27 अग॰ 2025·8 मिनट
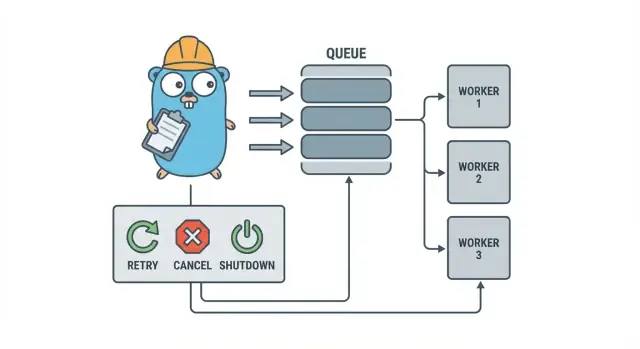
Go वर्कर पूल बैकग्राउंड जॉब के लिए: रिट्राइ, कैंसिल, शटडाउन
Go वर्कर पूल छोटी टीमों को retries, कैंसलेशन और साफ़ शटडाउन के साथ बैकग्राउंड जॉब चलाने देते हैं — भारी इंफ्रास्ट्रक्चर जोड़ने से पहले सरल पैटर्न्स इस्तेमाल करें।
क्यों बैकग्राउंड जॉब जल्दी गड़बड़ हो जाते हैं
एक छोटे Go सर्विस में, बैकग्राउंड वर्क आमतौर पर एक साधारण लक्ष्य से शुरू होता है: HTTP response जल्दी लौटाइए, और धीमी चीज़ें बाद में करें। वह ईमेल भेजना, इमेज रिसाइज़ करना, दूसरे API से सिंक करना, सर्च इंडेक्स रीबिल्ड करना, या नाइटली रिपोर्ट्स चलाना हो सकता है।
समस्या यह है कि ये जॉब असल प्रोडक्शन वर्क हैं, बस उन गार्डरेल्स के बिना जो request handling में मिलते हैं। HTTP handler से शुरू की गइं एक goroutine ठीक लगती है जब तक कि deploy के बीच कोई टास्क चल रहा न हो, कोई अपस्ट्रीम API स्लो न हो, या वही request दोबारा चलकर जॉब को दो बार ट्रिगर न कर दे।
पहले दर्द वाले बिंदु अनुमानित हैं:
- अटक जाने वाले जॉब: एक कॉल हैंग हो जाती है और वर्कर्स प्रोग्रेस करना बंद कर देते हैं।
- डुप्लिकेट वर्क: HTTP स्तर पर retries वही जॉब दोबारा चलाते हैं।
- कोई शटडाउन प्लान नहीं: प्रोसेस निकल जाता है और काम खो जाता है या आधा-अधूरा रह जाता है।
- साइलेंट फेल्यर: एरर एक बार लॉग होते हैं (या बिलकुल नहीं) और गायब हो जाते हैं।
- रिट्राई स्टॉर्म्स: फेलिंग जॉब्स तुरंत रिट्राई करते हैं और dependencies पर ओवरलोड डालते हैं।
यहीं एक छोटा, स्पष्ट पैटर्न जैसे Go वर्कर पूल मदद करता है। यह concurrency को एक विकल्प बनाता है (N workers), “बाद में करो” को एक साफ़ जॉब टाइप बनाता है, और retries, timeouts, और cancellation को एक जगह हैंडल करने देता है।
उदाहरण: एक SaaS ऐप को इनवॉइस भेजने की ज़रूरत है। आप नहीं चाहेंगे कि बैच इम्पोर्ट के बाद 500 एक साथ भेजे जाएँ, और आप नहीं चाहेंगे कि वही इनवॉइस फिर से भेजा जाए क्योंकि request retry हुआ। एक वर्कर पूल आपको throughput को कैप करने और “send invoice #123” को ट्रैक किए गए यूनिट के रूप में ट्रीट करने देता है।
एक वर्कर पूल उस समय सही टूल नहीं है जब आपको durable, cross-process गारंटी चाहिए। अगर जॉब्स को crashes से survive करना है, भविष्य के लिए schedule करना है, या कई सर्विसेस द्वारा प्रोसेस होना है, तो आपको असल queue और जॉब स्टेट के लिए persistent storage चाहिए होगा।
साधारण भाषा में वर्कर पूल मॉडल
एक Go वर्कर पूल जानबूझकर साधारण है: काम एक queue में डालिए, एक फिक्स्ड सेट ऑफ वर्कर्स उन्हें खींचे और सुनिश्चित कीजिए कि पूरा सिस्टम साफ़ तरीके से बंद हो सके।
मूल शब्दावली:
- Job: एक यूनिट ऑफ वर्क, जैसे “इस इमेज को रिसाइज़ करो” या “यह इनवॉइस ईमेल भेजो”।
- Queue: जहाँ जॉब्स इंतज़ार करते हैं।
- Worker: एक goroutine जो बार-बार जॉब लेती है और चलाती है।
- Dispatcher: वह हिस्सा जो जॉब्स स्वीकार करता है और उन्हें queue में डालता है।
