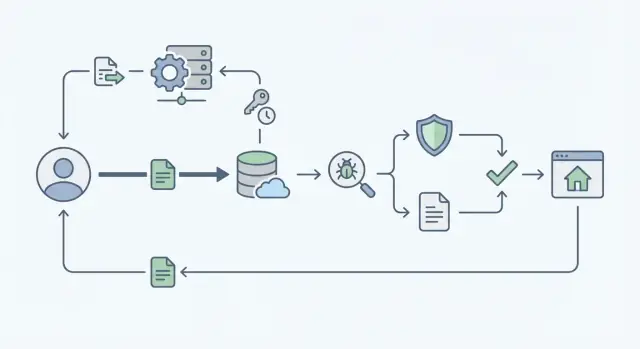
Cosa rende difficili i caricamenti a scala
I caricamenti di file sembrano semplici finché non arrivano gli utenti veri. Una persona carica una foto profilo. Poi diecimila persone caricano PDF, video e fogli di calcolo contemporaneamente. All'improvviso l'app rallenta, i costi di storage aumentano e i ticket di supporto si accumulano.
I casi di fallimento comuni sono prevedibili. Le pagine di upload si bloccano o si scadono quando il server cerca di gestire l'intero file invece di lasciare che sia l'object storage a fare il lavoro pesante. I permessi si degradano, così qualcuno indovina un URL di un oggetto e vede cose che non dovrebbe. Arrivano file “innocui” con malware, o con formati ingannevoli che mandano in crash gli strumenti a valle. E i log sono incompleti, quindi non riesci a rispondere a domande basilari come chi ha caricato cosa e quando.
Quello che vuoi invece è noioso e affidabile: upload veloci, regole chiare (tipi e dimensioni consentite) e una traccia di audit che rende gli incidenti facili da investigare.
Lo scambio più difficile è velocità vs sicurezza. Se esegui tutti i controlli prima che l'utente finisca, aspetta e ritenta, aumentando il carico. Se rimandi troppo i controlli, file non sicuri o non autorizzati possono propagarsi prima che tu li rilevi. Un approccio pratico è separare l'upload dai controlli e mantenere ogni passaggio rapido e misurabile.
Sii anche specifico su cosa intendi per “scala”. Scrivi i tuoi numeri: file al giorno, picco di upload al minuto, dimensione massima del file e dove si trovano i tuoi utenti. Le regioni contano per latenza e regole di privacy.
Se stai costruendo un'app su una piattaforma come Koder.ai, conviene decidere questi limiti presto, perché influenzano come progetti permessi, storage e workflow di scansione in background.
Un semplice modello di minacce per gli upload
Prima di scegliere gli strumenti, chiarisci cosa può andare storto. Un modello di minacce non deve essere un documento lungo. È una comprensione breve e condivisa di cosa devi prevenire, cosa puoi rilevare dopo e quali compromessi accetti.
Gli attaccanti di solito provano a infilarsi in punti prevedibili: il client (modificando i metadata o falsificando il MIME type), il bordo di rete (replay e abuso dei rate limit), lo storage (indovinando nomi di oggetti, sovrascrivendo), e il download/preview (attivando rendering rischiosi o rubando file tramite accessi condivisi).
Da lì, mappa le minacce a controlli semplici:
I file sovradimensionati sono l'abuso più semplice. Possono far salire i costi e rallentare gli utenti reali. Fermali presto con limiti in byte rigidi e rigetto rapido.
I tipi falsi di file vengono dopo. Un file chiamato invoice.pdf potrebbe essere qualcos'altro. Non fidarti delle estensioni o dei controlli UI. Verifica basandoti sui byte reali dopo l'upload.
Il malware è diverso. Di solito non puoi scansionare tutto prima che l'upload sia completo senza rendere l'esperienza dolorosa. Il pattern comune è rilevarlo in modo asincrono, mettere in quarantena gli elementi sospetti e bloccarne l'accesso fino a quando la scansione non è passata.
