17 दिस॰ 2025·8 मिनट
PostgreSQL कनेक्शन पूलिंग: ऐप पूलिंग बनाम PgBouncer
PostgreSQL कनेक्शन पूलिंग: Go बैकएंड के लिए ऐप पूल और PgBouncer की तुलना, निगरानी के लिए मीट्रिक्स, और गलत कॉन्फ़िग्स जो लेटेंसी स्पाइक्स ट्रिगर करते हैं।
PostgreSQL कनेक्शन पूलिंग: Go बैकएंड के लिए ऐप पूल और PgBouncer की तुलना, निगरानी के लिए मीट्रिक्स, और गलत कॉन्फ़िग्स जो लेटेंसी स्पाइक्स ट्रिगर करते हैं।
एक डेटाबेस कनेक्शन आपके ऐप और Postgres के बीच फोन लाइन जैसा है। एक नई लाइन खोलने में दोनों ओर समय और संसाधन लगते हैं: TCP/TLS सेटअप, ऑथेंटिकेशन, मेमोरी और Postgres साइड पर एक बैकएंड प्रोसेस। एक कनेक्शन पूल इन “फोन लाइन्स” का छोटा सेट खुला रखता है ताकि आपका ऐप उन्हें दोबारा इस्तेमाल कर सके और हर रिक्वेस्ट पर फिर से डायल न करे।
जब पूलिंग बंद हो या गलत साइज़ की हो, तो अक्सर साफ़-सी त्रुटि नहीं मिलती — आपको रैंडम स्लोनैस मिलती है। जो रिक्वेस्ट आमतौर पर 20–50 ms लेती हैं, अचानक 500 ms या 5 सेकंड ले सकती हैं और p95 आसमान छू सकता है। फिर टाइमआउट आते हैं, उसके बाद “too many connections” या ऐप के अंदर एक कतार दिखाई देती है जब यह खाली कनेक्शन का इंतज़ार करता है।
कनेक्शन लिमिट छोटे ऐप्स के लिए भी मायने रखती है क्योंकि ट्रैफिक बर्स्टी होता है। एक मार्केटिंग ईमेल, एक क्रोन जॉब या कुछ स्लो एंडपॉइंट्स दर्जनों रिक्वेस्ट्स एक साथ DB पर डाल सकते हैं। अगर हर रिक्वेस्ट नया कनेक्शन खोलती है, तो Postgres काफी क्षमता केवल कनेक्शन्स स्वीकारने और प्रबंधित करने में लगा सकता है बजाय क्वेरी चलाने के। वहीं अगर आपके पास पूल है लेकिन वह बहुत बड़ा है, तो आप बहुत सारी सक्रिय बैकएंड्स के साथ Postgres को ओवरलोड कर सकते हैं और कंटेक्स्ट स्विचिंग व मेमोरी प्रेसर ट्रिगर कर सकते हैं।
शुरुआती लक्षणों पर नजर रखें जैसे:
पूलिंग कनेक्शन चर्न घटाती है और बर्स्ट्स को संभालने में Postgres की मदद करती है। यह धीमी SQL को सुधारती नहीं है। अगर कोई क्वेरी फुल टेबल स्कैन कर रही है या लॉक पर रुकी है, तो पूलिंग मुख्य रूप से सिस्टम के विफल होने के तरीके को बदलती है (जल्दी कतारबद्ध होना, बाद में टाइमआउट) — तेज़ बनाती नहीं।
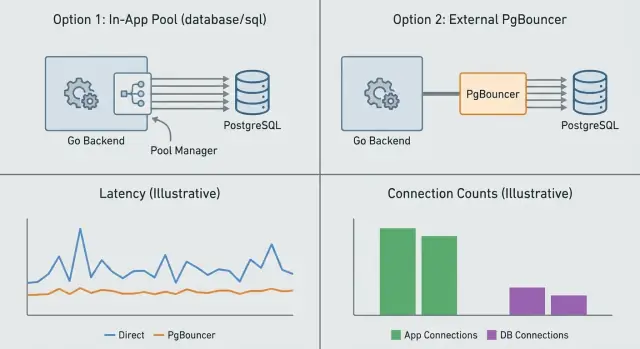
कनेक्शन पूलिंग का उद्देश्य एक साथ कितनी डेटाबेस कनेक्शन्स मौजूद हों और उन्हें कैसे री-यूज किया जाए, यह नियंत्रित करना है। आप यह अपने ऐप के अंदर कर सकते हैं (ऐप-लेवल पूलिंग) या Postgres के सामने एक अलग सर्विस (PgBouncer) के साथ। वे संबंधित लेकिन अलग समस्याएँ हल करते हैं।
