04 जन॰ 2026·7 मिनट
Go context timeouts: तेज़ API के लिए व्यावहारिक नुस्खा
Go context टाइमआउट धीमी DB कॉल्स और बाहरी रिक्वेस्ट्स को जमा होने से रोकते हैं। डेडलाइन propagation, कैंसिलेशन और सुरक्षित डिफ़ॉल्ट्स सीखें।
Go context टाइमआउट धीमी DB कॉल्स और बाहरी रिक्वेस्ट्स को जमा होने से रोकते हैं। डेडलाइन propagation, कैंसिलेशन और सुरक्षित डिफ़ॉल्ट्स सीखें।
एक अकेली धीमी रिक्वेस्ट ज़्यादातर वक्त "सिर्फ धीमी" नहीं होती। प्रतीक्षा के दौरान यह एक goroutine को ज़िंदा रखती है, बफ़र और प्रतिक्रिया ऑब्जेक्ट्स के लिए मेमोरी बांधती है, और अक्सर एक डेटाबेस कनेक्शन या पूल में एक स्लॉट कब्ज़ा कर लेती है। जब पर्याप्त धीमी रिक्वेस्ट एक साथ इकठ्ठा हो जाती हैं, तो आपकी API उपयोगी काम करना बंद कर देती है क्योंकि सीमित संसाधन प्रतीक्षा में फँस जाते हैं।
इसके असर आप तीन जगह अनुभव करते हैं। Goroutines इकट्ठा होने लगते हैं और scheduling ओवरहेड बढ़ता है, इसलिए लेटेंसी सबके लिए खराब होती है। डेटाबेस पूल खाली कनेक्शन्स खत्म हो जाते हैं, इसलिए तेज़ क्वेरी भी धीमी क्वेरियों के पीछे कतार में लगने लगती हैं। इन-फ़्लाइट डेटा और आंशिक रूप से बने responses से मेमोरी बढ़ती है, जिससे GC का काम बढ़ जाता है।
और ज़्यादा सर्वर जोड़ना अक्सर समस्या का समाधान नहीं करता। अगर हर इंस्टेंस एक ही बॉटलनेक (छोटा DB पूल, एक धीमा अपस्ट्रीम, साझा रेट लिमिट) को हिट कर रहा है, तो आप बस कतार को दूसरी जगह शिफ्ट करते हैं और ज़्यादा भुगतान करते हैं जबकि errors वहीं spike कर रहे होते हैं।
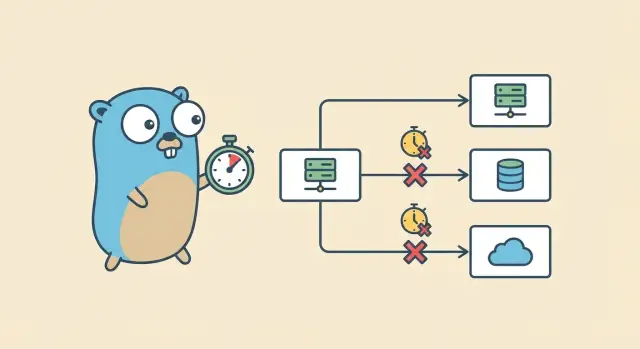
एक हैंडलर की परिकल्पना करें जो फैलता है: यह PostgreSQL से यूज़र लोड करता है, एक भुगतान सेवा को कॉल करता है, फिर एक recommendation सेवा को कॉल करता है। अगर recommendation कॉल फँस जाए और कुछ भी उसे कैंसिल न करे, तो रिक्वेस्ट कभी खत्म नहीं होगी। DB कनेक्शन लौट सकता है, पर goroutine और HTTP क्लाइंट संसाधन बँधे रहें। इसे सैकड़ों रिक्वेस्ट से गुणा करें और आपको धीमी पतन जैसी स्थिति मिलेगी।
लक्ष्य सरल है: एक स्पष्ट समय सीमा सेट करें, समय पूरे होने पर काम रोकें, संसाधन मुक्त करें, और एक पूर्वानुमेय त्रुटि लौटाएँ। Go context टाइमआउट हर स्टेप को एक डेडलाइन देते हैं ताकि काम तब रुक जाए जब उपयोगकर्ता आगे इंतज़ार नहीं कर रहा।
एक context.Context एक छोटा ऑब्जेक्ट है जिसे आप कॉल चेन में पास करते हैं ताकि हर लेयर एक बात पर सहमत हो: इस रिक्वेस्ट को कब बंद करना है। टाइमआउट्स आमतौर पर यही सुनिश्चित करते हैं कि एक धीमा निर्भरता आपके सर्वर को बँधे रखकर न रखे।
