16 जन॰ 2026·8 मिनट
दस्तावेज़-केंद्रित कार्यप्रवाह: डेटा मॉडल और UI पैटर्न
विश praktische दस्तावेज़-केंद्रित वर्कफ़्लो: वर्ज़निंग, प्रिव्यू, मेटाडेटा और स्पष्ट स्टेट्स के लिए डेटा मॉडल और UI पैटर्न।
विश praktische दस्तावेज़-केंद्रित वर्कफ़्लो: वर्ज़निंग, प्रिव्यू, मेटाडेटा और स्पष्ट स्टेट्स के लिए डेटा मॉडल और UI पैटर्न।
एक ऐप दस्तावेज़-केंद्रित तब होता है जब दस्तावेज़ खुद वह उत्पाद हो जिसे उपयोगकर्ता बनाते, समीक्षा करते और उस पर निर्भर करते हैं। अनुभव PDF, इमेज, स्कैन और रसीद जैसी फाइलों के इर्द-गिर्द बनाया जाता है, न कि उस फ़ॉर्म के जो केवल अटैचमेंट के रूप में फाइल रखता है।
दस्तावेज़-केंद्रित वर्कफ़्लो में लोग दस्तावेज़ के अंदर वास्तविक काम करते हैं: वे उसे खोलते हैं, देखते हैं क्या बदला, संदर्भ जोड़ते हैं, और तय करते हैं अगला कदम क्या होगा। अगर दस्तावेज़ पर भरोसा नहीं किया जा सकता तो ऐप उपयोगी नहीं रहता।
अधिकांश दस्तावेज़-केंद्रित ऐप्स को शुरुआत में कुछ मुख्य स्क्रीन चाहिए:
समस्याएँ जल्दी सामने आती हैं। यूज़र्स एक ही रसीद दो बार अपलोड कर देते हैं। कोई बिना कारण बताए PDF एडिट करके फिर से अपलोड कर देता है। एक स्कैन में तारीख, विक्रेता और मालिक नहीं है। हफ़्तों बाद किसी को नहीं पता किस वर्ज़न को अप्रूव किया गया था या निर्णय किस आधार पर लिया गया था।
एक अच्छा दस्तावेज़-केंद्रित ऐप तेज़ और भरोसेमंद लगता है। उपयोगकर्ताओं को कुछ सेकंड में ये सवालों के जवाब मिल जाने चाहिए:
यह स्पष्टता परिभाषाओं से आती है। स्क्रीन बनाने से पहले तय करें कि आपकी ऐप में “वर्ज़न”, “प्रिव्यू”, “मेटाडेटा” और “स्टेटस” का मतलब क्या है। यदि ये शब्द अस्पष्ट रहेंगे तो आप डुप्लिकेट्स, भ्रमित इतिहास और ऐसे रिव्यू फ्लोज़ पाएँगे जो असली काम से मेल नहीं खाते।
UI अक्सर सरल दिखता है (एक सूची, एक व्यूअर, कुछ बटन), पर डेटा मॉडल ही भार उठाता है। अगर मुख्य ऑब्जेक्ट सही हैं तो audit इतिहास, तेज़ प्रिव्यू और भरोसेमंद अनुमोदन काफी आसान हो जाते हैं।
शुरुआत इस अलगाव से करें: “दस्तावेज़ रिकॉर्ड” को “फाइल कंटेंट” से अलग रखें। रिकॉर्ड वह है जिसकी उपयोगकर्ता चर्चा करते हैं (ACME से इनवॉयस, टैक्सी रसीद)। कंटेंट वह बाइट्स हैं (PDF, JPG) जिन्हें बदला, पुनःप्रोसेस या स्थानांतरित किया जा सकता है बिना यह बदले कि ऐप के अंदर दस्तावेज़ का क्या मतलब है।
मॉडल करने के लिए व्यावहारिक ऑब्जेक्ट्स का सेट:
निर्णय लें कि किसे ऐसा ID मिलेगा जो कभी नहीं बदलेगा। एक उपयोगी नियम: Document ID हमेशा रहता है, जबकि Files और Previews को फिर से बनाया जा सकता है। Versions को भी स्थिर IDs चाहिए, क्योंकि लोग “कल यह कैसा दिखता था” का संदर्भ देते हैं और आपको audit trail चाहिए होगा।
रिलेशनशिप्स को स्पष्ट रूप से मॉडल करें। एक Document के कई Versions होते हैं। प्रत्येक Version के कई Previews हो सकते हैं (विभिन्न साइज़ या फॉर्मैट)। इससे लिस्ट स्क्रीन तेज़ रहती हैं क्योंकि वे हल्का preview डेटा लोड कर सकती हैं, जबकि डिटेल स्क्रीन केवल जब ज़रूरत हो तब फुल फाइल लोड करती हैं।
उदाहरण: एक यूज़र एक झुर्रीदार रसीद की फोटो अपलोड करता है। आप एक Document बनाते हैं, मूल File स्टोर करते हैं, एक थंबनेल Preview जेनरेट करते हैं, और Version 1 बनाते हैं। बाद में उपयोगकर्ता एक clearer स्कैन अपलोड करता है। वह Version 2 बन जाता है, बिना Document से जुड़े कमेंट्स, अप्रूवल या सर्च को तोड़े।
लोग उम्मीद करते हैं कि दस्तावेज़ समय के साथ बदलेगा बिना “एक अलग आइटम बन जाने” के। इसे देने का सबसे सरल तरीका पहचान (Document) को कंटेंट (Version और Files) से अलग रखना है।
शुरू करते समय एक स्थिर document_id रखें जो कभी न बदले। चाहे यूज़र वही PDF फिर से अपलोड करे, धुंधली फोटो बदल दे, या सुधारशुदा स्कैन अपलोड करे, उसे वही Document रिकॉर्ड होना चाहिए। कमेंट्स, असाइनमेंट और ऑडिट लॉग साफ़-सुथरे तरीके से एक टिकाऊ ID पर जुड़ते हैं।
हर महत्वपूर्ण बदलाव को एक नई version पंक्ति मानें। हर वर्ज़न को कैप्चर करना चाहिए कि किसने इसे बनाया और कब, साथ ही स्टोरेज पॉइंटर्स (file key, checksum, size, page count) और उस सटीक फाइल से जुड़े derived artifacts (OCR टेक्स्ट, preview इमेज)। inplace editing से बचें। यह पहले सरल दिखता है, पर ट्रैसेबिलिटी टूट जाती है और बग्स को उलटना मुश्किल हो जाता है।
तेज़ पढ़ने के लिए, दस्तावेज़ पर current_version_id रखें। अधिकांश स्क्रीन को केवल “लेटेस्ट” चाहिए, ताकि हर लोड पर वर्ज़न सॉर्ट न करना पड़े। जब इतिहास दिखाना हो, वर्ज़न अलग लोड करें और एक साफ़ टाइमलाइन दिखाएँ।
रोलबैक केवल एक पॉइंटर चेंज है। किसी चीज़ को मिटाने की बजाय current_version_id को पुराने वर्ज़न पर सेट करें। यह तेज़, सुरक्षित है और ऑडिट ट्रेल बरकरार रखता है।
इतिहास को समझने योग्य बनाए रखने के लिए, हर वर्ज़न का कारण रिकॉर्ड करें। एक छोटा, सुसंगत reason फ़ील्ड (वैकल्पिक नोट के साथ) टाइमलाइन को रहस्यमय अपडेट्स से बचाता है। आम कारणों में re-upload replacement, scan cleanup, OCR correction, redaction और approval edit शामिल हैं।
