18 ago 2025·8 min
Soft delete vs hard delete: compromessi importanti nelle app reali
Soft delete vs hard delete: scopri i reali compromessi per analitica, supporto, cancellazioni in stile GDPR e complessità delle query, più pattern sicuri per il ripristino.
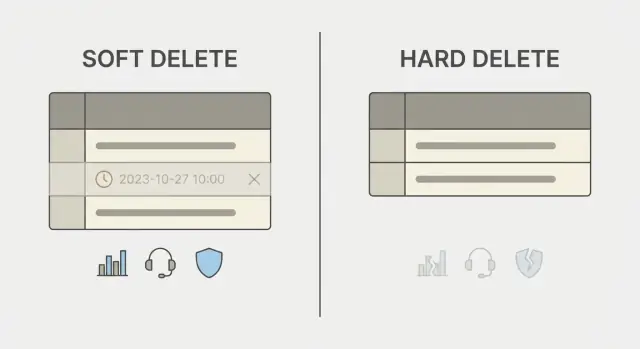
Cosa significano davvero soft delete e hard delete
Un pulsante di eliminazione può significare due cose molto diverse in un database.
Una cancellazione definitiva (hard delete) rimuove la riga. Dopo di ciò, il record è sparito a meno che tu non abbia backup, log o repliche che lo contengano ancora. È semplice da comprendere, ma è finale.
Una cancellazione logica (soft delete) mantiene la riga ma la marca come cancellata, di solito con un campo come deleted_at o is_deleted. L'app tratta le righe marcate come invisibili. Conservi i dati correlati, preservi la cronologia e talvolta puoi ripristinare il record.
Questa scelta compare nel lavoro quotidiano più di quanto si pensi. Influisce su come rispondi a domande come: “Perché il fatturato è diminuito il mese scorso?”, “Potete riportare indietro il mio progetto cancellato?” o “Abbiamo ricevuto una richiesta di cancellazione GDPR: stiamo davvero eliminando i dati personali?” Influisce anche su cosa significa “cancellato” nell'interfaccia utente. Gli utenti spesso presumono di poter annullare, finché non possono.
Una regola pratica:
- Usa la cancellazione logica quando gli utenti si aspettano un annulla, quando il supporto deve recuperare errori o quando ti serve una traccia di audit.
- Usa la cancellazione definitiva quando mantenere i dati crea un rischio legale, un rischio di sicurezza o costi di storage chiari senza valore reale.
- Usa entrambe quando vuoi un periodo di “cestino”: prima soft delete, poi purge permanente.
Esempio: un cliente elimina un workspace e poi si accorge che conteneva fatture necessarie per la contabilità. Con una cancellazione logica, il supporto può ripristinarlo (se l'app è costruita per gestire i restore in sicurezza). Con una cancellazione definitiva, probabilmente dovrai spiegare backup, ritardi o “non è possibile.”
Nessun approccio è universalmente “migliore”. L'opzione meno dolorosa dipende da cosa vuoi proteggere: fiducia dell'utente, accuratezza del reporting o conformità alla privacy.
Compromessi per l'analitica: accuratezza vs preservare la storia
La scelta di cancellare emerge subito nell'analitica. Il giorno in cui inizi a tracciare utenti attivi, conversioni o fatturato, “cancellato” smette di essere uno stato semplice e diventa una decisione di reporting.
Se fai hard delete, molte metriche appaiono pulite perché i record rimossi spariscono dalle query. Ma perdi contesto: abbonamenti passati, dimensione passata del team o com'era un funnel il mese scorso. Un cliente eliminato può spostare i grafici storici quando riesegui i report, il che è spaventoso per finance e growth.
Se fai soft delete, conservi la storia, ma puoi gonfiare i numeri accidentalmente. Un semplice “COUNT users” potrebbe includere persone che se ne sono andate. Un grafico di churn può contare doppio se tratti deleted_at come churn in un report e lo ignori in un altro. Anche il fatturato può diventare confuso se le fatture rimangono ma l'account è marcato come cancellato.