ऐप-लेवल पूलिंग (Go में आमतौर पर बिल्ट-इन database/sql पूल) प्रति प्रोसेस कनेक्शन्स प्रबंधित करती है। यह तय करती है कि कब नया कनेक्शन खोला जाए, कब किसी को री-यूज किया जाए और कब आइडल कनेक्शन्स बंद करें। यह हर रिक्वेस्ट पर सेटअप लागत बचाती है। जो यह नहीं कर सकती वह है कई ऐप इंस्टेंसों के बीच समन्वय। अगर आप 10 रेप्लिकास चलाते हैं, तो आपके पास असल में 10 अलग पूल होंगे।
PgBouncer आपके ऐप और Postgres के बीच बैठता है और कई क्लाइंट्स की ओर से पूल करता है। यह तब सबसे उपयोगी है जब आपके पास बहुत सारे शॉर्ट-लाइव्ड रिक्वेस्ट, कई ऐप इंस्टेंस या स्पाइकी ट्रैफिक हो। यह सर्वर-साइड कनेक्शन्स को Postgres पर कैप कर देता है भले ही सैकड़ों क्लाइंट कनेक्शन्स एक साथ आएं।
जिम्मेदारियों का एक सरल विभाजन:
वे बिना “डबल पूलिंग” समस्याओं के साथ मिलकर काम कर सकते हैं जब तक कि हर लेयर का स्पष्ट उद्देश्य हो: हर Go प्रोसेस के लिए एक समझदारी भरा database/sql पूल, और ग्लोबल कनेक्शन बजट लागू करने के लिए PgBouncer।
एक आम भ्रम यह है कि “ज्यादा पूल्स का मतलब ज्यादा क्षमता” — आमतौर पर इसका अर्थ उल्टा होता है। अगर हर सर्विस, वर्कर और रेप्लिका का अपना बड़ा पूल है, तो कुल कनेक्शन काउंट तेजी से बढ़ सकता है और कतारबद्धता, कंटेक्स्ट स्विचिंग और अचानक लेटेंसी स्पाइक्स का कारण बन सकता है।
database/sql पूल का असल व्यवहारGo में, sql.DB एक कनेक्शन पूल मैनेजर है, एक सिंगल कनेक्शन नहीं। जब आप db.Query या db.Exec कॉल करते हैं, तो database/sql किसी आइडल कनेक्शन को री-यूज़ करने की कोशिश करता है। यदि वह नहीं कर पाता, तो यह नया कनेक्शन खोल सकता है (आपकी सीमा तक) या कॉलर्स को इंतज़ार करवा सकता है।
यही वो इंतज़ार है जहाँ अक्सर “मिस्ट्री लेटेंसी” आती है। जब पूल सैचुरेट हो जाता है, रिक्वेस्ट्स आपके ऐप के अंदर कतारबद्ध हो जाती हैं। बाहर से देखने पर ऐसा लगता है कि Postgres स्लो हो गया है, पर असल समय एक फ्री कनेक्शन के इंतज़ार में बीत रहा होता है।
ज़्यादातर ट्यूनिंग चार सेटिंग्स पर आती है:
MaxOpenConns: ओपन कनेक्शन्स (idle + in use) पर हार्ड कैप। जब यह हिट होता है, कॉलर्स ब्लॉक होते हैं।MaxIdleConns: कितने कनेक्शन्स री-यूज़ के लिए तैयार बैठे रह सकते हैं। बहुत कम होने पर बार-बार reconnection होगा।ConnMaxLifetime: कनेक्शन को समय-समय पर रिसायकल करने पर मजबूर करता है। लोड बैलेंसर और NAT टाइमआउट्स के लिए फायेदेमंद, पर बहुत छोटा होने पर churn बढ़ता है।ConnMaxIdleTime: उन कनेक्शन्स को बंद कर देता है जो लंबे समय तक अनयूज़्ड रहे हों।कनेक्शन री-यूज़ सामान्यतः लेटेंसी और डेटाबेस CPU घटाता है क्योंकि आप बार-बार सेटअप (TCP/TLS, auth, session init) नहीं कर रहे होते। पर एक ओवरसाइज़्ड पूल इसका उल्टा कर सकता है: यह Postgres की योग्यता से ज्यादा concurrency की अनुमति देता है, जिससे कॉन्टेंशन और ओवरहेड बढ़ता है।