उदाहरण: फ़ायनेंस टीम एक रसीद की फोटो अपलोड करती है, बाद में उसमें clearer स्कैन से रिप्लेस करती है, फिर OCR ठीक करती है ताकि total पढ़ा जा सके। हर चरण एक नया वर्ज़न है, पर दस्तावेज़ इनबॉक्स में एक ही आइटम बना रहता है। अगर OCR फिक्स गलत हो, तो रोलबैक एक क्लिक में होता है क्योंकि आप केवल current_version_id बदल रहे हैं।
दस्तावेज़-केंद्रित वर्कफ़्लो में प्रिव्यू अक्सर मुख्य इंटरैक्शन होता है। अगर प्रिव्यू धीमे या खराब हैं तो पूरा ऐप टूटा हुआ सा लगेगा।
प्रिव्यू जनरेशन को एक अलग जॉब मानें, न कि ऐसा कुछ जिससे अपलोड स्क्रीन को इंतज़ार करना पड़े। पहले मूल फाइल सहेजें, यूज़र को नियंत्रण वापस दें, फिर बैकग्राउंड में प्रिव्यू बनाएँ। यह UI को उत्तरदायी रखता है और retries को सुरक्षित बनाता है।
कई प्रिव्यू साइज़ स्टोर करें। एक साइज़ हर स्क्रीन पर फिट नहीं बैठता: सूचियों के लिए छोटा थंबनेल, स्प्लिट व्यू के लिए मीडियम इमेज, और डिटेल रिव्यू के लिए फुल-पेज इमेज (PDF के लिए पेज-बाय-पेज)।
प्रिव्यू स्टेट को स्पष्ट रूप से ट्रैक करें ताकि UI हमेशा जान सके क्या दिखाना है: pending, ready, failed, needs_retry। UI में ये उपयोगकर्ता-अनुकूल शब्दों में दिखें, पर डेटा में स्टेट्स साफ़ रहें।
रेंडरिंग तेज़ रखने के लिए preview रिकॉर्ड के साथ derived मान कैश करें बजाय हर व्यू पर उन्हें फिर से कैलकुलेट करने के। सामान्य फ़ील्ड्स में page count, preview width/height, rotation (0/90/180/270) और एक वैकल्पिक “thumbnail के लिए best page” शामिल हैं।
धीमी और गड़बड़ फाइलों के लिए डिज़ाइन करें। 200-पेज स्कैन किए गए PDF या झुर्रीदार रसीद फोटो प्रोसेस होने में समय ले सकते हैं। प्रोग्रेसिव लोडिंग उपयोग करें: पहले तैयार पेज को जैसे ही मिले दिखाएँ, फिर बाकी भरें।
उदाहरण: एक यूज़र 30 रसीद फोटो अपलोड करता है। लिस्ट व्यू थंबनेल्स को “pending” दिखाता है, फिर जैसा-जैसा प्रिव्यू्स बनते हैं कार्ड “ready” में बदल जाते हैं। यदि कुछ करप्ट इमेज की वजह से फेल होते हैं, वे clear retry क्रिया के साथ दिखते हैं बजाय गायब होने या पूरे बैच को ब्लॉक करने के।
मेटाडेटा फाइलों के ढेर को कुछ ऐसा बनाता है जिसे आप सर्च, सॉर्ट, रिव्यू और अप्रूव कर सकें। यह लोगों को सरल सवालों के उत्तर तेजी से देने में मदद करता है: यह क्या है? यह किसका है? क्या यह वैध है? अगला क्या होना चाहिए?
