लक्ष्य और अपनाने के संकेत परिभाषित करें
ग्राहक अपनाने के हेल्थ स्कोर को बनाने से पहले तय करें कि यह स्कोर बिजनेस के लिए क्या करेगा. चर्न रिस्क अलर्ट ट्रिगर करने वाला स्कोर उन स्कोर्स से अलग दिखेगा जो ऑनबोर्डिंग, ग्राहक शिक्षा, या प्रोडक्ट सुधार के लिए मार्गदर्शन देने के लिए हैं।
अपने प्रोडक्ट के लिए “अपनाना” क्या है, परिभाषित करें
अपनाना सिर्फ़ "हाल ही में लॉग इन किया" नहीं होता। उन कुछ व्यवहारों को लिखें जो सच्च में दर्शाते हैं कि ग्राहक वैल्यू पा रहा है:
- Activation: वह पहला क्षण जब यूज़र मायने रखनी वाली उपलब्धि प्राप्त करता है (उदा., “टीममेट को आमंत्रित किया”, “डेटा स्रोत कनेक्ट किया”, “रिपोर्ट प्रकाशित किया”).
- Core actions: दोहराने योग्य, हाई-सिग्नल व्यवहार जो सफल खातों से जुड़े होते हैं (उदा., साप्ताहिक एक्सपोर्ट, ऑटोमेशन रन, एक से अधिक उपयोगकर्ताओं द्वारा देखे गए डैशबोर्ड)।
- Retention: आपके प्रोडکٹ के लिए सही आवृत्ति पर लगातार उपयोग (डेली/वीकली/मंथली), आदर्श रूप से खाते में एक से अधिक उपयोगकर्ता द्वारा।
ये आपकी शुरुआती adoption signals बनेंगे फीचर उपयोग एनालिटिक्स और बाद की कोहोर्ट एनालिसिस के लिए।
तय करें कि आपके ऐप से कौन-से निर्णय लिए जाने चाहिए
स्पष्ट रूप से लिखें कि स्कोर बदलने पर क्या होगा:
- कोई थ्रेशहोल्ड से नीचे गिरने पर किसे नोटिफाई किया जाएगा?\n- कौन-से प्लेबुक लॉन्च होने चाहिए (आउटरीच, ट्रेनिंग, सपोर्ट चेक-इन)?\n- कौन-सी इनसाइट्स प्रोडक्ट अपनाने की मॉनिटरिंग को सूचित करेंगी (फ्रिक्शन पॉइंट्स, कम उपयोग वाले फीचर, time-to-value)?
अगर आप कोई निर्णय नामित नहीं कर सकते, तो अभी उस मीट्रिक को ट्रैक मत करें।
उपयोगकर्ता, भूमिकाएँ और टाइम विंडो पहचानें
क्लियर करें कि कस्टमर सक्सेस डैशबोर्ड किसके द्वारा इस्तेमाल होगा:
- CS मैनेजर को प्राथमिकता और अकाउंट संदर्भ चाहिए।
- प्रोडक्ट को पैटर्न, कोहोर्ट, और फीचर-स्तर मूवमेंट चाहिए।
- सपोर्ट को टिकट्स और घटनाओं के आसपास हालिया गतिविधि चाहिए।
- लीडरशिप को समझने योग्य रोल-अप और ट्रेंड चाहिए।
मानक विंडोज चुनें—पिछले 7/30/90 दिन—और लाइफसाइकल स्टेज (ट्रायल, ऑनबोर्डिंग, स्थिर-स्टेट, रीन्यूवल) पर विचार करें। इससे नया अकाउंट किसी परिपक्व अकाउंट से तुलना नहीं होगा।
सफलता मानदंड सेट करें
अपने हेल्थ स्कोर मॉडल के लिए “डन” परिभाषित करें:
- Accuracy: क्या यह आपकी मौजूदा अप्रोच से रिस्क और एक्सपैंशन संकेत बेहतर प्रिडिक्ट करता है?\n- Explainability: क्या एक CSM एक मिनट में बता सकता है कि स्कोर हाई/लो क्यों है?\n- Ease of use: क्या यह समय बचाता है और लगातार एक्शन ड्राइव करता है?