एक context तीन तरह की जानकारी रख सकता है: एक डेडलाइन (कब काम बंद होना चाहिए), एक cancellation सिग्नल (किसी ने पहले रोकने का निर्णय लिया), और कुछ request-scoped वैल्यूज़ (इन्हें संयम से उपयोग करें, और कभी बड़े डेटा के लिए नहीं)।
Cancellation जादू नहीं है। एक context Done() चैनल एक्सपोज़ करता है। जब यह बंद होता है, तो रिक्वेस्ट कैंसिल या समय सीमा पूरी हो चुकी है। context को मानने वाला कोड Done() चेक करता है (अक्सर select के साथ) और जल्दी लौट आता है। आप ctx.Err() भी चेक कर सकते हैं कि यह क्यों खत्म हुआ — आमतौर पर context.Canceled या context.DeadlineExceeded।
context.WithTimeout का उपयोग "X सेकंड के बाद बंद" के लिए करें। context.WithDeadline का उपयोग तब करें जब आपके पास पहले से ही एक निश्चित कटऑफ समय हो। context.WithCancel का उपयोग तब करें जब किसी पैरेंट कंडीशन को काम रोकना चाहिए (क्लाइंट डिसकनेक्ट, यूज़र ने नेविगेट किया, या आपके पास पहले से उत्तर आ चुका है)।
जब context कैंसिल होता है, सही व्यवहार बोरिंग पर महत्वपूर्ण होता है: काम रोकें, धीमी I/O पर इंतज़ार बंद करें, और स्पष्ट त्रुटि लौटाएँ। अगर एक हैंडलर डेटाबेस क्वेरी का इंतज़ार कर रहा है और context समाप्त हो जाता है, तो जल्दी लौटें और डेटाबेस कॉल को abort होने दें यदि वह context सपोर्ट करता है।
धीमी रिक्वेस्ट को रोकने का सबसे सुरक्षित स्थान वह बाउंडरी है जहाँ ट्रैफ़िक आपकी सर्विस में प्रवेश करता है। अगर कोई रिक्वेस्ट टाइम आउट होने वाली है, तो आप चाहते हैं कि यह पूर्वानुमेय और जल्दी हो — न कि तब जब उसने goroutines, DB कनेक्शन और मेमोरी बांध ली हों।
एज (लोड बैलेंसर, API गेटवे, रिवर्स प्रॉक्सी) से शुरू करें और किसी भी रिक्वेस्ट के लिए एक हार्ड कैप सेट करें कि वह कितनी देर तक जीवित रह सकती है। यह आपकी Go सर्विस की रक्षा करता है भले ही कोई हैंडलर टाइमआउट सेट करना भूल जाए।
अपने Go सर्वर के अंदर, HTTP टाइमआउट्स सेट करें ताकि सर्वर धीमे क्लाइंट या स्टॉल्ड रिस्पॉन्स के लिए अनंत समय तक न रुके। न्यूनतम रूप से, हेडर्स पढ़ने, पूरा request body पढ़ने, response लिखने, और idle कनेक्शन्स रखने के लिए टाइमआउट्स कॉन्फ़िगर करें।
अपने प्रोडक्ट के अनुसार एक डिफ़ॉल्ट रिक्वेस्ट बजट चुनें। कई APIs के लिए, सामान्य रिक्वेस्ट्स के लिए 1 से 3 सेकंड एक अच्छा शुरुआती बिंदु है, जबकि known slow ऑपरेशनों (जैसे एक्सपोर्ट्स) के लिए उच्च सीमा रखें। सटीक संख्या से ज़्यादा महत्वपूर्ण यह है कि आप सुसंगत हों, मापें, और अपवादों के लिए स्पष्ट नियम रखें।
