06 अग॰ 2025·8 मिनट
केंद्रीकृत सूचना नियंत्रण के लिए वेब ऐप कैसे बनाएं
सीखें कि कैसे एक वेब ऐप डिजाइन और बनाएं जो चैनलों में फैली सूचनाओं को केंद्रीकृत करे — राउटिंग नियम, टेम्पलेट, उपयोगकर्ता प्राथमिकताएँ और डिलीवरी ट्रैकिंग के साथ।
सीखें कि कैसे एक वेब ऐप डिजाइन और बनाएं जो चैनलों में फैली सूचनाओं को केंद्रीकृत करे — राउटिंग नियम, टेम्पलेट, उपयोगकर्ता प्राथमिकताएँ और डिलीवरी ट्रैकिंग के साथ।
केंद्रीकृत नोटिफिकेशन प्रबंधन का मतलब है कि आपके प्रोडक्ट द्वारा भेजे जाने वाले हर संदेश — ईमेल, SMS, पुश, इन-ऐप बैनर, Slack/Teams, वेबहुक callbacks — को एक समन्वित सिस्टम के हिस्से के रूप में माना जाए।
हर फीचर टीम अपना "एक संदेश भेजो" लॉजिक बनाने की बजाय, आप एक ही जगह बनाते हैं जहाँ इवेंट्स आते हैं, नियम तय करते हैं कि क्या होगा, और डिलीवरी को end-to-end ट्रैक किया जाता है।
जब नोटिफिकेशन्स सेवाओं और कोडबेस में बिखरी होती हैं, तो वही समस्याएँ बार-बार आती हैं:
केंद्रीकरण एड-हॉक भेजने को एक सुसंगत वर्कफ़्लो से बदल देता है: इवेंट बनाइए, प्राथमिकताएँ और नियम लागू कीजिए, टेम्पलेट चुनिए, चैनलों द्वारा भेजिए, और परिणाम रिकॉर्ड कीजिए।
एक नोटिफिकेशन हब आम तौर पर सेवा देता है:
आप जान पाएँगे कि यह काम कर रहा है जब:
आर्किटेक्चर का मसौदा बनाने से पहले यह स्पष्ट कर लें कि आपके संगठन के लिए "केंद्रीकृत नोटिफिकेशन नियंत्रण" का क्या मतलब है। स्पष्ट आवश्यकताएँ पहले संस्करण को केन्द्रित रखें और हब को आधा बिल्ट CRM बनने से रोकें।
जिस सूची का आप समर्थन करेंगे वह नियम, टेम्पलेट और अनुपालन को प्रभावित करती है:
स्पष्ट रूप से परिभाषित करें कि प्रत्येक संदेश किस श्रेणी में आता है — इससे बाद में "मार्केटिंग को Transactional के रूप में छुपाना" रोका जा सकेगा।
ऐसे छोटे सेट को चुनें जिसे आप पहले दिन से भरोसेमंद रूप से चला सकें, और "बाद में" चैनलों का दस्तावेज रखें ताकि आपका डेटा मॉडल उन्हें ब्लॉक न करे।
अब सपोर्ट करें (आम MVP): ईमेल + एक रीयल-टाइम चैनल (पुश या इन-ऐप) या यदि आपका प्रोडक्ट उसी पर निर्भर है तो SMS।
बाद में सपोर्ट करें: चैट टूल्स (Slack/Teams), WhatsApp, वॉइस, पोस्टल, पार्टनर वेबहुक्स।
चैनल सीमाएँ भी लिखें: rate limits, deliverability आवश्यकताएँ, sender identities (डोमेन्स, फोन नंबर), और प्रति संदेश लागत।
केंद्रीकृत नोटिफिकेशन प्रबंधन "सब कुछ ग्राहक-संबंधित" नहीं है। सामान्य non-goals:
नियमों को जल्दी पकड़ लें ताकि बाद में retrofit न करना पड़े:
यदि आपके पास पहले से नीतियाँ हैं, तो उन्हें आंतरिक रूप से लिंक करें (उदा., /security, /privacy) और MVP के लिए उन्हें acceptance criteria मानें।