कई इन-प्रोसेस डिज़ाइनों में, एक Go channel ही queue होता है। एक buffered channel सीमित संख्या में जॉब रख सकता है इससे पहले कि producers block हों। वह blocking बैकप्रेशर है, और अक्सर यही आपकी सर्विस को अनलिमिटेड वर्क लेने से और ट्रैफ़िक spike पर मेमोरी खत्म होने से बचाता है।
बफ़र साइज सिस्टम का अनुभव बदल देता है। छोटा बफ़र दबाव जल्दी दिखाता है (callers जल्दी रुकते हैं)। बड़ा बफ़र छोटे ब्लस्ट को स्मूद करता है पर ओवरलोड को बाद में छिपा सकता है। परफेक्ट नंबर नहीं है, सिर्फ़ वह नंबर जो आप सहन कर सकते हैं।
आप यह भी चुनते हैं कि पूल साइज फिक्स्ड हो या बदल सके। फिक्स्ड पूल को समझना आसान होता है और संसाधन उपयोग predictable रखता है। ऑटो-स्केलिंग वर्कर्स असममित लोड में मदद कर सकते हैं, पर इससे और निर्णय जुड़ते हैं (कब स्केल करें, कितनी बार, और कब वापस)।
अंत में, एक इन-प्रोसेस पूल में “ack” का मतलब आमतौर पर बस यह होता है कि worker ने जॉब खत्म कर दिया और कोई error नहीं लौटा। बाहरी ब्रोक़र नहीं है जो डिलीवरी की पुष्टि करे, इसलिए आपका कोड परिभाषित करता है कि “done” क्या है और जॉब फेल या कैंसिल होने पर क्या होता है।
डिज़ाइन लक्ष्य: retries, cancellation, और क्लीन शटडाउन
वर्कर पूल मैकेनिकल रूप से सरल है: फिक्स्ड संख्या में वर्कर्स चलाइए, उन्हें जॉब्स दीजिए, और प्रोसेस कीजिए। असली फायदा नियंत्रण है: predictible concurrency, स्पष्ट failure हैंडलिंग, और ऐसा shutdown path जो आधा-उद्देश्यित काम पीछे न छोड़े।
छोटी टीमों को तीन लक्ष्य सँभालने में मदद करते हैं:
- Concurrency सीमित करें ताकि एक spike डेटाबेस या बाहरी API को न पिघला दे।
- वर्क खोना टालें (या कम से कम ठीक से जानें कि क्या ड्रॉप हुआ और क्यों)।
- डिबग करने लायक रहें: हर जॉब लॉग्स और कुछ काउंटर के जरिए ट्रेसेबल हो।
ज़्यादातर फेल्यर नीरस होते हैं, पर आप उन्हें अलग तरह से हैंडल करना चाहेंगे:
- ट्रांज़िएंट एरर (नेटवर्क hiccups, rate limits) जिन्हें रिट्राई करना चाहिए।
- स्थायी एरर (खराब इनपुट, गायब रिकॉर्ड) जिन्हें रिट्राई नहीं करना चाहिए।
- टाइमआउट (कोई dependency हैंग हो जाए) जिन्हें काटा जाना चाहिए ताकि workers जाम न हों।
कैंसलेशन एरर जैसा नहीं है। यह एक निर्णय है: यूजर ने कैंसिल किया, deploy ने आपकी प्रोसेस बदली, या आपकी सर्विस शटडाउन कर रही है। Go में context cancellation को पहला दर्जा दें, और सुनिश्चित करें कि हर जॉब महंगे काम शुरू करने से पहले और निष्पादन के बीच कुछ सुरक्षित बिंदुओं पर इसे चेक करे।
क्लीन शटडाउन वह जगह है जहाँ कई पूल टूटते हैं। पहले तय कीजिए कि आपके जॉब्स के लिए “safe” क्या मतलब है: क्या आप इन-फ्लाइट वर्क पूरा करेंगे, या जल्दी बंद हों और बाद में पुन: चलाएँ? एक व्यावहारिक फ्लो:
- नए जॉब स्वीकार करना बंद करें।
- वर्कर्स को बताइए कि वे अपना करंट जॉब खत्म करने के बाद रुक जाएँ (या तुरंत रुकें)।
- एक डेडलाइन तक इंतज़ार करें, फिर मजबूर रूप से exit करें।
अगर आप ये नियम पहले से तय कर लें तो retries, cancellation, और shutdown छोटी और predictable रहेंगे बजाय कि यह एक बड़ा होमग्रोन फ्रेमवर्क बन जाए।
कदम दर कदम: एक बेसिक वर्कर पूल बनाना
