30 दिस॰ 2025·8 मिनट
React में Optimistic UI अपडेट्स: त्वरित अनुभव, बिना डेटा ड्रिफ्ट के
React में Optimistic UI अपडेट्स ऐप को तुरंत महसूस कराते हैं। सीखें कैसे सुरक्षित पैटर्न से सर्वर ट्रुथ reconcile करें, फेल्यर्स हैंडल करें और डेटा ड्रिफ्ट रोकें।
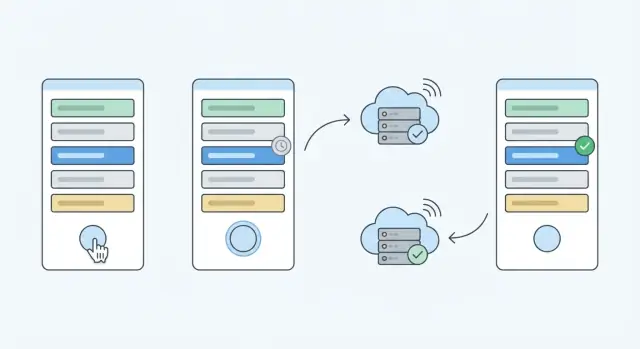
React में Optimistic UI अपडेट्स ऐप को तुरंत महसूस कराते हैं। सीखें कैसे सुरक्षित पैटर्न से सर्वर ट्रुथ reconcile करें, फेल्यर्स हैंडल करें और डेटा ड्रिफ्ट रोकें।
React में Optimistic UI का मतलब है कि आप स्क्रीन को ऐसे अपडेट करते हैं मानो चेंज पहले ही सफल हो गया हो, सर्वर की पुष्टि से पहले। कोई "Like" क्लिक करता है, काउंट तुरंत बढ़ जाता है, और अनुरोध बैकग्राउंड में चलता रहता है।
यह तुरंत फ़ीडबैक ऐप को त्वरित बनाता है। धीमे नेटवर्क पर अक्सर यही फर्क होता है "snappy" और "क्या यह काम हुआ?" के बीच।
ट्रेडऑफ है डेटा ड्रिफ्ट: जो यूज़र देखता है वह धीरे-धीरे सर्वर की सच्चाई से अलग होने लग सकता है। ड्रिफ्ट आमतौर पर छोटे, निराशाजनक असंगतियों के रूप में दिखता है जो टाइमिंग पर निर्भर होते हैं और दोहराना मुश्किल होता है।
यूज़र्स तब ड्रिफ्ट नोटिस करते हैं जब चीज़ें बाद में “अपना मन बदलती” लगें: काउंटर कूदता है और फिर वापस आ जाता है, कोई आइटम दिखाई देता है और रिफ्रेश पर गायब हो जाता है, कोई एडिट तब तक टिकी रहती है जब तक आप पेज पर वापस नहीं जाते, या दो टैब अलग वैल्यू दिखाते हैं।
यह इसलिए होता है क्योंकि UI एक अनुमान लगा रहा है, और सर्वर अलग सच्चाई बता सकता है। वैलिडेशन नियम, डुपिंग हटाना, permission चेक, रेट लिमिट, या कोई दूसरा डिवाइस उसी रिकॉर्ड को बदलना—ये सब अंतिम परिणाम बदल सकते हैं। एक और सामान्य कारण ओवरलैपिंग रिक्वेस्ट्स हैं: एक पुराना रिस्पॉन्स आखिरी में आकर यूज़र की नई क्रिया को ओवरराइट कर देता है।
उदाहरण: आप किसी प्रोजेक्ट का नाम "Q1 Plan" कर देते हैं और उसे हेडर में तुरंत दिखाते हैं। सर्वर whitespace ट्रिम कर सकता है, कैरेक्टर रिजेक्ट कर सकता है, या slug जेनरेट कर सकता है। यदि आप ऑप्टिमिस्टिक वैल्यू को सर्वर की फाइनल वैल्यू से कभी बदलते नहीं हैं, तो UI सही दिखता है जब तक अगला रिफ्रेश न हो, तब वह "रहस्यमयी" तरीके से बदल सकता है।
Optimistic UI हमेशा सही विकल्प नहीं होता। पैसों और बिलिंग के लिए, अपरिवर्तनीय कार्रवाइयों, रोल और permission बदलने के मामलों, जटिल सर्वर नियमों वाले वर्कफ़्लो, या किसी भी चीज़ के लिए जहाँ यूज़र को स्पष्ट पुष्टि की ज़रूरत है—यहाँ सतर्क रहें (या इससे बचें)।
अच्छी तरह उपयोग किया जाए तो ऑप्टिमिस्टिक अपडेट्स ऐप को तुरंत महसूस करवाते हैं, पर केवल तब जब आप reconciliation, ordering, और failure handling की योजना बनाएं।