Streaming responses को अतिरिक्त ध्यान चाहिए। बहुधा आप अनजाने में एक अनंत स्ट्रीम बना देते हैं जहाँ सर्वर कनेक्शन खुला रखकर छोटे-छोटे chunks लिखता रहता है, या पहले बाइट से पहले हमेशा के लिए इंतज़ार करता है। पहले तय करें कि क्या कोई endpoint वाकई stream है। अगर नहीं है, तो कुल समय और time-to-first-byte दोनों के लिए एक अधिकतम लागू करें।
जब बाउंडरी पर स्पष्ट डेडलाइन हो, तो उस डेडलाइन को पूरी रिक्वेस्ट में propagate करना बहुत आसान हो जाता है।
शुरू करने के लिए सबसे सरल स्थान HTTP हैंडलर है। यहीं से एक रिक्वेस्ट आपके सिस्टम में आती है, इसलिए यह एक प्राकृतिक जगह है जहाँ एक हार्ड लिमिट सेट करें।
नया context एक डेडलाइन के साथ बनाएं, और सुनिश्चित करें कि आप उसे cancel करते हैं। फिर वह context उन सभी जगहों पर पास करें जहाँ ब्लॉकिंग काम हो सकता है: डेटाबेस, HTTP कॉल, या धीमे कंप्यूटेशन।
func (s *Server) GetUser(w http.ResponseWriter, r *http.Request) {
ctx, cancel := context.WithTimeout(r.Context(), 2*time.Second)
defer cancel()
userID := r.URL.Query().Get("id")
if userID == "" {
http.Error(w, "missing id", http.StatusBadRequest)
return
}
user, err := s.loadUser(ctx, userID)
if err != nil {
writeError(w, ctx, err)
return
}
writeJSON(w, http.StatusOK, user)
}
एक अच्छा नियम: अगर कोई फ़ंक्शन I/O पर इंतज़ार कर सकता है, तो उसे एक context.Context स्वीकार करना चाहिए। हैंडलरों को पठनीय रखने के लिए विवरणों को छोटे helper फ़ंक्शनों में रखें जैसे loadUser।
func (s *Server) loadUser(ctx context.Context, id string) (User, error) {
return s.repo.GetUser(ctx, id) // repo should use QueryRowContext/ExecContext
}
अगर डेडलाइन पूरी हो जाती है (या क्लाइंट डिस्कनेक्ट कर देता है), तो काम रोकें और यूज़र-फ्रेंडली प्रतिक्रिया लौटाएँ। एक सामान्य मैपिंग है: context.DeadlineExceeded → 504 Gateway Timeout, और context.Canceled → "client is gone" (अक्सर बिना response body के)।
func writeError(w http.ResponseWriter, ctx context.Context, err error) {
if errors.Is(err, context.DeadlineExceeded) {
http.Error(w, "request timed out", http.StatusGatewayTimeout)
return
}
if errors.Is(err, context.Canceled) {
// Client went away. Avoid doing more work.