Quello che funziona è scegliere un pattern di reporting coerente e mantenerlo:
- Filtra i record cancellati nelle metriche di stato corrente (utenti attivi, MRR corrente).
- Usa tabelle snapshot per dashboard basate sul tempo così la storia non cambia quando entità vengono cancellate in seguito.
- Separa fatti ed entità: conserva righe di eventi immutabili (pagamenti, login) anche se nascondi il record utente.
- Tratta “cancellato” come uno stato del ciclo di vita con la sua data e riportalo esplicitamente (created, activated, deleted).
- Definisci finestre di retention: quando i dati soft-deleted diventano veramente rimossi.
La chiave è la documentazione così gli analisti non indovinano. Scrivi cosa significa “attivo”, se gli utenti soft-deleted sono inclusi e come viene attribuito il fatturato se un account viene cancellato in seguito.
Esempio concreto: un workspace è cancellato per errore e poi ripristinato. Se la tua dashboard conta i workspace senza filtri, mostrerai un calo e un rimbalzo improvvisi che non riflettono l'uso reale. Con snapshot, il grafico storico resta stabile mentre le viste prodotto possono continuare a nascondere i workspace cancellati.
Supporto e audit trail: cosa puoi recuperare dopo
La maggior parte dei ticket di supporto legati alle cancellazioni suonano simili: “L'ho cancellato per errore,” o “Dov'è il mio record?” La tua strategia di eliminazione decide se il supporto può rispondere in minuti o se la risposta onesta è “È andato.”
Con soft delete, di solito puoi verificare cosa è successo e annullare l'azione. Con hard delete, il supporto spesso deve fare affidamento sui backup (se esistono), e questo può essere lento, incompleto o impossibile per un singolo elemento. Ecco perché la scelta non è solo un dettaglio di database. Determina quanto il tuo prodotto può essere “di aiuto” dopo un problema.
Una semplice traccia di audit (cosa memorizzare)
Se prevedi supporto reale, aggiungi alcuni campi che spieghino gli eventi di cancellazione:
deleted_at(timestamp)deleted_by(user id o system)delete_reason(opzionale, testo breve)deleted_from_ipodeleted_from_device(opzionale)restored_aterestored_by(se supporti il restore)
Anche senza un registro completo delle attività, questi dettagli permettono al supporto di rispondere: chi l'ha cancellato, quando è successo e se è stato un errore o un'operazione automatica.
Cosa significano le hard delete per il supporto
Le cancellazioni definitive possono andar bene per dati temporanei, ma per i record visibili all'utente cambiano cosa può fare il supporto.
Il supporto non può ripristinare un singolo record a meno che tu non abbia costruito un cestino altrove. Potrebbero aver bisogno di un ripristino completo da backup, che può impattare altri dati. Non possono neanche dimostrare facilmente cosa è successo, il che porta a lunghe conversazioni avanti e indietro.
Le funzionalità di restore cambiano anche il carico di lavoro. Se gli utenti possono auto-ripristinare entro una finestra temporale, i ticket diminuiscono. Se il restore richiede l'intervento manuale del supporto, i ticket potrebbero aumentare, ma diventano rapidi e ripetibili invece di indagini sporadiche.
Cancellazione in stile GDPR: la soft delete non è una cancellazione completa
Il “diritto all'oblio” di solito significa che devi smettere di trattare i dati di una persona e rimuoverli dai luoghi dove sono ancora utilizzabili. Non sempre significa dover cancellare immediatamente ogni aggregato storico, ma significa che non dovresti tenere dati identificabili “nel caso” se non hai più una base legale per conservarli.
Qui la scelta tra soft delete e hard delete diventa più che una decisione di prodotto. Una soft delete (come impostare deleted_at) spesso nasconde il record dall'app. I dati sono ancora nel database, ancora interrogabili dagli admin e spesso presenti in esportazioni, indici di ricerca e tabelle analitiche. Per molte richieste di cancellazione GDPR, questo non è cancellazione.