Optimistic UI तब सबसे अच्छा काम करता है जब आप दो प्रकार की स्टेट को अलग करते हैं:
अधिकांश ड्रिफ्ट तब शुरू होती है जब एक लोकल अनुमान को कन्फर्म्ड सच माना जाता है।
एक सरल नियम: यदि किसी वैल्यू का व्यावसायिक मतलब वर्तमान स्क्रीन के बाहर है, तो सर्वर source of truth है। अगर यह केवल स्क्रीन के व्यवहार को प्रभावित करता है (खुला/बंद, फोकस्ड इनपुट, ड्राफ्ट टेक्स्ट), तो इसे लोकल रखें।
व्यवहार में, सर्वर सच्चाई उन चीज़ों के लिए रखें जैसे permissions, कीमतें, बैलेंस, इन्वेंट्री, कम्प्यूटेड या वे फ़ील्ड जो वेलिडेट होते हैं, और कोई भी चीज़ जो कहीं और बदल सकती है (दूसरी टैब, दूसरा उपयोगकर्ता)। लोकल UI स्टेट रखें ड्राफ्ट्स, "is editing" फ्लैग, अस्थायी फ़िल्टर, एक्सपैंडेड रो, और एनीमेशन टॉगल्स के लिए।
कुछ कार्रवाइयां "सुरक्षित अनुमान" होती हैं क्योंकि सर्वर उन्हें लगभग हमेशा स्वीकार कर देता है और उन्हें उलटना आसान होता है, जैसे किसी आइटम को स्टार करना या एक साधारण प्राथमिकता टॉगल करना।
जब कोई फ़ील्ड अनुमान लगाने के लिए सुरक्षित नहीं है, तब भी आप बिना यह दिखाए कि परिवर्तन फाइनल है, ऐप को तेज़ महसूस करा सकते हैं। आख़िरी कन्फर्म्ड वैल्यू रखें, और एक स्पष्ट pending संकेत जोड़ें।
उदाहरण के लिए, CRM स्क्रीन पर जहाँ आप "Mark as paid" क्लिक करते हैं, सर्वर इसे रिजेक्ट कर सकता है (permissions, validation, पहले से रिफंड)। हर व्युत्पन्न नंबर को तुरंत नहीं बदलने के बजाय, स्टेटस को एक सूक्ष्म "Saving..." लेबल के साथ अपडेट करें, टोटल्स को अपरिवर्तित रखें, और केवल पुष्टि के बाद टोटल्स अपडेट करें।
अच्छे पैटर्न सरल और सुसंगत होते हैं: बदले आइटम के पास एक छोटा "Saving..." बैज, क्रिया को अस्थायी रूप से अक्षम करना (या उसे Undo में बदलना) जब तक अनुरोध settle न हो, या ऑप्टिमिस्टिक वैल्यू को अस्थायी के रूप में विज़ुअली चिह्नित करना (हल्का टेक्स्ट या छोटा स्पिनर)।
यदि सर्वर रिस्पॉन्स कई जगहों को प्रभावित कर सकता है (टोटल्स, सॉर्टिंग, कम्प्यूटेड फ़ील्ड्स, permissions), तो पूर्ण refetch आमतौर पर सुरक्षित होता है बजाय कि सब कुछ पैच करने की कोशिश करने के। यदि यह छोटा, अलग बदलाव है (नोट का नाम बदलना, एक फ़्लैग टॉगल करना), तो लोकल पैच अक्सर ठीक रहता है।
एक उपयोगी नियम: जो चीज़ उपयोगकर्ता ने बदली उसे पैच करें, फिर किसी भी डेटा को refetch करें जो व्युत्पन्न, aggregate, या स्क्रीन-ओवर-शेयर किया गया है।
Optimistic UI तब काम करता है जब आपका डेटा मॉडल यह ट्रैक करे कि क्या कन्फर्म्ड है और क्या अभी भी अनुमान है। यदि आप उस गैप को स्पष्ट रूप से मॉडल करते हैं, तो "यह क्यों वापस आ गया?" जैसे पल दुर्लभ हो जाते हैं।