return
}
http.Error(w, "internal error", http.StatusInternalServerError)
}
यह पैटर्न pile-ups को रोकता है। जैसे ही टाइमर समाप्त होता है, चेन में हर context-aware फ़ंक्शन एक ही स्टॉप सिग्नल पाता है और तेज़ी से बाहर आ जाता है।
जब आपके हैंडलर के पास एक डेडलाइन वाला context होता है, सबसे महत्वपूर्ण नियम सरल है: वही ctx डेटाबेस कॉल तक पहुँचाएँ। इसी तरह टाइमआउट्स काम करते हैं — सिर्फ़ हैंडलर का इंतज़ार बंद नहीं होता, असली काम भी रुका जाता है।
database/sql के साथ, context-aware मेथड्स पसंद करें:
func (s *Server) getUser(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
row := s.db.QueryRowContext(ctx,
"SELECT id, email FROM users WHERE id = $1",
r.URL.Query().Get("id"),
)
var id int64
var email string
if err := row.Scan(&id, &email); err != nil {
// handle below
}
}
अगर हैंडलर बजट 2 सेकंड है, तो डेटाबेस को उसका केवल एक हिस्सा दें। JSON एन्कोडिंग, अन्य निर्भरताएँ, और error handling के लिए समय छोड़ें। एक सरल शुरुआती बिंदु यह है कि Postgres को कुल बजट का 30%–60% दें। 2 सेकंड के handler के लिए यह 800ms से 1.2s तक हो सकता है।
जब context कैंसिल होता है, ड्राइवर Postgres से क्वेरी रोकने के लिए कहता है। आम तौर पर कनेक्शन पूल में वापस आ जाता है और पुनः उपयोग के लिए उपलब्ध रहता है। अगर कैंसिलेशन किसी खराब नेटवर्क क्षण के दौरान हुआ, तो ड्राइवर उस कनेक्शन को निकाल सकता है और बाद में नया कनेक्शन खोल सकता है। किसी भी स्थिति में, आप एक goroutine के अनंत इंतज़ार से बच जाते हैं।
एरर्स की जाँच करते समय, टाइमआउट्स को असली DB फेलियर से अलग मानें। अगर errors.Is(err, context.DeadlineExceeded) तो आप समय समाप्त कर चुके हैं और timeout लौटाएँ। अगर errors.Is(err, context.Canceled) तो क्लाइंट चला गया और आप शांतिपूर्वक रुक जाएँ। अन्य त्रुटियाँ सामान्य क्वेरी समस्याएँ होती हैं (गलत SQL, missing row, permissions)।
अगर आपके हैंडलर के पास डेडलाइन है, तो आपके आउटबाउंड HTTP कॉल्स को भी उसका सम्मान करना चाहिए। अन्यथा क्लाइंट टूट चुका होगा पर आपका सर्वर धीमे अपस्ट्रीम का इंतज़ार करता रहेगा और goroutines, sockets, और मेमोरी बँधी रहेंगी।
parent context के साथ आउटबाउंड रिक्वेस्ट बनाएं ताकि cancellation अपने आप यात्रा करे:
func fetchUser(ctx context.Context, url string) ([]byte, error) {
// Add a small per-call cap, but never exceed the parent deadline.
ctx, cancel := context.WithTimeout(ctx, 800*time.Millisecond)
defer cancel()
req, err := http.NewRequestWithContext(ctx, http.MethodGet, url, nil)
if err != nil {
return nil, err
}
resp, err := http.DefaultClient.Do(req)
if err != nil {
return nil, err
}
defer resp.Body.Close() // always close, even on non-200
return io.ReadAll(resp.Body)
}
वह per-call timeout एक safety net है। parent request डेडलाइन ही वास्तविक मालिक है। एक ही घड़ी पूरी रिक्वेस्ट के लिए, और जोखिम भरे स्टेप्स के लिए छोटे कैप्स।