प्रोसेस-वार नहीं, कुल में सोचें। अगर हर Go इंस्टेंस 50 ओपन कनेक्शन्स की अनुमति देता है और आप 20 इंस्टेंस तक स्केल करते हैं, तो आपने प्रभावी रूप से 1,000 कनेक्शन्स की अनुमति दे दी है। उस संख्या की तुलना करें कि आपका Postgres सर्वर वास्तव में कितनी कनेक्शन्स को सुचारू रूप से चला सकता है।
एक व्यावहारिक शुरुआत यह है कि MaxOpenConns को प्रति इंस्टेंस की अपेक्षित concurrency से बाँधें, फिर इसे बढ़ाने से पहले पूल मीट्रिक्स (in-use, idle, wait time) से सत्यापित करें।
PgBouncer एक छोटा प्रॉक्सी है आपके ऐप और PostgreSQL के बीच। आपकी सर्विस PgBouncer से कनेक्ट करती है, और PgBouncer Postgres के लिए सीमित असली सर्वर कनेक्शन्स रखता है। बर्स्ट्स के दौरान PgBouncer क्लाइंट वर्क को कतारबद्ध करता है बजाय तुरंत और अधिक Postgres बैकएंड्स बनाने के। वह कतार नियंत्रित धीमेपन और डेटाबेस के टॉप-ओवर के बीच का फर्क कर सकती है।
PgBouncer के तीन पूलिंग मोड हैं:
Session pooling डायरेक्ट Postgres कनेक्शन्स जैसा व्यवहार दिखाता है। यह सबसे कम आश्चर्यजनक है, पर बर्स्टी लोड में यह सर्वर कनेक्शन्स कम नहीं बचाता।
टिपिकल Go HTTP APIs के लिए transaction pooling अक्सर एक मजबूत डिफ़ॉल्ट होता है। ज़्यादातर रिक्वेस्ट एक छोटा क्वेरी या छोटा ट्रांज़ैक्शन करते हैं और फिर खत्म हो जाते हैं। ट्रांज़ैक्शन पूलिंग कई क्लाइंट कनेक्शन्स को एक छोटे Postgres कनेक्शन बजट में साझा करने देती है।
ट्रेडऑफ सेशन स्टेट है। ट्रांज़ैक्शन मोड में, जो कुछ भी एक ही सर्वर कनेक्शन पर पिन होता है वह टूट सकता है या अजीब तरीके से व्यवहार कर सकता है, जैसे:
SET, SET ROLE, search_path)अगर आपका ऐप उस तरह के स्टेट पर निर्भर है तो session pooling सुरक्षित विकल्प है। statement pooling सबसे प्रतिबंधक है और वेब ऐप्स के लिए शायद ही उपयुक्त होता है।
एक उपयोगी नियम: अगर हर रिक्वेस्ट अपने लिए जो चाहिए वह एक ट्रांज़ैक्शन के अंदर सेट कर सकता है, तो ट्रांज़ैक्शन पूलिंग लोड के तहत लेटेंसी को अधिक स्थिर रखती है। अगर आपको लंबे समय तक चलने वाले सत्र व्यवहार की ज़रूरत है, तो session pooling का उपयोग करें और ऐप में सख्त सीमाओं पर ध्यान दें।
यदि आप database/sql के साथ Go सर्विस चलाते हैं, तो आपके पास पहले से ऐप-साइड पूलिंग है। कई टीमों के लिए वहीं काफी होता है: कुछ इंस्टेंस, स्थिर ट्रैफ़िक और क्वेरियाँ जो अत्यधिक स्पाइकी नहीं हैं। ऐसी सेटिंग में सबसे सरल और सुरक्षित विकल्प है Go पूल को ट्यून करना, डेटाबेस कनेक्शन लिमिट यथार्थपरक रखना, और यहीं रुक जाना।
PgBouncer तब मदद करता है जब डेटाबेस पर बहुत सारे क्लाइंट कनेक्शन्स एक साथ आ रहे हों। यह तब दिखता है जब कई ऐप इंस्टेंस हों (या serverless-स्टाइल स्केलिंग), बर्स्टी ट्रैफिक हो, और बहुत सारी शॉर्ट क्वेरियाँ हों।