Devi comunque prevedere un purge quando:
- Un utente richiede la cancellazione e non hai un motivo legale valido per conservarla (es. regole di fatturazione).
- Hai memorizzato categorie particolari di dati e la tua politica dice che devono essere rimossi.
- Il record appare in esportazioni rivolte agli utenti o può essere recuperato dal supporto.
- Un processore terzo (email, analytics, strumenti di supporto) lo conserva.
I backup e i log sono la parte che i team dimenticano. Potresti non riuscire a eliminare una singola riga da un backup cifrato, ma puoi definire una regola: i backup scadono in fretta e i backup ripristinati devono ri-applicare gli eventi di cancellazione prima che il sistema sia di nuovo operativo. I log dovrebbero evitare di memorizzare dati personali raw quando possibile e avere limiti di retention chiari.
Una politica pratica in due fasi è:
- Soft delete immediatamente (così il prodotto si comporta correttamente, gli account sono disabilitati e il “ripristino di record cancellati” può funzionare per errori).
- Avvia un timer di retention (per esempio, 7–30 giorni) e pianifica un job di purge che faccia hard-delete o anonimizzazione dei campi personali.
- Registra cosa è successo in una traccia di audit usando marker non identificativi (timestamp, codici motivo) così il supporto può spiegare le azioni senza conservare i dati.
Se la tua piattaforma supporta l'esportazione del codice sorgente o l'export dei dati, considera i file esportati come archivi di dati: definisci dove vivono, chi vi ha accesso e quando vengono eliminati.
Complessità delle query e comportamento del prodotto: il costo nascosto
Progetta la tua politica di cancellazione
Usa la modalità di pianificazione per definire regole di restore, purge e audit prima di costruire.
Le soft delete sembrano semplici: aggiungi deleted_at (o is_deleted) e nascondi la riga. Il costo nascosto è che ogni posto dove leggi i dati ora deve ricordare quel flag. Se lo dimentichi una volta, ottieni bug strani: totali che includono elementi cancellati, ricerca che mostra risultati “fantasma” o un utente che vede qualcosa che pensava fosse sparito.
Casi limite di UI e UX emergono velocemente. Immagina che un team cancelli un progetto chiamato “Roadmap” e più tardi provi a crearne uno nuovo con lo stesso nome. Se il database ha una regola di unicità sul nome, la creazione può fallire perché la riga cancellata esiste ancora. La ricerca può confondere le persone: se nascondi gli elementi cancellati nelle liste ma non nella ricerca globale, gli utenti penseranno che l'app sia rotta.
I filtri di soft delete vengono spesso dimenticati in:
- Dashboard amministrative e strumenti di supporto
- Job in background (email, promemoria, pulizie)
- Query e esportazioni analitiche
- Controlli di permessi (“esiste questo record?”)
- Autocomplete e ricerca
La performance è solitamente ok all'inizio, ma la condizione extra aggiunge lavoro. Se la maggior parte delle righe è attiva, filtrare deleted_at IS NULL è economico. Se molte righe sono cancellate, il DB deve saltare più righe a meno che tu non aggiunga l'indice giusto. In termini semplici: è come cercare documenti attuali in un cassetto che contiene anche molti vecchi documenti.
Un'area “Archivio” separata può ridurre la confusione. Mostra di default solo i record attivi e metti gli elementi cancellati in un posto con etichette chiare e una finestra temporale. In strumenti costruiti velocemente (per esempio, app interne fatte su Koder.ai), questa decisione di prodotto spesso previene più ticket di supporto di qualsiasi trucco di query.
Modelli di dati comuni per la soft delete
La soft delete non è una sola funzionalità. È una scelta di modello dati e il modello che scegli plasmerà tutto il resto: regole di query, comportamento di restore e cosa significa “cancellato” per il tuo prodotto.
Modello 1: deleted_at più deleted_by
Il pattern più comune è un timestamp nullable. Quando un record viene cancellato, imposti deleted_at (e spesso deleted_by con l'id dell'utente). I record “attivi” sono quelli con deleted_at a null.