मेटाडेटा को साफ़ रखने का व्यावहारिक तरीका इसे स्रोत के अनुसार अलग रखना है:
ये बकेट बाद में विवादों को रोकते हैं। यदि total गलत है, आप देख पाएँगे वह OCR से आया था या किसी इंसान ने एडिट किया।
रसीदों और इनवॉइस के लिए, कुछ फ़ील्ड्स का छोटा सेट उपयोगी होता है अगर आप उन्हें लगातार इस्तेमाल करें (एक ही नामकरण, एक ही फॉर्मैट)। सामान्य anchor फ़ील्ड्स हैं vendor, date, total, currency, और document_number। शुरुआत में इन्हें वैकल्पिक रखें। लोग आंशिक स्कैन और धुंधली फ़ोटो अपलोड करते हैं, और अगर किसी एक फ़ील्ड की कमी की वजह से कार्य रुक जाए तो पूरा वर्कफ़्लो धीमा होगा।
अज्ञात मानों को first-class मानें। स्पष्ट स्टेट्स जैसे null/unknown का उपयोग करें, साथ में कारण जब सहायक हो (missing page, unreadable, not applicable)। इससे दस्तावेज़ आगे बढ़ता रहता है जबकि समीक्षा करने वालों को दिखता है किस पर ध्यान चाहिए।
साथ ही extracted फ़ील्ड्स के लिए provenance और confidence स्टोर करें। स्रोत हो सकता है user, OCR, import, या API। confidence 0-1 स्कोर या high/medium/low जैसे छोटे सेट में हो सकता है। अगर OCR ने "$18.70" कम confidence के साथ पढ़ा क्योंकि आखिरी अंक धुंधला है, UI उसे हाइलाइट कर सकता है और त्वरित पुष्टि माँग सकता है।
मल्टी-पेज दस्तावेज़ों के लिए एक अतिरिक्त निर्णय चाहिए: क्या चीज़ दस्तावेज़ पूरी पर लागू होती है और क्या किसी एक पेज पर? कुल रकम और विक्रेता आम तौर पर दस्तावेज़-स्तरीय होते हैं। पेज-लेवल नोट्स, redactions, rotation और पेज-वार classification अक्सर पेज-लेवल पर होते हैं।
स्टेट का जवाब यह है: “यह दस्तावेज़ प्रक्रिया में कहाँ है?” इसे छोटा और साधारण रखें। अगर आप हर बार किसी ने नया पूछा तो नया स्टेट जोड़ते गए, तो फिल्टर भरोसेमंद नहीं रहेंगे।
एक व्यावहारिक बिज़नेस स्टेट्स सेट जो वास्तविक निर्णयों से मानचित्रित होता है:
“Processing” को बिज़नेस स्टेट से बाहर रखें। OCR चलना और प्रिव्यू बनना सिस्टम क्या कर रहा है बताते हैं, न कि व्यक्ति को अगला क्या करना चाहिए। इन्हें अलग प्रोसेसिंग स्टेट्स में स्टोर करें।
असाइनमेंट को भी स्टेट से अलग रखें (assignee_id, team_id, due_date)। एक दस्तावेज़ Approved हो सकता है पर फिर भी follow-up के लिए असाइन किया गया रहे, या Needs review हो पर अभी कोई owner नहीं हो।
स्टेट हिस्ट्री रिकॉर्ड करें, केवल वर्तमान मान नहीं। एक साधारण लॉग जैसे (from_status, to_status, changed_at, changed_by, reason) काम आता है जब कोई पूछे, “इस रसीद को किसने reject किया और क्यों?”