L'accesso non autorizzato è spesso il danno maggiore. Tratta ogni upload e ogni download come una decisione di autorizzazione. Un utente dovrebbe caricare solo in una posizione che possiede (o in cui ha il permesso di scrittura) e scaricare solo file che può vedere.
Per molte app, una solida policy v1 è:
- Applica dimensione massima e categorie consentite (immagini, PDF, ecc.)
- Verifica il tipo reale del file lato server dopo l'upload
- Scansiona in modo asincrono e metti in quarantena finché non è pulito
- Richiedi autorizzazione esplicita per upload e download
- Logga e genera alert sui fallimenti ripetuti (dimensione, tipo, auth)
Un'architettura pratica per upload che resta veloce
Il modo più veloce per gestire gli upload è tenere il server dell'app fuori dal “business dei bytes”. Invece di inviare ogni file attraverso il tuo backend, lascia che il client carichi direttamente su object storage usando un URL firmato a breve durata. Il backend si concentra su decisioni e registri, non sul trasferimento di gigabyte.
La divisione è semplice: il backend risponde “chi può caricare cosa e dove”, mentre lo storage riceve i dati del file. Questo rimuove un collo di bottiglia comune: i server che fanno lavoro doppio (auth più proxy del file) e finiscono la CPU, la memoria o la rete sotto carico.
I componenti minimi
Tieni un piccolo record di upload nel database (per esempio PostgreSQL) così ogni file ha un proprietario chiaro e un ciclo di vita definito. Crea questo record prima che l'upload inizi, poi aggiornalo man mano che gli eventi accadono.
I campi che pagano quasi sempre includono gli identificatori di owner e tenant/workspace, la chiave dell'oggetto nello storage, uno stato, la dimensione dichiarata e il MIME type, e un checksum che puoi verificare.
Pianifica gli stati di upload in anticipo
Tratta gli upload come una macchina a stati così i controlli di autorizzazione restano corretti anche quando avvengono retry.
Un set pratico di stati è:
- requested
- uploaded
- scanned
- approved
- rejected
Permetti al client di usare l'URL firmato solo dopo che il backend ha creato un record requested. Dopo che lo storage conferma l'upload, passalo a uploaded, avvia la scansione malware in background e espone il file solo quando è approved.
Passo dopo passo: upload con URL firmati senza colli di bottiglia
Si parte quando l'utente clicca Upload. L'app chiama il backend per iniziare un upload con dettagli di base come filename, dimensione prevista e uso previsto (avatar, fattura, allegato). Il backend verifica il permesso per quel target specifico, crea un record di upload e restituisce un URL firmato a breve durata.
L'URL firmato dovrebbe essere strettamente limitato. Idealmente permette un singolo upload per una chiave oggetto esatta, con scadenza breve e condizioni chiare (limite di dimensione, tipo di contenuto consentito, checksum opzionale).
Il browser carica direttamente nello storage usando quell'URL. Quando finisce, il browser richiama il backend per finalizzare. Alla finalizzazione, ricontrolla i permessi (gli utenti possono perdere accesso), e verifica cosa è effettivamente arrivato nello storage: dimensione, tipo di contenuto rilevato e checksum se lo usi. Rendi la finalize idempotente così i retry non creano duplicati.
Poi marca il record come uploaded e avvia la scansione in background (coda/job). L'interfaccia può mostrare “In elaborazione” mentre la scansione è in corso.
Validazione di tipo e dimensione di cui puoi fidarti
Quarantena i file fino all'approvazione
Configura job in background per la scansione e servi i file solo dopo l'approvazione.
Cosa validare e dove
Affidarsi all'estensione è il modo in cui invoice.pdf.exe finisce nel tuo bucket. Tratta la validazione come una serie ripetibile di controlli che avvengono in più punti.
Inizia con i limiti di dimensione. Inserisci la dimensione massima nella policy dell'URL firmato (o nelle condizioni del pre-signed POST) così lo storage può rifiutare upload sovradimensionati precocemente. Applica lo stesso limite quando il tuo backend registra i metadata, perché i client possono comunque cercare di aggirare l'interfaccia.