नोटिफिकेशन हब को पाइपलाइन की तरह समझना आसान है: इवेंट्स अंदर जाते हैं, संदेश बाहर आते हैं, और हर चरण पर ऑब्ज़र्वेबल होना चाहिए। जिम्मेदारियों को अलग रखना बाद में चैनल जोड़ने (SMS, WhatsApp, पुश) को आसान बनाता है बिना सब कुछ फिर से लिखे।
1) इवेंट intake (API + connectors). आपका ऐप, सर्विसेज़, या बाहरी पार्टनर्स "कुछ हुआ" इवेंट्स एकल एंट्री प्वाइंट पर भेजते हैं। आम intake पाथ में REST endpoint, वेबहुक्स, या डायरेक्ट SDK कॉल्स शामिल होते हैं।
2) राउटिंग इंजन. हब तय करता है किसे नोटिफाई करना है, किस चैनल/चैनलों के माध्यम से, और कब। यह लेयर recipient डेटा और प्राथमिकताओं को पढ़ती है, नियमों का मूल्यांकन करती है, और एक delivery plan आउटपुट करती है।
3) टेम्पलेटिंग + पर्सनलाइजेशन. एक delivery plan मिलने पर, हब चैनल-विशिष्ट संदेश रेंडर करता है (ईमेल HTML, SMS टेक्स्ट, पुश पेलोड) टेम्पलेट और वेरिएबल्स का उपयोग कर।
4) डिलीवरी वर्कर्स. ये प्रोवाइडर्स (SendGrid, Twilio, Slack, आदि) के साथ इंटीग्रेट करते हैं, retries संभालते हैं, और rate limits का पालन करते हैं।
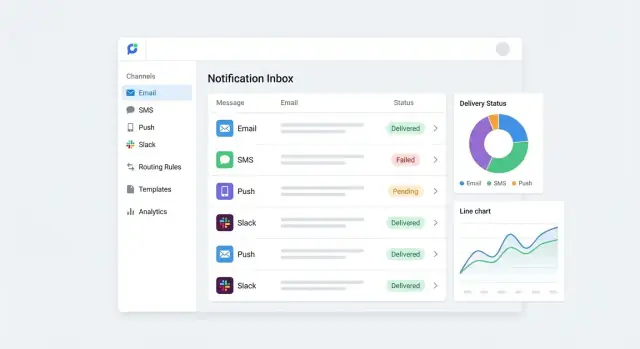
5) ट्रैकिंग + रिपोर्टिंग. हर प्रयास रिकॉर्ड होता है: accepted, sent, delivered, failed, opened/clicked (जहाँ उपलब्ध)। यह एडमिन डैशबोर्ड और ऑडिट ट्रेल्स को पावर करता है।
हल्के intake (जैसे validate और 202 Accepted लौटाएँ) के लिए synchronous प्रोसेसिंग ही रखें। वास्तविक सिस्टम के लिए अधिकांश काम asynchronous होना चाहिए:
शुरू से dev/staging/prod की योजना बनाएं। प्रोवाइडर क्रेडेंशियल्स, rate limits, और feature flags environment-specific कॉन्फ़िगरेशन में रखें (टेम्पलेट्स में नहीं)। टेम्पलेट्स का वर्शनिंग रखें ताकि आप staging में टेस्ट कर सकें पहले कि वे प्रोडक्शन को प्रभावित करें।
एक व्यावहारिक विभाजन:
यह आर्किटेक्चर एक स्थिर बैकबोन देता है जबकि दैनिक संदेश परिवर्तनों को deployment cycles से बाहर रखता है।
केंद्रीकृत नोटिफिकेशन सिस्टम की सफलता इवेंट्स की गुणवत्ता पर निर्भर करती है। अगर आपके प्रोडक्ट के अलग हिस्से एक ही चीज़ को अलग तरीके से वर्णन करते हैं, तो आपका हब अनुवाद करने, अंदाज़ा लगाने, और टूटने में लगा रहेगा।
एक छोटा, स्पष्ट कॉन्ट्रैक्ट शुरू करें जिसका हर प्रोड्यूसर पालन कर सके। एक व्यावहारिक बेसलाइन कुछ यूँ दिखती है:
invoice.paid, comment.mentioned)यह संरचना इवेंट-ड्राइवेन नोटिफिकेशन्स को समझने योग्य रखती है और राउटिंग नियम, टेम्पलेट्स, और डिलीवरी ट्रैकिंग को सपोर्ट करती है।