अंत में, तय करें कि हर स्टेट में कौन सी क्रियाएँ अनुमत हैं। नियम सरल रखें: Imported से Needs review जा सकता है; Approved read-only है जब तक नया वर्ज़न नहीं बनाया जाता; Rejected को फिर से खोला जा सकता है पर पिछले कारण को रखना होगा।
अधिकतर समय सूची स्कैन करने, एक आइटम खोलने, कुछ फ़ील्ड ठीक करने, और आगे बढ़ने में जाता है। अच्छा UI उन कदमों को तेज़ और प्रत्याश्यपूर्ण बनाता है।
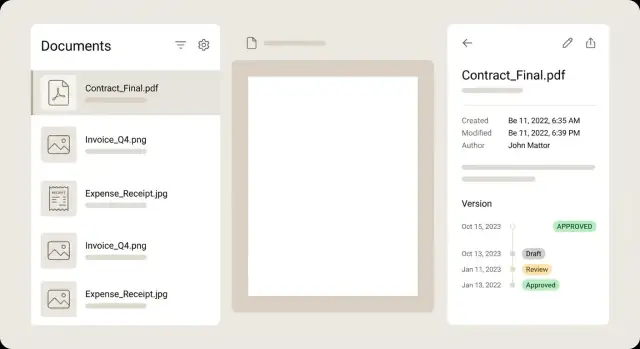
दस्तावेज़ सूची के लिए, हर रो को सारांश की तरह ट्रीट करें ताकि उपयोगकर्ता हर फाइल खोलने के बिना निर्णय ले सकें। एक मजबूत रो छोटा थंबनेल, स्पष्ट शीर्षक, कुछ प्रमुख फ़ील्ड्स (merchant, date, total), एक स्टेटस बैज, और जब ध्यान चाहिए तो एक सूक्ष्म वॉर्निंग दिखाती है।
डिटेल व्यू को शांत और स्कैन करने योग्य रखें। एक सामान्य लेआउट है लेफ्ट पर प्रिव्यू और राइट पर मेटाडेटा, प्रत्येक फ़ील्ड के पास एडिट कंट्रोल्स। उपयोगकर्ताओं को ज़ूम, रोटेट और पेज बदलने में सक्षम होना चाहिए बिना फॉर्म में अपनी जगह खोए। अगर कोई फ़ील्ड OCR से निकला है तो एक छोटा confidence सूचक दिखाएँ, और आदर्श रूप में जब फ़ील्ड फोकस में हो तो प्रिव्यू पर सोर्स एरिया हाइलाइट करे।
वर्ज़न सबसे अच्छे टाइमलाइन के रूप में काम करते हैं, ड्रॉपडाउन के बजाय। दिखाएँ किसने क्या और कब बदला, और किसी भी पुराने वर्ज़न को read-only मोड में खोलने दें। अगर आप तुलना देते हैं, तो metadata में अंतर (amount बदला, vendor ठीक किया) पर फोकस करें बजाय PDF के पिक्सल-बाय-पिक्सल तुलना के।
रिव्यू मोड स्पीड के लिए ऑप्टिमाइज़ होना चाहिए। एक कीबोर्ड-फर्स्ट ट्रायज फ्लो अक्सर पर्याप्त है: तेज़ approve/reject क्रियाएँ, सामान्य फ़ील्ड्स के लिए फास्ट फिक्स, और rejections के लिए एक छोटा कमेंट बॉक्स।
Empty states अहम हैं क्योंकि दस्तावेज़ अक्सर mid-processing होते हैं। खाली बॉक्स के बजाय बताएं क्या हो रहा है: “Preview जेनरेट हो रहा है,” “OCR चल रहा है,” या “इस फाइल टाइप का प्रिव्यू अभी नहीं है।”
एक सरल वर्कफ़्लो ऐसा लगता है जैसे “अपलोड, चेक, अप्रूव।” अंदर के काम में यह तब बेहतर चलता है जब आप फाइल (वर्ज़न और प्रिव्यू) को बिजनेस मीनिंग (मेटाडेटा और स्टेटस) से अलग रखें।
यूज़र एक PDF, फोटो, या रसीद स्कैन अपलोड करता है और तुरंत उसे इनबॉक्स सूची में देखता है। प्रोसेसिंग खत्म होने तक इंतज़ार न करें। एक फाइलनाम, अपलोड समय, और एक स्पष्ट बैज जैसे “Processing” दिखाएं। यदि आप स्रोत पहले से जानते हैं (ईमेल इम्पोर्ट, मोबाइल कैमरा, ड्रैग-एंड-ड्रॉप), तो वह भी दिखाएँ।