I controlli sul tipo dovrebbero basarsi sul contenuto, non sul nome del file. Ispeziona i primi byte del file (magic bytes) per confermare che corrispondono a quanto ti aspetti. Un vero PDF inizia con %PDF, e i PNG cominciano con una firma fissa. Se il contenuto non corrisponde alla tua allowlist, rifiutalo anche se l'estensione sembra corretta.
Mantieni le allowlist specifiche per ciascuna feature. Un upload di avatar potrebbe permettere solo JPEG e PNG. Una feature documenti potrebbe permettere PDF e DOCX. Questo riduce il rischio e rende le regole più facili da spiegare.
Checksum e nomi file
Non fidarti mai del filename originale come chiave di storage. Normalizzalo per la visualizzazione (rimuovi caratteri strani, tronca la lunghezza), ma memorizza una tua chiave oggetto sicura, come una UUID più un'estensione che assegni dopo la rilevazione del tipo.
Conserva un checksum (per esempio SHA-256) nel database e confrontalo più avanti durante l'elaborazione o la scansione. Questo aiuta a catturare corruzione, upload parziali o manomissioni, specialmente quando gli upload vengono ritentati sotto carico.
Scansione malware che non fa aspettare gli utenti
La scansione malware è importante, ma non dovrebbe stare nel percorso critico. Accetta l'upload rapidamente, poi tratta il file come bloccato finché non supera la scansione.
Il pattern asincrono
Crea un record di upload con uno stato come pending_scan. L'interfaccia può mostrare il file, ma non dovrebbe essere ancora utilizzabile.
La scansione viene tipicamente scatenata da un evento di storage quando l'oggetto è creato, pubblicando un job su una coda subito dopo il completamento dell'upload, o facendo entrambe le cose (coda più evento come backstop).
Il worker di scansione scarica o streamma l'oggetto, esegue gli scanner e poi scrive il risultato nel database. Conserva l'essenziale: stato della scansione, versione dello scanner, timestamp e chi ha richiesto l'upload. Quella traccia di audit semplifica molto il supporto quando qualcuno chiede “Perché il mio file è stato bloccato?”.
Cosa succede quando un file fallisce
Non lasciare i file falliti mescolati a quelli puliti. Scegli una policy e applicala in modo coerente: mettili in quarantena e rimuovi l'accesso, oppure cancellali se non servono per l'indagine.
Qualunque sia la scelta, mantieni la comunicazione con l'utente calma e specifica. Dì cosa è successo e cosa fare dopo (ri-caricare, contattare il supporto). Alert il team se molti fallimenti avvengono in breve tempo.
La cosa più importante è avere una regola rigorosa per download e anteprime: solo i file marcati approved possono essere serviti. Tutti gli altri devono restituire una risposta sicura come “Il file è ancora in fase di verifica.”
Controlli di autorizzazione che restano corretti sotto carico
Gli upload veloci sono ottimi, ma se la persona sbagliata può allegare un file al workspace sbagliato, hai un problema più grande delle richieste lente. La regola più semplice è anche la più forte: ogni record di file appartiene esattamente a un tenant (workspace/org/progetto) e ha un owner o creator chiaro.
Esegui i controlli di permesso due volte: quando emetti l'URL firmato per l'upload, e di nuovo quando qualcuno prova a scaricare o visualizzare il file. Il primo controllo ferma upload non autorizzati. Il secondo ti protegge se l'accesso viene revocato, un URL trapela o il ruolo di un utente cambia dopo l'upload.
Il principio del least privilege mantiene sia la sicurezza sia le prestazioni prevedibili. Invece di un unico permesso generico “files”, separa i ruoli in “può caricare”, “può visualizzare” e “può gestire (cancellare/condividere)”. Molte richieste diventano così semplici lookup (utente, tenant, azione) invece di logiche custom costose.
Per prevenire indovinamenti di ID, evita ID sequenziali nelle URL e nelle API. Usa identificatori opachi e mantieni le chiavi di storage non indovinabili. Gli URL firmati sono il trasporto, non il tuo sistema di permessi.