PgBouncer गलत मोड में उपयोग करने पर भी नुकसान कर सकता है। अगर आपका कोड session state पर निर्भर है (temporary tables, prepared statements across requests, advisory locks held across calls, या session-level settings), तो transaction pooling भ्रमित करने वाली विफलताएँ पैदा कर सकता है। अगर आपको सचमुच session व्यवहार चाहिए, तो session pooling उपयोग करें या PgBouncer को छोड़कर ऐप पूल्स को सावधानी से साइज़ करें।
यह नियम अपनाएँ:
कनेक्शन लिमिट एक बजट हैं। अगर आप वह बजट एक साथ खर्च कर देते हैं, तो हर नया रिक्वेस्ट इंतज़ार करेगा और टेल लेटेंसी कूदेगी। लक्ष्य यह है कि concurrency को नियंत्रित तरीके से कैप करें जबकि थ्रूपुट स्थिर रखें।
आज के पीक्स और टेल लेटेंसी नापें। पीक एक्टिव कनेक्शन्स (औसत नहीं), और रिक्वेस्ट व की-क्वेरियों के p50/p95/p99 रिकॉर्ड करें। किसी भी कनेक्शन एरर या टाइमआउट्स को नोट करें।
ऐप के लिए एक सुरक्षित Postgres कनेक्शन बजट सेट करें। max_connections से शुरू करें और एडमिन एक्सेस, माइग्रेशंस, बैकग्राउंड जॉब्स, और बर्स्ट्स के लिए हेडरूम घटाएँ। अगर कई सर्विसेस DB शेयर कर रही हैं, तो बजट को जानबूझकर बाँटें।
बजट को इंस्टेंस-वार Go लिमिट्स में मैप करें। ऐप बजट को इंस्टेंस की संख्या से बाँटें और MaxOpenConns को उसी (या थोड़ा कम) पर सेट करें। MaxIdleConns इतना रखें कि लगातार reconnects न हों, और lifetimes इस तरह सेट करें कि कनेक्शन्स कभी-कभार रिसायकल हों पर churn न हो।
यदि जरूरत हो तभी PgBouncer जोड़ें, और मोड चुनें। अगर आपको session state चाहिए तो session pooling उपयोग करें। अगर आपका ऐप कम्पैटिबल है और आप सर्वर कनेक्शन्स में बड़ा कट चाहते हैं, तो transaction pooling चुनें।
धीरे-धीरे रोल आउट करें और पहले व बाद में तुलना करें। एक समय में एक चीज़ बदलें, canary रोलआउट करें, फिर टेल लेटेंसी, पूल वेट टाइम, और DB CPU की तुलना करें।
उदाहरण: अगर Postgres सुरक्षित रूप से आपकी सर्विस को 200 कनेक्शन्स दे सकता है और आप 10 Go इंस्टेंस चलाते हैं, तो प्रति इंस्टेंस MaxOpenConns=15-18 से शुरू करें। यह बर्स्ट्स के लिए जगह छोड़ता है और यह संभावना कम करता है कि हर इंस्टेंस एक साथ सीमा को हिट कर दे।
पूलिंग समस्याएँ अक्सर पहले “बहुत सारे कनेक्शन्स” के रूप में नहीं दिखतीं। अक्सर आप वेट टाइम में धीरे-धीरे वृद्धि देखते हैं और फिर अचानक p95/p99 कूद जाती है।
शुरूआत अपने Go ऐप की रिपोर्ट से करें। database/sql के साथ open connections, in-use, idle, wait count और wait time मॉनिटर करें। अगर ट्रैफिक स्थिर रहते हुए wait count बढ़ता है, तो आपका पूल undersized है या कनेक्शन्स बहुत लंबे समय तक होल्ड किए जा रहे हैं।