Funziona bene quando ti serve un restore pulito: ripristinare è semplicemente azzerare deleted_at e deleted_by. Dà anche al supporto un segnale di audit semplice.
Modello 2: stati espliciti
Invece di un timestamp, alcuni team usano un campo status con stati chiari come active, archived e deleted. È utile quando “archived” è uno stato reale di prodotto (nascosto da molte schermate ma conteggiato per la fatturazione, per esempio).
Il costo è nelle regole. Devi definire cosa significa ogni stato ovunque: ricerca, notifiche, esportazioni e analitica.
Modello 3: storage separato per record di alto valore
Per oggetti sensibili o di alto valore, puoi spostare le righe cancellate in una tabella separata o registrare un evento in un log append-only.
- Soft delete con timestamp:
deleted_at,deleted_by - State machine:
statuscon stati nominati - Tabella separata per cancellati: la tabella “attiva” resta piccola
- Event log: conserva “chi ha fatto cosa” senza tenere le righe complete per sempre
Questo si usa spesso quando i restore devono essere strettamente controllati o quando vuoi una traccia di audit senza mischiare i dati cancellati nelle query quotidiane.
Anche i record figli hanno bisogno di una regola intenzionale. Se un workspace è cancellato, cosa succede a progetti, file e membership?
- Cascade: marca anche i figli come cancellati
- Restrict: blocca la cancellazione finché i figli non sono gestiti
- Archive: converti i figli in
archived(non cancellati) - Detach: rimuovi le relazioni ma conserva il figlio
Scegli una regola per ogni relazione, scrivila e mantienila coerente. La maggior parte dei bug “il restore è andato storto” deriva da genitori e figli che usano significati diversi di cancellato.
Come implementare una funzione di restore sicura (passo dopo passo)
Un pulsante di restore sembra semplice, ma può rompere permessi, riportare vecchi dati nel posto sbagliato o confondere gli utenti se “ripristinato” non significa ciò che si aspettano. Inizia scrivendo la promessa esatta che il tuo prodotto fa.
Un flusso di restore pratico
Usa una sequenza piccola e rigorosa così il restore è prevedibile e auditabile.
- Definisci cosa significa “restore”. Il record conserverà lo stesso ID? Tornerà allo stesso parent (workspace, project) e manterrà le stesse relazioni? Decidi cosa succede a membership, ruoli e visibilità.
- Fai confermare l'utente e cattura un motivo. Mostra cosa sarà ripristinato (nome, proprietario, data ultima modifica) e richiedi una conferma chiara. Per i team di supporto, un breve campo motivo (“cancellato per errore”, “chiusura ticket”) è spesso sufficiente.
- Controlla conflitti prima di cambiare nulla. Problemi comuni: il vecchio nome è stato riutilizzato, l'utente non ha più permessi o record correlati sono stati hard-deleted. Scegli una regola: blocca il restore con un messaggio chiaro oppure ripristina in uno stato “needs review”.
- Registra l'azione di restore. Memorizza chi ha ripristinato, quando, da dove (UI, API) e cosa è cambiato. Aiuta per audit e supporto, ed è essenziale quando qualcuno chiede “Perché è tornato?”
- Aggiungi un limite temporale quando serve. Molte app permettono restore per 30 o 90 giorni, poi richiedono un processo diverso o trattano la cancellazione come permanente.
Se costruisci app rapidamente in uno strumento guidato da chat come Koder.ai, mantieni questi controlli come parte del workflow generato così ogni schermata ed endpoint seguono le stesse regole.
Errori comuni e trappole da evitare
Audita le cancellazioni chiaramente
Aggiungi campi `deleted_at`, `deleted_by` e reason partendo da una specifica unica e chiara.
Il problema più grande con le soft delete non è la cancellazione in sé, ma tutti i posti che dimenticano che il record è “sparito”. Molti team scelgono soft delete per sicurezza, poi mostrano per errore elementi cancellati in risultati di ricerca, badge o totali. Gli utenti notano subito quando una dashboard dice “12 progetti” ma nella lista ne appaiono solo 11.