नए बनाए गए आइटम्स के लिए एक अस्थायी क्लाइंट ID असाइन करें (जैसे temp_12345 या UUID), फिर जब रिस्पॉन्स आये तो उसे असली सर्वर ID से स्वैप कर दें। इससे लिस्ट्स, चयन, और एडिटिंग स्टेट साफ़ तरीके से reconcile होते हैं।
उदाहरण: उपयोगकर्ता एक टास्क जोड़ता है। आप इसे तुरंत id: "temp_a1" के साथ रेंडर करते हैं। जब सर्वर id: 981 के साथ उत्तर देता है, तो आप ID को एक जगह बदल देते हैं, और जो कुछ भी ID द्वारा की किया गया है वह काम करता रहता है।
एकल स्क्रीन-लेवल लोडिंग फ्लैग बहुत मोटा है। स्टेटस को उस आइटम (या यहां तक कि उस फ़ील्ड) पर ट्रैक करें जो बदल रहा है। इस तरह आप सूक्ष्म pending UI दिखा सकते हैं, केवल विफल हिस्सों को रीट्राई कर सकते हैं, और unrelated कार्रवाईयों को ब्लॉक करने से बच सकते हैं।
एक व्यावहारिक आइटम शेप:
id: रीयल या अस्थायीstatus: pending | confirmed | failedoptimisticPatch: आपने लोकली क्या बदला (छोटा और विशिष्ट)serverValue: आख़िरी कन्फर्म्ड डेटा (या confirmedAt टाइमस्टैम्प)rollbackSnapshot: पिछली कन्फर्म्ड वैल्यू जिसे आप वापस कर सकते हैंऑप्टिमिस्टिक अपडेट्स तब सबसे सुरक्षित होते हैं जब आप केवल वही छूते हैं जो उपयोगकर्ता ने बदला (उदा., completed को टॉगल करना) बजाय पूरे ऑब्जेक्ट को अनुमानित "नए वर्जन" से बदलने के। पूरे ऑब्जेक्ट रिप्लेसमेंट से नए एडिट्स, सर्वर-जोड़े गए फ़ील्ड, या समवर्ती परिवर्तनों को मिटाना आसान हो जाता है।
एक अच्छा ऑप्टिमिस्टिक अपडेट तुरंत महसूस होता है, परन्तु अंत में सर्वर से मिलकर मेल खाता है। ऑप्टिमिस्टिक परिवर्तन को अस्थायी समझें, और उसे सुरक्षित रूप से कन्फर्म या undo करने के लिए पर्याप्त बुककीपिंग रखें।
उदाहरण: उपयोगकर्ता सूची में किसी टास्क का शीर्षक संपादित करता है। आप चाहते हैं कि शीर्षक तुरंत अपडेट हो, पर आपको validation errors और सर्वर-साइड formatting भी संभालनी होगी।
ऑप्टिमिस्टिक परिवर्तन तुरंत लोकल स्टेट में लागू करें। revert के लिए एक छोटा पैच (या snapshot) रखें।
अनुरोध भेजें एक request ID के साथ (इंक्रीमेंटिंग नंबर या रैंडम ID)। इसी से आप रिस्पॉन्स को उस क्रिया से मैच कर पाएंगे जिसने उसे ट्रिगर किया था।
आइटम को pending के रूप में मार्क करें। Pending UI को ब्लॉक करना ज़रूरी नहीं है—यह एक छोटा स्पिनर, फीका टेक्स्ट, या "Saving..." हो सकता है। महत्वपूर्ण बात यह है कि उपयोगकर्ता समझे कि यह अभी कन्फर्म नहीं हुआ।
सफल होने पर अस्थायी क्लाइंट डेटा को सर्वर वर्जन से बदल दें। यदि सर्वर ने कुछ एडजस्ट किया (whitespace ट्रिम, केसिंग बदली, timestamps अपडेट), तो लोकल स्टेट को मैच कर दें।