ट्रांसपोर्ट लेवल पर भी टाइमआउट्स सेट करें। Context रिक्वेस्ट को कैंसिल करता है, पर ट्रांसपोर्ट टाइमआउट्स आप को slow handshakes और ऐसे सर्वरों से बचाते हैं जो हेडर कभी नहीं भेजते।
एक बारीक बात जो टीमों को काटती है: response bodies को हर पाथ पर बंद करना चाहिए। अगर आप जल्दी लौटते हैं (status code चेक, JSON decode त्रुटि, context timeout), तब भी body बंद करें। बॉडी रिसोर्स लीक होना कनेक्शन्स पूल को धीरे-धीरे समाप्त कर सकता है और "random" लेटेंसी spike पैदा कर सकता है।
एक ठोस परिदृश्य: आपकी API भुगतान प्रदाता को कॉल करती है। क्लाइंट 2 सेकंड बाद टाइम आउट हो जाता है, पर अपस्ट्रीम 30 सेकंड तक हैंग करता है। बिना request cancellation और transport timeouts के, आप हर त्यागी रिक्वेस्ट के लिए उस 30 सेकंड के इंतज़ार का भुगतान करते रहते हैं।
एक सामान्य रिक्वेस्ट अक्सर एक से अधिक धीमी चीज़ों को छूती है: हैंडलर काम, एक DB क्वेरी, और एक या अधिक बाहरी APIs। अगर आप हर स्टेप को उदार टाइमआउट देते हैं, तो कुल समय चुपचाप बढ़ता जाता है जब तक कि उपयोगकर्ता इसे महसूस न कर लें और आपका सर्वर पाइल-अप हो।
बजटिंग सबसे सरल समाधान है। पूरे रिक्वेस्ट के लिए एक parent डेडलाइन सेट करें, फिर हर निर्भरता को छोटे हिस्से दें। चाइल्ड डेडलाइन को पैरेंट से पहले रखना चाहिए ताकि आप जल्दी फेल हों और साफ़ त्रुटि लौटाने के लिए समय बचे।
वास्तविक सेवाओं में काम आने वाले नियम:
ऐसे timeouts stacking से बचें जो एक दूसरे से लड़ते हों। अगर आपका हैंडलर context 2 सेकंड है और HTTP क्लाइंट का timeout 10 सेकंड है, तो आप सुरक्षित हैं लेकिन यह भ्रमित कर सकता है। उल्टा होने पर, क्लाइंट अनजाने में जल्दी कट सकता है।
बैकग्राउंड वर्क (audit logs, metrics, emails) के लिए request context का पुन: उपयोग न करें। एक अलग context और छोटा टाइमआउट उपयोग करें ताकि क्लाइंट कैंसिलेशन्स महत्वपूर्ण cleanup को मार न दें।
ज्यादातर टाइमआउट बग हैंडलर में नहीं होते। वे एक या दो लेयर नीचे होते हैं, जहाँ डेडलाइन चुपचाप खो जाती है। अगर आपने सीमा पर टाइमआउट सेट किया पर बीच में उसे नज़रअंदाज़ कर दिया, तो फिर भी goroutines, DB क्वेरीज, या HTTP कॉल्स चलती रहेंगी जबकि क्लाइंट जा चुका होता है।
अक्सर दिखाई देने वाले पैटर्न सरल हैं:
context.Background() (या TODO) से कॉल करना। इससे काम और क्लाइंट कैंसिल/हैंडलर डेडलाइन अलग हो जाते हैं।ctx.Done() चेक किए बिना स्लीप करना, retry करना, या लूप करना। रिक्वेस्ट कैंसिल हो चुकी है पर कोड इंतज़ार करता रहता है।context.WithTimeout लगाना। इसके परिणामस्वरूप कई टाइमर्स और भ्रमित करने वाले डेडलाइन बनते हैं।ctx जोड़ना भूल जाना। हैंडलर टाइमआउट बेकार है यदि dependency कॉल उसे इग्नोर करे।एक क्लासिक फेलियर: हैंडलर में 2 सेकंड टाइमआउट जोड़ते हैं, फिर आपका repository डेटाबेस क्वेरी के लिए context.Background() इस्तेमाल करता है। लोड के तहत एक धीमी क्वेरी क्लाइंट के छोड़ने के बाद भी चलती रहती है और pile बढ़ती रहती है।