इवेंट्स विकसित होते हैं। उन्हें versioning देकर ब्रेकेज से बचाएँ, उदाहरण के लिए schema_version: 1 के साथ। जब ब्रेकिंग चेंज की ज़रूरत हो, नया वर्शन प्रकाशित करें (या नया event name) और संक्रमण अवधि के लिए दोनों सपोर्ट करें। यह तब सबसे महत्वपूर्ण होता है जब कई प्रोड्यूसर्स (बैकएंड सर्विसेस, वेबहुक्स, शेड्यूल्ड जॉब्स) एक हब को फीड कर रहे हों।
आने वाले इवेंट्स को अनविश्वसनीय इनपुट समझें, यहाँ तक कि अपनी ही सिस्टम से आए हों:
idempotency_key: invoice_123_paid) ताकि retries multi-channel नोटिफिकेशन्स में duplicate sends न बनाएं।मज़बूत डेटा कॉन्ट्रैक्ट्स सपोर्ट टिकट घटाते हैं, इंटीग्रेशन्स तेज़ करते हैं, और रिपोर्टिंग/ऑडिट लॉग्स को भरोसेमंद बनाते हैं।
एक नोटिफिकेशन हब तभी काम करता है जब वह जानता हो कि कौन है, किस तरह उसे पहुँचाना है, और उन्होंने क्या स्वीकार किया है। पहचान, संपर्क डेटा, और प्राथमिकताओं को प्रथम श्रेणी ऑब्जेक्ट्स मानें—न कि यूज़र रिकॉर्ड पर आकस्मिक फ़ील्ड्स।
User (लॉग इन करने वाला) को Recipient (जिसे संदेश मिल सकता है) से अलग रखें:
प्रति संपर्क बिंदु स्टोर करें: value (उदा., ईमेल), चैनल प्रकार, लेबल, मालिक, और verification status (unverified/verified/blocked)। साथ में metadata जैसे last verified time और verification method (लिंक, कोड, OAuth) रखें।
प्राथमिकताएँ व्यक्त करना चाहिए पर पूर्वानुमेय:
इसे लेयर्ड डिफ़ॉल्ट्स के साथ मॉडल करें: organization → team → user → recipient, जहाँ निचले स्तर ऊपरी स्तर को ओवरराइड करें। इससे admins बेसलाइन सेट कर सकें जबकि व्यक्ति व्यक्तिगत डिलिवरी नियंत्रित कर सकें।
सहमति सिर्फ एक चेकबॉक्स नहीं है। स्टोर करें:
सहमति परिवर्तनों को auditable और single-place से exportable बनाएं (उदा., /settings/notifications), क्योंकि सपोर्ट टीम्स को यह बताने की ज़रूरत पड़ेगी कि "मुझे यह क्यों मिला/नहीं मिला"।
राउटिंग नियम केंद्रीकृत नोटिफिकेशन हब का “ब्रेन” होते हैं: वे तय करते हैं कि किस recipient को नोटिफाई किया जाए, किस चैनल से, और किन शर्तों में। अच्छे राउटिंग शोर कम करते हैं बिना महत्वपूर्ण अलर्ट मिस किए।
परिभाषित करें कि आपके नियम किन इनपुट्स का मूल्यांकन कर सकते हैं। पहला संस्करण छोटा लेकिन अभिव्यंजक रखें:
invoice.overdue, deployment.failed, comment.mentioned)ये इनपुट्स आपके इवेंट कॉन्ट्रैक्ट से निकले हुए होने चाहिए, न कि एडमिन्स द्वारा मैन्युअली हर नोटिफिकेशन के लिए टाइप किए गए।
क्रियाएँ डिलिवरी बिहेवियर को निर्दिष्ट करती हैं:
प्रति नियम एक स्पष्ट priority और fallback order परिभाषित करें। उदाहरण: पहले पुश कोशिश करें, अगर पुश फेल हो तो SMS, और अंतिम विकल्प के रूप में ईमेल।