विफलता पर, केवल उसी चीज़ को revert करें जिसे इस अनुरोध ने बदला और एक स्पष्ट लोकल एरर दिखाएँ। unrelated स्क्रीन हिस्सों को rollback करने से बचें।
यहाँ एक छोटा, लाइब्रेरी-एगोनिस्टिक शेप आप फॉलो कर सकते हैं:
const requestId = crypto.randomUUID();
applyOptimistic({ id, title: nextTitle, pending: requestId });
try {
const serverItem = await api.updateTask({ id, title: nextTitle, requestId });
confirmSuccess({ id, requestId, serverItem });
} catch (err) {
rollback({ id, requestId });
showError("Could not save. Your change was undone.");
}
दो बातें जो कई बग रोकती हैं: आइटम पर जब यह pending हो तो request ID स्टोर करें, और केवल तब ही confirm या rollback करें जब IDs मैच करें। इससे पुरानी रिस्पॉन्सेज़ नई एडिट्स को ओवरराइट नहीं कर पातीं।
Optimistic UI तब टूटता है जब नेटवर्क का उत्तर रॉर-आर्डर में आता है। एक क्लासिक फेलियर: उपयोगकर्ता शीर्षक एडिट करता है, तुरंत फिर से एडिट करता है, और पहला अनुरोध आख़िर में फिनिश हो जाता है। अगर आप उस लेट रिस्पॉन्स को लागू करते हैं, तो UI पुराने वैल्यू पर झपक जाता है।
फिक्स यह है कि हर रिस्पॉन्स को "शायद प्रासंगिक" समझें और केवल तब लागू करें जब वह नवीनतम यूज़र इरादे से मेल खाती हो।
एक व्यावहारिक पैटर्न क्लाइंट request ID (एक काउंटर) है जिसे हर ऑप्टिमिस्टिक परिवर्तन के साथ जोड़ा जाता है। आइटम के लिए latest ID स्टोर करें। जब रिस्पॉन्स आये, तो IDs की तुलना करें। यदि रिस्पॉन्स पुराने हैं तो उन्हें अनदेखा करें।
वर्शन चेक्स भी मदद करते हैं। यदि आपका सर्वर updatedAt, version, या etag लौटाता है, तब केवल उन्हीं रिस्पॉन्सेज़ को स्वीकार करें जो UI से नए हों।
आप इन विकल्पों को मिला कर भी इस्तेमाल कर सकते हैं:
उदाहरण (request ID गार्ड):
let nextId = 1;
const latestByItem = new Map();
async function saveTitle(itemId, title) {
const requestId = nextId++;
latestByItem.set(itemId, requestId);
// optimistic update
setItems(prev => prev.map(i => i.id === itemId ? { ...i, title } : i));
const res = await api.updateItem(itemId, { title, requestId });
// ignore stale response
if (latestByItem.get(itemId) !== requestId) return;
// reconcile with server truth
setItems(prev => prev.map(i => i.id === itemId ? { ...i, ...res.item } : i));
}
यदि उपयोगकर्ता तेजी से टाइप कर सकते हैं (नोट्स, टाइटल्स, सर्च), तो बचेंस सेवेस को cancel करने या सेव को तब तक देर करने पर विचार करें जब तक वे टाइपिंग रोक नहीं देते। यह सर्वर लोड कम करता है और लेट रिस्पॉन्सेज़ से झपकने की संभावना घटाता है।