बुनियादी सुधार करें: ctx को कॉल स्टैक में पहली आर्गुमेंट के रूप में पास करें। लंबे काम में छोटे चेक जोड़ें जैसे:
select {
case <-ctx.Done():
return ctx.Err()
default:
}
context.DeadlineExceeded को timeout response (अक्सर 504) और context.Canceled को client-cancel शैली प्रतिक्रिया (अक्सर 408 या 499, आपकी convention के अनुसार) में मैप करें।
टाइमआउट तभी मदद करते हैं जब आप उन्हें देख सकें और पुष्टि कर सकें कि सिस्टम साफ़-सुथरा रिकवरी कर रहा है। जब कुछ धीमा होता है, रिक्वेस्ट को रोक देना चाहिए, संसाधन मुक्त होने चाहिए, और API प्रतिक्रियाशील बने रहनी चाहिए।
हर रिक्वेस्ट के लिए एक छोटा, एक सा सेट फील्ड्स लॉग करें ताकि आप सामान्य रिक्वेस्ट्स और टाइमआउट्स की तुलना कर सकें। context डेडलाइन (यदि मौजूद है) और क्या काम ने समाप्त किया इसकी जानकारी शामिल करें।
उपयोगी फील्ड्स में डेडलाइन (या "none"), कुल अल्पावधि समय, कैंसिलेशन कारण (timeout vs client canceled), एक छोटा ऑपरेशन लेबल ("db.query users", "http.call billing"), और एक रिक्वेस्ट ID शामिल हैं।
एक न्यूनतम पैटर्न कुछ ऐसा दिखता है:
start := time.Now()
deadline, hasDeadline := ctx.Deadline()
err := doWork(ctx)
log.Printf("op=%s hasDeadline=%t deadline=%s elapsed=%s err=%v",
"getUser", hasDeadline, deadline.Format(time.RFC3339Nano), time.Since(start), err)
लॉग्स एक रिक्वेस्ट डिबग करने में मदद करते हैं। मीट्रिक्स रुझान दिखाते हैं।
कुछ संकेत जो गलत टाइमआउट्स में पहले spike होते हैं: रूट और निर्भरता के अनुसार timeout की गिनती, in-flight रिक्वेस्ट्स (लोड के तहत यह सीमित रहनी चाहिए), DB पूल वेट टाइम, और latency percentiles (p95/p99) जिन्हें success बनाम timeout के अनुसार विभाजित किया गया हो।
धीमा पन predictable बनाइए। एक handler में debug-only delay जोड़ें, किसी DB क्वेरी को जानबूझकर धीमा करें, या एक परीक्षण सर्वर के साथ बाहरी कॉल को स्लो करें। फिर यह सत्यापित करें: आप टाइमआउट एरर देखते हैं, और कैंसिलेशन के तुरंत बाद काम रुक जाता है।
एक छोटा load test भी मदद करता है। 20–50 समवर्ती रिक्वेस्ट 30–60 सेकंड तक चलाएँ जबकि एक निर्भरता धीमी हो। Goroutine count और in-flight रिक्वेस्ट्स बढ़कर फिर स्थिर होना चाहिए। अगर वे बढ़ते ही रहे, तो कुछ context cancellation को इग्नोर कर रहा है।
टाइमआउट तभी मदद करते हैं जब वे हर जगह लागू हों जहाँ रिक्वेस्ट प्रतीक्षा कर सकती है। डिप्लॉय करने से पहले अपने कोडबेस पर एक पास करें और सुनिश्चित करें कि हर हैंडलर में वही नियम लागू हों:
context.DeadlineExceeded और context.Canceled के लिए erreurs चेक करें।http.NewRequestWithContext (या req = req.WithContext(ctx)) का उपयोग करे और क्लाइंट/ट्रांसपोर्ट टाइमआउट्स सेट हों (dial, TLS, response header)। प्रोडक्शन पाथ्स में http.DefaultClient पर भरोसा करने से बचें।रिलीज़ से पहले एक छोटा "slow dependency" ड्रिल करना फायदेमंद है। किसी SQL क्वेरी में आर्टिफिशियल 2 सेकंड देरी डालें और तीन चीज़ों की पुष्टि करें: हैंडलर समय पर लौटता है, DB कॉल वास्तव में रुकता है (केवल हैंडलर नहीं), और आपके लॉग्स साफ़ बताते हैं कि यह DB टाइमआउट था।