DB साइड पर active connections बनाम max, CPU और lock activity ट्रैक करें। अगर CPU निचला है पर लेटेंसी ऊँची है, तो अक्सर यह कतारबद्धता या लॉकिंग होती है, कच्चे compute की कमी नहीं।
अगर आप PgBouncer चलाते हैं तो एक तीसरी दृष्टि जोड़ें: client connections, server connections to Postgres, और queue depth। एक बढ़ती कतार जबकि server connections स्थिर हैं तो स्पष्ट संकेत है कि बजट सैचुरेट हो रहा है।
अच्छे अलर्ट संकेत:
पूलिंग मुद्दे अक्सर बर्स्ट्स के दौरान सामने आते हैं: रिक्वेस्ट्स कनेक्शन के इंतज़ार में जमा हो जाती हैं, फिर अचानक सब कुछ ठीक लगने लगता है। जड़ अक्सर ऐसा सेटिंग होता है जो एक इंस्टेंस पर ठीक लगता है पर कई कॉपियों में खतरनाक बन जाता है।
सामान्य कारण:
MaxOpenConns बिना ग्लोबल बजट के सेट। 100 कनेक्शन्स प्रति इंस्टेंस और 20 इंस्टेंस = 2,000 संभावित कनेक्शन्स।ConnMaxLifetime / ConnMaxIdleTime बहुत छोटा सेट। इससे कई कनेक्शन्स एक साथ रिसायकल हो सकते हैं और reconnect स्टोर्म बन सकती है।स्पाइक्स कम करने का एक सरल तरीका यह है कि पूलिंग को एक साझा सीमा मानें, न कि ऐप-स्थानीय डिफ़ॉल्ट: कुल कनेक्शन्स पर कैप लगाएँ, एक साधारण आइडल पूल रखें, और लाइफटाइम इतने लंबे रखें कि सिंक्रोनाइज़्ड reconnects न हों।
जब ट्रैफिक बढ़ती है, आमतौर पर आप तीन में से एक परिणाम देखते हैं: रिक्वेस्ट्स फ्री कनेक्शन के लिए कतारबद्ध हो जाती हैं, रिक्वेस्ट्स टाइमआउट हो जाती हैं, या सब कुछ इतना स्लो हो जाता है कि retries इकठ्ठा हो जाते हैं।
कतारबद्धता सबसे चालाक है। आपका हैंडलर अभी भी चल रहा है, पर यह कनेक्शन के इंतज़ार में पार्क है। वह इंतज़ार रिस्पॉन्स टाइम का हिस्सा बन जाता है, इसलिए छोटा पूल एक 50 ms क्वेरी को लोड पर कई सेकंड का एन्डपॉइंट बना सकता है।
एक मददगार मानसिक मॉडल: अगर आपके पूल में 30 उपयोगी कनेक्शन्स हैं और अचानक 300 concurrent रिक्वेस्ट्स आते हैं जो सभी DB चाहते हैं, तो 270 को इंतज़ार करना होगा। यदि हर रिक्वेस्ट कनेक्शन 100 ms के लिए होल्ड करती है, तो टेल लेटेंसी जल्दी सेकंड्स में चली जाएगी।
एक स्पष्ट टाइमआउट बजट सेट करें और उस पर टिके रहें। ऐप टाइमआउट DB टाइमआउट से थोड़ा छोटा होना चाहिए ताकि आप जल्दी फेल करें और दबाव कम करें बजाय काम को अटके रहने देने के।
statement_timeout ताकि एक खराब क्वेरी कनेक्शन्स नहीं रोक सकेफिर बैकप्रेशर जोड़ें ताकि आप पहले से ही पूल को ओवरलोड न करें। कुछ अनुमानित मेकैनिज्म चुनें, जैसे प्रति एंडपॉइंट concurrency सीमित करना, स्पष्ट एरर के साथ लोड shed करना (429 जैसा), या बैकग्राउंड जॉब्स को यूजर ट्रैफिक से अलग करना।