ये लक्ष्य आगे की सभी चीज़ों को आकार देते हैं: इवेंट ट्रैकिंग, स्कोरिंग लॉजिक, और उन वर्कफ़्लोज़ को जो आप स्कोर के आस-पास बनाते हैं।
अपने हेल्थ स्कोर के लिए मीट्रिक्स चुनें
मीट्रिक्स चुनना वह स्थान है जहाँ आपका हेल्थ स्कोर या तो सहायक संकेत बनता है या शोर भरा नंबर। कुछ ही संकेतों के लिए लक्ष्य रखें जो असली अपनाने को दर्शाते हों—सिर्फ़ एक्टिविटी नहीं।
प्रोडक्ट अपनाने के संकेतों से शुरू करें
ऐसे मीट्रिक्स चुनें जो दिखाएँ कि उपयोगकर्ता बार-बार वैल्यू पा रहे हैं:
- Logins / active users: उदाहरण के लिए साप्ताहिक सक्रिय उपयोगकर्ता (WAU) और पिछले 4–8 हफ्तों का ट्रेंड।\n- Active days: किसी सप्ताह/माह में खाते के कितने अलग-अलग दिन सक्रिय थे (यह “एक बड़ा सत्र” फाल्स पॉज़िटिव को रोकता है)।\n- Feature depth: आपके “वैल्यू फीचर्स” का उपयोग—हर बटन क्लिक नहीं।\n- Integrations connected: खासकर जब इंटीग्रेशन स्विचिंग कॉस्ट बढ़ाते हैं या प्रमुख वर्कफ़्लो खोलते हैं।\n- Seat utilization: खरीदी गई सीटों का प्रतिशत जो इनवाइटेड, एक्टिवेटेड और वास्तव में सक्रिय है।
लिस्ट को फ़ोकस्ड रखें। अगर आप किसी मीट्रिक का एक वाक्य में कारण नहीं समझा सकते, तो वह शायद कोर इनपुट नहीं है।
बिजनेस संदर्भ जोड़ें (ताकि स्कोर अनुचित न हो)
अपनाने की व्याख्या संदर्भ में की जानी चाहिए। 3-सीट टीम का व्यवहार 500-सीट रोलआउट से अलग होगा।
आम संदर्भ संकेत:
- Plan tier और फीचर एंटाइटलमेंट्स\n- Contract size / ARR band\n- Lifecycle stage: ट्रायल बनाम नया-पेड बनाम रीन्यूवल विंडो
ये पॉइंट्स जरूरी नहीं कि “पॉइंट्स जोड़ें”, पर वे आपको सेगमेंट के अनुसार वास्तविक अपेक्षाएँ और थ्रेशहोल्ड सेट करने में मदद करते हैं।
लीडिंग बनाम लैगिंग इंडिकेटर्स तय करें
एक उपयोगी स्कोर मिश्रित होना चाहिए:
- Leading indicators (भविष्य की सफलता की भविष्यवाणी करते हैं): सक्रिय दिनों में वृद्धि, ऑनबोर्डिंग पूरा होना, पहला इंटीग्रेशन कनेक्ट होना।\n- Lagging indicators (परिणामों की पुष्टि करते हैं): रीन्यूवल, विस्तार, दीर्घकालिक रिटेंशन।
लैगिंग मीट्रिक्स पर ओवर-वेटिंग से बचें; वे सिर्फ़ बतलाते हैं कि क्या पहले ही हुआ था।
वैकल्पिक: गुणात्मक इनपुट्स (सावधानी से उपयोग करें)
यदि आपके पास हैं, तो NPS/CSAT, सपोर्ट टिकट वॉल्यूम, और CSM नोट्स सूक्ष्मता जोड़ सकते हैं। इन्हें मोडिफायर या फ्लैग के रूप में उपयोग करें—इन पर निर्भर बेस नहीं बनाएँ, क्योंकि गुणात्मक डेटा sparse और सब्जेक्टिव हो सकता है।
एक सरल डेटा डिक्शनरी बनाएं
चार्ट बनाने से पहले नामों और परिभाषाओं पर सहमति करें। एक हल्की डेटा डिक्शनरी में यह शामिल होना चाहिए:
- मीट्रिक नाम (उदा.,
active_days_28d)\n- स्पष्ट परिभाषा (क्या गिना जाएगा, क्या नहीं)\n- टाइम विंडो और रिफ्रेश कैडेंस\n- सोर्स सिस्टम (प्रोडक्ट इवेंट्स, CRM, सपोर्ट)
यह बाद में "एक ही मीट्रिक, अलग मतलब" की उलझन रोकता है जब आप डैशबोर्ड और अलर्ट लागू करते हैं।
एक समझ में आने वाला हेल्थ स्कोर मॉडल डिज़ाइन करें
एक अपनाने का स्कोर तब ही काम करेगा जब आपकी टीम उस पर भरोसा करे। लक्ष्य यह हो कि आप इसे एक CSM को एक मिनट में और ग्राहक को पांच मिनट में समझा सकें।
सरल से शुरू करें: वेटेड पॉइंट्स (ML से पहले)
شفर कीजिए एक पारदर्शी, रूल-बेस्ड स्कोर से। कुछ अपनाने के संकेत चुनें (जैसे एक्टिव यूज़र्स, प्रमुख फीचर उपयोग, सक्षम इंटीग्रेशन) और उन संकेतों को ऐसे वज़न दें जो आपके प्रोडक्ट के “आहा” क्षणों को दर्शाएँ।
उदाहरण वेटिंग:
- Weekly active users per seat: 0–40 points\n- Key feature usage frequency: 0–35 points\n- Breadth of features used: 0–15 points\n- Time since last meaningful activity: 0–10 points
वज़न तर्कसंगत और बचावयोग्य रखें। बाद में आप इन्हें पुनः देख सकते हैं—पूर्ण मॉडल के इंतजार में मत रुकें।
बायस कम करने के लिए नॉर्मलाइज़ करें
कच्चे काउंट छोटे खातों को दंडित करते हैं और बड़े को फ्लैट कर देते हैं। जहाँ जरूरी हो मीट्रिक्स नॉर्मलाइज़ करें:
- प्रति सीट (usage / licensed seats)\n- अकाउंट आयु के अनुसार (नए बनाम परिपक्व खाते)\n- प्लान टियर द्वारा (फीचर उपलब्धता)
यह मदद करता है कि आपका ग्राहक अपनाने का हेल्थ स्कोर व्यवहार को दिखाए, सिर्फ़ साइज नहीं।
हरा/पीला/लाल साफ़ कारणों के साथ परिभाषित करें