कल्पना कीजिए एक endpoint GET /v1/account/summary जैसा। एक यूज़र एक क्रिया करती है जो तीन काम ट्रिगर करती है: PostgreSQL क्वेरी (खाता और हालिया गतिविधि) और दो बाहरी HTTP कॉल्स (उदाहरण के लिए, बिलिंग स्टेटस और प्रोफ़ाइल एन्क्रिचमेंट)।
कुल रिक्वेस्ट के लिए एक हार्ड 2 सेकंड बजट दें। बिना बजट के, एक धीमी निर्भरता goroutines, DB कनेक्शन्स, और मेमोरी को तब तक बांधे रख सकती है जब तक आपकी API हर जगह टाइमआउट देने न लगे।
सरल विभाजन हो सकता है: DB क्वेरी के लिए 800ms, बाहरी कॉल A के लिए 600ms, और बाहरी कॉल B के लिए 600ms।
एक बार जब आप कुल डेडलाइन जानते हैं, उसे नीचे पास करें। हर निर्भरता को अपनी छोटी टाइमआउट मिले, पर वे पैरेंट से cancellation inherited करती हैं।
func AccountSummary(w http.ResponseWriter, r *http.Request) {
ctx, cancel := context.WithTimeout(r.Context(), 2*time.Second)
defer cancel()
dbCtx, dbCancel := context.WithTimeout(ctx, 800*time.Millisecond)
defer dbCancel()
aCtx, aCancel := context.WithTimeout(ctx, 600*time.Millisecond)
defer aCancel()
bCtx, bCancel := context.WithTimeout(ctx, 600*time.Millisecond)
defer bCancel()
// Use dbCtx for QueryContext, aCtx/bCtx for outbound HTTP requests.
}
यदि बाहरी कॉल B धीमा हो और 2.5 सेकंड ले ले, तो आपका हैंडलर 600ms पर इंतज़ार बंद कर देना चाहिए, इन-फ्लाइट वर्क को कैंसिल कर देना चाहिए, और क्लाइंट को एक स्पष्ट timeout प्रतिक्रिया लौटानी चाहिए। क्लाइंट को लंबा हैंगिंग स्पिनर देखने की जगह एक तेज़ फ़ेलचर दिखाई देगा।
आपके लॉग्स से स्पष्ट होना चाहिए कि किसने बजट उपयोग किया: उदाहरण के लिए DB जल्दी खत्म हुआ, बाहरी A सफल हुआ, और बाहरी B ने अपना कैप पार किया और context deadline exceeded लौटा।
एक असली एन्डपॉइंट में टाइमआउट और कैंसिलेशन अच्छी तरह काम करने के बाद, इसे एक दोहराने योग्य पैटर्न बनाएं। इसे end-to-end लागू करें: हैंडलर डेडलाइन, DB कॉल्स, और आउटबाउंड HTTP। फिर यही संरचना अगली एन्डपॉइंट पर कॉपी करें।
बोरिंग हिस्सों को केंद्रीकृत करने से आप तेज़ी से आगे बढ़ेंगे: एक boundary timeout helper, wrapper जो सुनिश्चित करें कि ctx DB और HTTP कॉल्स में पास हो, और एक सुसंगत error mapping और log फ़ॉर्मैट।
यदि आप इस पैटर्न का तेज़ प्रोटोटाइप बनाना चाहते हैं, तो Koder.ai (koder.ai) चैट प्रॉम्प्ट से Go हैंडलर और सर्विस कॉल जेनरेट कर सकता है, और आप सोर्स को एक्सपोर्ट करके अपने टाइमआउट helpers और बजट लागू कर सकते हैं। लक्ष्य सुसंगतता है: धीमे कॉल जल्दी बंद हों, एरर्स एक जैसे दिखें, और डिबग करना इस बात पर निर्भर न करे कि किसने एन्डपॉइंट लिखा।
एक धीमी रिक्वेस्ट प्रतीक्षा के दौरान सीमित संसाधनों को बांधे रखती है: एक goroutine, बफर और प्रतिक्रिया ऑब्जेक्ट्स के लिए मेमोरी, और अक्सर डेटाबेस या HTTP क्लाइंट कनेक्शन। जब कई रिक्वेस्ट एक साथ प्रतीक्षा करती हैं, तो कतारें बनती हैं, लेटेंसी बढ़ती है और सेवा विफल होने लगती है यहाँ तक कि हर एक रिक्वेस्ट अलग-अलग ठीक खत्म हो रही हो।