fallback को वास्तविक डिलीवरी सिग्नल्स (bounced, provider error, device unreachable) से जोड़ें, और retry लूप्स को स्पष्ट caps के साथ रोकें।
नियमों को मार्गदर्शित UI (ड्रॉपडाउन, प्रीव्यू, और चेतावनियाँ) के माध्यम से संपादित करने दें, जिनमें शामिल हों:
टेम्पलेट्स वह जगह हैं जहाँ केंद्रीकृत नोटिफिकेशन प्रबंधन "कई संदेशों" को एक सुसंगत उत्पाद अनुभव में बदल देता है। अच्छा टेम्पलेट सिस्टम टोन को टीमों में स्थिर रखता है, त्रुटियों को घटाता है, और मल्टी-चैनल डिलीवरी (ईमेल, SMS, पुश, इन-ऐप) को इरादतन बनाता है।
टेम्पलेट को एक संरचित संपत्ति के रूप में देखें, न कि टेक्स्ट का ढेर। कम से कम स्टोर करें:
{{first_name}}, {{order_id}}, {{amount}})वेरिएबल्स को स्पष्ट schema के साथ रखें ताकि सिस्टम यह मान्य कर सके कि इवेंट payload आवश्यक चीज़ें प्रदान कर रहा है। इससे "Hi {{name}}" जैसे अधूरे रेंडर से बचा जा सकेगा।
प्राप्तकर्ता की locale कैसे चुनी जाएगी पर नियम बनाएं: पहले user preference, फिर account/org सेटिंग, फिर डिफ़ॉल्ट (आम तौर पर en)। हर टेम्पलेट के लिए locale अनुसार अनुवाद स्टोर करें और स्पष्ट fallback नीति रखें:
fr-CA गायब है तो fr पर fallback करें।fr भी गायब है तो टेम्पलेट की डिफ़ॉल्ट locale पर fallback करें।इससे मिसिंग ट्रांसलेशन्स रिपोर्टिंग में दिखाई देंगी बजाय चुपचाप घटने के।
एक टेम्पलेट प्रीव्यू स्क्रीन दें जो एडमिन को अनुमति दे:
अंतिम संदेश को बिल्कुल उसी तरह रेंडर करें जैसा पाइपलाइन भेजेगा, लिंक रीराइटिंग और ट्रंकेशन नियमों सहित। एक test-send जोड़ें जो "sandbox recipient list" को लक्षित करे ताकि गलती से ग्राहकों को संदेश न जाए।
टेम्पलेट्स को कोड की तरह वर्शन करें: हर बदलाव एक नया immutable वर्शन बनाता है। स्टेट्स जैसे Draft → In review → Approved → Active का उपयोग करें, रोल-बेस्ड approvals वैकल्पिक रखें। रोलबैक एक क्लिक में हो।
ऑडिटेबिलिटी के लिए रिकॉर्ड रखें कि किसने क्या बदला, कब और क्यों, और इसे डिलीवरी परिणामों से लिंक करें ताकि आप failures के spikes को टेम्पलेट edits से correlate कर सकें (देखें /blog/audit-logs-for-notifications)।
नोटिफिकेशन हब उतना ही विश्वसनीय होता है जितना उसका आखिरी मील: वे चैनल प्रोवाइडर्स जो वास्तव में ईमेल, SMS, और पुश संदेश डिलीवर करते हैं। लक्ष्य यह है कि हर प्रोवाइडर "प्लग-इन" जैसा महसूस हो, जबकि डिलीवरी बिहेवियर चैनलों भर में सुसंगत रहे।
