23 अक्टू॰ 2025·6 मिनट
सर्वर-साइड बनाम क्लाइंट-साइड फिल्टरिंग: निर्णय चेकलिस्ट
डेटा साइज, लेटेंसी, परमिशन और कैशिंग के आधार पर सर्वर-साइड बनाम क्लाइंट-साइड फिल्टरिंग चुनने के लिए चेकलिस्ट — बिना UI लीक या लैग के।
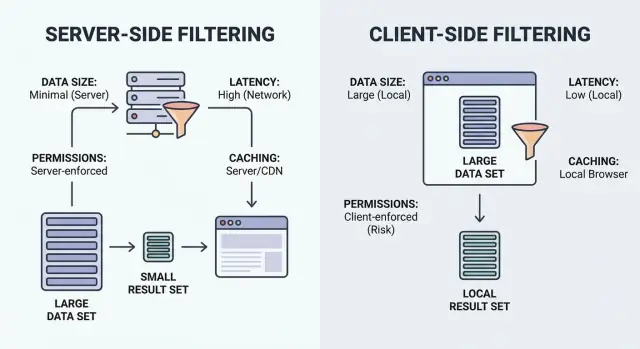
डेटा साइज, लेटेंसी, परमिशन और कैशिंग के आधार पर सर्वर-साइड बनाम क्लाइंट-साइड फिल्टरिंग चुनने के लिए चेकलिस्ट — बिना UI लीक या लैग के।
UI में फिल्टरिंग सिर्फ एक सिंगल सर्च बॉक्स से ज़्यादा है। इसमें आमतौर पर कुछ संबंधित क्रियाएँ होती हैं जो उपयोगकर्ता को दिखने वाला डेटा बदलती हैं: टेक्स्ट सर्च (नाम, ईमेल, ऑर्डर ID), फेसेट्स (status, owner, date range, tags), और सॉर्टिंग (नवीनतम, उच्चतम मूल्य, आख़िरी गतिविधि)।
मुख्य सवाल यह नहीं है कि कौन सी तकनीक "बेहतर" है। प्रश्न यह है कि पूरा डेटासेट कहाँ रहता है, और किसे उसे एक्सेस करने की अनुमति है। अगर ब्राउज़र को ऐसे रिकॉर्ड मिलते हैं जो उपयोगकर्ता को नहीं दिखने चाहिए, तो UI संवेदनशील डेटा उजागर कर सकती है—even अगर आप उसे विज़ुअली छिपाते हों।
सर्वर-साइड बनाम क्लाइंट-साइड फिल्टरिंग पर ज़्यादातर बहसें वास्तव में दो ऐसी विफलताओं पर प्रतिक्रियाएं हैं जिन्हें उपयोगकर्ता तुरंत नोटिस करते हैं:
तीसरी समस्या जो अनंत बग रिपोर्ट बनाती है: असंगत परिणाम। अगर कुछ फिल्टर्स क्लाइंट पर चलते हैं और कुछ सर्वर पर, तो उपयोगकर्ता काउंट्स, पेज और टोटल्स जो मैच नहीं करते देखते हैं। यह विश्वास जल्दी तोड़ देता है, खासकर पेजिनेटेड लिस्ट्स में।
एक व्यावहारिक डिफ़ॉल्ट सरल है: अगर उपयोगकर्ता को पूरा डेटासेट एक्सेस करने की अनुमति नहीं है, तो सर्वर पर फ़िल्टर करें। अगर अनुमति है और डेटासेट छोटा है और जल्दी लोड हो सकता है, तो क्लाइंट फ़िल्टरिंग ठीक हो सकती है।
फिल्टरिंग बस "वो आइटम दिखाओ जो मैच करते हैं" है। मुख्य सवाल यह है कि मैचिंग कहाँ होती है: उपयोगकर्ता के ब्राउज़र (क्लाइंट) में या आपके बैकएंड (सर्वर) पर।
क्लाइंट-साइड फिल्टरिंग ब्राउज़र में चलती है। ऐप रिकॉर्ड्स का एक सेट (अक्सर JSON) डाउनलोड करता है, फिर फिल्टर्स लोकल रूप से लागू करता है। डेटा लोड होने के बाद यह तुरंत महसूस हो सकती है, पर यह तभी काम करती है जब डेटासेट पर्याप्त छोटा हो और एक्सपोज़ करना सुरक्षित हो।
सर्वर-साइड फिल्टरिंग आपके बैकएंड पर चलती है। ब्राउज़र फिल्टर इनपुट भेजता है (जैसे status=open, owner=me, createdAfter=Jan 1), और सर्वर केवल मिलते हुए रिज़ल्ट्स लौटाता है। व्यवहार में, यह आमतौर पर एक API एंडपॉइंट होता है जो फिल्टर्स स्वीकार करता है, डेटाबेस क्वेरी बनाता है, और पेजिनेटेड लिस्ट प्लस टोटल्स लौटाता है।