अपलोड पर, एक Document रिकॉर्ड बनाएं (लॉन्ग-लिव्ड चीज़) और एक Version रिकॉर्ड (यह विशेष फाइल)। current_version_id को नए वर्ज़न पर सेट करें। preview_state = pending और extraction_state = pending सेट करें ताकि UI बता सके क्या रेडी है।
डिटेल व्यू तुरंत खुलना चाहिए, पर एक placeholder व्यूअर और स्पष्ट “Preparing preview” संदेश दिखाएँ बजाय टूटे फ्रेम के।
एक बैकग्राउंड जॉब थंबनेल और viewable प्रिव्यू बनाता है (PDF के लिए पेज इमेज, फोटो के लिए रिसाइज़्ड इमेज)। एक और जॉब मेटाडेटा एक्सट्रैक्ट करता है (vendor, date, total, currency, document type)। जब हर जॉब खत्म हो, केवल उसके स्टेट और टाइमस्टैम्प अपडेट करें ताकि आप फेल्यर्स को रीट्राई कर सकें बिना बाकी चीज़ों को छेड़े।
UI को संकुचित रखें: preview state, data state दिखाएँ, और low confidence वाले फ़ील्ड्स हाइलाइट करें।
जब प्रिव्यू रेडी हो, रिव्यूअर फ़ील्ड्स सही करते हैं, नोट्स जोड़ते हैं, और दस्तावेज़ को Imported -> Needs review -> Approved (या Rejected) जैसे बिज़नेस स्टेट्स से आगे बढ़ाते हैं। लॉग रखें कि किसने क्या और कब बदला।
यदि रिव्यूअर एक corrected फाइल अपलोड करता है, तो वह एक नया Version बन जाती है और दस्तावेज़ स्वचालित रूप से Needs review में लौट आता है।
एक्सपोर्ट्स, अकाउंटिंग सिंक, या इंटरनल रिपोर्ट्स current_version_id और approved metadata snapshot से पढ़ें, न कि “latest extraction” से। यह रोकता है कि आधा-प्रोसेस हुआ re-upload नंबर बदल दे।
दस्तावेज़-केंद्रित वर्कफ़्लो उबाऊ कारणों से फेल होते हैं: शुरुआती शॉर्टकट रोज़मर्रा की परेशानियाँ बन जाते हैं जब लोग डुप्लिकेट अपलोड करते हैं, गलतियाँ सुधारते हैं, या पूछते हैं, “किसने और कब यह बदला?”
फ़ाइल नाम को दस्तावेज़ की पहचान मानना क्लासिक गलती है। नाम बदलते हैं, यूज़र्स फिर से अपलोड करते हैं, और कैमरे डुप्लिकेट नाम बनाते हैं जैसे IMG_0001। हर दस्तावेज़ को एक स्थिर ID दें, और फ़ाइल नाम को केवल एक लेबल मानें।
मूल फाइल को ओवरराइट करना भी परेशानी पैदा करता है। यह सरल लगता है, पर आप अपना ऑडिट ट्रेल खो देते हैं और बाद में बुनियादी सवालों का जवाब नहीं दे पाते (कौन सा अप्रूव हुआ था, क्या एडिट हुआ था, क्या भेजा गया था)। बाइनरी फाइल को अपरिवर्तनीय रखें और नया वर्ज़न रिकॉर्ड जोड़ें।
स्टेट भ्रम सूक्ष्म बग पैदा करता है। “OCR चल रहा है” और “Needs review” एक ही नहीं हैं। प्रोसेसिंग स्टेट बताते हैं सिस्टम क्या कर रहा है; बिज़नेस स्टेट बताते हैं व्यक्ति को क्या करना चाहिए। जब दोनों मिल जाते हैं, दस्तावेज़ गलत बकेट में फँस जाते हैं।
UI निर्णय भी घर्षण पैदा कर सकते हैं। अगर आप स्क्रीन को तब तक ब्लॉक कर देते हैं जब तक प्रिव्यू जेनरेट न हो जाए, तो लोग ऐप को धीमा अनुभव करेंगे भले ही अपलोड सफल हो गया हो। दस्तावेज़ को तुरंत दिखाएँ एक स्पष्ट placeholder के साथ, फिर रेडी होने पर थंबनेल स्वैप करें।