एक वर्कर पूल बस कुछ goroutines हैं जो चैनल से जॉब्स खींचते और काम करते हैं। महत्वपूर्ण हिस्सा बेसिक्स को predictable बनाना है: जॉब कैसा दिखता है, वर्कर्स कैसे रुकते हैं, और आप कैसे जानते हैं कि सारा काम खत्म हुआ।
सरल Job टाइप से शुरू करें। इसे ID दीजिए (लॉग्स के लिए), payload (जो प्रोसेस करना है), एक attempt काउंटर (बाद में retries के लिए उपयोगी), timestamps, और per-job context data के लिए जगह।
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := &Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i < size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case <-p.ctx.Done():
return
case job, ok := <-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case <-p.ctx.Done():
return context.Canceled
case p.jobs <- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
कुछ व्यावहारिक विकल्प जो आप तुरंत चुनेंगे:
- आप कितना इंतज़ार सहन कर सकते हैं उसके आधार पर queue साइज चुनें।
- backpressure का मतलब callers के लिए क्या है: block, error लौटाना, या drop करना।
Stop()औरWait()को अलग रखें ताकि आप पहले intake रोक सकें, फिर इन-फ्लाइट वर्क का इंतज़ार कर सकें।
बिना फ्रेमवर्क बनाए retries जोड़ना
Retries उपयोगी हैं, पर यही वह जगह है जहाँ वर्कर पूल जटिल हो जाते हैं। लक्ष्य संकुचित रखें: केवल तब रिट्राई करें जब अगली कोशिश में सचमुच सफल होने का मौका हो, और जब नकारात्मक हो तो जल्दी रुक जाएँ।
शुरू करें यह तय करके कि क्या retryable है। अस्थायी समस्याएँ (नेटवर्क hiccups, timeouts, “try again later” responses) आमतौर पर रिट्राई के लायक हैं। स्थायी समस्याएँ (खराब इनपुट, गायब रिकॉर्ड, permission denied) नहीं हैं।
एक छोटा retry policy अक्सर काफी होता है:
- एरर को retryable बनाम non-retryable के रूप में मार्क करें (उदाहरण के लिए, एक
Retryable(err)हेल्पर से wrap करें)। - अधिकतम attempt काउंट सेट करें (अक्सर 3 से 5)। इसके बाद आप ज़्यादातर समय बर्बाद कर रहे होते हैं।
- exponential backoff इस्तेमाल करें और jitter जोड़ें ताकि जॉब्स एक साथ रिट्राई न करें।
- delay पर सीमा लगाएँ (उदाहरण के लिए, कभी 30 सेकंड से ज़्यादा न सोएँ)।
- retries को attempt नंबर, अगला delay और job ID के साथ लॉग करें।
Backoff जटिल नहीं होना चाहिए। एक सामान्य फ़ॉर्म है: delay = min(base * 2^(attempt-1), max), फिर jitter जोड़ें (±20% की रैंडमाइज़ेशन)। jitter मायने रखता है क्योंकि वरना कई वर्कर्स साथ फेल होंगे और साथ में रिट्राई भी करेंगे।
डिले कहां रहे? छोटे सिस्टम के लिए, worker के अंदर sleep कर लेना ठीक है, पर इससे एक worker स्लॉट बँध जाता है। अगर retries दुर्लभ हैं तो यह स्वीकार्य है। अगर retries सामान्य या delays लंबे हैं, तो जॉब को एक “run after” timestamp के साथ फिर से enqueue करने पर विचार करें ताकि वर्कर्स दूसरे काम पर व्यस्त रहें।
अंतिम फेल्यर पर स्पष्ट हों। फेल हुए जॉब (और आखिरी एरर) को review के लिए स्टोर करें, रिप्ले करने के लिए पर्याप्त संदर्भ लॉग करें, या इसे एक dead list में डालें जिसे आप नियमित रूप से जांचें। साइलेंट ड्रॉप से बचें। जो पूल फेल्यर छिपाता है वह न होने से भी बदतर है।