विफलताएँ वह जगह हैं जहाँ ऑप्टिमिस्टिक UI भरोसा खो देता है। सबसे खराब अनुभव अचानक रोलबैक है जिसके कोई स्पष्टीकरण नहीं होता।
एडिट्स के लिए एक अच्छा डिफ़ॉल्ट: उपयोगकर्ता का वैल्यू स्क्रीन पर रखें, उसे "not saved" के रूप में चिह्नित करें, और जहाँ उन्होंने एडिट किया वहां एक inline error दिखाएँ। यदि कोई प्रोजेक्ट नाम "Alpha" से "Q1 Launch" में बदला, तो उसे "Alpha" पर वापस मत झपकाइए जब तक ज़रूरी न हो। "Q1 Launch" रखें, जोड़ें "Not saved. Name already taken," और उन्हें सही करने दें।
इनलाइन फ़ीडबैक ठीक उसी फ़ील्ड या रो के साथ जुड़ा रहता है जिसने फेल किया। यह उस पल से बचाता है जहाँ एक टोस्ट दिखता है पर UI चुपचाप वापस बदल जाता है।
भरोसेमंद संकेतों में शामिल हैं: इन-फ़्लाइट के दौरान "Saving...", विफलता पर "Not saved", प्रभावित रो पर हल्का हाइलाइट, और एक छोटी संदेश जो उपयोगकर्ता को आगे क्या करना चाहिए बताती हो।
Retry लगभग हमेशा मददगार है। Undo तेज़ कार्रवाइयों के लिए अच्छा है जिन्हें कोई पछता सकता है (जैसे archive), पर एडिट्स के लिए यह भ्रमित कर सकता है जहाँ उपयोगकर्ता स्पष्ट रूप से नई वैल्यू चाहता है।
जब कोई म्यूटेशन फेल हो:
यदि आपको रोलबैक करना ही है (उदा., permission बदल गया और उपयोगकर्ता एडिट नहीं कर सकता), तो कारण बताएं और सर्वर ट्रुथ बहाल करें: "Couldn’t save. You no longer have access to edit this." जैसा संदेश दें।
सर्वर रिस्पॉन्स को केवल success flag न समझें—इसे रसीद की तरह ट्रीट करें। अनुरोध पूरा होने के बाद reconcile करें: उपयोगकर्ता का मतलब रखें, और वह स्वीकार करें जो सर्वर बेहतर जानता है।
पूर्ण refetch तब सबसे सुरक्षित है जब सर्वर ने आपके लोकल अनुमान से अधिक चीज़ बदली हो सकती है। यह सोचना भी आसान बनाता है।
यदि म्यूटेशन कई रिकॉर्ड्स को प्रभावित करता है (आइटम्स को सूचियों के बीच मूव करना), जब permissions या वर्कफ़्लो नियम परिणाम बदल सकते हैं, जब सर्वर आंशिक डेटा लौटाता है, या जब अन्य क्लाइंट्स अक्सर उसी व्यू को अपडेट करते हैं—तो refetch बेहतर होता है।
यदि सर्वर अपडेटेड एंटिटी (या पर्याप्त फ़ील्ड) लौटाता है, तो merging बेहतर अनुभव दे सकता है: UI स्थिर रहती है जबकि सर्वर ट्रुथ स्वीकार की जाती है।
ड्रिफ्ट अक्सर सर्वर-ओन्ड फ़ील्ड्स को ऑप्टिमिस्टिक ऑब्जेक्ट से ओवरराइट करने से आता है। सोचिए काउंटर, कम्प्यूटेड वैल्यूज़, timestamps, और नार्मलाइज़्ड फ़ॉर्मैटिंग।
उदाहरण: आप ऑप्टिमिस्टिकली likedByMe=true सेट कर देते हैं और likeCount बढ़ा देते हैं। सर्वर डुप्लिकेट-लाइक्स को हटाकर अलग likeCount लौटा सकता है, साथ में refreshed updatedAt भी।
एक सरल मर्ज अप्रोच:
जब कॉन्फ्लिक्ट हो, तो पहले से निर्णय लें। "Last write wins" टॉगल्स के लिए ठीक है। फॉर्म्स के लिए फ़ील्ड-लेवल मर्ज बेहतर है।
प्रति-फ़ील्ड "dirty since request" फ्लैग (या लोकल वर्ज़न नंबर) यह बताने देता है कि सर्वर वैल्यूज़ को उन फ़ील्ड्स के लिए इग्नोर करें जिन्हें उपयोगकर्ता ने म्यूटेशन शुरू होने के बाद बदला, जबकि बाकी सर्वर ट्रुथ स्वीकार करें।
यदि सर्वर म्यूटेशन रिजेक्ट करता है, तो जोर दें कि सटीक, हल्के एरर्स दें बजाय अचानक रोलबैक के। उपयोगकर्ता की इनपुट को रखें, फ़ील्ड हाइलाइट करें, और मैसेज दिखाएँ। सेव रोलबैक उन मामलों के लिए रखें जहाँ एक्शन वास्तव में टिका नहीं सकता (उदा., आपने ऑप्टिमिस्टिकली कोई आइटम हटाया जिसे सर्वर ने डिलीट करना अस्वीकार कर दिया)।
लिस्ट्स वह जगह हैं जहाँ ऑप्टिमिस्टिक UI शानदार लगता है पर टूटना भी आसान है। एक आइटम का बदलना ordering, totals, filters, और कई पेजों को प्रभावित कर सकता है।
क्रिएट्स के लिए, नया आइटम तुरंत दिखाएँ पर उसे pending चिह्नित करें और अस्थायी ID दें। उसकी पोजीशन स्थिर रखें ताकि वह कूदे नहीं।
डिलीट्स के लिए, सुरक्षित पैटर्न है आइटम को तुरंत छुपा देना पर मेमोरी में एक short-lived "ghost" रिकॉर्ड रखना जब तक सर्वर पुष्टि न करे। इससे undo समर्थित होता है और फेल्यर्स हैंडल करना आसान होता है।
रीऑर्डरिंग जटिल है क्योंकि यह कई आइटम्स को छूता है। यदि आप ऑप्टिमिस्टिकली रीयोर्डर करते हैं, तो पिछला क्रम स्टोर करें ताकि ज़रूरत पड़ने पर आप उसे restore कर सकें।
पेजिनेशन या infinite scroll में, तय करें कि ऑप्टिमिस्टिक इनसर्ट्स कहाँ जाएँ। फीड्स में नए आइटम अक्सर टॉप पर जाते हैं। सर्वर-रैंक्ड कैटलॉग्स में लोकल इनसर्शन भ्रम पैदा कर सकती है क्योंकि सर्वर आइटम कहीं और रख सकता है। एक व्यावहारिक समझौता यह है कि विज़िबल लिस्ट में आइटम डालें और उसे pending बैज दें, फिर सर्वर रिस्पॉन्स पर उसे मूव करने के लिए तैयार रहें यदि फाइनल सॉर्ट की वैल्यू अलग हो।
जब अस्थायी ID असली ID बन जाती है, तो स्थिर की द्वारा डेड्यूप करें। यदि आप केवल ID से मैच करते हैं, तो आप एक ही आइटम दो बार दिखा सकते हैं (temp और confirmed)। एक tempId-to-realId मैप रखें और inplace रिप्लेस करें ताकि स्क्रॉल पोजीशन और चयन रिसेट न हो।
काउंट्स और फ़िल्टर्स भी लिस्ट स्टेट हैं। केवल तभी ऑप्टिमिस्टिकली काउंट अपडेट करें जब आप सुनिश्चित हों कि सर्वर सहमत होगा; अन्यथा उन्हें refreshing चिह्नित करें और रिस्पॉन्स के बाद reconcile करें।
ज्यादातर ऑप्टिमिस्टिक-अपडेट बग्स वास्तव में React के बारे में नहीं होते। वे तब आते हैं जब ऑप्टिमिस्टिक परिवर्तन को "नई सच्चाई" मान लिया जाता है, बजाय कि अस्थायी अनुमान के।