अंत में, मेटाडेटा अविश्वसनीय बन जाता है जब आप वैल्यूज़ provenance के बिना स्टोर करते हैं। अगर total OCR से आया था, तो बताइए। टाइमस्टैम्प रखें।
एक त्वरित चेकलिस्ट:
उदाहरण: एक रिसीप्ट ऐप में, उपयोगकर्ता clearer फोटो फिर से अपलोड करता है। अगर आप इसे वर्ज़न करते हैं, तो पुरानी इमेज रखें, OCR को reprocessing मार्क करें, और Needs review रखें जब तक कोई इंसान राशि कन्फर्म न करे।
दस्तावेज़-केंद्रित वर्कफ़्लो "मुकम्मल" तब लगता है जब लोग जो वे देखते हैं उस पर भरोसा कर सकें और चीज़ें गलत होने पर रिकवर कर सकें। लॉन्च से पहले गंदे, असली दस्तावेज़ों के साथ टेस्ट करें (धुंधली रसीदें, घुमी हुई PDFs, बार-बार अपलोड)।
पाँच जांचें जो अधिकतर आश्चर्य पकड़ लेती हैं:
एक छोटी वास्तविकता परीक्षण: किसी से कहें तीन समान रसीदें रिव्यू करें और जानबूझकर एक गलत परिवर्तन करें। अगर वे वर्तमान वर्ज़न पहचान सकें, स्टेट समझ सकें, और एक मिनट के अंदर गलती सुधार सकें, तो आप काफी नज़दीक हैं।
मासिक रसीद चुकौती स्पष्ट उदाहरण है दस्तावेज़-केंद्रित काम का। एक कर्मचारी रसीद अपलोड करता है, फिर दो समीक्षक उसे देखते हैं: पहला मैनेजर, फिर फ़ायनेंस। रसीप्ट खुद उत्पाद है, इसलिए आपकी ऐप वर्ज़निंग, प्रिव्यूज़, मेटाडेटा और स्पष्ट स्टेट्स पर टिकी रहती है।
Jamie एक टैक्सी रसीद की फोटो अपलोड करता/करती है। आपकी सिस्टम Document #1842 बनाती है Version v1 (मूल फाइल), एक थंबनेल और प्रिव्यू, और मेटाडेटा जैसे merchant, date, currency, total और OCR confidence स्कोर। दस्तावेज़ Imported में शुरू होता है, फिर preview और extraction रेडी होने पर Needs review में चला जाता है।
बाद में, Jamie गलती से वही रसीद फिर से अपलोड कर देता/देती है। एक duplicate चेक (file hash और समान vendor/date/total) सरल विकल्प दिखा सकता है: “ऐसा लगता है कि यह #1842 का duplicate है। फिर भी attach करें या discard?” यदि वे attach करते हैं, तो इसे उसी Document से जुड़ी दूसरी File के रूप में स्टोर करें ताकि समीक्षा थ्रेड और स्टेट एक ही रहे।
रिव्यू के दौरान, मैनेजर प्रिव्यू, प्रमुख फ़ील्ड्स और चेतावनियाँ देखता है। OCR ने total $18.00 पढ़ा पर इमेज स्पष्ट रूप से $13.00 दिखाती है। Jamie total सही कर देता/देती है। इतिहास न मिटे: Version v2 बनाएं जिसमें अपडेटेड फील्ड्स हों, v1 अपरिवर्तित रहें, और "Total corrected by Jamie" लॉग करें।
यदि आप इस तरह का वर्कफ़्लो जल्दी बनाना चाहते हैं, तो Koder.ai (koder.ai) आपकी मदद कर सकता है ताकि आप चैट-आधारित प्लान से ऐप का पहला वर्किंग वर्ज़न जेनरेट कर सकें, पर वही नियम लागू होता है: पहले ऑब्जेक्ट्स और स्टेट्स परिभाषित करें, फिर स्क्रीन बनने दें।