कैंसलेशन और टाइमआउट जो वाकई काम रोकें
Go में क्लीन शटडाउन बनाएं
सिग्नल हैंडलिंग और context timeouts मिनटों में चैट प्रॉम्प्ट से बनवाएँ।
वर्कर पूल तभी सुरक्षित महसूस करते हैं जब आप उन्हें रोक सकें। सबसे सरल नियम है: हर उस लेयर में context.Context पास करें जो ब्लॉक कर सकती है। इसका मतलब है submission, execution, और cleanup।
एक व्यावहारिक सेटअप दो समय सीमाएँ प्रयोग करता है:
- एक प्रति-जॉब टाइमआउट ताकि कोई टास्क एक worker को हमेशा के लिए न घेर ले।
- एक शटडाउन टाइमआउट ताकि प्रोसेस बाहर निकल सके भले कुछ जॉब्स cooperate न करें।
end-to-end context का उपयोग करें
हर जॉब को worker के context से निकले हुए अपने context दें। फिर हर धीमी कॉल (DB, HTTP, queues, file I/O) को उस context के साथ चलाना चाहिए ताकि वह जल्दी लौट सके।
func worker(ctx context.Context, jobs <-chan Job) {
for {
select {
case <-ctx.Done():
return
case job, ok := <-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
यदि Run आपके DB या किसी API को कॉल करता है, तो उन कॉल्स में context को वायर करें (उदाहरण: QueryContext, NewRequestWithContext, या ऐसे क्लाइंट मेथड जो context स्वीकार करते हैं)। अगर आप किसी जगह इसे इग्नोर करते हैं, तो cancellation “best effort” बन जाता है और अक्सर सबसे ज़रूरी समय पर फेल हो जाता है।
आंशिक काम और "सुरक्षित रीट्राई" स्टेप्स
कैंसलेशन जॉब के बीच में हो सकती है, इसलिए आंशिक काम को सामान्य मानिए। idempotent स्टेप्स पर काम करें ताकि reruns duplicates न बनाएं। आम तरीके हैं unique keys का उपयोग करना (या upserts), प्रोग्रेस मार्कर लिखना (started/done), आगे बढ़ने से पहले results स्टोर करना, और स्टेप्स के बीच ctx.Err() चेक करना।
शटडाउन को एक डेडलाइन की तरह ट्रीट करें: नए जॉब स्वीकार करना बंद करें, worker contexts को cancel करें, और शटडाउन टाइमआउट तक ही इन-फ्लाइट जॉब्स के खत्म होने का इंतज़ार करें।
क्लीन शटडाउन: जब प्रोसेस बाहर निकलना चाहिए तो क्या करें
क्लीन शटडाउन का एक काम है: नया काम लेना रोको, इन-फ्लाइट काम को रोकने के लिए कहो, और सिस्टम को अजीब स्थिति में न छोड़ते हुए बाहर निकलो।
सिग्नल से शुरू करें। ज्यादातर डिप्लॉयमेंट में आप लोकली SIGINT और process manager/container runtime से SIGTERM देखेंगे। एक shutdown context बनाइए जिसे सिग्नल आने पर cancel किया जाता है, और इसे अपने पूल और जॉब हैंडलर्स को पास करें।
फिर नए जॉब्स लेना बंद कर दें। किसी चैनल में सबमिशन करते हुए callers को कभी भी अनंत तक block मत होने दें। सबमिशन को एक फ़ंक्शन के पीछे रखें जो shutdown flag चेक करे या submit से पहले shutdown context पर select करे।
फिर queued वर्क का क्या होगा तय करें:
- Drain: पहले से queued काम पूरा करें, पर नए सबमिशन अस्वीकार करें।
- Drop: जो भी अभी तक शुरू नहीं हुआ उसे छोड़ दें।
ड्रेन पेमेंट्स और ईमेल जैसी चीज़ों के लिए सुरक्षित है। ड्रॉप कैश री-कैल्क्यू जैसे "nice to have" कार्यों के लिए ठीक है।
एक व्यावहारिक shutdown अनुक्रम:
- SIGINT/SIGTERM पकड़े और एक साझा context cancel करें।