I file condivisi sono dove i sistemi spesso diventano lenti e disordinati. Tratta la condivisione come dati espliciti, non come accesso implicito. Un approccio semplice è un record di condivisione separato che concede a un utente o gruppo il permesso su un file, eventualmente con una scadenza.
Mantenere gli upload veloci man mano che aumentano traffico e dimensione file
Aggiungi validazione affidabile
Crea controlli di dimensione e tipo lato server con un backend Go e record PostgreSQL.
Quando si parla di scalare upload sicuri, spesso ci si concentra sui controlli di sicurezza e si dimenticano le basi: spostare bytes è la parte lenta. L'obiettivo è tenere il traffico di file grandi lontano dai server dell'app, mantenere i retry sotto controllo e evitare che i controlli di sicurezza diventino una coda senza limiti.
Rendi i file grandi prevedibili
Per file grandi, usa upload multipart o chunked così una connessione instabile non costringe l'utente a ricominciare da zero. I chunk aiutano anche a far rispettare limiti più chiari: dimensione totale massima, dimensione massima per chunk e tempo massimo per l'upload.
Imposta timeout e retry sul client in modo intenzionale. Alcuni retry aiutano gli utenti reali; retry illimitati possono far esplodere i costi, specialmente su reti mobili. Punta a timeout brevi per chunk, un piccolo numero di retry e una deadline rigida per l'intero upload.
Controlla lo step “create upload”
Gli URL firmati mantengono veloce il percorso dei dati pesanti, ma la richiesta che li crea resta un punto critico. Proteggilo così rimane reattivo:
- Rate-limit per “create upload” per utente e per IP
- Applica i limiti di dimensione prima di emettere l'URL firmato
- Mantieni una TTL breve così URL inutilizzati scadono velocemente
- Traccia gli upload in corso così un utente non ne può avviare centinaia contemporaneamente
- Usa chiavi di idempotenza così i refresh non creano upload duplicati
La latenza dipende anche dalla geografia. Mantieni app, storage e worker di scansione nella stessa regione quando possibile. Se ti servono hosting per paese per compliance, pianifica il routing presto così gli upload non rimbalzano tra continenti. Piattaforme che girano globalmente su AWS (come Koder.ai) possono posizionare i workload più vicino agli utenti quando la residenza dei dati è rilevante.
Infine, pianifica i download, non solo gli upload. Servi i file con URL firmati per il download e imposta regole di caching basate sul tipo di file e sul livello di privacy. Asset pubblici possono essere cacheati più a lungo; ricevute private dovrebbero avere URL a breve durata e controlli di autorizzazione.
Scenario d'esempio: fatture e ricevute in un'app multi-utente
Immagina una piccola app per aziende dove i dipendenti caricano fatture e foto di ricevute, e un manager le approva per il rimborso. Qui il design degli upload smette di essere accademico: hai molti utenti, immagini grandi e soldi veri in gioco.
Un buon flusso usa stati chiari così tutti sanno cosa succede e puoi automatizzare le parti noiose: il file atterra nello object storage e salvi un record legato a utente/workspace/expense; un job in background scansiona il file ed estrae metadata di base (come il vero MIME type); poi l'elemento viene approvato e diventa utilizzabile nei report, oppure viene rifiutato e bloccato.
Gli utenti hanno bisogno di feedback rapido e specifico. Se il file è troppo grande, mostra il limite e la dimensione corrente (per esempio: “File 18 MB. Max 10 MB.”). Se il tipo è sbagliato, indica cosa è permesso (“Carica un PDF, JPG o PNG”). Se la scansione fallisce, mantieni il messaggio calmo e azionabile (“Questo file potrebbe essere pericoloso. Carica una nuova copia.”).
I team di supporto hanno bisogno di una traccia che li aiuti a debuggare senza aprire il file: upload ID, user ID, workspace ID, timestamp per created/uploaded/scan started/scan finished, codici risultato (troppo grande, tipo non corrispondente, scansione fallita, permesso negato), più chiave di storage e checksum.