व्यावहारिक अगले कदम:
एक document-centric ऐप वह है जो दस्तावेज़ को मुख्य उत्पाद मानता है, न कि केवल एक अटैचमेंट। लोग उसे खोलते हैं, उस पर भरोसा करते हैं, जो बदला वो समझते हैं, और अगला कदम उसी दस्तावेज़ के आधार पर तय करते हैं।
एक इनबॉक्स/लिस्ट, तेज़ प्रिव्यू वाला दस्तावेज़ डिटेल व्यू, एक सरल समीक्षा क्षेत्र (approve/reject/request changes), और एक्सपोर्ट/शेयर करने का रास्ता — ये चार स्क्रीन ढूँढो, खोलो, निर्णय लो और हेंडऑफ करने के सामान्य चक्र को कवर करती हैं।
एक स्थिर Document रिकॉर्ड मॉडल करें जो कभी बदलता न हो, और वास्तविक फाइल बाइट्स को अलग File ऑब्जेक्ट के रूप में रखें। फिर एक Version जोड़ें जो किसी विशेष फाइल (और उसके derived outputs) को उस दस्तावेज़ से जोड़ता है। यह अलगाव कमेंट्स, असाइनमेंट और इतिहास को बरकरार रखता है।
हर महत्वपूर्ण बदलाव को नई वर्ज़न बनाकर ही रखें; inplace overwrite न करें। डॉक्यूमेंट पर तेज़ ‘latest’ पढ़ने के लिए current_version_id रखें और audit/rollback के लिए पुराने वर्ज़न का टाइमलाइन रखें।
मूल फाइल सहेजकर प्रिव्यूज़ asynchronously जेनरेट करें ताकि अपलोड तुरंत लगे और retries सुरक्षित रहें। pending/ready/failed जैसे preview स्टेट ट्रैक करें ताकि UI ईमानदार रहे, और अलग-अलग आकार स्टोर करें ताकि लिस्ट व्यू हल्का और डिटेल शार्प रहे।
मेटाडेटा को तीन बकेट में रखें: सिस्टम (फाइल नाम, साइज, MIME type), एक्सट्रैक्टेड (OCR फ़ील्ड और confidence), और यूज़र-एंटरड करेक्शंस। प्रॉवेनन्स रखें ताकि पता चले कोई वैल्यू OCR से आई है या किसी इंसान ने डाली है।
छोटे, स्पष्ट बिज़नेस स्टेट्स रखें जो बताएं अगला इंसान क्या करेगा: Imported, Needs review, Approved, Rejected, Archived। प्रोसेसिंग (OCR/preview चल रहा है) को अलग रखें ताकि दस्तावेज़ गलत bucket में फँसे न रहें।
अपलोड पर immutable फाइल चेकसम्स स्टोर करें और उन पर तुलना करें; जब उपलब्ध हो तो vendor/date/total जैसे प्रमुख फ़ील्ड्स से दूसरा मिलान भी जोड़ें। शक होने पर यूज़र को स्पष्ट विकल्प दें: इसे उसी Document में attach करें या discard करें।
कौन-क्या बदला, कब और क्यों इसका लॉग रखें (from_status, to_status, changed_at, changed_by, reason), और rollback को एक पॉइंटर चेंज रखें न कि डिलीट। इससे आडिट रिकॉर्ड और तेजी से recovery मिलती है।
पहले ऑब्जेक्ट्स और स्टेट्स पर स्पष्ट रहें, फिर UI बनने दें। अगर आप Koder.ai का उपयोग करते हैं तो chat प्लान में Document/Version/File, preview और extraction स्टेट्स, और status नियम स्पष्ट बताएं ताकि जेनरेट किए गए स्क्रीन वास्तविक वर्कफ़्लो से मेल खाएं।