due:
Anche a livello alto, decidi presto perché influenza la struttura della risposta dell'API.
GraphQL supporta descrizioni direttamente nello schema — usale per campi, argomenti e casi particolari. Poi aggiungi alcuni esempi copy-paste nella documentazione (inclusa la paginazione e scenari di errore comuni). Uno schema ben descritto rende introspezione ed esploratori API molto più utili.
Iniziare con GraphQL significa scegliere alcuni strumenti ben supportati e impostare un flusso di lavoro affidabile. Non devi adottare tutto subito — fai funzionare una query end-to-end, poi espandi.
Scegli un server in base allo stack e a quanto "batteries included" vuoi:
Un primo passo pratico: definisci un piccolo schema (un paio di tipi + una query), implementa i resolver e collega una sorgente dati reale (anche se è solo una lista in memoria).
Se vuoi muoverti più velocemente dall'idea a un'API funzionante, una piattaforma tipo Koder.ai può aiutarti a scaffoldare una piccola app full-stack (React frontend, Go + PostgreSQL backend) e iterare su schema/resolver via chat — poi esportare il codice quando sei pronto a gestirlo.
Sul frontend la scelta dipende spesso se preferisci convenzioni opinabili o flessibilità:
Se stai migrando da REST, comincia usando GraphQL per una schermata o feature e tieni REST per il resto finché l'approccio non dimostra il suo valore.
Tratta lo schema come un contratto API. Livelli utili di test includono:
Per approfondire, continua con:
GraphQL è un linguaggio di query e un runtime per API. I client inviano una query che descrive esattamente i campi di cui hanno bisogno e il server ritorna una risposta JSON che rispecchia quella struttura.
È meglio pensarlo come uno strato tra i client e una o più sorgenti di dati (database, servizi REST, API di terze parti, microservizi).
GraphQL aiuta principalmente con:
Permettendo al client di richiedere solo campi specifici (inclusi campi annidati), GraphQL può ridurre il trasferimento di dati non necessario e semplificare il codice client.
GraphQL non è:
Trattalo come un contratto API più un motore di esecuzione, non come una bacchetta magica per prestazioni o storage.
La maggior parte delle API GraphQL espone un endpoint singolo (spesso /graphql). Invece di avere più URL, invii operazioni diverse (query/mutation) allo stesso endpoint.
Implicazione pratica: caching e osservabilità si basano spesso su nome dell'operazione + variabili, non sull'URL.
Lo schema è il contratto dell'API. Definisce:
User, Post)User.name)User.posts)Essendo , il server può validare le query prima di eseguirle e restituire errori chiari quando i campi non esistono.
Le query GraphQL sono operazioni di lettura. Specifica i campi che ti servono e la risposta JSON rispecchia la struttura della query.
Consigli:
query GetUserWithPosts) per debug e monitoraggio.posts(limit: 2)).Le mutation sono operazioni di scrittura (create/update/delete). Uno schema comune è:
inputRestituire dati (non solo success: true) aiuta l'interfaccia a aggiornarsi subito e mantiene le cache coerenti.
I resolver sono funzioni a livello di campo che indicano come recuperare o calcolare ogni campo.
Nella pratica, i resolver possono:
L'autorizzazione viene spesso applicata nei resolver (o in middleware condivisi) perché sanno chi sta richiedendo e quali dati si stanno accedendo.
È facile creare un pattern N+1 (ad es. caricare i post separatamente per ciascuno di 100 utenti).
Mitigazioni comuni:
Misura i tempi dei resolver e controlla chiamate ripetute a servizi esterni durante una singola richiesta.
GraphQL può restituire dati parziali insieme a un array errors. Succede quando alcuni campi vengono risolti correttamente e altri no (es. campo proibito, timeout di un servizio downstream).
Buone pratiche:
message brevi e sicuri per l'utenteextensions.code stabili (es. FORBIDDEN, BAD_USER_INPUT)I client devono decidere quando mostrare dati parziali o trattare l'operazione come fallita.