एक सरल मानसिक मॉडल:
हाइब्रिड सेटअप आम हैं। एक अच्छा पैटर्न है कि “बड़े” फिल्टर्स सर्वर पर लागू हों (परमिशन, ओनरशिप, डेट रेंज, सर्च), और छोटे UI-ओनली टॉगल लोकली रखें (आर्काइव्ड आइटम छिपाना, क्विक टैग चिप्स, कॉलम विजिबिलिटी) बिना अतिरिक्त रिक्वेस्ट के।
सॉर्टिंग, पेजिनेशन और सर्च आमतौर पर उसी निर्णय में आते हैं। वे पेलोड साइज, उपयोगकर्ता का अनुभव, और आप कौन सा डेटा एक्सपोज़ कर रहे हैं को प्रभावित करते हैं।
सबसे व्यावहारिक सवाल से शुरू करें: अगर आप क्लाइंट पर फ़िल्टर करेंगे तो आप ब्राउज़र को कितना डेटा भेजेंगे? अगर ईमानदार जवाब “कई स्क्रीन से ज़्यादा” है, तो आप डाउनलोड टाइम, मेमोरी उपयोग, और धीमे इंटरैक्शन्स का भुगतान करेंगे।
आपको परफ़ेक्ट अनुमान नहीं चाहिए। बस आर्डर ऑफ़ मैग्निट्यूड पता करें: उपयोगकर्ता कितनी पंक्तियाँ देख सकता है, और हर पंक्ति का औसत साइज क्या है? 500 आइटम की सूची जिसमें कुछ छोटे फ़ील्ड हों बहुत अलग है बनाम 50,000 आइटम जहाँ हर पंक्ति में लंबा नोट, रिच टेक्स्ट, या नेस्टेड ऑब्जेक्ट्स हों।
वाइड रिकॉर्ड्स चुपचाप पेलोड का किलर होते हैं। एक टेबल रो काउंट से छोटी लग सकती है पर फिर भी भारी हो सकती है अगर हर रो में कई फ़ील्ड, बड़े स्ट्रिंग्स, या जोइन किए गए डेटा हों (contact + company + last activity + full address + tags)। अक्सर टीमें केवल तीन कॉलम दिखाने के बावजूद “सब कुछ, हो सकता है काम आए” भेज देती हैं और पेलोड फूल जाता है।
वृद्धि के बारे में भी सोचें। आज जो ठीक है, कुछ महीनों में दर्दनाक हो सकता है। यदि डेटा तेज़ी से बढ़ता है, तो क्लाइंट-साइड फिल्टरिंग को शॉर्ट‑टर्म शॉर्टकट मानें, डिफ़ॉल्ट नहीं।
नियम का अंदाज़:
यह आख़िरी बात परफ़ॉर्मेंस से ज़्यादा सुरक्षा के लिए मायने रखती है। “क्या हम पूरा डेटासेट ब्राउज़र को भेज सकते हैं?” यह भी एक सुरक्षा प्रश्न है। अगर उत्तर निश्चित 'हाँ' नहीं है, तो भेजें मत।
फ़िल्टरिंग विकल्प अक्सर सटीकता पर नहीं, अनुभव पर फेल होते हैं। उपयोगकर्ता मिलीसेकेंड नहीं मापते। वे पाज़, फ्लिकर, और टाइप करते हुए नाचते हुए परिणाम नोटिस करते हैं।
समय विभिन्न स्थानों पर गायब हो सकता है:
इस स्क्रीन के लिए “पर्याप्त तेज़” का मतलब परिभाषित करें। एक लिस्ट व्यू में टाइपिंग रिस्पॉन्सिव और स्मूद स्क्रॉलिंग चाहिए, जबकि एक रिपोर्ट पेज छोटा वेइट सहन कर सकता है बशर्ते पहला रिज़ल्ट जल्दी आ जाए।