रिक्वेस्ट की सीमा (boundary) पर एक स्पष्ट समयसीमा सेट करें (प्रॉक्सी/गेटवे और Go सर्वर दोनों पर), हैंडलर में एक timed context बनाएं, और उस ctx को हर blocking कॉल (DB और आउटबाउंड HTTP) में पास करें। डेडलाइन पूरा होने पर जल्दी लौटें, एक सुसंगत timeout प्रतिक्रिया दें, और किसी भी इन-फ़्लाइट काम को बंद कर दें जो cancellation को सपोर्ट करता है।
जब आप "X समय बाद बंद करो" चाहते हैं तो context.WithTimeout(parent, d) का प्रयोग करें — यह हैंडलरों में सबसे सामान्य है। यदि आपकी पास पहले से ही एक निश्चित कटऑफ समय है, तो context.WithDeadline(parent, t) का प्रयोग करें। जब किसी आंतरिक घटना के कारण जल्दी रुकना हो (जैसे "हमें पहले से ही जवाब मिल गया" या क्लाइंट डिस्कनेक्ट हुआ), तो context.WithCancel(parent) उपयोगी है।
हर बार derived context बनाने के तुरन्त बाद defer cancel() लिखना चाहिए। यह timer को रिहा करता है और उन child वर्क के लिए साफ़ स्टॉप सिग्नल भेजता है जो जल्दी लौटने वाले पाथ्स में होते हैं, भले ही डेडलाइन कभी ट्रिगर न हो।
हैंडलर में एक ही request context बनाएं और उसे first argument के रूप में उन फ़ंक्शनों को पास करें जो ब्लॉक कर सकती हैं। खोज के तौर पर कोडबेस में context.Background() या context.TODO() जैसी जगहें देखें; वे अक्सर cancellation propagation को तोड़ देती हैं।
कॉन्टेक्स्ट-सपोर्ट करने वाले DB मेथड जैसे QueryContext, QueryRowContext, और ExecContext का प्रयोग करें (या आपके ड्राइवर में उनके समकक्ष)। जब context खत्म होता है, ड्राइवर Postgres से क्वेरी रद्द करने को कह सकता है ताकि आप अनुरोध के खत्म होने के बाद समय और कनेक्शन न गंवाएँ।
आउटबाउंड रिक्वेस्ट में parent request context अटैच करें: http.NewRequestWithContext(ctx, ...) का प्रयोग करें, और क्लाइंट/ट्रांसपोर्ट लेवल पर टाइमआउट भी कॉन्फ़िगर करें ताकि कनेक्ट, TLS और response header इंतज़ार से आप सुरक्षित रहें। त्रुटि या non-200 स्थिति में भी response body हमेशा बंद करें ताकि कनेक्शन्स पूल में लौट आएँ।
पहले कुल बजट चुनें (उदाहरण: यूज़र-फेसिंग एन्डप्वाइंट के लिए 2 सेकंड)। फिर प्रत्येक dependency को उस बजट का छोटा हिस्सा दें और handler overhead के लिए थोड़ा बफ़र रखें। यदि parent context में केवल 120ms बचे हैं, तो कोई ऐसा कॉल न शुरू करें जिसे सामान्यतः 300ms चाहिए।
सामान्यतः context.DeadlineExceeded को 504 Gateway Timeout के साथ मैप करना ठीक रहता है (संक्षिप्त संदेश जैसे “request timed out”)। context.Canceled अक्सर क्लाइंट के जाय जाने का संकेत है; सामान्यतः सबसे अच्छा कार्य है काम रोक देना और बॉडी लिखे बिना लौटना, ताकि आप और संसाधन न खोएँ।
सबसे सामान्य गलतियाँ: request context छोड़कर context.Background() का उपयोग करना, retries या sleep के दौरान ctx.Done() नहीं चेक करना, और blocking कॉल्स को ctx के साथ अटैच करना भूल जाना। इसके अलावा, हर जगह कई अलग timeouts लगाना जिससे डिबग मुश्किल हो जाता है।