थ्रेशहोल्ड सेट करें (उदा., Green ≥ 75, Yellow 50–74, Red < 50) और दस्तावेज़ करें कि प्रत्येक कटऑफ क्यों है। थ्रेशहोल्ड्स को अपेक्षित परिणामों (रीन्यूवल रिस्क, ऑनबोर्डिंग पूरा होना, एक्सपैंशन तैयारी) से लिंक करें, और नोट्स अपने आंतरिक डॉक्स या /blog/health-score-playbook में रखें।
इसे समझने योग्य बनाएं: योगदानकर्ता और ट्रेंड
हर स्कोर में दिखना चाहिए:
- शीर्ष 3 योगदानकर्ता (क्या मदद कर रहा/नुकसान पहुँचाया)\n- समय के साथ परिवर्तन (पिछले 7/30 दिन)\n- एक आसान-भाषा सारांश ("Feature X उपयोग सप्ताह-दर-सप्ताह 35% घटा")
इटरैशन की योजना बनाएं: मॉडल वर्ज़निंग
स्कोरिंग को एक प्रोडक्ट की तरह माना जाए। वर्ज़न करें (v1, v2) और प्रभाव ट्रैक करें: क्या चर्न रिस्क अलर्ट ज़्यादा एक्यूरेट हुए? क्या CSMs तेज़ी से एक्शन लेते हैं? हर कैलकुलेशन के साथ स्कोर वर्ज़न स्टोर करें ताकि आप समय के साथ परिणामों की तुलना कर सकें।
प्रोडक्ट इवेंट्स और डेटा सोर्सेस इंस्ट्रूमेंट करें
एक हेल्थ स्कोर उतना ही भरोसेमंद होगा जितना कि उसके पीछे की गतिविधि डेटा। स्कोरिंग लॉजिक बनाने से पहले पुष्टि करें कि सही संकेत लगातार सिस्टम्स में कैप्चर हो रहे हैं।
अपने इवेंट सोर्स चुनें
अधिकांश अपनाने प्रोग्राम मिश्रण से खींचते हैं:
- Frontend events (पेज व्यूज़, क्लिक, फीचर इंटरैक्शन)\n- Backend actions (API कॉल, जॉब्स कंप्लीट, रिकॉर्ड्स बनाए गए)\n- Billing (प्लान, रीन्यूअल, पेमेंट स्टेटस, सीट काउंट)\n- Support and success tools (टिकट्स, CSAT, ऑनबोर्डिंग माइलस्टोन्स)
एक व्यावहारिक नियम: क्रिटिकल एक्शन्स सर्वर-साइड ट्रैक करें (स्पूफ करना कठिन, ad blockers से कम प्रभावित) और UI एंगेजमेंट व डिस्कवरी के लिए फ्रंटेंड इवेंट्स का उपयोग करें।
एक स्पष्ट इवेंट स्कीमा परिभाषित करें
संगत कॉन्ट्रैक्ट रखें ताकि इवेंट्स आसानी से जोड़े, क्वेरी और स्टेकहोल्डर्स को समझाए जा सकें। एक सामान्य बेसलाइन:
event_name\n- user_id\n- account_id\n- timestamp (UTC)\n- properties (feature, plan, device, workspace_id, आदि)
event_name के लिए नियंत्रित शब्दावली (उदा., project_created, report_exported) का उपयोग करें और इसे एक साधारण tracking plan में दस्तावेज़ करें।
SDK vs server-side (या दोनों) पर फैसला करें
- SDK tracking जल्दी शिप करने के लिए अच्छा और UI इवेंट्स के लिए उपयुक्त।\n- Server-side tracking सिस्टम-ऑफ़-रिकार्ड क्रियाओं के लिए बेहतर।
कई टीमें दोनों करती हैं, पर सुनिश्चित करें कि आप एक ही वास्तविक-वर्ल्ड एक्शन को डबल-काउंट न करें।
पहचान को सही तरीके से हैंडल करें
हेल्थ स्कोर सामान्यतः account लेवल पर रोल-अप करते हैं, इसलिए भरोसेमंद user→account मैपिंग चाहिए। इसके लिए योजना बनाएं:
- कई खातों से जुड़े उपयोगकर्ता\n- अकाउंट मर्जेस (अधिग्रहण, वर्कस्पेस कंसोलिडेशन)\n- प्री-लॉगिन व्यवहार के लिए अनामकृत IDs (सुरक्षित मर्ज के साथ साइनअप के बाद)
डेटा क्वालिटी चेक जोड़ें
कम से कम, मिसिंग इवेंट्स, डुप्लिकेट बर्स्ट्स, और टाइमज़ोन कंसिस्टेंसी (UTC में स्टोर करें; डिस्प्ले के लिए कन्वर्ट करें) की निगरानी करें। अनियमितताओं को जल्दी फ़्लैग करें ताकि आपका चर्न रिस्क अलर्टिंग ट्रैकिंग ब्रेक होने पर नहीं चल पड़े।
अपने डेटा और स्टोरेज को मॉडल करें
एक ग्राहक अपनाने हेल्थ स्कोर ऐप "किसने क्या किया, और कब" को कितनी अच्छी तरह मॉडल करता है, उसी पर ज़िंदा रहता या मरता है। लक्ष्य आम सवालों का तेज़ उत्तर देना है: इस सप्ताह यह अकाउंट कैसा कर रहा है? कौन से फीचर्स ऊपर या नीचे ट्रेंड कर रहे हैं? अच्छा डेटा मॉडलिंग स्कोरिंग, डैशबोर्ड और अलर्ट को सरल रखती है।
मॉडल करने के लिए कोर एंटिटीज
एक छोटी सेट "सोर्स ऑफ़ ट्रुथ" टेबल्स से शुरू करें:
- Accounts: account_id, plan, segment, lifecycle stage, CSM owner\n- Users: user_id, account_id, role/persona, created_at, status\n- Subscriptions (या contracts): account_id, start/end, seats, MRR, renewal date\n- Features: feature_id, name, category (activation, collaboration, admin, आदि)\n- Events: event_id, account_id, user_id, feature_id (nullable), event_name, timestamp, properties\n- Scores: account_id, score_date (या computed_at), overall_score, component scores, explanation fields
इन एंटिटीज़ को हर जगह स्थिर IDs (account_id, user_id) का उपयोग करके सुसंगत रखें।
स्टोरेज विभाजन: रिलेशनल + एनालिटिक्स
रिलेशनल डेटाबेस (उदा., Postgres) का उपयोग accounts/users/subscriptions/scores के लिए करें—ऐसी चीज़ें जिन्हें आप अक्सर अपडेट और जोइन करते हैं।\n