अंत में, पहले स्लो क्वेरीज ठीक करें। पूलिंग दबाव में, स्लो क्वेरीज कनेक्शन्स ज्यादा देर तक रोकती हैं, जिससे वेट्स बढ़ते हैं, टाइमआउट्स बढ़ते हैं और retries होते हैं। यह फीडबैक लूप है जिससे “थोड़ी सी स्लो” "सब कुछ स्लो" में बदल जाती है।
लोड टेस्टिंग को अपने कनेक्शन बजट को मान्य करने का तरीका समझें, केवल थ्रूपुट नहीं। लक्ष्य यह पुष्टि करना है कि पूलिंग दबाव में उसी तरह व्यवहार करती है जैसे स्टेजिंग में करती है।
वास्तविक ट्रैफिक के साथ टेस्ट करें: वही रिक्वेस्ट मिक्स, बर्स्ट पैटर्न, और उतनी ही ऐप इंस्टेंस की संख्या जितनी प्रोडक्शन में होती है। “एक एंडपॉइंट” बेंचमार्क अक्सर पूल समस्याओं को लॉन्च डे तक छिपाए रखता है।
वॉर्म-अप शामिल करें ताकि आप कोल्ड कैशेस और रैम्प-अप इफेक्ट्स न मापें। पूल्स को उनके सामान्य आकार तक पहुँचने दें, फिर रिकॉर्ड करना शुरू करें।
यदि आप रणनीतियों की तुलना कर रहे हैं, तो वर्कलोड समान रखें और चलाएँ:
database/sql, कोई PgBouncer नहीं)हर रन के बाद एक छोटा स्कोरकार्ड रिकॉर्ड करें जिसे आप हर रिलीज के बाद फिर इस्तेमाल कर सकें:
समय के साथ, यह क्षमता योजना अनुमान से हटाकर दोहराने योग्य बना देगा।
पूल साइज़ बदलने से पहले एक नंबर लिख लें: आपका कनेक्शन बजट। यह इस एनवायरनमेंट (dev, staging, prod) के लिए सक्रिय Postgres कनेक्शन्स की अधिकतम सुरक्षित संख्या है, जिसमें बैकग्राउंड जॉब्स और एडमिन एक्सेस भी शामिल हैं। यदि आप इसे नामित नहीं कर सकते, तो आप अंदाज़ लगा रहे हैं।
एक त्वरित चेकलिस्ट:
MaxOpenConns) बजट में फिट होता है (या PgBouncer कैप)।max_connections और कोई भी रिज़र्व कनेक्शन्स आपकी योजना के साथ मेल खाते हों यह सुनिश्चित करें।रोलआउट प्लान जो रोलबैक आसान रखे:
यदि आप Go + PostgreSQL ऐप Koder.ai (koder.ai) पर बना और होस्ट कर रहे हैं, तो Planning Mode मदद कर सकता है कि आप परिवर्तन और क्या मापेंगे मैप करें, और snapshots व rollback से tail latency खराब होने पर लौटना आसान हो जाएगा।
अगला कदम: अगले ट्रैफिक जंप से पहले एक माप जोड़ें। ऐप में “कनेक्शन के लिए बिताया गया समय” अक्सर सबसे उपयोगी होता है, क्योंकि यह उपयोगकर्ताओं को महसूस होने से पहले पूलिंग दबाव को दिखाता है।
एक पूल PostgreSQL कनेक्शनों का छोटा सेट खुला रखता है और उन्हें कई रिक्वेस्ट में दोबारा इस्तेमाल करता है। इससे TCP/TLS, प्रमाणीकरण और सर्वर-साइड बैकएंड प्रोसेस जैसा सेटअप बार-बार नहीं करना पड़ता, और बर्स्ट के दौरान टेल लेटेंसी स्थिर रखने में मदद मिलती है।
जब पूल भर जाता है, तो रिक्वेस्ट आपके ऐप के अंदर एक फ्री कनेक्शन के लिए रुक जाती हैं, और वही रुकावट धीरे-धीरे धीमी प्रतिक्रियाओं के रूप में दिखाई देती है। अक्सर औसत लेटेंसी ठीक रहती है जबकि p95/p99 ट्रैफिक बर्स्ट के दौरान कूद जाते हैं।