केवल ऑफिस Wi‑Fi पर जज मत करें। स्लो कनेक्शनों पर, क्लाइंट‑साइड फिल्टरिंग पहले लोड के बाद शानदार लग सकती है, पर वही पहला लोड धीमा हो सकता है। सर्वर‑साइड फिल्टरिंग पेलोड्स को छोटा रखती है, पर अगर आप हर कीस्ट्रोक पर रिक्वेस्ट फायर करेंगे तो यह लैगी महसूस हो सकती है।
मानव इनपुट के आसपास डिजाइन करें। टाइपिंग के दौरान रिक्वेस्ट को डिबाउंस करें। बड़े रिज़ल्ट सेट्स के लिए प्रोग्रेसिव लोडिंग का उपयोग करें ताकि पेज कुछ जल्दी दिखाए और उपयोगकर्ता स्क्रॉल करते हुए स्मूद अनुभव रखें।
परमिशन को आपकी फ़िल्टरिंग अप्रोच से ज़्यादा महत्व देना चाहिए बजाए केवल स्पीड के। अगर ब्राउज़र कभी भी ऐसा डेटा प्राप्त करता है जिसे उपयोगकर्ता नहीं देख सकता, तो आप पहले ही समस्या में हैं, भले ही आप इसे डिसेबल्ड बटन के पीछे या कोलैप्स्ड कॉलम में छिपा दें।
शुरूआत स्क्रीन पर जो संवेदनशील है उसे नाम देकर करें। कुछ फ़ील्ड स्पष्ट हैं (ईमेल, फोन नंबर, पते)। कुछ आसानी से ओवरलुक हो जाते हैं: इंटरनल नोट्स, लागत या मार्जिन, स्पेशल प्राइसिंग नियम, रिस्क स्कोर, मोडरेशन फ्लैग।
बड़ी ट्रैप यह है: “हम क्लाइंट पर फिल्टर करते हैं, पर केवल अनुमति वाली पंक्तियाँ दिखाते हैं।” इसका मतलब यह है कि पूरा डेटासेट डाउनलोड हुआ। कोई भी नेटवर्क रिस्पॉन्स देख सकता है, डिव टूल खोल सकता है, या पेलोड सेव कर सकता है। UI में कॉलम छिपाना एक्सेस कंट्रोल नहीं है।
जब ऑथोराइज़ेशन उपयोगकर्ता के अनुसार बदलता है, खासकर जब अलग‑अलग उपयोगकर्ता अलग पंक्तियाँ या फ़ील्ड देख सकते हैं, तो सर्वर‑साइड फिल्टरिंग सुरक्षित डिफ़ॉल्ट है।
त्वरित जांच:
अगर किसी भी सवाल का जवाब हाँ है, तो सर्वर पर फिल्टर और फील्ड सिलेक्शन रखें। केवल वो भेजें जो उपयोगकर्ता देख सकता है, और वही नियम सर्च, सॉर्ट, पेजिनेशन और एक्सपोर्ट पर भी लागू करें।
उदाहरण: एक CRM कॉन्टैक्ट लिस्ट में, रिप्स केवल अपने अकाउंट देख पाते हैं जबकि मैनेजर्स सभी देख सकते हैं। अगर ब्राउज़र सभी कॉन्टैक्ट डाउनलोड कर के लोकली फिल्टर करे, तो एक रिप छिपे हुए अकाउंट्स को रिस्पॉन्स से रिकवर कर सकता है। सर्वर‑साइड फिल्टरिंग इससे रोकती है क्योंकि वे पंक्तियाँ कभी भेजी ही नहीं जातीं।
कॅशिंग स्क्रीन को तुरंत महसूस करा सकती है। यह गलत सत्य भी दिखा सकती है। कुंजी यह है कि आप क्या पुन: उपयोग कर सकते हैं, कितनी देर के लिए, और कौन‑से इवेंट्स उसे वाइप कर देंगे।