जब आप केवल एक फ़ील्ड बदला हो पर पूरे ऑब्जेक्ट या स्क्रीन को ऑप्टिमिस्टिकली अपडेट कर देते हैं तो blast radius बढ़ जाता है। बाद में सर्वर corrections unrelated एडिट्स को ओवरराइट कर सकते हैं।
उदाहरण: एक प्रोफ़ाइल फॉर्म पूरा user ऑब्जेक्ट को बदलता है जब आप एक सेटिंग टॉगल करते हैं। अनुरोध इन-फ्लाइट होने पर उपयोगकर्ता अपना नाम एडिट करता है। जब रिस्पॉन्स आता है, आपका रिप्लेस पुराने नाम को वापस रख सकता है।
ऑप्टिमिस्टिक पैच छोटे और फोकस्ड रखें।
एक और ड्रिफ्ट स्रोत है pending फ्लैग्स को सफल या त्रुटि के बाद साफ़ न करना। UI आधे-लोडिंग की तरह रहती है, और बाद की लॉजिक उसे अभी भी ऑप्टिमिस्टिक मान सकती है।
यदि आप pending स्टेट को आइटम-स्तर पर ट्रैक करते हैं, तो उसे उसी key से साफ़ करें जिससे आपने उसे सेट किया था। अस्थायी IDs अक्सर "घोस्ट pending" आइटम्स का कारण बनते हैं जब असली ID हर जगह मैप नहीं होती।
Rollback बग्स तब होते हैं जब स्नैपशॉट बहुत देर से स्टोर किया गया हो या बहुत व्यापक स्कोप में लिया गया हो।
यदि उपयोगकर्ता ने दो जल्दी एडिट किए, तो आप edit #2 को edit #1 से पहले वाला स्नैपशॉट प्रयोग करके rollback कर सकते हैं। UI उस स्थिति पर कूद सकती है जिसे उपयोगकर्ता ने कभी नहीं देखा।
सुधार: जिस स्लीस को आप restore करेंगे उसका ठीक-ठीक स्नैपशॉट लें, और उसे एक विशिष्ट म्यूटेशन प्रयास के साथ स्कोप करें (अक्सर request ID का उपयोग करके)।
वास्तविक सेव्स अक्सर मल्टी-स्टेप होते हैं। यदि step 2 फेल हो (उदा., इमेज अपलोड), तो step 1 को चुपचाप undo न करें। जो सेव हुआ उसे दिखाएँ, जो नहीं हुआ उसे बताएं, और उपयोगकर्ता को आगे क्या करना है बताएं।
साथ ही, यह न मानें कि सर्वर वही echo करेगा जो आपने भेजा। सर्वर टेक्स्ट को सामान्यीकृत कर सकता है, permissions लागू कर सकता है, timestamps सेट कर सकता है, IDs असाइन कर सकता है, और फ़ील्ड ड्रॉप कर सकता है। हमेशा रिस्पॉन्स (या refetch) से reconcile करें बजाय कि ऑप्टिमिस्टिक पैच पर हमेशा भरोसा करने के।
Optimistic UI तभी काम करती है जब यह predictable हो। हर ऑप्टिमिस्टिक परिवर्तन को एक छोटे ट्रांज़ैक्शन की तरह ट्रीट करें: इसका एक ID हो, एक विज़िबल pending स्टेट हो, एक स्पष्ट success swap हो, और एक failure पाथ हो जो लोगों को हैरान न करे।
शिप करने से पहले रिव्यू करने के लिए चेकलिस्ट:
यदि आप जल्दी प्रोटोटाइप बना रहे हैं, तो पहली वर्ज़न छोटा रखें: एक स्क्रीन, एक म्यूटेशन, एक लिस्ट अपडेट। Koder.ai (koder.ai) जैसी टूल्स UI और API को तेज़ी से स्केच करने में मदद कर सकती हैं, पर वही नियम लागू होते हैं: pending बनाम confirmed स्टेट मॉडल करें ताकि क्लाइंट कभी यह भूल न जाए कि सर्वर ने वास्तव में क्या स्वीकार किया।