- सबमिशन रोकें (submit path को बंद करें, जरूरी नहीं कि काम चैनल को)।
- वर्कर्स को context के आधार पर finish या abort करने दें।
- WaitGroup से वेट करें।
- एक डेडलाइन लागू करें, फिर exit करें।
डेडलाइन मायने रखती है। उदाहरण के लिए, इन-फ्लाइट जॉब्स को रुकने के लिए 10 सेकंड दें। उसके बाद जो अभी भी चल रहा है उसे लॉग करें और exit कर दें। इससे deploys predictable रहते हैं और stuck processes से बचाव होता है।
वर्कर पूल के लिए लॉगिंग और साधारण मैट्रिक्स
PostgreSQL जॉब क्यू में शिफ्ट करें
इन-प्रोसेस जॉब्स को बिना हैंडलर्स रीराइट किए आसान PostgreSQL queue में बदलें।
जब वर्कर पूल टूटता है, यह शायद जोर से फेल नहीं करता। जॉब्स स्लो हो जाते हैं, retries जमा हो जाते हैं, और कोई रिपोर्ट करता है कि "कुछ काम नहीं हो रहा"। लॉगिंग और कुछ बेसिक काउंटर इस कहानी को साफ़ बनाते हैं।
हर जॉब को स्थिर ID दें (या submit समय पर जेनरेट करें) और हर लॉग लाइन में उसे शामिल रखें। लॉग्स सुसंगत रखें: एक लाइन जब जॉब शुरू हो, एक जब यह खत्म हो, और एक जब यह फेल हो। अगर आप retry करते हैं, तो attempt नंबर और next delay लॉग करें।
एक साधारण लॉग आकार:
- start: job_id, worker_id, attempt, kind
- finish: job_id, worker_id, attempt, duration_ms
- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
मैट्रिक्स न्यूनतम ही रखिए और फिर भी लाभ मिलेगा। queue length, in-flight jobs, सफलताएँ और फेल्यर्स की कुल गिनती, और job latency (कम से कम avg और max) ट्रैक करें। अगर queue length लगातार बढ़ रही है और in-flight workers पिक्ड पर अटकी रहती है, तो आप saturated हैं। अगर submitters jobs चैनल में भेजते समय block हो रहे हैं, तो बैकप्रेशर कॉलर तक पहुँच रहा है। यह हमेशा बुरा नहीं है, पर यह जानबूझकर होना चाहिए।
जब "जॉब्स अटके हैं", तो जाँचें कि क्या प्रोसेस अभी भी जॉब्स ले रहा है, क्या queue लंबा हो रहा है, क्या वर्कर्स जीवित हैं, और कौन से जॉब सबसे लंबा चले आ रहे हैं। लंबी रंटाइम्स आमतौर पर missing timeouts, धीमे dependencies, या एक रिट्राई लूप की ओर इशारा करती हैं जो कभी नहीं रुकता।
एक वास्तविक उदाहरण: एक छोटा SaaS बैकग्राउंड क्यू
सोचिए एक छोटा SaaS जहाँ एक ऑर्डर PAID में बदलता है। पेमेंट के तुरंत बाद आपको इनवॉइस PDF भेजना, ग्राहक को ईमेल करना, और आंतरिक टीम को नोटिफाई करना होता है। आप यह काम वेब रिक्वेस्ट को ब्लॉक करके नहीं करना चाहते। यह वर्कर पूल के लिए अच्छा मैच है क्योंकि काम असली है, पर सिस्टम अभी छोटा है।
जॉब payload न्यूनतम हो सकता है: बस इतना कि डेटाबेस से बाकी डेटा लाया जा सके। API handler उसी ट्रांज़ेक्शन में order update के साथ jobs(status='queued', type='send_invoice', payload, attempts=0) जैसी एक row लिखता है, फिर एक बैकग्राउंड लूप queued jobs के लिए poll करता है और उन्हें worker channel में पुश करता है।
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
जब कोई worker इसे उठाता है, तो हॅप्पी पाथ सरल है: order लोड करो, invoice जनरेट करो, email provider कॉल करो, फिर जॉब को done मार्क करो।