हाई-वॉल्यूम events को एक वेयरहाउस/एनालिटिक्स स्टोर (उदा., BigQuery/Snowflake/ClickHouse) में स्टोर करें। इससे डैशबोर्ड और कोहोर्ट एनालिसिस रिस्पॉन्सिव रहते हैं बिना ट्रांज़ैक्शनल DB को ओवरलोड किए।
गति के लिए एग्रीगेट्स स्टोर करें
रॉ इवेंट्स से हर बार सब कुछ रीकैल्कुलेट करने की बजाय, बनाए रखें:
- Daily account summaries (प्रति दिन प्रति अकाउंट एक रो): active users, key event counts, last activity, adoption milestones\n- Feature counters: प्रति अकाउंट/दिन/फीचर उपयोग काउंट्स, यूनिक यूज़र्स, समय बिताया (यदि उपलब्ध)
ये तालिकाएँ ट्रेंड चार्ट, “क्या बदला” इनसाइट्स, और हेल्थ स्कोर कंपोनेंट्स को पॉवर करती हैं।
रिटेंशन, पार्टिशनिंग, और क्वेरी प्रदर्शन
बड़े इवेंट टेबल्स के लिए रिटेंशन प्लान करें (उदा., 13 महीने रॉ, एग्रीगेट्स के लिए लंबा) और तारीख़ से पार्टिशन करें। account_id और timestamp/date द्वारा क्लस्टर/इंडेक्स करें ताकि “account over time” क्वेरीज तेज़ हों।
रिलेशनल टेबल्स में सामान्य फ़िल्टर और जोइन के लिए इंडेक्स लगाएँ: account_id, (account_id, date) पर summaries, और foreign keys डेटा को साफ़ रखने के लिए।
वेब ऐप आर्किटेक्चर की योजना बनाएं
हेल्थ स्कोर v1 लॉन्च करें
स्कैफोल्डिंग की बजाय चैट से अपने हेल्थ स्कोर विचारों को काम करने वाले डैशबोर्ड में बदलें।
आपकी आर्किटेक्चर को ऐसा होना चाहिए कि आप भरोसेमंद v1 जल्दी शिप कर सकें और बिना री-राइट के बढ़ सकें। शुरू में तय करें कि आपको वास्तव में कितने मूविंग पार्ट्स चाहिए।
मोनोलिथ vs सर्विसेज (v1 को सरल रखें)
अधिकतर टीमों के लिए मॉड्यूलर मोनोलिथ सबसे तेज़ रास्ता है: एक कोडबेस जिसमें स्पष्ट सीमाएँ हों (ingestion, scoring, API, UI), एक डिप्लॉयेबल, और कम ऑपरेशनल सरप्राइज़।
सिर्फ़ तब सर्विसेज की ओर बढ़ें जब आपके पास स्पष्ट कारण हो—स्वतंत्र स्केलिंग की ज़रूरत, कड़ी डेटा अलगाव, या अलग टीमें जो घटकों का प्रबंधन करती हों। अन्यथा, पूर्व-समय पर सर्विसेज बढ़ने से फेलियर पॉइंट्स बढ़ते और इटरेशन धीमा होता है।
कोर कंपोनेंट्स को परिभाषित करें
कम से कम इन जिम्मेदारियों की योजना बनाएं (यहाँ तक कि अगर ये सभी एक ऐप में हों):
- Ingestion: प्रोडक्ट इवेंट्स स्वीकार करता है (SDK, Segment, webhook, batch imports).\n- Aggregation: रॉ इवेंट्स को दैनिक/साप्ताहिक उपयोग तथ्य में बदलता है प्रति अकाउंट/यूज़र।\n- Scoring: ग्राहक अपनाने का हेल्थ स्कोर और सहायक व्याख्याएँ कंप्यूट करता है।\n- API: स्कोर, ट्रेंड और "क्यों" इनसाइट्स UI और इंटीग्रेशंस को सर्व करता है।\n- UI: कस्टमर सक्सेस डैशबोर्ड जिसमें अकाउंट व्यूज़, कोहोर्ट्स और ड्रिल-डाउन हों।
त्वरित प्रोटोटाइप के लिए, एक vibe-coding दृष्टिकोण आपको वर्कफ़्लो के बिना जल्दी से कार्यशील डैशबोर्ड तक पहुंचने में मदद कर सकता है। उदाहरण के लिए, Koder.ai एक React-आधारित वेब UI और Go + PostgreSQL बैकएंड जनरेट कर सकता है आपकी एंटिटीज़ (accounts, events, scores), एन्डपॉइंट्स, और स्क्रीन के सरल चैट विवरण से—v1 खड़ा करने के लिए उपयोगी ताकि आपकी CS टीम जल्दी प्रतिक्रिया दे सके।
शेड्यूल्ड जॉब्स vs स्ट्रीमिंग
ब्याच स्कोरिंग (उदा., हर घंटे/रोज़) आमतौर पर अपनाने की मॉनिटरिंग के लिए काफी है और ऑपरेट करने में काफी सरल है। यदि आपको near-real-time अलर्ट्स चाहिए (जैसे अचानक उपयोग में गिरावट) या बहुत उच्च इवेंट वॉल्यूम है तो स्ट्रीमिंग मायने रखती है।
एक व्यावहारिक हाइब्रिड: इवेंट्स को लगातार इन्गेस्ट करें, एग्रीगेट/स्कोरिंग शेड्यूल पर करें, और छोटे सेट के लिए स्ट्रीमिंग रिज़र्व रखें जो तीव्र संकेत हैं।
एनवायरनमेंट्स, सीक्रेट्स, और नॉन-फंक्शनल जरूरतें
शुरू में dev/stage/prod सेट करें, स्टेज में नमूना अकाउंट्स सीड करें ताकि डैशबोर्ड मान्य हो सकें। मैनेज्ड सीक्रेट्स स्टोर का उपयोग करें और क्रेडेंशियल्स को रोटेट करें।
पहले से आवश्यकताएँ डॉक्यूमेंट करें: अपेक्षित इवेंट वॉल्यूम, स्कोर फ्रेशनेस (SLA), API लेटेंसी टार्गेट्स, उपलब्धता, डेटा रिटेंशन, और प्राइवेसी सीमाएँ (PII हैंडलिंग और एक्सेस कंट्रोल)। इससे आर्किटेक्चर निर्णय देर से दबाव में लिए जाने से बचें।
डेटा पाइपलाइन और स्कोरिंग जॉब्स बनाएं
आपका हेल्थ स्कोर उसी पाइपलाइन जितना भरोसेमंद होगा जो इसे पैदा करती है। स्कोरिंग को एक प्रोडक्शन सिस्टम की तरह ट्रीट करें: पुनरुत्पादन योग्य, ऑब्ज़र्वेबल, और आसान समझ के लिए जब कोई पूछे, “आज इस खाते का स्कोर क्यों गिरा?”