सबसे पहले कैश यूनिट चुनें। पूरी लिस्ट कैश करना सरल है पर अक्सर बैंडविड्थ बर्बाद करता है और जल्दी स्टेल हो जाता है। पेज कैश करना इनफिनिट स्क्रॉल के लिए अच्छा है। क्वेरी रिज़ल्ट्स (फिल्टर + सॉर्ट + सर्च) कैश करना सटीक है, पर अगर उपयोगकर्ता कई संयोजन आज़माते हैं तो कैश जल्दी बढ़ सकता है।
ताज़गी कुछ डोमेन में ज़्यादा मायने रखती है। अगर डेटा तेज़ी से बदलता है (स्टॉक लेवल, बैलेंस, डिलिवरी स्टेटस), तो 30‑सेकंड का भी कैश उपयोगकर्ताओं को भ्रमित कर सकता है। अगर डेटा धीरे‑धीरे बदलता है (आर्काइव्ड रिकॉर्ड, रेफरेंस डेटा), तो लंबे कैश ठीक रहते हैं।
कोड करने से पहले इनवैलिडेशन की योजना बनाएं। समय के अलावा, तय करें क्या फिर से ताज़ा होना चाहिए: क्रिएट/एडिट/डिलीट, परमिशन बदलना, बल्क इम्पोर्ट या मर्ज, स्टेटस ट्रांज़िशन, अनडू/रोलबैक, और बैकग्राउंड जॉब्स जो वे फ़ील्ड अपडेट करते हैं जिन पर उपयोगकर्ता फिल्टर करते हैं।
यह भी तय करें कि कैश कहाँ रहेगा। ब्राउज़र मेमोरी बैक/फॉरवर्ड नेविगेशन को तेज बनाती है, पर यह अकाउंट्स के बीच डेटा लीक कर सकती है अगर आप इसे user और org के हिसाब से की नहीं करते। बैकएंड कैशिंग परमिशन और सुसंगति के लिए सुरक्षित है, पर इसमें पूरा फिल्टर सिग्नेचर और कॉलर आइडेंटिटी शामिल होनी चाहिए ताकि परिणाम मिक्स न हों।
लक्ष्य को गैर‑वार्तीय मानें: स्क्रीन तेज़ लगनी चाहिए बिना डेटा लीक के।
अधिकांश टीमें उन्हीं पैटर्न से काट खाती हैं: एक UI जो डेमो में शानदार दिखता है, पर असली डेटा, असली परमिशन, और असली नेटवर्क स्पीड उसे उजागर कर देते हैं।
सबसे गंभीर विफलता यह है कि फिल्टरिंग को केवल प्रस्तुति समझ लिया जाए। अगर ब्राउज़र को रिकॉर्ड मिल गए जो उसे नहीं मिलने चाहिए थे, तो आप हार चुके हैं।
दो सामान्य कारण:
उदाहरण: इंटर्न्स को केवल अपने रीजन के लीड्स दिखने चाहिए। अगर API सभी रीजन लौटा दे और ड्रॉपडाउन React में लोकली फिल्टर करे, तो इंटर्न पूरा लिस्ट निकाल सकता है।
लैग अक्सर धाराओं से आता है:
एक सूक्ष्म पर दर्दनाक समस्या है नियमों का मेल न बैठना। अगर सर्वर "starts with" अलग तरीके से हैं बनाम UI, तो उपयोगकर्ता काउंट्स देखेंगे जो मैच नहीं करते, या आइटम रिफ्रेश के बाद गायब हो सकते हैं।
दो मानसिकताओं के साथ आख़िरी पास करें: एक जिज्ञासु उपयोगकर्ता और एक खराब नेटवर्क दिन।
एक साधारण टेस्ट: एक प्रतिबंधित रिकॉर्ड बनाएं और पुष्टि करें कि वह कभी भी पेलोड, काउंट या कैश में नहीं दिखता, भले ही आप चौड़ा फिल्टर करें या फिल्टर्स क्लियर करें।