Optimistic UI स्क्रीन को तुरंत अपडेट करता है, सर्वर की पुष्टि से पहले। यह ऐप को पल भर में लगने में मदद करता है, पर UI को सर्वर रिस्पॉन्स के साथ reconcile करना जरूरी है ताकि UI वास्तविक सेव्ड स्टेट से हट न जाए।
डेटा ड्रिफ्ट तब होता है जब UI ने जो अनुमान लगाया उसे पक्का मान लिया जाता है, जबकि सर्वर ने कुछ अलग सेव किया या बदलाव को रिजेक्ट कर दिया। यह अक्सर रिफ्रेश पर, दूसरी टैब में, या धीमी नेटवर्क के कारण रिस्पॉन्स के आउट-ऑफ-ऑर्डर आने पर दिखता है।
पैसे, बिलिंग, अपरिवर्तनीय कार्रवाइयां, permission बदलाव और भारी सर्वर-रूल्स वाले वर्कफ़्लो के लिए ऑप्टिमिस्टिक अपडेट से बचें या बहुत सतर्क रहें। इन केसों में बेहतर है कि स्पष्ट pending स्टेट दिखाएँ और कन्फर्मेशन तक महत्त्वपूर्ण बदलाव न करें।
जो कुछ भी वर्तमान स्क्रीन से बाहर व्यावसायिक मायने रखता है—जैसे कीमतें, permissions, कम्प्यूटेड फ़ील्ड, साझा काउंटर—उनके लिए बैकएंड को स्रोत-ओफ़-ट्रूथ मानें। ड्राफ्ट, focus, “is editing”, फ़िल्टर्स और अन्य केवल प्रस्तुतिकरण वाले स्टेट लोकल रखें।
बदलाव हुए जगह के पास ही एक छोटा, लगातार सिग्नल दिखाएँ, जैसे “Saving…”, फीका टेक्स्ट, या सूक्ष्म स्पिनर। उद्देश्य है कि उपयोगकर्ता समझे कि यह मान अस्थायी है बिना पूरे पेज को ब्लॉक किए।
जब आप आइटम बनाते हैं तो क्लाइंट-साइड अस्थायी ID (जैसे UUID या temp_...) दें और सफलता पर उसे सर्वर ID से बदल दें। इससे लिस्ट की कीज़, चयन और एडिटिंग स्टेट स्थिर रहती है और आइटम झपकता या डुप्लिकेट नहीं होता।
ग्लोबल लोडिंग फ्लैग का उपयोग न करें; हर आइटम (या फ़ील्ड) पर pending ट्रैक करें ताकि केवल बदला हुआ हिस्सा pending दिखे। एक छोटी optimisticPatch और एक rollback snapshot रखें ताकि आप सिर्फ़ उस परिवर्तन को कन्फर्म या revert कर सकें।
हर म्यूटेशन के साथ एक request ID जोड़ें और आइटम के लिए latest request ID स्टोर करें। जब रिस्पॉन्स आये, तो केवल तभी लागू करें जब वह latest request ID से मैच करे; इस तरह लेट रिस्पॉन्स पुराने वैल्यू पर UI को वापस नहीं लौटा पाएंगे।
ज्यादातर एडिट्स के लिए, उपयोगकर्ता के वैल्यू को स्क्रीन पर रखें, उसे "not saved" के रूप में चिह्नित करें और उसी जगह एक inline error दिखाएँ, साथ में स्पष्ट Retry विकल्प। केवल उन्हीं मामलों में हार्ड-रोलबैक करें जहाँ परिवर्तन अस्वीकार्य हो (जैसे permissions हटना), और कारण बताएं।
जब परिवर्तन कई जगहों को प्रभावित कर सकता है—जैसेTotals, sorting, permissions—तो refetch करना सुरक्षित है क्योंकि सब कुछ सही तरीके से patch करना मुश्किल हो सकता है। यदि सर्वर अपडेटेड एंटिटी लौटा रहा है और यह छोटा, अलग बदलाव है, तो लोकल मर्ज करना बेहतर UX देता है।