प्रत्येक चैनल के लिए एक मजबूत समर्थित प्रोवाइडर से शुरू करें — उदा., SMTP या ईमेल API, एक SMS गेटवे, और पुश सर्विस (APNs/FCM)। इंटीग्रेशन्स को एक सामान्य इंटरफ़ेस के पीछे रखें ताकि बाद में प्रोवाइडर्स बदलने या जोड़ने पर बिज़नेस लॉजिक न बदलनी पड़े।
प्रत्येक इंटीग्रेशन को संभालना चाहिए:
"नोटिफिकेशन भेजो" को एक पाइपलाइन के रूप में देखें: enqueue → prepare → send → record। छोटा ऐप होने पर भी, queue-based worker मॉडल slow provider calls को वेब ऐप रोकने से बचाता है और retries लागू करने की जगह देता है।
एक व्यावहारिक दृष्टिकोण:
प्रोवाइडर्स बहुत भिन्न प्रतिक्रियाएँ लौटाते हैं। उन्हें एक आंतरिक स्टेट मॉडल में सामान्यीकृत करें जैसे: queued, sent, delivered, failed, bounced, suppressed, throttled।
डिबगिंग के लिए raw provider payload स्टोर करें, पर डैशबोर्ड और अलर्ट normalized स्टेटस के आधार पर बनें।
exponential backoff और अधिकतम प्रयास सीमा के साथ retries लागू करें। केवल अस्थायी त्रुटियों (timeouts, 5xx, throttling) को ही retry करें, न कि स्थायी त्रुटियों (invalid number, hard bounce)।
प्रोवाइडर rate limits का सम्मान करने के लिए प्रति-प्रोवाइडर throttling जोड़ें। उच्च-वॉल्यूम इवेंट्स के लिए जहाँ प्रोवाइडर सपोर्ट करता है वहां बैचिंग करें (उदा., bulk email API calls) ताकि लागत कम हो और थ्रूपुट बढ़े।
केंद्रीकृत नोटिफिकेशन हब उसी हद तक भरोसेमंद है जितनी उसकी विजिबिलिटी। जब कोई ग्राहक कहे "मुझे वह ईमेल नहीं मिला", तो आपको तेज़ी से जवाब देना चाहिए: क्या भेजा गया, किस चैनल से, और उसके बाद क्या हुआ।
चैनलों भर में रिपोर्टिंग को स्थिर रखने के लिए एक छोटा सा स्टेट सेट मानकीकृत करें। व्यावहारिक बेसलाइन:
इन्हें एक टाइमलाइन की तरह मानें—हर संदेश प्रयास कई स्टेट अपडेट भेज सकता है।
एक मैसेज लॉग बनाएँ जो सपोर्ट और ऑपरेशन्स के लिए उपयोग में आसान हो। कम से कम इसे सर्चेबल रखें:
invoice.paid, password.reset)मुख्य विवरण शामिल करें: चैनल, टेम्पलेट नाम/वर्शन, लोकल, प्रोवाइडर, एरर कोड, और retry count। डिफ़ॉल्ट रूप से सुरक्षित रखें: संवेदनशील फ़ील्ड्स को आंशिक रूप से redact करें और roles के जरिए पहुँच सीमित करें।
प्रत्येक नोटिफिकेशन में trace IDs जोड़ें ताकि उसे ट्रिगर करने वाली क्रिया (checkout, admin update, वेबहुक) से जोड़ा जा सके। एक ही trace ID का उपयोग करें:
यह "क्या हुआ?" को कई-सिस्टम की खोज की बजाय एक फ़िल्टर्ड व्यू में बदल देता है।
डैशबोर्ड पर ध्यान निर्णयों पर रखें, vanity metrics पर नहीं:
चार्ट्स से drill-down जोड़ें ताकि हर मेट्रिक समझने योग्य हो और underlying message log तक पहुँचा जा सके।