एक सरल पाइपलाइन: raw → validated → aggregates
एक स्टेज्ड फ्लो से शुरू करें जो डेटा को संकुचित करता है ताकि आप इसे सुरक्षित रूप से स्कोर कर सकें:
- Raw events: आपके ऐप, मोबाइल, इंटीग्रेशंस, और बिलिंग/CRM एक्सपोर्ट्स से एप्पेंड-ओनली इन्गेस्ट।\n- Validated events: ऐसे इवेंट्स जो स्कीमा चेक पास करते हैं (आवश्यक फील्ड, सही प्रकार), पहचान चेक (user → account मैपिंग), और डुप्लिकेशन हटाना।\n- Daily aggregates: अकाउंट द्वारा रोल-अप जैसे active users, key event counts, last activity, adoption milestones
यह संरचना आपके स्कोरिंग जॉब्स को तेज़ और स्थिर रखती है, क्योंकि वे क्लीन, कॉम्पैक्ट तालिकाओं पर चलते हैं बजाय अरबों रॉ पंक्तियों के।
पुनर्गणना शेड्यूल और बैकफिल्स
निर्धारित करें कि स्कोर कितना "ताज़ा" होना चाहिए:
- Hourly स्कोरिंग हाई-टच मोशन्स के लिए जहाँ CSMs तेजी से कार्रवाई करते हैं।\n- Daily स्कोरिंग SMB/self-serve के लिए अक्सर काफी होती है और लागत कम रखती है।
शेड्यूलर को बैकफिल्स सपोर्ट करने लायक बनाएं (उदा., पिछले 30/90 दिन पुन:प्रसंस्करण) जब आप ट्रैकिंग ठीक करें, वेटिंग बदलें, या नया संकेत जोड़ें। बैकफिल्स को प्राथमिक-श्रेणी की सुविधा बनाएं, न कि आपातकालीन स्क्रिप्ट।
Idempotency: डबल-काउंटिंग से बचें
स्कोरिंग जॉब्स रीट्राय होंगे। इम्पोर्ट्स दोबारा चलेंगे। वेबहुक्स दो बार डिलीवर होंगे। इसके लिए डिज़ाइन करें।
इवेंट्स के लिए एक idempotency key का उपयोग करें (event_id या timestamp + user_id + event_name + properties का स्थिर हैश) और validated लेयर पर यूनिकनेस लागू करें। एग्रीगेट्स के लिए, (account_id, date) द्वारा upsert करें ताकि पुनर्गणना पिछला परिणाम रिप्लेस करे न कि जोड़ दे।
मॉनिटरिंग और एनॉमली चेक्स
ऑपरेशनल मॉनिटरिंग जोड़ें:
- Job success/failure और retry counts\n- Data lag (आपके लेटेस्ट एग्रीगेट्स कितना "अब" से पीछे हैं)\n- Volume anomalies (इवेंट्स में अचानक गिरावट/स्पाइक, सक्रिय उपयोगकर्ताओं में बदलाव)
यहाँ तक कि हल्की थ्रेशहोल्ड्स (उदा., "इवेंट्स 7-दिन औसत से 40% कम") भी चुपचाप ब्रेक होने से रोकती हैं जो कस्टमर सक्सेस डैशबोर्ड को गलत दिशा दिखा सकती हैं।
हर स्कोर के लिए ऑडिट ट्रेल्स
प्रति अकाउंट प्रति स्कोरिंग रन एक ऑडिट रिकॉर्ड स्टोर करें: इनपुट मीट्रिक्स, डेराइव्ड फीचर्स (जैसे सप्ताह-दर-सप्ताह परिवर्तन), मॉडल वर्ज़न, और फाइनल स्कोर। जब कोई CSM "क्यों?" क्लिक करे, आप ठीक दिखा सकेंगे कि क्या बदला और कब—लॉग्स से रिवर्स-इंजीनियर किए बिना।
हेल्थ और इनसाइट्स के लिए एक सुरक्षित API बनाएं
साथ मिलकर बनाएं
ड्राइवर्स और थ्रेशहोल्ड्स को परिष्कृत करते हुए प्रोडक्ट और CS के साथ एक ही ऐप पर सहयोग करें।
आपका वेब ऐप अपने API पर ही जिंदा रहता है। यह आपके स्कोरिंग जॉब्स, UI, और किसी भी डाउनस्ट्रीम टूल्स (CS प्लेटफार्म, BI, डेटा एक्सपोर्ट्स) के बीच अनुबंध है। तेज़, प्रत्याश्य योग्य और डिफ़ॉल्ट रूप से सुरक्षित API का लक्ष्य रखें।
वास्तविक वर्कफ़्लोज़ का समर्थन करने वाले कोर एन्डपॉइंट्स
कस्टमर सक्सेस की खोज-बीन कैसे करती है उसके इर्द-गिर्द एन्डपॉइंट डिज़ाइन करें:
- Account health:
GET /api/accounts/{id}/health लेटेस्ट स्कोर, स्टेटस बैंड (उदा., Green/Yellow/Red), और आख़िरी कैलकुलेशन टाइमस्टैम्प लौटाता है।\n- Trends: GET /api/accounts/{id}/health/trends?from=&to= स्कोर ओवर टाइम और की मीट्रिक डेल्टाज़ के लिए।\n- Drivers (“why”): GET /api/accounts/{id}/health/drivers शीर्ष सकारात्मक/नकारात्मक फैक्टर्स दिखाने के लिए।\n- Cohorts: GET /api/cohorts/health?definition= कोहोर्ट एनालिसिस और पीयर बेंचमार्क के लिए।\n- Exports: POST /api/exports/health CSV/Parquet जेनरेट करने के लिए निरंतर स्कीम के साथ।