सोचिए एक CRM में 200,000 कॉन्टैक्ट्स हैं। सेल्स रिप्स केवल अपने अकाउंट देख सकते हैं, मैनेजर्स अपनी टीम देख सकते हैं, और एडमिन्स सब कुछ देख सकते हैं। स्क्रीन में सर्च, फिल्टर्स (status, owner, last activity), और सॉर्टिंग है।
यहाँ क्लाइंट‑साइड फिल्टरिंग जल्दी फेल हो जाती है। पेलोड भारी है, पहला लोड धीमा हो जाता है, और डेटा लीक का जोखिम अधिक है। भले ही UI पंक्तियों को छिपाए, ब्राउज़र ने फिर भी डेटा प्राप्त किया होता है। आप डिवाइस पर भी दबाव डालते हैं: बड़े एरेज़, भारी सॉर्टिंग, बार‑बार फिल्टर रन, उच्च मेमोरी उपयोग, और पुराने फोन पर क्रैश।
एक सुरक्षित अप्रोच सर्वर‑साइड फिल्टरिंग है साथ में पेजिनेशन। क्लाइंट फिल्टर विकल्प और सर्च टेक्स्ट भेजता है, और सर्वर केवल उन्हीं पंक्तियों को लौटाता है जिन्हें उपयोगकर्ता देखने के लिए अधिकृत है, पहले से फ़िल्टर और सॉर्ट किया हुआ।
एक व्यावहारिक पैटर्न:
एक छोटा अपवाद जहाँ क्लाइंट‑साइड फिल्टरिंग ठीक है: छोटा, स्टैटिक डेटा। “Contact status” के लिए 8 मानों वाला ड्रॉपडाउन एक बार लोड किया जा सकता है और लोकली फिल्टर किया जा सकता है बिना रिस्क के।
टीमें आमतौर पर एक बार “गलत” विकल्प चुनने से नहीं जला करतीं। वे तब जलते हैं जब हर स्क्रीन पर अलग चुनाव करते हैं, फिर दबाव में लीक और धीमी पेजेज़ को ठीक करने की कोशिश करते हैं।
हर स्क्रीन के लिए एक छोटा निर्णय नोट लिखें जिसमें फिल्टर्स: डेटासेट साइज, भेजने की लागत, क्या "पर्याप्त तेज़" लगता है, कौन से फ़ील्ड संवेदनशील हैं, और परिणामों को कैसे कैश/न करें। सर्वर और UI को अलाइन रखें ताकि फिल्टरिंग के दो सत्य न बनें।
अगर आप Koder.ai (koder.ai) में तेजी से स्क्रीन बना रहे हैं, तो पहले तय कर लें कि कौन से फिल्टर्स बैकएंड पर लागू होने चाहिए (परमिशन और रो‑लेवल एक्सेस) और कौन से छोटे UI‑ओनली टॉगल React लेयर में रह सकते हैं। यही एक निर्णय सबसे महँगे री‑राइट्स को रोकता है।
डिफ़ॉल्ट रूप से सर्वर-साइड चुनें जब उपयोगकर्ताओं की अनुमति अलग-अलग हो, डेटासेट बड़ा हो, या आप सुसंगत पेजिनेशन और टोटल की परवाह कर रहे हों। केवल तब क्लाइंट-साइड का इस्तेमाल करें जब पूरा डेटासेट छोटा, सुरक्षित और तेज़ी से डाउनलोड करने के लिए उपयुक्त हो।
क्योंकि ब्राउज़र को जो कुछ भी मिलता है उसे देखा और एक्सेस किया जा सकता है। भले ही UI पंक्तियों या कॉलमों को छिपा दे, कोई भी नेटवर्क रिस्पॉन्स, कैश्ड पेलोड या इन‑मेमोरी ऑब्जेक्ट्स देखकर डेटा निकाल सकता है।