नहीं। पूलिंग मुख्यतः री-कनेक्ट चर्न घटाती है और एक समय में कितनी कन्करेंट क्वेरी चलेंगी यह नियंत्रित करती है। अगर कोई क्वेरी स्लो है (फुल टेबल स्कैन, लॉक आदि), तो पूलिंग उसे तेज नहीं करेगी; यह बस यह नियंत्रित करेगी कि कितनी स्लो क्वेरीज एक साथ चलें।
ऐप-लेवल पूलिंग प्रति प्रोसेस कनेक्शनों का प्रबंधन करती है, यानी हर ऐप इंस्टेंस का अपना पूल और सीमाएँ होती हैं। PgBouncer Postgres के सामने बैठकर कई क्लाइंट्स के लिए एक वैश्विक कनेक्शन बजट लागू करता है, जो कई रेप्लिकास या स्पाइकी ट्रैफिक में खासकर उपयोगी है।
यदि आपके पास कम इंस्टेंस हैं और कुल ओपन कनेक्शन्स सुरक्षित रूप से DB लिमिट के भीतर रहते हैं, तो database/sql के पूल को ट्यून करना अक्सर काफी होता है। जब कई इंस्टेंस, ऑटोस्केलिंग या बर्स्टरी ट्रैफिक कुल कनेक्शन्स को उस सीमा से ऊपर धकेल सकते हैं जिसे Postgres अच्छी तरह संभालता है, तब PgBouncer जोड़ें।
एक अच्छा तरीका यह है कि पहले सर्विस के लिए कुल कनेक्शन बजट सेट करें, उसे इंस्टेंसों से भाग कर प्रति इंस्टेंस MaxOpenConns तय करें और इसे थोड़ा नीचे रखें। छोटे से शुरू करें, wait time और p95/p99 देखें, और तभी बढ़ाएँ जब आपको सुनिश्चित हो कि डेटाबेस के पास हेडरूम है।
ट्रांज़ैक्शन पूलिंग अक्सर HTTP APIs के लिए अच्छा डिफ़ॉल्ट होता है क्योंकि यह कई क्लाइंट कनेक्शन्स को कम सर्वर कनेक्शन्स में शेयर करने देता है और बर्स्ट के दौरान लेटेंसी को स्थिर रखता है। यदि आपका कोड सेशन स्टेट पर निर्भर है (टेम्परेरी टेबल, सत्र सेटिंग्स, आदि), तो session pooling चुनें।
Prepared statements, temp tables, advisory locks और session-लेवल सेटिंग्स असामान्य व्यवहार दिखा सकती हैं क्योंकि क्लाइंट को अगली बार वही सर्वर कनेक्शन न मिल सके। यदि आप इन सुविधाओं पर निर्भर हैं, तो हर अनुरोध के अंदर सब कुछ एक ही ट्रांज़ैक्शन में रखें या session pooling का उपयोग करें।
p95/p99 के साथ-साथ ऐप पूल वेट टाइम को देखें, क्योंकि वेट टाइम अक्सर यूजर शिकायतों से पहले बढ़ता है। Postgres पर active connections, CPU और locks ट्रैक करें; PgBouncer के लिए client connections, server connections और queue depth देखें ताकि पता चले कि कनेक्शन बजट सैचुरेट हो रहा है या नहीं।
पहले, request deadlines और DB के लिए statement_timeout सेट करें ताकि एक स्लो क्वेरी कनेक्शन्स को अनिश्चितकाल तक न रोके। फिर बैकप्रेशर जोड़ें: DB-हेवी एंडपॉइंट्स पर concurrency सीमित करें, लोड shed करें (जैसे 429), और reconnect स्टोर्म रोकने के लिए कनेक्शन लाइफटाइम बहुत छोटा न रखें।