नोटिफिकेशन हब ग्राहक डेटा, प्रोवाइडर क्रेडेंशियल्स, और संदेश सामग्री को छूता है—इसलिए सुरक्षा को डिज़ाइन में शामिल करें, न कि बाद में जोड़ें। लक्ष्य सरल है: केवल सही लोग व्यवहार बदल सकें, राज़ रहस्यों को सुरक्षित रखें, और हर परिवर्तन traceable हो।
एक छोटे सेट के रोल्स से शुरू करें और उन्हें उन कार्रवाइयों के साथ मैप करें जो मायने रखती हैं:
न्यूनतम-विशेषाधिकार (least privilege) डिफ़ॉल्ट्स का उपयोग करें: नए उपयोगकर्ताओं को तब तक नियम या क्रेडेंशियल्स संपादित करने की अनुमति न दें जब तक स्पष्ट रूप से प्रदान न की जाए।
प्रोवाइडर कीज़, वेबहुक साइनिंग सीक्रेट्स, और API टोकन्स को end-to-end सिक्योर तरीके से रखें:
हर कॉन्फ़िगरेशन परिवर्तन एक immutable audit इवेंट लिखे: किसने क्या बदला, कब, कहाँ (IP/device), और before/after मान (सीक्रेट फ़ील्ड्स masked)। राउटिंग नियम, टेम्पलेट्स, प्रोवाइडर कीज़, और अनुमति असाइनमेंट्स के परिवर्तन ट्रैक करें। CSV/JSON के रूप में सरल export दें ताकि अनुपालन समीक्षाएँ की जा सकें।
डेटा प्रकार (इवेंट्स, डिलीवरी प्रयास, कंटेंट, ऑडिट लॉग्स) के लिए रिटेंशन परिभाषित करें और UI में दस्तावेज़ करें। जहां लागू हो, हटाने के अनुरोधों का समर्थन करें — रिसीपियंट पहचानकर्ताओं को हटाना या अनोनिमाइज़ करना, जबकि aggregate डिलीवरी मैट्रिक्स और masked audit रिकॉर्ड रखना।
केंद्रीकृत नोटिफिकेशन हब की सफलता या विफलता उपयोगिता पर निर्भर करती है। अधिकतर टीमें रोज़ाना "नोटिफिकेशन्स प्रबंधित" नहीं करतीं—जब तक कुछ टूटे या किसी घटना का असर न हो। UI को तेज़ स्कैनिंग, सुरक्षित बदलाव, और स्पष्ट परिणाम के लिए डिज़ाइन करें।
Rules नीतियों की तरह पढ़ना चाहिए, कोड की तरह नहीं। एक तालिका उपयोग करें जो “IF event… THEN send…” वाक्यविन्यास पढ़ती हो, साथ में चैनल के चिप्स (Email/SMS/Push/Slack) और recipients दिखाएँ। एक simulator शामिल करें: एक इवेंट चुनें और देखें कि किसे क्या, कहाँ और कब मिलेगा।
Templates के लिए side-by-side editor और preview बेहतर रहते हैं। एडमिन को लोकल, चैनल और sample data toggle करने दें। टेम्पलेट वर्शनिंग और "publish" कदम दें, और one-click rollback।
Recipients व्यक्तिगत और समूह (teams, roles, segments) दोनों का समर्थन करें। सदस्यता दिखाएँ ("Alex On-call में क्यों है?") और जहाँ recipient किसी नियम में संदर्भित है वह दिखाएँ।
Provider health का at-a-glance डैशबोर्ड चाहिए: डिलीवरी latency, error rate, queue depth, और आख़िरी incident। हर इश्यू को मानव-पाठ्य स्पष्टीकरण और अगले कदमों के साथ लिंक करें (उदा., “Twilio auth failed—API key permissions चेक करें”)।