Un secondo problema è il controllo degli accessi. Se un utente, team o workspace è soft-deleted, non dovrebbe poter effettuare il login, chiamare l'API o ricevere notifiche. Questo spesso sfugge quando il controllo di login cerca per email, trova la riga e non verifica il flag di cancellazione.
Trappole comuni che generano ticket di supporto in seguito:
- Mancato filtro dei cancellati in una via di lettura (view admin, esportazioni, ricerca, job di background).
- Ripristinare record che collidono con campi unici (email, username, slug, numero fattura).
- Cancellare un genitore lasciando i figli “attivi” (o cancellare i figli mentre il genitore sembra ancora vivo).
- Contare righe cancellate in analitica, quote o calcoli di fatturazione.
- Inviare dati cancellati a terze parti perché integrazioni e job di sync non capiscono “deleted”.
Le collisioni di unicità sono particolarmente fastidiose durante il restore. Se qualcuno crea un nuovo account con la stessa email mentre il vecchio è soft-deleted, un restore o fallisce o sovrascrive l'identità sbagliata. Decidi la regola in anticipo: bloccare il riuso finché non c'è purge, permettere il riuso ma impedire il restore, o ripristinare con un nuovo identificatore.
Uno scenario comune: un agente del supporto ripristina un workspace soft-deleted. Il workspace ritorna, ma i membri rimangono cancellati e un'integrazione riprende a sincronizzare vecchi record in uno strumento partner. Dal punto di vista dell'utente, il restore “ha funzionato a metà” e ha creato confusione.
Prima di rilasciare il restore, rendi espliciti questi comportamenti:
- Cosa significa “cancellato” per login, accesso API e notifiche
- Come il restore gestisce campi unici e ownership
- Come i record correlati seguono il genitore (tutto-o-nulla evita sorprese)
- Come esportazioni e integrazioni trattano i dati cancellati (escludi, marca o invia tombstone)
Esempio realistico: un workspace cancellato per errore
Un team B2B SaaS ha un pulsante “Delete workspace”. Un venerdì un admin fa pulizia e rimuove 40 workspace che sembravano inattivi. Il lunedì tre clienti si lamentano che i loro progetti sono spariti e chiedono il ripristino immediato.
La squadra assumeva che la decisione sarebbe stata semplice. Non lo era.
Primo problema: il supporto non può ripristinare ciò che è stato veramente cancellato. Se la riga workspace è stata hard-deleted e la cancellazione ha cascato rimuovendo progetti, file e membership, l'unica opzione sono i backup. Questo significa tempo, rischi e una risposta imbarazzante al cliente.
Secondo problema: l'analitica sembra rotta. La dashboard conta “workspace attivi” interrogando solo righe con deleted_at IS NULL. La cancellazione accidentale mostra un calo improvviso nell'adozione. Peggio, un report settimanale confronta con la settimana scorsa e segnala un falso picco di churn. I dati non sono stati persi, ma sono stati esclusi nei posti sbagliati.
Terzo problema: arriva una richiesta di privacy per uno degli utenti coinvolti. Chiedono la cancellazione dei loro dati personali. Una pura soft delete non basta. Il team ha bisogno di un piano per fare purge dei campi personali (nome, email, log IP) mantenendo aggregate non personali come totali di fatturazione e numeri di fattura.
Quarto problema: tutti chiedono “Chi ha cliccato elimina?” Se non c'è traccia, il supporto non può spiegare cosa è successo.
Un pattern più sicuro è trattare la cancellazione come un evento con metadata chiari:
- Marca il workspace come cancellato (e nascondilo nel prodotto)
- Registra
deleted_by,deleted_ate un motivo o ID ticket - Logga cosa sarà interessato (numero di progetti, sedie, storage)
- Permetti il restore entro una finestra temporale, poi esegui purge selettivi dei campi personali quando necessario
Questo è il tipo di workflow che i team spesso costruiscono velocemente in piattaforme come Koder.ai, per poi rendersi conto che la politica di eliminazione richiede tanta progettazione quanto le funzionalità intorno ad essa.