Retries यहीं असली हो जाते हैं। अगर आपका email provider अस्थायी आउटेज में है, तो आप नहीं चाहेंगे कि 1,000 जॉब्स हमेशा के लिए फेल हों या provider पर हर सेकंड hammer करें। एक व्यावहारिक तरीका:
- नेटवर्क एरर और 5xx responses को retryable मानें।
- exponential backoff और max delay का उपयोग करें (उदाहरण: 5s, 15s, 45s, 2m)।
- attempts को cap करें (उदाहरण: 10) और फिर जॉब को failed मार्क करें।
- आखिरी एरर रिकॉर्ड करें ताकि सपोर्ट देखें कि क्या हुआ।
आउटेज के दौरान, जॉब्स queued से in_progress और फिर वापस queued (future run time के साथ) होते हैं। जब provider recover करता है, वर्कर्स स्वतः बैकलॉग ड्रेन कर लेते हैं।
अब एक deploy की कल्पना कीजिए। आप SIGTERM भेजते हैं। प्रोसेस को नए काम लेना बंद कर देना चाहिए पर जो इन-फ्लाइट है उसे पूरा करना चाहिए। polling बंद करें, worker channel में फ़ीड बंद करें, और डेडलाइन के साथ वर्कर्स का इंतज़ार करें। जो जॉब्स खत्म होते हैं उन्हें done मार्क करें। जो जॉब्स डेडलाइन तक भी चल रहे हों उन्हें फिर से queued मार्क करें (या एक watchdog के साथ in_progress ही छोड़ दें) ताकि नया वर्ज़न स्टार्ट होने पर उन्हें उठाया जा सके।
सामान्य गलतियाँ और ट्रैप्स
बैकग्राउंड प्रोसेसिंग की ज्यादातर बग्स जॉब लॉजिक में नहीं होतीं। वे समन्वय की गलतियों से आती हैं जो केवल लोड के तहत या shutdown के दौरान दिखती हैं।
एक क्लासिक ट्रैप एक चैनल को एक से ज़्यादा जगह से close करना है। नतीजा एक panic है जो reproduce करना मुश्किल होता है। हर चैनल का एक मालिक चुनिए (आम तौर पर producer), और वही close(jobs) करे।
Retries भी एक क्षेत्र है जहाँ अच्छी नीयतें आउटेज बनाती हैं। अगर आप सब कुछ रिट्राई करेंगे तो आप स्थायी फेल्यर्स भी रिट्राई कर देंगे। यह समय बर्बाद करता है, लोड बढ़ाता है, और एक छोटी समस्या को incident बना सकता है। एरर क्लासिफाई करें और retries को स्पष्ट नीति के साथ cap करें।
डुप्लिकेट्स होंगे भी — सावधानी से डिज़ाइन के बावजूद। वर्कर्स क्रैश हो सकते हैं, टाइमआउट काम खत्म होने के बाद फायर कर सकता है, या आप deployment के दौरान requeue कर सकते हैं। अगर जॉब idempotent नहीं है, तो डुप्लिकेट्स असल नुकसान कर सकते हैं: दो इनवॉइस, दो welcome ईमेल, दो refunds।
सबसे आम गलतियाँ:
- एक ही चैनल को कई goroutines से close करना।
- स्थायी फेल्यर्स को retry करना बजाय उन्हें surface करने के।
- idempotency key न होना, जिससे duplicates दुपहिया साइड-इफेक्ट करते हैं।
- अनबाउंडेड इन-मेमोरी क्यू जो तब तक बढ़ती रहती है जब तक मेमोरी spike न कर दे।
context.Contextको अनदेखा करना, जिससे shutdown शुरू होने के बाद काम चला रहता है।
अनबाउंडेड क्यू खासकर चुपके से नुकसान करते हैं। एक स्पाइक काम RAM में चुपचाप जमा कर सकता है। bounded channel buffer पसंद करें और तय करें कि भर जाने पर क्या होगा: block, drop, या error लौटाना।
शिप करने से पहले त्वरित चेकलिस्ट
अपने अगले बिल्ड के लिए क्रेडिट कमाएँ
एक छोटा write-up प्रकाशित करें और Koder.ai पर अपने अगले बिल्ड के लिए क्रेडिट पाएं।