प्राथमिकताएँ हल्की रखें: चैनल opt-ins, quiet hours, और topic/category toggles (उदा., “Billing,” “Security,” “Product updates”)। ऊपर एक plain-language सारांश दिखाएँ ("आपको security alerts SMS पर कभी भी मिलेंगे")।
अनसब्सक्राइब फ्लोज़ सम्मानजनक और अनुपालन के अनुरूप रखें: मार्केटिंग के लिए one-click unsubscribe, और स्पष्ट संदेश जब critical alerts बंद नहीं किए जा सकते ("खाते की सुरक्षा के लिए आवश्यक")। यदि उपयोगकर्ता किसी चैनल को बंद करता है, तो पुष्टि करें कि क्या बदला ("अब SMS नहीं मिलेगा; ईमेल बना रहेगा")।
ऑपरेटरों को दबाव में सुरक्षित टूल चाहिए:
खाली अवस्थाएँ सेटअप मार्गदर्शित करें ("कोई नियम नहीं—अपना पहला राउटिंग नियम बनाएं") और अगला कदम लिंक करें (उदा., /rules/new)। त्रुटि संदेश बताएं कि क्या हुआ, क्या प्रभावित हुआ, और आगे क्या करना है—बिना आंतरिक शब्दजाल के। जहाँ संभव हो, एक त्वरित समाधान ("Reconnect provider") और support टिकट के लिए "copy details" बटन दें।
केंद्रीकृत नोटिफिकेशन हब बड़ा प्लेटफ़ॉर्म बन सकता है, पर इसे छोटे से शुरू करना चाहिए। MVP का लक्ष्य end-to-end फ्लो (इवेंट → राउट → टेम्पलेट → भेजना → ट्रैक) को सबसे कम घटकों के साथ साबित करना और फिर सुरक्षित रूप से विस्तार करना है।
यदि आप पहली कार्यरत प्रति तेज़ी चाहते हैं, तो Koder.ai जैसे vibe-coding प्लेटफ़ॉर्म आपकी मदद कर सकते हैं: React-based UI, Go backend with PostgreSQL जल्दी से स्टैंड अप करें—फिर planning mode, snapshots, और rollback का उपयोग करके नियम, टेम्पलेट और ऑडिट लॉग सुरक्षित रखें।
पहले रिलीज़ को जानबूझकर संकुचित रखें:
यह MVP यह साबित करना चाहिए: "क्या हम सही व्यक्ति को सही संदेश भरोसेमंद तरीके से भेज सकते हैं और यह देख सकते हैं कि क्या हुआ?"
नोटिफिकेशन्स उपयोगकर्ता-सामना और समय-संवेदनशील होते हैं, इसलिए automated tests जल्दी लाभ देती हैं। तीन क्षेत्रों पर ध्यान दें:
CI में sandbox प्रोवाइडर अकाउंट पर भेजने वाले कुछ end-to-end tests जोड़ें।
स्टेज्ड deployment का उपयोग करें:
एक बार स्थिर होने पर साफ़ चरणों में विस्तार करें: चैनल जोड़ें (SMS, पुश, इन-ऐप), समृद्ध राउटिंग, बेहतर टेम्पलेट टूलिंग, और गहरी एनालिटिक्स (डिलीवरी दरें, time-to-deliver, opt-out ट्रेंड)।
केंद्रीकृत नोटिफिकेशन प्रबंधन एक ऐसी एकल प्रणाली है जो इवेंट्स (जैसे invoice.paid) को इनजेस्ट करती है, प्राथमिकताओं और राउटिंग नियमों को लागू करती है, चैनल के अनुसार टेम्पलेट रेंडर करती है, प्रोवाइडर्स (ईमेल/SMS/push/आदि) के जरिए डिलीवरी करती है और अंत से अंत तक परिणाम रिकॉर्ड करती है.