Checklist rapida per scegliere la strategia di cancellazione giusta
Implementa un flusso di restore sicuro
Crea un cestino e controlli dei conflitti con un flusso di lavoro guidato a chat.
Scegliere tra cancellazione logica e definitiva riguarda meno la preferenza e più cosa la tua app deve garantire dopo che un record è “scomparso”. Fatti queste domande prima di scrivere la prima query.
- Hai bisogno di una vera cancellazione? Se devi rispettare richieste di privacy o legali, pianifica la rimozione reale (includendo backup ed esportazioni). Un flag di soft delete da solo non è sufficiente.
- Ti serve un pulsante di restore e per quanto tempo? Se l'annulla è importante, decidi la finestra di restore (7 giorni, 30 giorni, per sempre) e cosa succede dopo la scadenza.
- Il reporting avrà bisogno dei dati dopo la cancellazione? Alcuni team vogliono grafici che riflettano la vista corrente; altri necessitano di conteggi storici per finance o analisi. La scelta di delete cambia cosa significano “utenti attivi” e “fatturato totale”.
- Il supporto può spiegare cosa è successo senza indagini complesse? Se ti aspetti ticket come “il mio progetto è sparito”, ti serve una traccia chiara: chi ha cancellato, quando e da dove, più dati sufficienti per investigare.
- Il team può mantenere coerente il comportamento ovunque? Le soft delete spesso creano regole nascoste: ogni query deve filtrare i cancellati, ogni join deve comportarsi e ogni schermata deve concordare su cosa significa “cancellato”.
Un modo semplice per verificare la decisione è prendere un incidente realistico e seguirlo passo passo. Per esempio: qualcuno cancella un workspace per errore il venerdì sera. Il lunedì il supporto deve vedere l'evento di cancellazione, ripristinarlo in sicurezza ed evitare di far riemergere dati correlati che dovrebbero restare rimossi. Se stai costruendo un'app su una piattaforma come Koder.ai, definisci queste regole presto così il backend e l'UI generati seguano una sola policy invece di spargere eccezioni nel codice.
Passi successivi: scegli una politica e costruiscila in sicurezza
Scegli il tuo approccio scrivendo una politica semplice che puoi condividere con il team e il supporto. Se non è messa per iscritto, sarà soggetta a deriva e gli utenti sentiranno l'incoerenza.
Inizia con un insieme chiaro di regole:
- Cosa viene soft-deleted (e per quanto rimane ripristinabile)
- Cosa viene hard-deleted immediatamente (e perché)
- Quando i dati soft-deleted vengono purgati (per esempio dopo X giorni)
- Chi può ripristinare e quale prova o approvazione è richiesta
- Come vengono gestite end-to-end le richieste di cancellazione per privacy
Poi costruisci due percorsi distinti che non si mescolino: un percorso “restore amministrativo” per errori e un percorso “purge per privacy” per la cancellazione definitiva. Il percorso di restore dovrebbe essere reversibile e logged. Il percorso di purge dovrebbe essere finale e rimuovere o anonimizzare tutti i dati correlati che possono identificare una persona, inclusi backup o esportazioni se la tua politica lo richiede.
Aggiungi guardrail così i dati cancellati non ritornino nel prodotto. Il modo più semplice è trattare “cancellato” come uno stato di prima classe nei test. Aggiungi checkpoint di revisione per ogni nuova query, pagina di lista, ricerca, esportazione e job analitico. Una buona regola è: se una schermata mostra dati rivolti all'utente, deve avere una decisione esplicita sui record cancellati (nascondi, mostra con etichetta o solo admin).
Se sei nelle prime fasi di prodotto, prototipa entrambi i flussi prima di stabilire lo schema. In Koder.ai puoi schizzare la politica di cancellazione in modalità pianificazione, generare il CRUD di base e provare rapidamente scenari di restore e purge, poi aggiustare il modello dati prima di confermare.