फ़िल्टरिंग, पेजिनेशन, और कैशिंग
लिस्ट एन्डपॉइंट्स को स्लाइस करना आसान बनाएं:
- फ़िल्टर्स:
plan, segment, csm_owner, lifecycle_stage, और date_range मूलभूत हैं।\n- पेजिनेशन: करसर-आधारित पेजिनेशन (cursor, limit) उपयोग करें ताकि डेटा बदलते समय स्थिरता बनी रहे।\n- कैशिंग: भारी क्वेरीज (कोहोर्ट रोलअप, ट्रेंड सीरीज़) को कैश करें और ETag/If-None-Match लौटाएँ ताकि रिपीट लोड्स घटें। कैश कीज़ को फ़िल्टर और परमिशन्स के प्रति जागरूक रखें।
रोल-आधारित एक्सेस कंट्रोल (RBAC) से सुरक्षा
डेटा को अकाउंट-लेवल पर सुरक्षित रखें। हर एन्डपॉइंट पर RBAC लागू करें (उदा., Admin, CSM, Read-only)। एक CSM को केवल उन्हीं खातों को देखना चाहिए जिनके वह मालिक हैं; फाइनेंस रोल प्लान-स्तर एग्रीगेट्स देख सकता है पर उपयोगकर्ता-स्तर विवरण नहीं।
हमेशा समझाने योग्य परिणाम लौटाएँ
संख्यात्मक customer adoption health score के साथ "क्यों" फील्ड्स लौटाएँ: शीर्ष ड्राइवर, प्रभावित मीट्रिक्स, और तुलना बेसलाइन (पिछला पीरियड, कोहोर्ट मीडियन)। यह product adoption monitoring को सिर्फ रिपोर्टिंग नहीं, बल्कि एक्शन में बदल देता है और आपका customer success dashboard भरोसेमंद बनाता है।
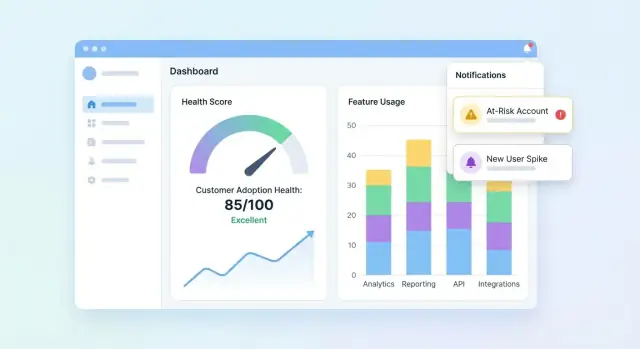
डैशबोर्ड और अकाउंट व्यू डिज़ाइन करें
आपका UI तीन सवाल जल्दी हल कर दे: कौन हेल्दी है? कौन गिर रहा है? क्यों? एक पोर्टफोलियो सारांश वाला डैशबोर्ड से शुरू करें, फिर उपयोगकर्ताओं को अकाउंट ड्रिल-इन करने दें ताकि स्कोर के पीछे की कहानी समझ सकें।
पोर्टफोलियो डैशबोर्ड अनिवार्य
कस्टमर सक्सेस टीमें सेकंडों में स्कैन कर सकें ऐसी टाइल्स और चार्ट्स शामिल करें:
- Score distribution (हिस्टोग्राम या बकेट्स जैसे Healthy / Watch / At-risk)\n- At-risk list सिर्फ़ आवश्यक फ़ील्ड्स के साथ (account, owner, score, last activity, top driver)\n- Score trend over time (लाइन चार्ट) सेगमेंट फ़िल्टरिंग के विकल्प के साथ
At-risk लिस्ट को क्लिक करने योग्य बनाएं ताकि यूज़र अकाउंट खोल कर तुरंत देख सके कि क्या बदला।
अकाउंट व्यू: स्कोर को समझाएँ
अकाउंट पेज को अपनाने की टाइमलाइन की तरह बनाएं:
- Timeline: प्रमुख घटनाएँ (ऑनबोर्डिंग स्टेप्स पूरे, इंटीग्रेशन जुड़े, एडमिन चेंजेस, बड़ा फीचर पहली बार प्रयोग)\n- Key metrics: active users, key feature actions, last meaningful activity से कितना समय हुआ\n- Feature adoption breakdown: किस फीचर को अपनाया गया, अनदेखा किया गया, या घट रहा है
"Why this score?" पैनल जोड़ें: स्कोर पर क्लिक करने से योगदान संकेत (पॉज़िटिव और नेगेटिव) plain-language में दिखें।
कोहोर्ट और सेगमेंट व्यू
कोहोर्ट फ़िल्टर्स प्रदान करें जो टीमों के अकाउंट प्रबंधन से मेल खाते हों: onboarding cohorts, plan tiers, और industries। हर कोहोर्ट के साथ ट्रेंड लाइन्स और टॉप मूवर्स की छोटी टेबल जोड़े ताकि टीमें परिणामों की तुलना कर सकें और पैटर्न पहचान सकें।
पहुँच योग्य, भरोसेमंद विज़ुअल्स
साफ़ लेबल और यूनिट्स उपयोग करें, अस्पष्ट आइकन से बचें, और color-safe status indicators (उदा., टेक्स्ट लेबल + शेप्स) दें। चार्ट्स को निर्णय टूल के रूप में ट्रीट करें: स्पाइक्स को एनोटेट करें, डेट रेंज दिखाएँ, और ड्रिल-डाउन व्यवहार पेजों में सुसंगत रखें।
अलर्ट्स, टास्क, और वर्कफ़्लोज़ जोड़ें