प्रोडक्शन में वर्कर पूल शिप करने से पहले, आप जॉब लाइफ़साइकल ज़ुबानी बता सकें। अगर कोई पूछे "यह जॉब अभी कहाँ है?", तो जवाब अनुमान न हो।
एक व्यावहारिक प्री-फ्लाइट चेकलिस्ट:
- आप प्रत्येक स्टेट और ट्रांज़िशन का नाम बता सकते हैं: queued, picked up, running, finished, failed (और क्या उन्हें मूव करता है)।
- Concurrency एक knob है (जैसे
workerCount), और इसे बदलने के लिए कोड दोबारा लिखने की ज़रूरत नहीं हो। - Retries bounded हैं: max attempts स्पष्ट हैं, backoff बढ़ता है, और स्थायी फेल्यर कहीं इरादतन जाता है।
- Shutdown व्यवहार परखा हुआ है: intake बंद किया जाता है, इन-फ्लाइट जॉब्स खत्म होते हैं, और एक हार्ड timeout है।
- लॉग्स बुनियादी बातों का जवाब देते हैं: job ID, attempt नंबर, duration, और error कारण।
रिलीज़ से पहले एक वास्तविक ड्रिल करें: 100 “send receipt email” जॉब enqueue करें, 20 को फेल करने के लिए मजबूर करें, फिर रन के बीच सर्विस रीस्टार्ट करें। आपको देखना चाहिए कि retries उम्मीद के अनुसार कार्य करें, कोई डुप्लिकेट साइड-इफेक्ट न हो, और कैंसलेशन डेडलाइन पर वाकई काम रोक दे।
अगर कोई आइटम अस्पष्ट है, तो अब उसे कड़ी करें। यहाँ छोटी फिक्सेस बाद में दिनों की बचत कराती हैं।
अगले कदम: भारी इन्फ्रास्ट्रक्चर कब जोड़ें (और कब नहीं)
एक साधारण इन-प्रोसेस पूल अक्सर तब तक काफी होता है जब तक प्रोडक्ट युवा है। अगर आपके जॉब्स "nice to have" हैं (ईमेल भेजना, कैश रीफ़्रेश, रिपोर्ट जनरेट करना) और आप उन्हें फिर से चला सकते हैं, तो वर्कर पूल सिस्टम को समझने में आसान रखता है।
संकेत कि आपने इन-प्रोसेस पूल से आगे बढ़ना चाहिए
इन प्रेशर पॉइंट्स पर नजर रखें:
- आप कई ऐप इंस्टेंस चलाते हैं और चाहते हैं कि उनमें से केवल एक जॉब उठाए।
- आपको durability चाहिए (जॉब्स crashes और deploys से बचें)।
- आपको audit trail चाहिए: किसने क्या queue किया, कब चला, और परिणाम क्या रहा।
- आपको सर्विसेज के पार बैकप्रेशर कंट्रोल्स चाहिए, सिर्फ़ एक प्रोसेस के अंदर नहीं।
- आपको कड़ा scheduling या लंबे delays (घंटों या दिनों) चाहिए जिनके साथ reliable wake-up हो।
अगर इनमें से कोई भी सच नहीं है, तो भारी टूल्स ज़्यादा चलन में आकर मूल्य से ज़्यादा जटिलता जोड़ सकते हैं।
बिना री-राइट के धीरे-धीरे माइग्रेट करें
सबसे अच्छा हेज एक स्थिर जॉब इंटरफ़ेस है: एक छोटा payload टाइप, एक ID, और एक हैंडलर जो स्पष्ट परिणाम लौटाता है। फिर आप बाद में queue backend बदल सकते हैं (in-memory channel से database table पर, और उसके बाद dedicated queue पर) बिना business code बदले।
एक व्यावहारिक मध्यवर्ती कदम एक छोटा Go सर्विस है जो PostgreSQL से जॉब्स पढ़ती है, उन्हें lock के साथ claim करती है, और status अपडेट करती है। आपको durability और बेसिक auditability मिलती है जबकि वही worker लॉजिक रहता है।
अगर आप जल्दी प्रोटोटाइप करना चाहते हैं, तो Koder.ai (koder.ai) एक चैट प्रॉम्प्ट से Go + PostgreSQL स्टार्टर जेनरेट कर सकता है, जिसमें बैकग्राउंड jobs टेबल और वर्कर लूप शामिल है, और उसकी snapshots और rollback आपकी retries और shutdown व्यवहार ट्यून करते समय मदद कर सकते हैं।