यह ad-hoc “यहाँ ईमेल भेजो” वाले लॉजिक की जगह एक सुसंगत पाइपलाइन ले आता है जिसे आप ऑपरेट और ऑडिट कर सकते हैं।
प्रारम्भिक संकेत जिनसे पता चलता है कि आपके प्रोडक्ट को नोटिफिकेशन हब की ज़रूरत है:
यदि ये समस्याएँ बार-बार हो रही हैं, तो हब जल्दी ही लागत बचा सकता है।
पहले उन छोटे-से-चैनलों से शुरू करें जिन्हें आप भरोसेमंद रूप से चला सकते हैं:
"बाद में" आने वाले चैनलों को डॉक्यूमेंट करें (Slack/Teams, वेबहुक, WhatsApp) ताकि आपका डेटा मॉडल बाद में विस्तारित हो सके, पर MVP में उन्हें न जोड़ें।
एक व्यावहारिक MVP सादगी के साथ पूरा लूप (इवेंट → रूट → टेम्पलेट → डिलिवर → ट्रैक) प्रमाणित करे:
queued/sent/failed स्टेटस होंलक्ष्य भरोसेमंदता और अवलोकनीयता है, फीचर की चौड़ाई नहीं।
नोटिफिकेशन के लिए छोटा, स्पष्ट इवेंट कॉन्ट्रैक्ट उपयोग करें ताकि राउटिंग और टेम्पलेट अनुमान पर निर्भर न हों:
event_name (स्थिर)actor (जिसने ट्रिगर किया)recipient (जिसके लिए है)Idempotency डुप्लिकेट नोटिफिकेशन्स रोकती है जब प्रोड्यूसर्स retry करते हैं या हब स्वयं retry करता है.
व्यवहारिक तरीका:
idempotency_key अनिवार्य करें (उदा., invoice_123_paid)यह मल्टी-चैनल और retry-heavy फ्लोज़ में विशेष रूप से महत्वपूर्ण है।
पहचान और संपर्क बिंदुओं को अलग रखें:
प्रति recipient verification status (unverified/verified/blocked) ट्रैक करें और प्राथमिकताओं के लिए लेयर्ड डिफ़ॉल्ट्स (org → team → user → recipient) लागू करें।
दिन एक से ही निम्न चीज़ें लागू करें और इन्हें ऑडिटेबल बनाएं:
एक सिंगल exportable view रखें ताकि सपोर्ट यह बता सके "मुझे यह क्यों मिला/नही मिला"।
विभिन्न प्रोवाइडर्स के परिणामों को एक सुसंगत आंतरिक स्टेट मशीन में सामान्यीकृत करें:
queued, sent, delivered, failed, bounced, suppressed, throttledत्रुटियों से बचाने के लिए सुरक्षित संचालन पैटर्न और गार्डरैइल्स का उपयोग करें:
हर चीज़ immutable audit logs के साथ सपोर्ट करें — किसने क्या और कब बदला।
payload (बिजनेस फील्ड्स जिनकी संदेश के लिए ज़रूरत है)metadata (tenant, timestamp, source, locale hints)schema_version और एक idempotency key जोड़ें ताकि retries डुप्लिकेट न बनाएँ।
डिबग के लिए raw provider responses स्टोर करें, पर डैशबोर्ड और अलर्ट्स normalized statuses पर आधारित हों। स्टेटस को टाइमलाइन के रूप में मानें—एक संदेश प्रयास कई status updates भेज सकता है।