एक हेल्थ स्कोर तभी उपयोगी है जब वह एक्शन ड्राइव करे। अलर्ट्स और वर्कफ़्लोज़ "दिलचस्प डेटा" को समय रहते आउटरीच, ऑनबोर्डिंग फिक्स, या प्रोडक्ट नज में बदल देते हैं—बिना टीम को लगातार डैशबोर्ड देखने के दबाव में डाले।
वास्तविक रिस्क से मेल खाने वाले अलर्ट नियम परिभाषित करें
छोटे, हाई-सिग्नल ट्रिगर्स से शुरू करें:
- Score drops (उदा., सप्ताह-दर-सप्ताह 15 अंक की गिरावट)\n- Red status (एक महत्वपूर्ण थ्रेशहोल्ड पार होना)\n- Sudden usage decline (कुञ्जी फीचर उपयोग बेसलाइन से नीचे गिरना)\n- Failed onboarding step (स्टॉल्ड चेकलिस्ट आइटम, इंटीग्रेशन पूरा न होना)
हर नियम को स्पष्ट और समझाने योग्य बनाएं। "Bad health" की जगह "Feature X में 7 दिनों से कोई गतिविधि + ऑनबोर्डिंगIncomplete" जैसे अलर्ट करें।
चैनलों का चयन और उन्हें कॉन्फ़िगर करने योग्य रखें
टीमें अलग काम करती हैं, इसलिए चैनल सपोर्ट और प्राथमिकताएँ बनाएं:
- Email अकाउंट मालिकों और मैनेजर्स के लिए\n- Slack टीम विजिबिलिटी और तेज़ प्रतिक्रिया के लिए\n- In-app tasks आपके कस्टमर सक्सेस डैशबोर्ड के अंदर ताकि काम खो न जाए
हर टीम को कॉन्फ़िगर करने दें: किसे नोटिफाई करना है, कौन से नियम चालू हैं, और कौन से थ्रेशहोल्ड "urgent" माने जाएंगे।
शोर कम करने के लिए गार्ड्रेल्स
अलर्ट थकान अपनाने की निगरानी को मार देती है। नियंत्रण जोड़ें जैसे:
- Cooldown windows (एक ही अकाउंट पर N घंटों/दिनों तक फिर से अलर्ट न करें)\n- Minimum data thresholds (यदि अकाउंट के पास हालिया डेटा बहुत कम है तो अलर्ट स्किप करें)\n- Batching/digests गैर-जरूरी संकेतों के लिए (रोज़ाना/साप्ताहिक सार)
संदर्भ और अगले कदम जोड़ें
हर अलर्ट को बताना चाहिए: क्या बदला, क्यों मायने रखता है, और अगला कदम क्या है। हालिया स्कोर ड्राइवर, एक छोटी टाइमलाइन (उदा., पिछले 14 दिन), और सुझाए गए कार्य जैसे "ऑनबोर्डिंग कॉल शेड्यूल करें" या "इंटीग्रेशन गाइड भेजें" शामिल करें। अकाउंट व्यू से लिंक जोड़ें (उदा., /accounts/{id}).
परिणाम ट्रैक करें ताकि लूप बंद हो
अलर्ट्स को कार्य-आइटम की तरह ट्रीट करें जिनकी स्थिति हो: acknowledged, contacted, recovered, churned। आउटकम्स पर रिपोर्टिंग नियमों को परिष्कृत करने, प्लेबुक्स सुधारने, और साबित करने में मदद करती है कि हेल्थ स्कोर रिटेंशन पर वास्तविक प्रभाव डाल रहा है।
डेटा क्वालिटी, प्राइवेसी, और गवर्नेंस सुनिश्चित करें
कोडबेस पर पूरा नियंत्रण रखें
कस्टमाइज़ करने के लिए तैयार होने पर सोर्स कोड एक्सपोर्ट करके पूरा नियंत्रण रखें।
यदि आपका हेल्थ स्कोर अविश्वसनीय डेटा पर बना है, टीमें उस पर भरोसा खो देंगी—और उस पर कार्रवाई करना बंद कर देंगी। क्वालिटी, प्राइवेसी, और गवर्नेंस को फीचर की तरह ट्रीट करें, न कि बाद की सोच।
हर हैंडऑफ पर ऑटोमैटेड डेटा चेक लगाएँ
इंजेस्ट → वेयरहाउस → स्कोरिंग आउटपुट पर हल्के वेलिडेशन रखें। कुछ हाई-सिग्नल टेस्ट्स अधिकांश समस्याओं को जल्दी पकड़ लेते हैं:
- Schema checks: अपेक्षित कॉलम मौजूद हैं, प्रकार न बदले हों, enums वैध हों।\n- Range checks: असंभव मान (नेगेटिव सेशन्स, भविष्य की टाइमस्टैम्प) फेल करें।\n- Null checks: आवश्यक फील्ड्स (
account_id, event_name, occurred_at) खाली नहीं हो सकते।
जब टेस्ट फेल हों, स्कोरिंग जॉब ब्लॉक करें (या परिणामों को “stale” मार्क करें) ताकि टूटी पाइपलाइन बिना पता चले भ्रामक चर्न रिस्क अलर्ट न पैदा करे।
सामान्य एज केस स्पष्ट रूप से हैंडल करें
हेल्थ स्कोर "अजीब पर सामान्य" परिस्थितियों पर टूट जाता है। नियम परिभाषित करें:
- कम डेटा वाले नए खाते: "अपर्याप्त डेटा" दिखाएँ या रैंप-अप बेसलाइन उपयोग करें बजाय लो स्कोर के।\n- सीजनल उपयोग: सार्वभौमिक थ्रेशहोल्ड की जगह खाते के पिछले पीरियड या कोहोर्ट बेंचमार्क से तुलना करें।\n- आउटेज और ट्रैकिंग गैप्स: प्रभावित विंडोज़ को फ़्लैग करें और ग्राहक को आपकी डाउनटाइम के लिए दंडित न करें।
परमिशन्स और प्राइवेसी कंट्रोल जोड़ें
डिफ़ॉल्ट रूप से PII सीमित रखें: केवल वही स्टोर करें जो अपनाने की मॉनिटरिंग के लिए ज़रूरी हो। वेब ऐप में रोल-आधारित एक्सेस लागू करें, किसने देखा/एक्सपोर्ट किया इसे लॉग करें, और जब फील्ड्स आवश्यक न हों तो एक्सपोर्ट्स को redact करें (उदा., CSV डाउनलोड में ईमेल छुपाएँ)।
रनबुक्स और गवर्नेंस अभ्यास बनाएं
इंसिडेंट रिस्पॉन्स के लिए छोटे रनबुक लिखें: स्कोरिंग कैसे पॉज़ करें, बैकफिल डेटा कैसे करें, और ऐतिहासिक जॉब्स कैसे फिर चलाएँ। ग्राहक सक्सेस मीट्रिक्स और स्कोर वेट्स को नियमित रूप से—महीने या तिमाही—रीव्यू करें ताकि आपके प्रोडक्ट के बदलने पर ड्रिफ्ट न हो। प्रक्रिया का संरेखण करने के लिए अपनी आंतरिक चेकलिस्ट लिंक करें: /blog/health-score-governance।
हेल्थ स्कोर को वैलिडेट, इटरैट, और स्केल करें
वैद्युतीकरण वह स्थान है जहाँ हेल्थ स्कोर "अच्छा चार्ट" बंद होकर भरोसेमंद होकर कार्य चलाने लायक बनता है। अपने पहले वर्ज़न को हाइपोथेसिस मानें, अंतिम उत्तर नहीं।
पायलट चलाएँ और मानवीय निर्णय के साथ कैलिब्रेट करें
20–50 खातों के पायलट समूह के साथ शुरू करें। हर अकाउंट के लिए स्कोर और रिस्क कारण की तुलना अपने CSM के आकलन से करें।
पैटर्न देखें:
- स्कोर जो लगातार CSM न्याय से ऊपर/नीचे हैं (कैलिब्रेशन)\n- “False alarms” (उच्च रिस्क पर अकाउंट ठीक) बनाम “misses” (हेल्दी स्कोर पर अकाउंट चर्न)\n- कारण जो वास्तविकता से मेल नहीं खाते (explainability gaps)
यह वास्तव में उपयोगी है या नहीं, मापें
एक्यूरेसी मददगार है, पर उपयोगिता वही भुगतान दिलाती है। ऑपरेशनल आउटकम्स ट्रैक करें जैसे:
- Time-to-detect risk (कितनी जल्दी आप एक समस्या फ़्लैग करते हैं)\n- Outreach success rate (रीस्की अकाउंट्स में से कितने इंटरवेंशन के बाद सुधरते हैं)\n- Churn-reduction proxies (रीन्यूवल संभावना में बदलाव, एक्सपैंशन संकेत, सपोर्ट बर्डन में परिवर्तन)
वर्ज़निंग के साथ सुरक्षित परीक्षण करें
जब आप थ्रेशहोल्ड, वेट्स, या नए संकेत बदलते हैं, उन्हें नए मॉडल वर्ज़न के रूप में ट्रीट करें। वर्ज़न्स को तुलनात्मक कोहोर्ट्स पर A/B टेस्ट करें और ऐतिहासिक वर्ज़न्स रखें ताकि आप समझा सकें कि स्कोर समय के साथ क्यों बदला।
UI के अंदर फीडबैक इकट्ठा करें
एक हल्का कंट्रोल जोड़ें जैसे “Score feels wrong” साथ एक कारण (उदा., “हालिया ऑनबोर्डिंग पूरा हुआ पर दिखा नहीं”, “उपयोग मौसमी है”, “गलत अकाउंट मैपिंग”)। इस फीडबैक को बैकलॉग में भेजें और उसे अकाउंट और स्कोर वर्ज़न के साथ टैग करें ताकि डीबग तेज़ हो।
रोडमैप के साथ स्केल करें
पायलट स्थिर होने पर स्केल-अप वर्क की योजना बनाएं: गहरे इंटीग्रेशंस (CRM, बिलिंग, सपोर्ट), सेगमेंटेशन (प्लान, उद्योग, लाइफसाइकल), ऑटोमेशन (टास्क और प्लेबुक्स), और सेल्फ-सर्व सेटअप ताकि टीमें इंजीनियरिंग के बिना व्यू कस्टमाइज़ कर सकें।
जैसे-जैसे आप स्केल करते हैं, बिल्ड/इटरैट लूप तंग रखें। टीमें अक्सर Koder.ai का उपयोग नई डैशबोर्ड पेज स्पिन अप करने, API शेप्स परिष्कृत करने, या वर्कफ़्लो फ़ीचर्स जोड़ने के लिए चैट से सीधे करती हैं—खासकर तब जब आप अपना हेल्थ स्कोर मॉडल वर्ज़न कर रहे हों और UI + बैकएंड परिवर्तनों को बिना धीमा किए शिप करना चाहते हों।