Ri-caricamenti e sostituzioni sono comuni. Trattali come nuovi upload, attaccali alla stessa spesa come una nuova versione, conserva la cronologia (chi l'ha sostituita e quando) e marca come attiva solo la versione più recente. Se stai costruendo questa app su Koder.ai, questo mappa pulitamente su una tabella uploads più una expense_attachments con un campo version.
Errori comuni e correzioni semplici
Distribuisci vicino agli utenti
Lancia in regioni AWS che soddisfano i requisiti di latenza e data residency.
La maggior parte dei bug negli upload non sono hack complicati. Sono scorciatoie che diventano rischi reali quando il traffico cresce.
I cinque errori che compaiono più spesso
- Fidarsi solo dei controlli client-side. Correzione: valida di nuovo sul server usando i byte reali (magic bytes) e applica i limiti di dimensione usando i metadata dello storage, non solo il report del browser.
- Rendere gli URL firmati a lunga durata. Correzione: mantienili brevi (minuti), monouso e vincolati a una chiave oggetto. Ruota le credenziali e logga ogni emissione.
- Permettere il download prima che la scansione finisca. Correzione: carica in una posizione di quarantena, scansiona in modo asincrono e promuovi o servi solo dopo un risultato pulito.
- Usare nomi o percorsi forniti dall'utente come chiavi di storage. Correzione: genera le tue chiavi oggetto (UUID) e conserva il filename originale come metadata per la visualizzazione.
- Saltare i controlli di permesso sul download. Correzione: tratta il download come una decisione separata e ricontrolla ownership, appartenenza al workspace e regole di condivisione ogni volta che generi un URL di download.
Correzioni facili che prevengono colli di bottiglia
Più controlli non devono rendere gli upload lenti. Separa il percorso veloce da quello pesante.
Esegui controlli rapidi in modo sincrono (auth, dimensione, tipo consentito, rate limit), poi delega scansione e ispezioni più profonde a worker in background. Gli utenti possono continuare a lavorare mentre il file passa da “uploaded” a “ready”. Se costruisci con un builder basato su chat come Koder.ai, mantieni la stessa mentalità: rendi l'endpoint di upload piccolo e rigoroso, e sposta scansione e post-processing in job.
Checklist rapida e prossimi passi
Prima di lanciare gli upload, definisci cosa significa “sufficientemente sicuro per la v1”. I team normalmente si mettono nei guai mescolando regole troppo rigide (che bloccano utenti reali) con regole mancanti (che invitano abusi). Parti piccolo, ma assicurati che ogni upload abbia un percorso chiaro da “ricevuto” a “consentito al download”.
Una checklist stretta pre-lancio:
- Applica un limite di dimensione rigido presto (prima che i costi di storage crescano)
- Usa una allowlist per i tipi di file, validata dal contenuto (magic bytes), non solo dal filename
- Blocca l'accesso in attesa della scansione: non servire file ad altri finché la scansione non è finita
- Richiedi controlli di autorizzazione al download ogni volta
- Conserva log di audit per upload, risultati di scansione e tentativi di download
Se ti serve una policy minima, mantienila semplice: limite di dimensione, allowlist ristretta, upload con URL firmati e “quarantena finché la scansione non passa”. Aggiungi funzionalità più gradevoli dopo (anteprime, più tipi, reprocessing in background) solo quando il percorso core è stabile.
Il monitoring è ciò che impedisce che “veloce” diventi “misteriosamente lento” man mano che cresci. Monitora il tasso di fallimento degli upload (client vs server/storage), il tasso di fallimento e la latenza delle scansioni, il tempo medio di upload per bucket di dimensione, i dinieghi di autorizzazione al download e i pattern di egress dello storage.
Esegui un piccolo test di carico con dimensioni realistiche dei file e reti reali (i dati mobili si comportano diversamente dal Wi‑Fi d'ufficio). Sistema timeout e retry prima del lancio.
Se stai implementando questo in Koder.ai (koder.ai), Planning Mode è un buon posto per mappare prima gli stati di upload e gli endpoint, poi generare backend e UI attorno a quel flusso. Snapshots e rollback possono anche aiutare quando tari i limiti o regoli le regole di scansione.