यह आमतौर पर तब होता है जब आप बहुत सारा डेटा भेजते हैं और फिर हर कीस्ट्रोक पर बड़े एरेज़ को फ़िल्टर/सॉर्ट करते हैं, या जब आप हर कीस्ट्रोक पर सर्वर रिक्वेस्ट फायर कर देते हैं बिना डिबाउंस के। पेलोड्स को छोटा रखें और हर इनपुट बदलाव पर भारी काम करने से बचें।
“रियल” फिल्टर्स के लिए एक ही स्रोत रखें: परमिशन, सर्च, सॉर्टिंग और पेजिनेशन को साथ में सर्वर पर लागू करें। फिर क्लाइंट-साइड लॉजिक को केवल छोटे UI-टॉगल तक सीमित रखें जो मूल डेटासेट को नहीं बदलते।
क्लाइंट-साइड कैशिंग स्टाले या गलत डेटा दिखा सकती है, और यदि कैश की-में यूज़र आइडेंटिटी शामिल नहीं है तो यह अकाउंट्स के बीच लीक कर सकती है। सर्वर-साइड कैशिंग परमिशन के लिए सुरक्षित है, पर कैश की-में पूरा फिल्टर सिग्नेचर और कॉलर आइडेंटिटी शामिल होना चाहिए।
दो प्रश्न पूछें: एक उपयोगकर्ता के पास व्यावहारिक रूप से कितनी पंक्तियाँ हो सकती हैं, और हर पंक्ति कितने बाइट की है। यदि आप इसे सामान्य मोबाइल कनेक्शन पर आराम से लोड नहीं कर पाएँगे, या पुराने डिवाइस पर यह धीमा होगा, तो फिल्टरिंग सर्वर पर करें और पेजिनेट करें।
सर्वर-साइड। यदि भूमिकाएँ, टीमें, क्षेत्र, या अधिग्रहण नियम यह बदलते हैं कि कोई किसे देख सकता है, तो सर्वर को रो और फील्ड एक्सेस लागू करना चाहिए। क्लाइंट को केवल वही रिकॉर्ड और फील्ड भेजें जिन्हें उपयोगकर्ता देख सकता है।
सबसे पहले फ़िल्टर और सॉर्ट कॉन्ट्रैक्ट परिभाषित करें: स्वीकार्य फिल्टर फील्ड, डिफ़ॉल्ट सॉर्टिंग, पेजिनेशन नियम, और सर्च किस तरह मिलती है (कैस, एक्सेंट्स, पार्टियल मैच)। फिर वही लॉजिक लगातार बैकएंड पर लागू करें और टेस्ट करें कि टोटल्स और पेज मेल खाते हैं।
टाइपिंग पर डिबाउंस करें ताकि आप हर कीस्ट्रोक पर रिक्वेस्ट न भेजें, और नए परिणामों के आने तक पुराने परिणाम दिखाये रखें ताकि फ्लिकर कम हो। पेजिनेशन या प्रोग्रेसिव लोडिंग का उपयोग करें ताकि उपयोगकर्ता कुछ जल्दी देख सके बिना बड़े रिस्पॉन्स के ब्लॉक होने के।
पहले परमिशन लागू करें, फिर फिल्टर्स और सॉर्ट। केवल एक पेज और एक टोटल काउंट वापस करें। “जस्ट इन केस” के लिए अतिरिक्त फील्ड न भेजें, और कैश कीज़ में user/org/role शामिल करें ताकि किसी रेप को मैनेजर के लिए वाला डेटा न मिले।
पहले यह तय करें कि स्क्रीन तेज़ लगे और डेटा लीक न हो। स्क्रीन के लिए एक शॉर्ट डिसीजन नोट लिखें: डेटासेट साइज, भेजने की लागत, क्या “पर्याप्त तेज़” है, कौन से फील्ड संवेदनशील हैं, और रिजल्ट्स को कैसे कैश/इनवैलिडेट किया जाएगा। सर्वर और UI को अलाइन रखें ताकि फिल्टरिंग के “दो सत्य” न बने।